Operation ①:
requirement:
Master Selenium to find HTML elements, crawl Ajax web page data, wait for HTML elements, etc.
Use Selenium framework to crawl the information and pictures of certain commodities in Jingdong Mall.
Candidate sites: http://www.jd.com/
Key words: Students' free choice
1.1 experimental process
1.1.1 simulate users to search for commodity keywords
- Right click the search bar on JD's main page to check, and click find_element_by_id("key") for positioning,
Simulate the user to fill in the search keywords and press enter to enter the relevant page.

self.driver.get(url) #JD home page
keyInput = self.driver.find_element_by_id("key") #Find search bar
keyInput.send_keys(key)#Input keywords into mobile phone
keyInput.send_keys(Keys.ENTER) #Simulated carriage return
send_ Some usage of keys: cut, paste, select all and other operations are similar to copying, and can be modified to the corresponding letter.
| grammar | effect |
|---|---|
| send_keys(Keys.BACK_SPACE) | Delete key BackSpace |
| send_keys(Keys.SPACE) | Spacebar Space |
| send_keys(Keys.ENTER) | Enter |
| send_keys(Keys.CONTROL,'c') | Copy CTRL+C |
1.1.2 crawling commodity information
- Acquisition of mMark:
It is found that the first word of the title is the brand of the mobile phone, so we need to segment the title.
However, it should be noted that some mobile phone brands will have the label of "Jingpin mobile phone" in front, and we need to delete it.

- After cutting through the blank space, it can be found that Jingpin mobile phone is connected with the brand, so the code is as follows:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
if(mark[0:4] == 'Jingpin mobile phone'): #Remove unnecessary information
mark = mark[4:]
- About obtaining picture src:
There are two situations:
| Xpath path |
|---|
| li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src") |
| li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img") |
I'm confused about the attribute data lazy img, because when you directly view the web page html or use xpath helper, the value of this attribute is done, and the address of the picture is in the src attribute.

Query the relevant information and find that the html I see is responsive. You can understand the reason by using python to obtain the source code.
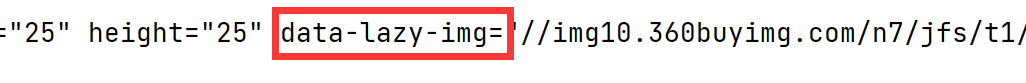
- Other information can be obtained normally, and some processing can be done as needed. It will not be displayed here.
1.1.3 commodity loading
- It can be found that there are only 30 items per page before the page drop-down

