Operation ①
1) Crawl Dangdang website book data
Requirements: master the serialization output method of Item and Pipeline data in the scene; Scrapy+Xpath+MySQL database storage technology route crawling Dangdang website book data
Candidate sites: http://search.dangdang.com/?key=python&act=input
Key words: students can choose freely
Output information: the output information of MySQL is as follows

Main code:
BookSpider.py
1 import scrapy 2 from book.items import BookItem 3 from bs4 import BeautifulSoup 4 from bs4 import UnicodeDammit 5 6 class MySpider(scrapy.Spider): 7 name = "books" 8 key = 'python' 9 source_url='http://search.dangdang.com/' 10 11 def start_requests(self): 12 url = MySpider.source_url+"?key="+MySpider.key 13 yield scrapy.Request(url=url,callback=self.parse) 14 15 def parse(self, response): 16 try: 17 dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) 18 data = dammit.unicode_markup 19 selector = scrapy.Selector(text=data) 20 print(selector) 21 lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]") 22 for li in lis: 23 title = li.xpath("./a[position()=1]/@title").extract_first() 24 price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first() 25 author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first() 26 date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first() 27 publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first() 28 detail = li.xpath("./p[@class='detail']/text()").extract_first() 29 # detail Sometimes there is no result None 30 31 item = BookItem() 32 item["title"] = title.strip() if title else "" 33 item["author"] = author.strip() if author else "" 34 item["date"] = date.strip()[1:] if date else "" 35 item["publisher"] = publisher.strip() if publisher else "" 36 item["price"] = price.strip() if price else "" 37 item["detail"] = detail.strip() if detail else "" 38 yield item 39 40 # On the last page link by None 41 link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first() 42 if link: 43 url = response.urljoin(link) 44 yield scrapy.Request(url=url, callback=self.parse) 45 except Exception as err: 46 print(err)
pipelines.oy
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 5 6 7 # useful for handling different item types with a single interface 8 from itemadapter import ItemAdapter 9 import pymysql 10 11 class BookPipeline(object): 12 def open_spider(self,spider): 13 print("opened") 14 try: 15 self.con=pymysql.connect(host="localhost", port=3306, user="root", password="123456", 16 db="mydb", charset="utf8") 17 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 18 self.cursor.execute("delete from books") 19 self.opened=True 20 self.count = 0 21 except Exception as err: 22 print(err) 23 self.opened=False 24 25 26 def close_spider(self,spider): 27 if self.opened: 28 self.con.commit() 29 self.con.close() 30 self.opened=False 31 print("closed") 32 print("Total crawling",self.count,"Book") 33 34 def process_item(self, item, spider): 35 try: 36 # print(item['title']) 37 # print(item['author']) 38 # print(item['publisher']) 39 # print(item['date']) 40 # print(item['price']) 41 # print(item['detail']) 42 # print() 43 if self.opened: 44 self.cursor.execute("insert into books(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) " 45 "values(%s,%s,%s,%s,%s,%s)", 46 (item['title'],item["author"],item["publisher"],item["date"],item["price"],item["detail"])) 47 self.count+=1 48 print("Climb to the third" + str(self.count) + "Ben success") 49 except Exception as err: 50 print(err) 51 return item
Experimental screenshot:
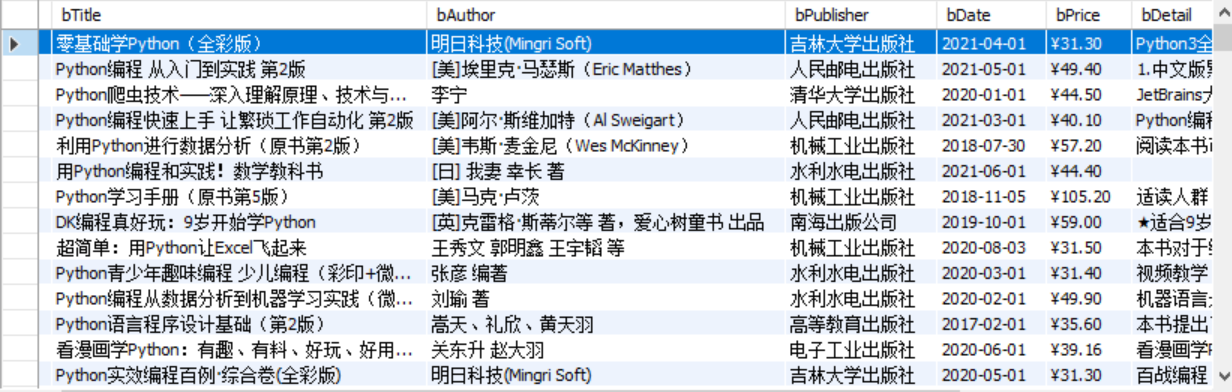
Add auto increment primary key:
1 ALTER TABLE t_security ADD id INT(16) NOT NULL 2 PRIMARY KEY AUTO_INCREMENT FIRST;
2) Experience
This topic mainly reproduces the examples in the book. The main problems encountered are data insertion and connection to the database. With the help of brother Cong and the teacher, it is found that it is a primary key. The solution is to add a self increasing primary key id,
Operation ②
1) Crawl foreign exchange website data
-
Requirements: master the serialization output method of Item and Pipeline data in the scene; Crawl the foreign exchange website data using the technology route of "scratch framework + Xpath+MySQL database storage".
