This practical project is based on the dataset of Lending Club [dataset address: https://github.com/H-Freax/lendingclub_analyse/data/ ]
This practical project is based on Colab environment
brief introduction
This practical project of data analysis is divided into two parts. The first part mainly introduces the Baseline method based on LightGBM and three methods of adding derived variables, and finds four groups of derived variables that can improve the effect. The second part mainly introduces the data analysis based on machine learning method and deep learning network method, At the same time, the integration of machine learning methods and the integration of deep learning network and machine learning methods are practiced.
Use machine learning methods to solve
Data preparation
train_ML = df_train.copy() test_ML = df_test.copy()
train_ML.fillna(0,inplace=True) test_ML.fillna(0,inplace=True) X_train = train_ML.drop(columns=['loan_status']).values Y_train = train_ML['loan_status'].values.astype(int) X_test = test_ML.drop(columns=['loan_status']).values Y_test = test_ML['loan_status'].values.astype(int)
Machine learning method
Random forest
from sklearn.ensemble import RandomForestClassifier rnd_clf = RandomForestClassifier(n_estimators = 100,random_state = 20) rnd_clf.fit(X_train,Y_train) rnd_clf.score(X_test,Y_test)
0.9164
SGDClassifier random gradient descent
from sklearn.linear_model import SGDClassifier sgd_clf = SGDClassifier(random_state=20) #random_state is used for reproduction sgd_clf.fit(X_train,Y_train) sgd_clf.score(X_test,Y_test)
0.8639
logistic regression
from sklearn.linear_model import LogisticRegression lr_clf = LogisticRegression(random_state = 20) lr_clf.fit(X_train,Y_train) lr_clf.score(X_test,Y_test)
0.9111
GBDT
from sklearn.ensemble import GradientBoostingClassifier gdbt_clf = GradientBoostingClassifier(random_state = 20) gdbt_clf.fit(X_train,Y_train) gdbt_clf.score(X_test,Y_test)
0.91772
from sklearn.model_selection import cross_val_predict y_train_pred=cross_val_predict(gdbt_clf,X_train,Y_train,cv=3)
from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt conf_mx=confusion_matrix(Y_train,y_train_pred) conf_mx plt.matshow(conf_mx,cmap=plt.cm.gray) plt.show()
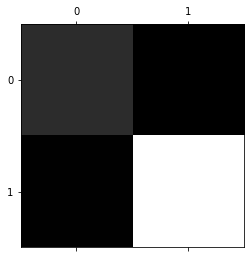
conf_mx
array([[ 8271, 1941],
[ 2098, 37690]])
SVM support vector machine classifier
from sklearn.svm import SVC svm_clf = SVC() svm_clf.fit(X_train,Y_train) svm_clf.score(X_test,Y_test)
0.80448
Ada classifier
from sklearn.ensemble import AdaBoostClassifier ada_clf = AdaBoostClassifier() ada_clf.fit(X_train,Y_train) ada_clf.score(X_test,Y_test)
0.91604
lightgbm
from lightgbm import LGBMClassifier lgbm_clf = LGBMClassifier() lgbm_clf.fit(X_train,Y_train) lgbm_clf.score(X_test,Y_test)
0.91768
XGB classifier
from xgboost import XGBClassifier #XGB classifier xgb_clf = XGBClassifier() xgb_clf.fit(X_train,Y_train) xgb_clf.score(X_test,Y_test)
0.91712
Bayesian classifier
from sklearn.naive_bayes import GaussianNB nby_clf = GaussianNB() nby_clf.fit(X_train,Y_train) nby_clf.score(X_test,Y_test)
0.90478
K-nearest neighbor classifier
from sklearn.neighbors import KNeighborsClassifier knc_clf = KNeighborsClassifier() knc_clf.fit(X_train,Y_train) knc_clf.score(X_test,Y_test)
0.84852
integrate
Voting Fusion Method
from sklearn.ensemble import VotingClassifier #Voting classifier
voting_clf = VotingClassifier(estimators=[('rf',rnd_clf ),('gdbt',gdbt_clf ),('ada',ada_clf ),('lgbm',lgbm_clf ),('xgb',xgb_clf )],#estimators: sub classifier
voting='hard') #The voting parameter represents your voting method, hard,soft
# Train the model and output the accuracy of each model
from sklearn.metrics import accuracy_score
for clf in (lr_clf,rnd_clf,svm_clf,voting_clf):
clf.fit(X_train,Y_train)
y_pre = clf.predict(X_test)
print(clf.__class__,accuracy_score(y_pre,Y_test))
Result output
<class 'sklearn.linear_model._logistic.LogisticRegression'> 0.91108 <class 'sklearn.ensemble._forest.RandomForestClassifier'> 0.9164 <class 'sklearn.svm._classes.SVC'> 0.80448 <class 'sklearn.ensemble._voting.VotingClassifier'> 0.91814