- However, there are 60 items per page after the page drop-down

- Therefore, if you want to obtain complete information, you need to load more products by using the simulated drop-down method.
The scroll bar cannot be located directly. There is no direct method to control the scroll bar in selenium. We can use Js to handle it.
#Control page drop-down js = 'document.documentElement.scrollTop=10000' #10000 represents the bottom self.driver.execute_script(js) time.sleep(5) #You need to stop for a while for the page to load
1.1.4 page turning processing
- The limited crawling quantity is 101. Since there are 60 items per page, it will only climb to the second page.
if(self.No < 101): #Limited climb 101
try:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(5)
nextPage.click()
self.processSpider() #Climb a new page
except Exception as err:
print(err)
1.1.5 downloading pictures
- urllib requests to access resources and obtain image data. Note that src1 and src2 are relative addresses, which need to be completed by urljoin before they can be accessed correctly.
After successful download, save to local folder.
#urllib request
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
...
if data: #The picture data needs to be written after it is successfully obtained
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
1.1.6 database
- Build table
def openDB(self):
print("opened")
try:
#Database connection
self.con = pymysql.connect(host="localhost", port=3306, user="root",
passwd="cccc", db="crawl", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#Create table
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256)," \
"mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
#If it already exists, delete the data
except Exception as err:
self.cursor.execute("delete from phones")
- insert
def insert(self,mNo, mMark, mPrice, mNote, mFile):
#if self.opened:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values ( % s, % s, % s, % s, % s)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
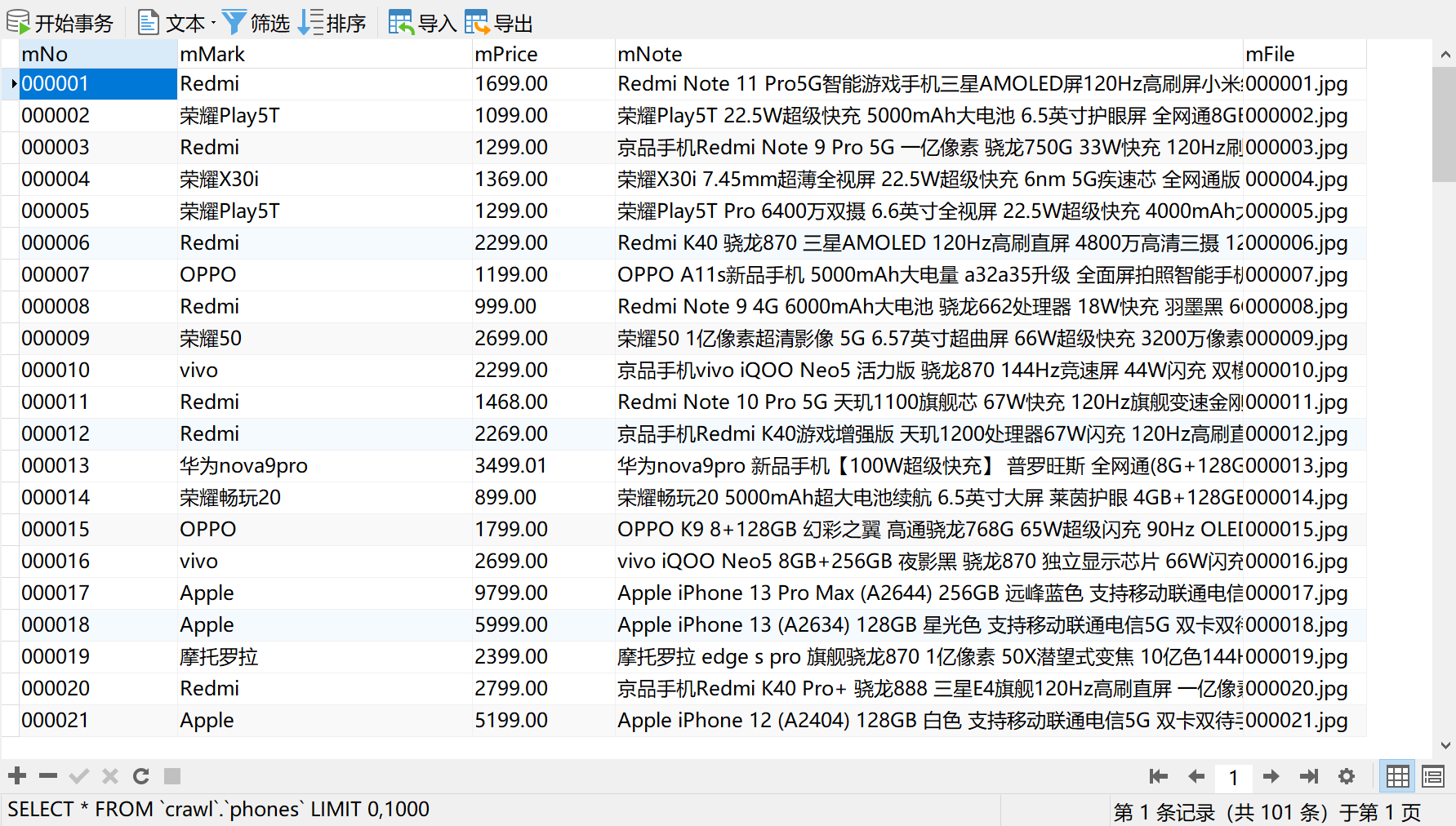
1.1.7 operation results
- Database storage
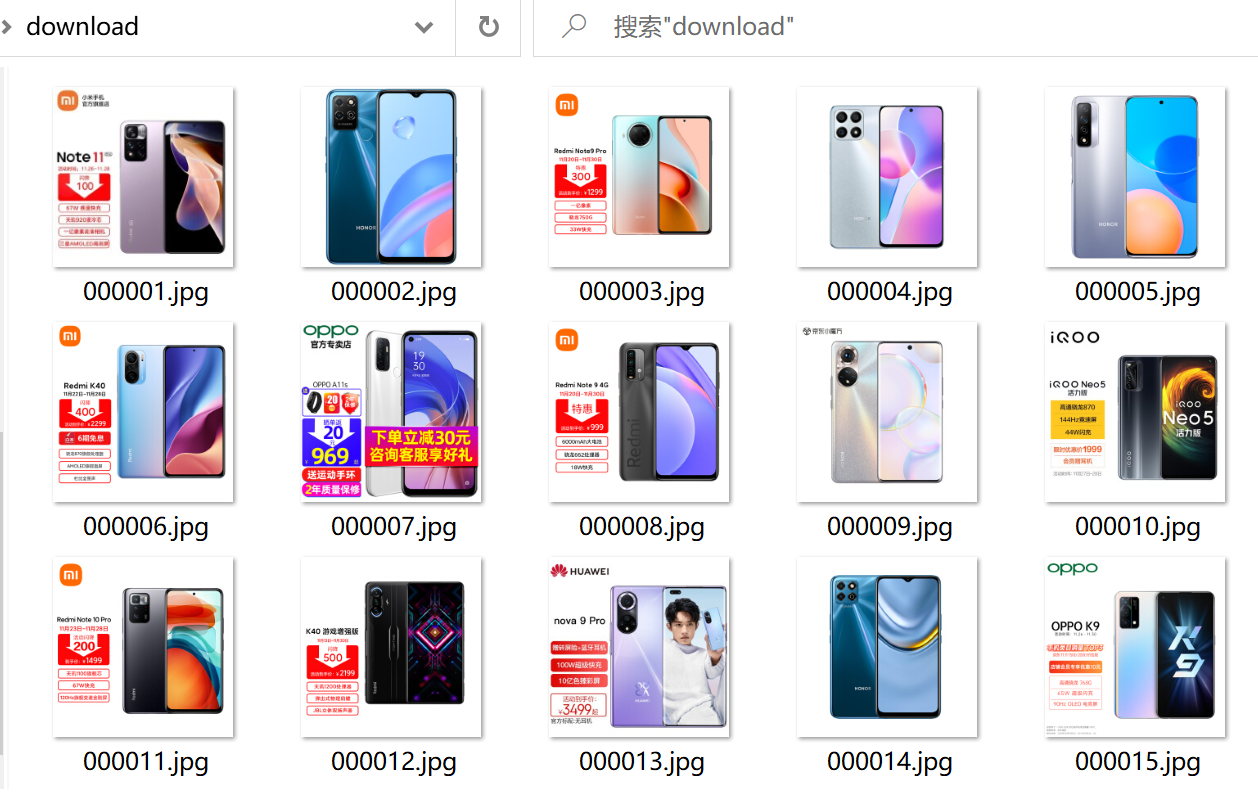
- Downloaded pictures
1.2 experimental experience
- This topic mainly uses Selenium to simulate crawling Jingdong's goods into the database and download relevant pictures.
I learned the method of page drop-down by executing js script, but remember that sleep will let the page load for a period of time. Strengthen the awareness of relative address and absolute address, and pay more attention.
Code link
https://gitee.com/yozhibo/crawl_project/blob/master/task_5/job_1
Operation ②:
requirement:
Proficient in Selenium's search for HTML elements, user simulated Login, crawling Ajax web page data, waiting for HTML elements, etc.