-
Candidate website: China Merchants Bank Network: http://fx.cmbchina.com/hq/
-
Output information: MySQL database storage and output format
-
-
Id Currency TSP CSP TBP CBP Time 1 HKD 86.60 86.60 86.26 85.65 15: 36: 30 2......
-
Main code:
ForexSpider.py
1 import scrapy 2 from forex.items import ForexItem 3 from bs4 import BeautifulSoup 4 from bs4 import UnicodeDammit 5 6 class MySpider(scrapy.Spider): 7 name = "forex" 8 source_url='http://fx.cmbchina.com/Hq/' 9 10 def start_requests(self): 11 url = MySpider.source_url 12 yield scrapy.Request(url=url,callback=self.parse) 13 14 def parse(self, response): 15 try: 16 dammit = UnicodeDammit(response.body, ["utf-8", "utf-16", "gbk"]) 17 data = dammit.unicode_markup 18 selector = scrapy.Selector(text=data) 19 trs = selector.xpath('//*[@id="realRateInfo"]//tr[position()>1]') 20 for tr in trs: 21 currency = tr.xpath("./td[@class='fontbold'][1]/text()").extract_first() 22 tsp = tr.xpath('./td[4]/text()').extract_first() 23 csp = tr.xpath('./td[5]/text()').extract_first() 24 tbp = tr.xpath('./td[6]/text()').extract_first() 25 cbp = tr.xpath('./td[7]/text()').extract_first() 26 last_time = tr.xpath('./td[8]/text()').extract_first() 27 item = ForexItem() 28 item['currency'] = currency.strip() if currency else "" 29 item['tsp'] = tsp.strip() if currency else "" 30 item['csp'] = csp.strip() if currency else "" 31 item['tbp'] = tbp.strip() if currency else "" 32 item['cbp'] = cbp.strip() if currency else "" 33 item['last_time'] = last_time.strip() if currency else "" 34 yield item 35 36 except Exception as err: 37 print(err)
pipelines.py
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 5 6 7 # useful for handling different item types with a single interface 8 from itemadapter import ItemAdapter 9 import pymysql 10 11 class ForexPipeline(object): 12 def open_spider(self,spider): 13 print("opened") 14 try: 15 self.con=pymysql.connect(host="localhost", port=3306, user="root", password="123456", 16 db="mydb", charset="utf8") 17 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 18 self.cursor.execute("delete from forexs") 19 self.opened=True 20 self.count = 0 21 except Exception as err: 22 print(err) 23 self.opened=False 24 25 26 def close_spider(self,spider): 27 if self.opened: 28 self.con.commit() 29 self.con.close() 30 self.opened=False 31 print("closed") 32 print("Total crawling",self.count,"Data bar") 33 def process_item(self, item, spider): 34 print() 35 try: 36 print(item['currency']) 37 print(item['tsp']) 38 print(item['csp']) 39 print(item['tbp']) 40 print(item['cbp']) 41 print(item['last_time']) 42 print() 43 if self.opened: 44 self.cursor.execute("insert into forexs(Currency,TSP,CSP,TBP,CBP,Time) " 45 "values(%s,%s,%s,%s,%s,%s)", 46 (item['currency'], item["tsp"], item["csp"], item["tbp"], item["cbp"], 47 item["last_time"])) 48 self.count += 1 49 print("Climb to the third" + str(self.count) + "Data entry succeeded") 50 except Exception as err: 51 print(err) 52 return item
Experimental screenshot:
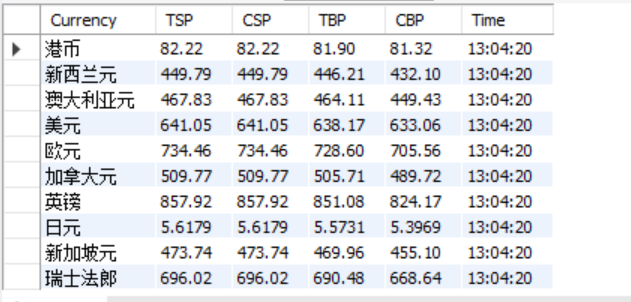
2) Experience:
It deepens the understanding of the writing sequence of script and xpath.