If all classifiers can estimate the class probability (that is, they all have a predict_proba() method in sklearn), then the probability average of the class can be calculated, and the voting classifier will take the class with the highest probability as its own prediction. This is called soft voting. Only two changes need to be made in the code. In the support vector machine, the parameter probability needs to be set to True to make the support vector machine have the function of predicting class probability. Voting should be set to soft in the voting classifier
#soft voting
svm_clf1 = SVC(probability=True)
voting_clf = VotingClassifier(estimators=[('lf',lr_clf),('svc',svm_clf1),('rf',rnd_clf)],
voting='soft')
for clf in (lr_clf, rnd_clf, svm_clf1, voting_clf):
clf.fit(X_train,Y_train)
y_pre = clf.predict(X_test)
print(clf.__class__,accuracy_score(y_pre,Y_test))
Output results
<class 'sklearn.linear_model._logistic.LogisticRegression'> 0.91108 <class 'sklearn.ensemble._forest.RandomForestClassifier'> 0.9164 <class 'sklearn.svm._classes.SVC'> 0.80448 <class 'sklearn.ensemble._voting.VotingClassifier'> 0.91664
Under normal circumstances, soft usually works better, but in this fusion, the effect decreases
Stacking stacking
Stacking is an integrated learning technology that uses predictions from multiple models (such as decision tree, knn or svm) to build new models. The model is used to predict the test set. The following is a step-by-step description of simple stack integration:
-
Divide the training set into 10 groups.
-
The basic model (such as decision tree) is trained with 9 groups in the training set and predicted with the 10th group.
-
Then, the basic model (such as decision tree) is fitted to the whole training data set.
-
Use this model to predict on the test set.
-
Repeat steps 2 to 4 for another basic model (such as knn) to generate another set of predictions for the training set and the test set.
-
The prediction of the training set is used as a feature for building a new model.
-
The model is used for the final prediction of the test prediction set.
from sklearn.model_selection import StratifiedKFold
def Stacking(model,train,y,test,n_fold):
folds=StratifiedKFold(n_splits=n_fold,random_state=1)
test_pred=np.empty((test.shape[0],1),float)
train_pred=np.empty((0,1),float)
for train_indices,val_indices in folds.split(train,y.values):
x_train,x_val=train.iloc[train_indices],train.iloc[val_indices]
y_train,y_val=y.iloc[train_indices],y.iloc[val_indices]
model.fit(X=x_train,y=y_train)
train_pred=np.append(train_pred,model.predict(x_val))
test_pred=np.column_stack((test_pred,model.predict(test)))
test_pred_a=np.mean(test_pred,axis=1) #Calculate average by row
return test_pred_a.reshape(-1,1),train_pred
Using gdbt and lgbm stack layer 0
x_train=train_ML.drop(columns=['loan_status']) x_test=test_ML.drop(columns=['loan_status']) y_train=train_ML['loan_status'] test_pred1 ,train_pred1=Stacking(model=gdbt_clf,n_fold=10, train=x_train,test=x_test,y=y_train) print(test_pred1.size) train_pred1=pd.DataFrame(train_pred1) test_pred1=pd.DataFrame(test_pred1) test_pred2 ,train_pred2=Stacking(model=lgbm_clf,n_fold=10,train=x_train,test=x_test,y=y_train) print(test_pred2.size) train_pred2=pd.DataFrame(train_pred2) test_pred2=pd.DataFrame(test_pred2)
The first layer of random forest pile is adopted
dff = pd.concat([train_pred1, train_pred2], axis=1) dff_test = pd.concat([test_pred1, test_pred2], axis=1) rnd_clf.fit(dff,y_train) rnd_clf.score(dff_test, Y_test)
0.91798
stacking mixing
Mixing follows the same method as stacking, but only the reserved / (validation) set from the training set is used for prediction. In other words, unlike stacking, prediction occurs only on the reserved set. The reserved set and its prediction are used to build the model, and the model is tested with the test set. The following is a detailed description of the mixing process:
-
The original training set is divided into training set and verification set.