Use Selenium framework + Mysql to simulate login to muke.com, obtain the information of the courses learned in the students' own account, save it in MySQL (course number, course name, teaching unit, teaching progress, course status and course picture address), and store the pictures in the imgs folder under the root directory of the local project. The names of the pictures are stored with the course name.
Candidate website: China mooc website: https://www.icourse163.org
2.1 experimental process
2.1.1 simulated Login
- Two login methods
First, the mobile phone number login needs to simulate more clicks and inputs, and will encounter the problem of nested pages, but it is not necessary to scan the code every time after completion.
Second, scan the code to log in. You need to set a waiting time of a few seconds and log in with a mobile app.
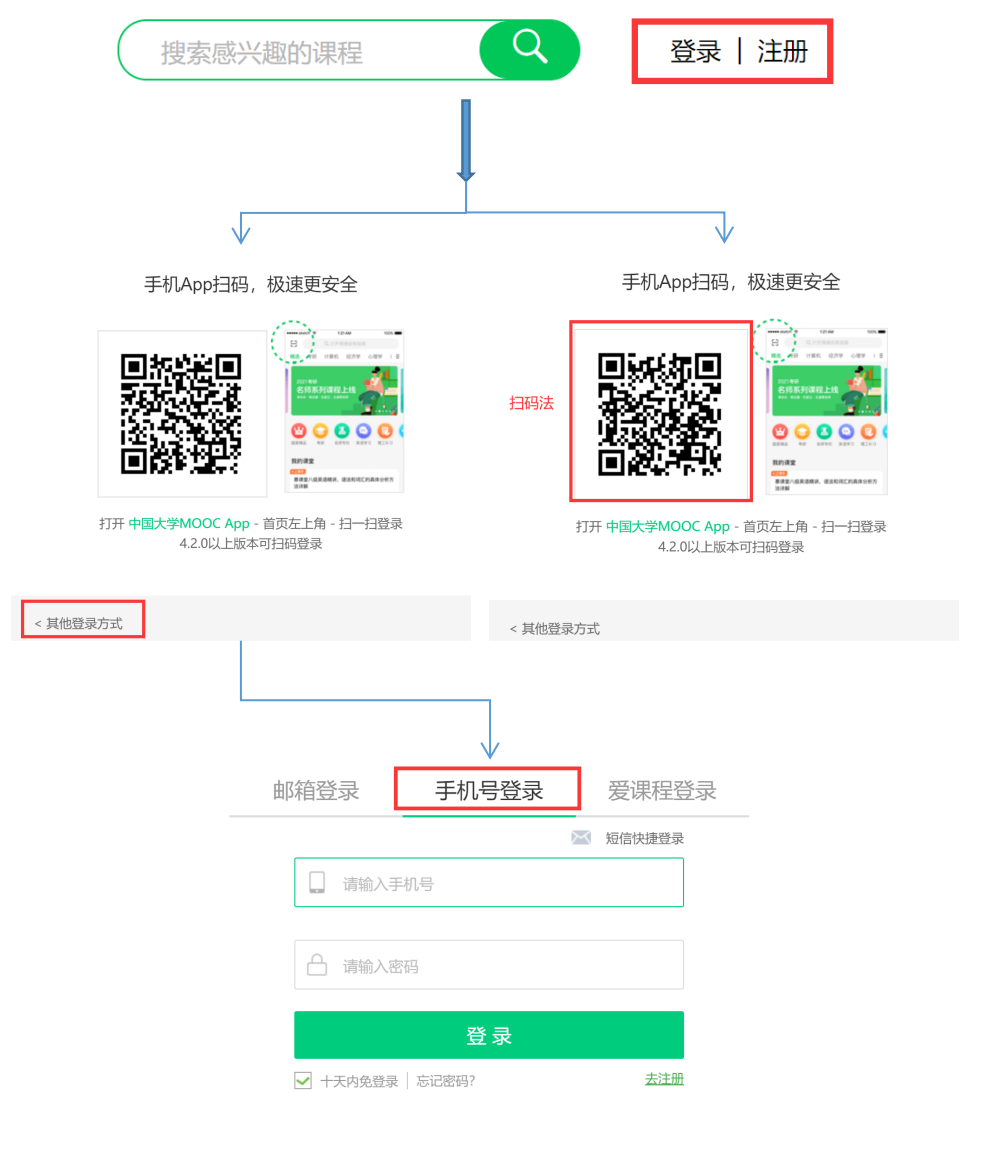
- Mobile number login:
① Simulate clicking "login", "login by other methods" and "login by mobile number"
#Login entry
wait.until(EC.element_to_be_clickable(
(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div'))).click()
#Other login methods
wait.until(EC.element_to_be_clickable(
(By.XPATH, '//div[@class="mooc-login-set"]//span[@class="ux-login-set-scan-code_ft_back"]'))).click()
#Mobile number login
wait.until(EC.element_to_be_clickable(
(By.XPATH, '//ul[@class="ux-tabs-underline_hd"]/li[position()=2]'))).click()
② Find the iframe and locate it, and switch the locator to iframe