Operation ③
1)
-
Requirements: be familiar with Selenium's search for HTML elements, crawling Ajax web page data, waiting for HTML elements, etc; Use Selenium framework + MySQL database storage technology route to crawl the stock data information of "Shanghai and Shenzhen A shares", "Shanghai A shares" and "Shenzhen A shares".
-
Candidate website: Dongfang fortune.com: http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
Output information: the storage and output format of MySQL database is as follows. The header should be named in English, such as serial number id, stock code: bStockNo..., which is defined and designed by students themselves:
-
Serial number Stock code Stock name Latest quotation Fluctuation range Rise and fall Turnover Turnover amplitude highest minimum Today open 1 688093 N Shihua 28.47 62.22% 10.92 261 thousand and 300 760 million 22.34 32.0 28.08 30.2 17.55 2......
Main code:
1 from selenium import webdriver 2 from selenium.webdriver.chrome.options import Options 3 from bs4 import BeautifulSoup 4 import pymysql 5 import json 6 import requests 7 import re 8 from bs4 import UnicodeDammit 9 import urllib.request 10 11 12 13 class StockDB: 14 def openDB(self): 15 print("opened") 16 try: 17 self.con=pymysql.connect(host="localhost", port=3306, user="root", password="123456", 18 db="mydb", charset="utf8") 19 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 20 self.cursor.execute("delete from Stock_sz") 21 self.opened = True 22 self.count = 0 23 except Exception as err: 24 print(err) 25 self.opened = False 26 27 def insert(self, stockList): 28 try: 29 self.cursor.executemany( 30 "insert into Stock_sz(Id,StockCode,StockName,NewPrice,RiseFallPercent,RiseFallNum,Turnover,DealNum,Amplitude,Highest,Lowest,Today,Yesterday) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", 31 stockList) 32 except Exception as err: 33 print(err) 34 35 def closeDB(self): 36 if self.opened: 37 self.con.commit() 38 self.con.close() 39 self.opened = False 40 