-
Fit the model to the training set.
-
Predictions are made on validation sets and test sets.
-
Validation sets and their predictions are used as features for building new models.
-
The model is used for the final prediction of test sets and meta features.
Same order
gdbt and lgbm are used first
Then random forest
x_train=train_ML.drop(columns=['loan_status']) x_test=test_ML.drop(columns=['loan_status']) y_train=train_ML['loan_status'] val_pred1 = gdbt_clf.predict(x_train) test_pred1 = gdbt_clf.predict(x_test) val_pred1 = pd.DataFrame(val_pred1) test_pred1 = pd.DataFrame(test_pred1) val_pred2 = lgbm_clf.predict(x_train) test_pred2 = lgbm_clf.predict(x_test) val_pred2 = pd.DataFrame(val_pred2) test_pred2 = pd.DataFrame(test_pred2) df2_val = pd.concat([x_train,val_pred1,val_pred2],axis = 1) df2_test = pd.concat([x_test,test_pred1,test_pred2],axis = 1) rnd_clf.fit(df2_val,y_train) rnd_clf.score(df2_test,Y_test)
0.91668
Deep learning network
DNN
Data preparation
train_DL = df_train.copy() test_DL = df_test.copy() train_DL.fillna(0,inplace=True) test_DL.fillna(0,inplace=True) X_train = train_DL.drop(columns=['loan_status']).values Y_train = train_DL['loan_status'].values.astype(int) X_test = test_DL.drop(columns=['loan_status']).values Y_test = test_DL['loan_status'].values.astype(int) from tensorflow.keras.utils import to_categorical Y_test=to_categorical(Y_test,2).astype(int) Y_train=to_categorical(Y_train,2).astype(int)
Build network
import keras as K from keras.layers.core import Dropout init = K.initializers.glorot_uniform(seed=1) model = K.models.Sequential() model.add(K.layers.Dense(units=146, input_dim=145, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=147, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=2, kernel_initializer=init, activation='softmax')) model.compile(loss='categorical_crossentropy', metrics=['accuracy'])
b_size = 128
max_epochs = 100
print("Starting training ")
h = model.fit(X_train, Y_train, batch_size=b_size, epochs=max_epochs, shuffle=True, verbose=1)
print("Training finished \n")
test result
eval = model.evaluate(X_test, Y_test, verbose=0)
print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" \
% (eval[0], eval[1] * 100) )
Evaluation on test data: loss = 0.244760 accuracy = 90.52%
Deep learning network DNN+trick (adam)
Data preparation
train_DL = df_train.copy() test_DL = df_test.copy()
train_DL.fillna(0,inplace=True) test_DL.fillna(0,inplace=True) X_train = train_DL.drop(columns=['loan_status']).values Y_train = train_DL['loan_status'].values.astype(int) X_test = test_DL.drop(columns=['loan_status']).values Y_test = test_DL['loan_status'].values.astype(int) from tensorflow.keras.utils import to_categorical Y_test=to_categorical(Y_test,2).astype(int) Y_train=to_categorical(Y_train,2).astype(int)
Build network
import keras as K from keras.layers.core import Dropout init = K.initializers.glorot_uniform(seed=1) simple_adam = K.optimizers.Adam()#trick added adam for model = K.models.Sequential() model.add(K.layers.Dense(units=146, input_dim=145, kernel_initializer=init, activation='relu')) # model.add(Dropout(0.1))#The effect of using dropout is not good model.add(K.layers.Dense(units=147, kernel_initializer=init, activation='relu')) # model.add(Dropout(0.9)) model.add(K.layers.Dense(units=2, kernel_initializer=init, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=simple_adam, metrics=['accuracy'])
b_size = 128
max_epochs = 100
print("Starting training ")
h = model.fit(X_train, Y_train, batch_size=b_size, epochs=max_epochs, shuffle=True, verbose=1)
print("Training finished \n")
test result
eval = model.evaluate(X_test, Y_test, verbose=0)
print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" \
% (eval[0], eval[1] * 100) )
Evaluation on test data: loss = 0.214410 accuracy = 91.21%
Deep learning network DNN+trick (SGD)
Data preparation
train_DL = df_train.copy() test_DL = df_test.copy()