#Find nested pages
iframe = self.driver.find_element_by_xpath('//div[@id="j-ursContainer-1"]/iframe[1]')
self.driver.switch_to.frame(iframe)
② Simulate input of account and password, and click login
#Account password
PHONENUM= "101" #In line 101, you can modify it yourself.
PASSWORD = "102"
#Enter account
self.driver.find_element_by_xpath\
('//div[@class="u-input box"]//input[@type="tel"]').send_keys(PHONENUM)
#Input password
self.driver.find_element_by_xpath\
('//div[@class="inputbox"]//input[@type="password"][2]').send_keys(PASSWORD)
#Click the login button
self.driver.find_element_by_xpath('//*[@id="submitBtn"]').click()
- Code scanning login:
wait = WebDriverWait(self.driver, 8)
#Login entry
wait.until(EC.element_to_be_clickable(
(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div'))).click()
#Wait for 5 seconds and wait for 8 seconds in the next step. The code scanning time is still sufficient
time.sleep(5)
2.1.2 course information crawling
- First, go to the "personal center" page

#Click personal Center
wait.until(EC.element_to_be_clickable(
(By.XPATH,'//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[3]/div/div/a/span'))).click()
After entering, you can view each course: the course information is shown in the frame, a total of 6 courses.

- The crawling of course information is relatively routine, and the main codes are directly displayed here
Id = self.No #Serial number
cCourse = li.find_element_by_xpath('.//Span [@ class = "text"]). Text # course name
cCollege = li.find_element_by_xpath('.//Div [@ class = "school"]). Text # start university
cSchedule = li.find_element_by_xpath('.//Span [@ class = "course progress text span"]). Text # course progress
cCourseStatus = li.find_element_by_xpath('.//Div [@ class = "course status"]). Text # course status
cImgUrl = li.find_element_by_xpath('.//div[@class="img"]/img').get_attribute("src") # course map
self.No += 1
2.1.3 database show() function
- Output the crawled course information to the console
for row in rows:
print("%-10s %-20s %-20s %-20s %-30s %-30s" % (row['Id'], row['cCourse'],
row['cSchedule'], row['cSchedule'], row['cCourseStatus'],row['cImgUrl']))
2.1.4 picture download
- Name the picture with the course name, and pay attention to the format of the picture.
p = cImgUrl.rfind(".") #Determine the picture suffix location
cCourse = cCourse + cImgUrl[p:p+4] #Add the suffix of the picture to the course name
T = threading.Thread(target=self.download, args=(cImgUrl, cCourse)) #Multithreaded Download
2.1.5 result display
- Database storage
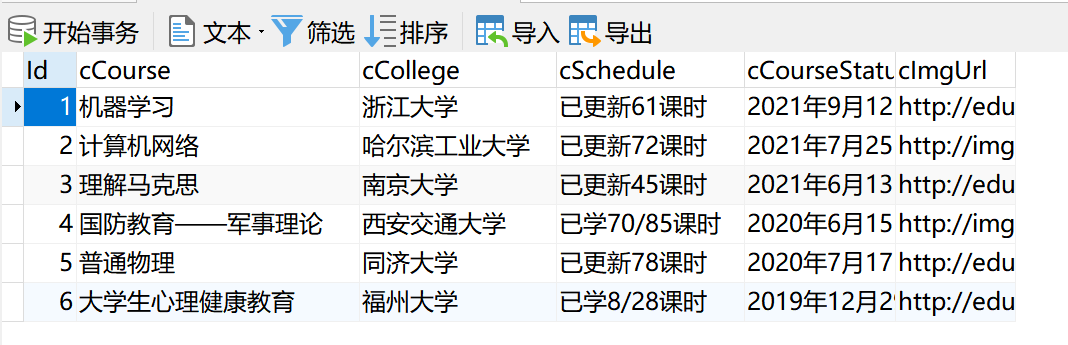
- Database output