print("closed") 41 42 def show(self): 43 self.cursor.execute("select * from Stock_hs") 44 rows = self.cursor.fetchall() 45 print("{:8}\t{:16}\t{:8}\t{:8}\t{:8}\t{:8}" 46 "\t{:16}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}" .format("Stock code","Stock name","Latest price","Fluctuation range","Rise and fall","Turnover","Turnover","amplitude","highest","minimum","Today's harvest","Received yesterday",chr(12288))) 47 for row in rows: 48 print("{:8}\t{:16}\t{:8}\t{:8}\t{:8}\t{:8}" 49 "\t{:16}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}".format(row[0], row[1], row[2], row[3], row[4], row[5], row[6], row[7], row[8], row[9], row[10], row[11],chr(12288))) 50 51 class stock: 52 def getStockData(self): 53 chrome_options = Options() 54 chrome_options.add_argument('--headless') 55 chrome_options.add_argument('--disable-gpu') 56 driver = webdriver.Chrome(options=chrome_options) 57 driver.get("http://quote.eastmoney.com/center/gridlist.html#sz_a_board") 58 trs = driver.find_elements_by_xpath('//tbody/tr') 59 stocks = [] 60 for tr in trs: 61 tds = tr.find_elements_by_xpath('./td') 62 td = [x.text for x in tds] 63 stocks.append(td) 64 # print(stocks) 65 stockInfo = [] 66 for stock in stocks: 67 stockInfo.append((stock[0], stock[1], stock[2], stock[4], stock[5], stock[6], stock[7], stock[8], stock[9], 68 stock[10], stock[11], stock[12], stock[13])) 69 return stockInfo 70 71 def process(self): 72 self.db = StockDB() 73 self.db.openDB() 74 stockInfo = self.getStockData() 75 print(stockInfo) 76 self.db.insert(stockInfo) 77 # self.db.show() 78 self.db.closeDB() 79 80 if __name__ =="__main__": 81 s = stock() 82 s.process() 83 print("completed")
Experimental screenshot:
Shanghai and Shenzhen A shares
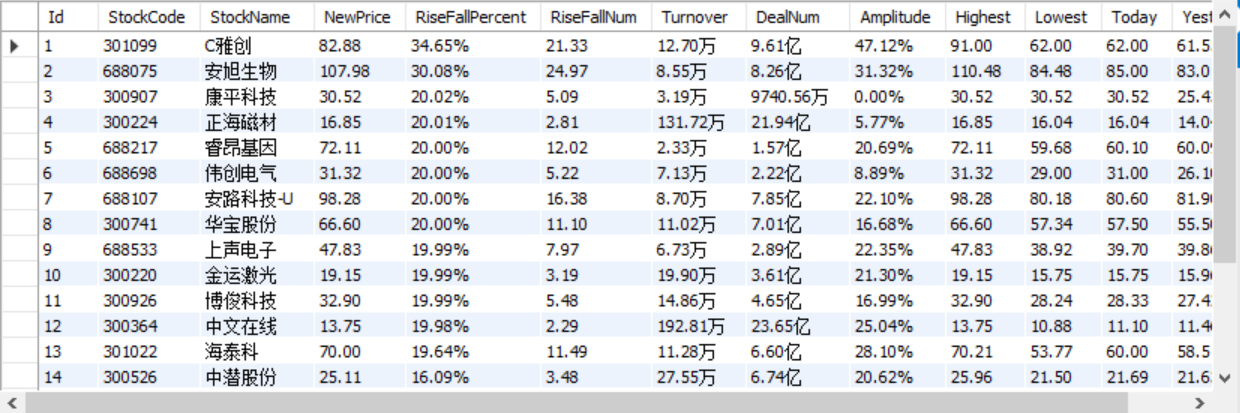
SSE A shares
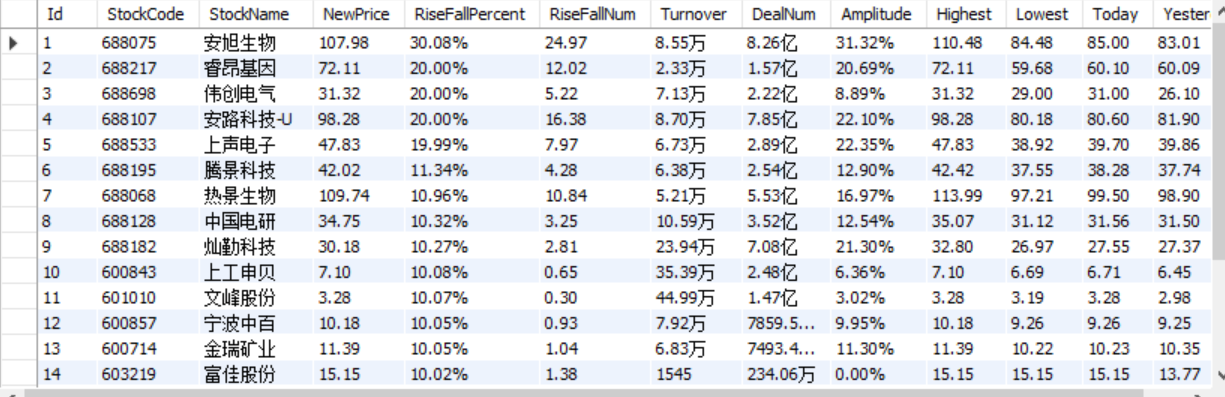
Shenzhen A shares
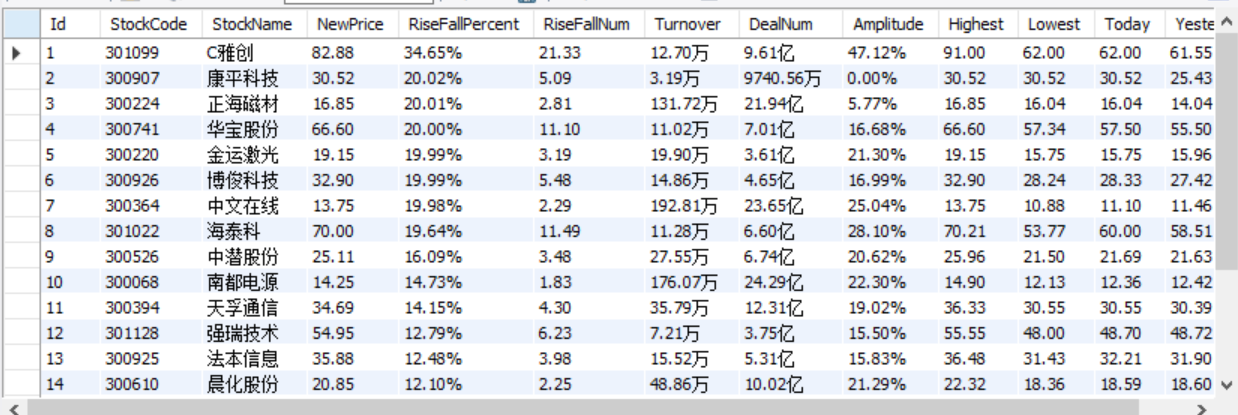
2) Experience:
Understand the workflow of selinum and strengthen the crawling and storage of continuous similar data.