train_DL.fillna(0,inplace=True) test_DL.fillna(0,inplace=True) X_train = train_DL.drop(columns=['loan_status']).values Y_train = train_DL['loan_status'].values.astype(int) X_test = test_DL.drop(columns=['loan_status']).values Y_test = test_DL['loan_status'].values.astype(int) from tensorflow.keras.utils import to_categorical Y_test=to_categorical(Y_test,2).astype(int) Y_train=to_categorical(Y_train,2).astype(int)
Build network
import keras as K from keras.layers.core import Dropout init = K.initializers.glorot_uniform(seed=1) simple_adam = K.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)#trick added RMSprop for model = K.models.Sequential() model.add(K.layers.Dense(units=146, input_dim=145, kernel_initializer=init, activation='relu')) # model.add(Dropout(0.1))#The effect of using dropout is not good model.add(K.layers.Dense(units=147, kernel_initializer=init, activation='relu')) # model.add(Dropout(0.9)) model.add(K.layers.Dense(units=2, kernel_initializer=init, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=simple_adam, metrics=['accuracy'])
b_size = 128
max_epochs = 100
print("Starting training ")
h = model.fit(X_train, Y_train, batch_size=b_size, epochs=max_epochs, shuffle=True, verbose=1)
print("Training finished \n")
test result
eval = model.evaluate(X_test, Y_test, verbose=0)
print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" \
% (eval[0], eval[1] * 100) )
Evaluation on test data: loss = 0.237782 accuracy = 91.39%
TabNet
Environment import
pip install pytorch-tabnet
Data preparation
train_DL = df_train.copy() test_DL = df_test.copy()
train_DL.fillna(0,inplace=True) test_DL.fillna(0,inplace=True) X_train = train_DL.drop(columns=['loan_status']).values Y_train = train_DL['loan_status'].values.astype(int) X_test = test_DL.drop(columns=['loan_status']).values Y_test = test_DL['loan_status'].values.astype(int)
Build network
from pytorch_tabnet.tab_model import TabNetClassifier, TabNetRegressor clf = TabNetClassifier() #TabNetRegressor() clf.fit( X_train, Y_train ) preds = clf.predict(X_test)
test result
accuracy_score(Y_test,preds)
0.9115
Deep learning network integrated machine learning
Stacking integrated DNN
train_DL = df_train.copy() test_DL = df_test.copy() train_DL.fillna(0,inplace=True) test_DL.fillna(0,inplace=True) X_train = train_DL.drop(columns=['loan_status']).values Y_train = train_DL['loan_status'].values.astype(int) X_test = test_DL.drop(columns=['loan_status']).values Y_test = test_DL['loan_status'].values.astype(int) from tensorflow.keras.utils import to_categorical Y_test=to_categorical(Y_test,2).astype(int) Y_train=to_categorical(Y_train,2).astype(int)
import keras as K from keras.layers.core import Dropout init = K.initializers.glorot_uniform(seed=1) model = K.models.Sequential() model.add(K.layers.Dense(units=146, input_dim=2, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=147, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=2, kernel_initializer=init, activation='softmax')) model.compile(loss='categorical_crossentropy', metrics=['accuracy'])
x_train=train_ML.drop(columns=['loan_status']) x_test=test_ML.drop(columns=['loan_status']) y_train=train_ML['loan_status'] test_pred1 ,train_pred1=Stacking(model=gdbt_clf,n_fold=10, train=x_train,test=x_test,y=y_train) print(test_pred1.size) train_pred1=pd.DataFrame(train_pred1) test_pred1=pd.DataFrame(test_pred1) test_pred2 ,train_pred2=Stacking(model=lgbm_clf,n_fold=10,train=x_train,test=x_test,y=y_train) print(test_pred2.size) train_pred2=pd.DataFrame(train_pred2) test_pred2=pd.DataFrame(test_pred2)
dff = pd.concat([train_pred1, train_pred2], axis=1)
dff_test = pd.concat([test_pred1, test_pred2], axis=1)
model.fit(dff,y_train)
eval = model.evaluate(dff_test, Y_test, verbose=0)
print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" \
% (eval[0], eval[1] * 100) )
result
1563/1563 [==============================] - 4s 2ms/step - loss: 0.2892 - accuracy: 0.9029 Evaluation on test data: loss = 0.261336 accuracy = 91.83%