- Picture download
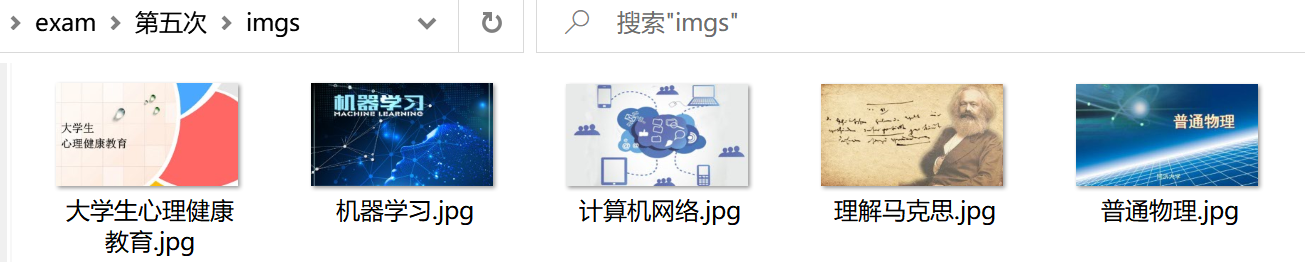
2.2 experimental experience
- In addition to being unable to locate correctly due to rendering, it may also be due to page nesting.
Scanning the code and logging in gave me a deeper understanding of selenium. It uses programs to simulate human operations,
During this period, people can also have their own operation, and the combination of the two can make up for each other's defects.
Code link
- Before running the code, you need to modify the account password (located in lines 101 and 102)
https://gitee.com/yozhibo/crawl_project/blob/master/task_5/job_2#
Operation ③: Flume log collection experiment
Requirements: Master big data related services and be familiar with the use of Xshell
Complete the document Hua Weiyun_ The tasks in the big data real-time analysis and processing experiment manual Flume log collection experiment (part) v2.docx are the following five tasks. See the document for specific operations.
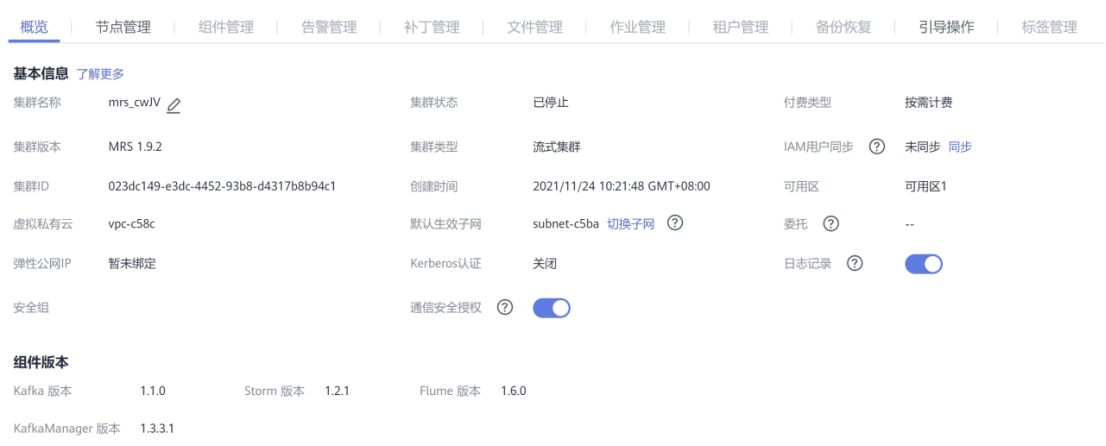
Task 1: open MapReduce service (environment construction)
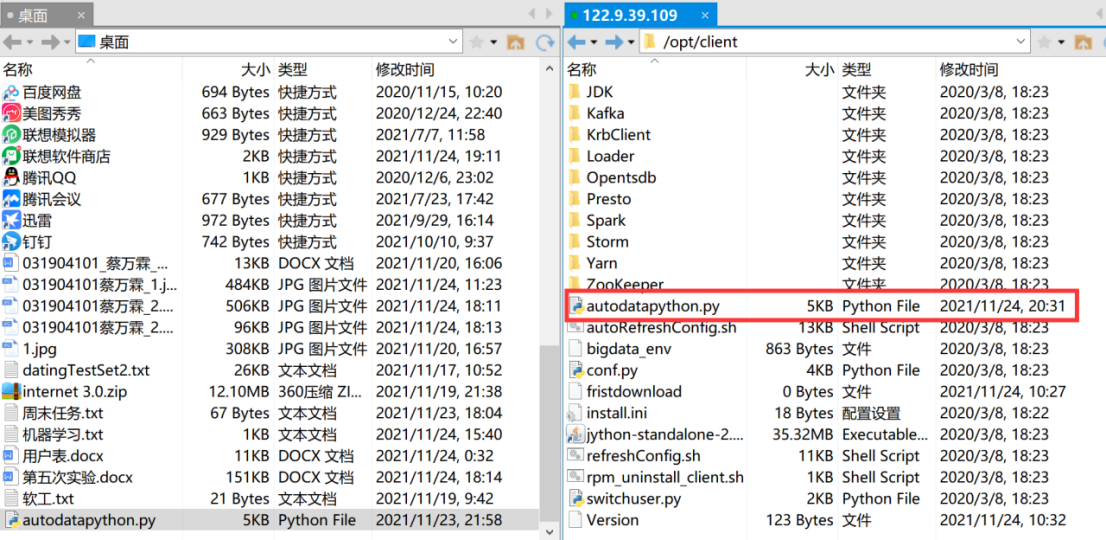
Task 2: generate test data from Python script
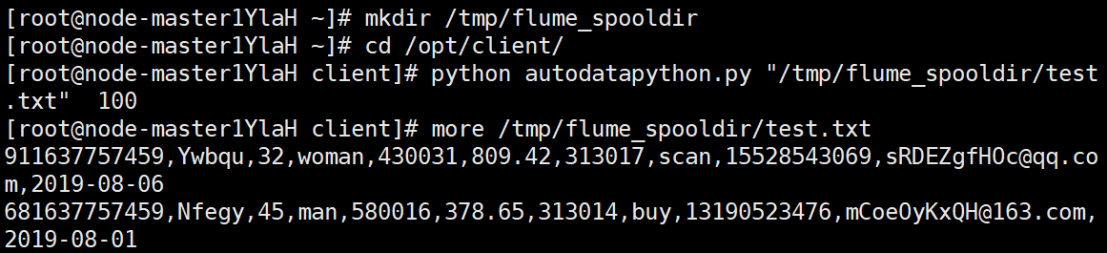
- Upload the local autodatapython.py file to the server / opt/client / directory
- Final view data: more / TMP / flume_ spooldir/test.txt
Task 3: configure Kafka
- source environment variable

- Create topic in kafka

- View topic information

Task 4: install Flume client
- Unzip the installation package

- Install Flume client

- Restart Flume service

Task 5: configure Flume to collect data
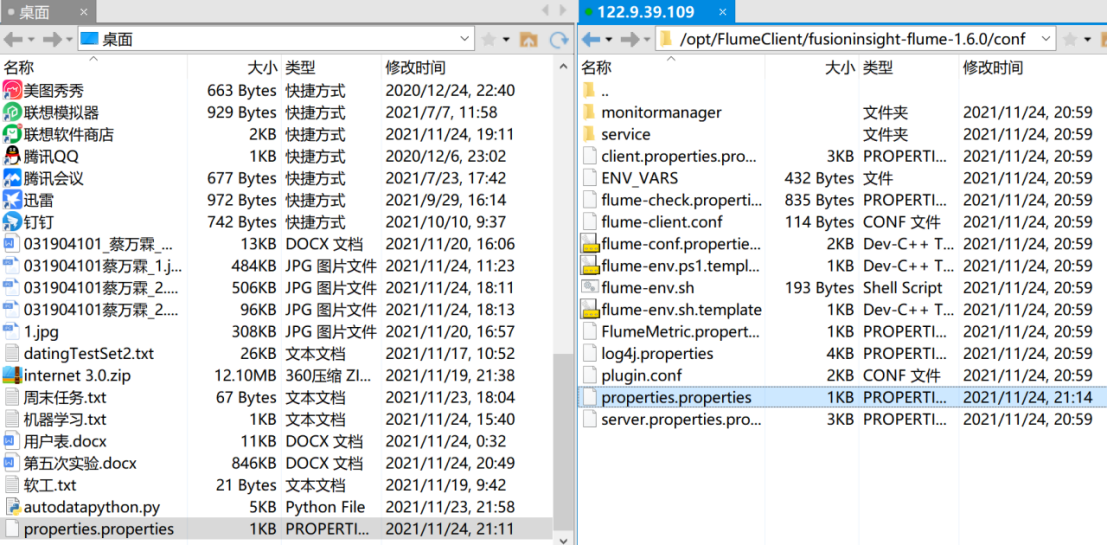
- After modifying the configuration file, upload it to the server with Xshell
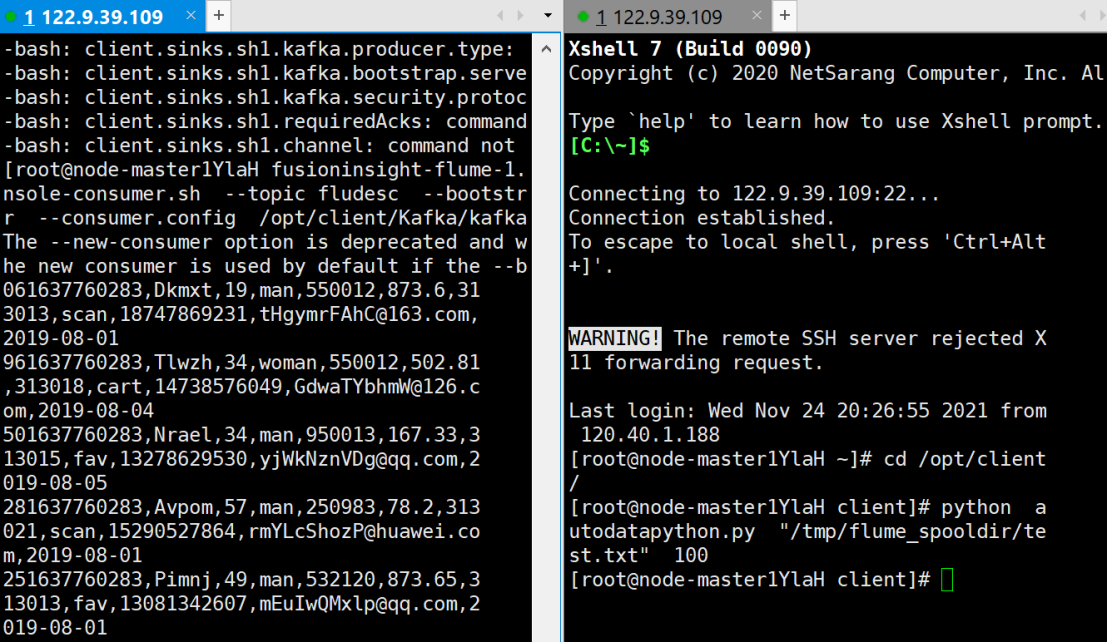
- Create data in consumer consumption kafka

- Open a new Xshell 7 window and execute Python script commands
Experimental experience
- Generally, it still follows the experimental steps, which is relatively smooth. Learned how to apply for and release resources on Huawei cloud platform, especially mapreduce service, and preliminarily mastered the steps of flume log collection.