Catalog
Features and usage scenarios of XML
Features and usage scenarios of XML
- One is plain text, which uses UTF-8 encoding by default. Can be nested;
- If you save the XML content as a file, it is an XML file
- Scenarios for using XML: XML content is often used for network transmission as a message or as a configuration file to store system information.
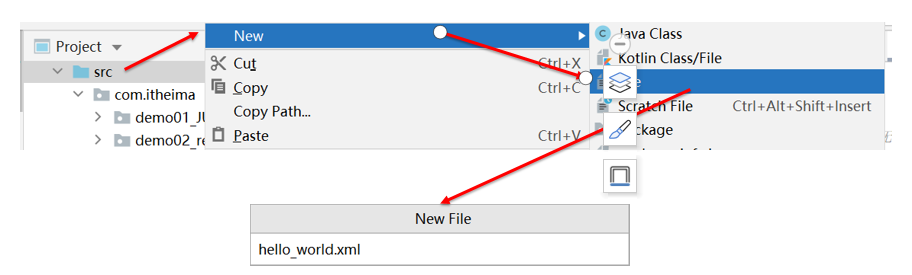
Creation of an XML file
Creating an XML file requires that the suffix of the file be xml, such as hello_world.xml
Syntax rules for XML:
The suffix name of the xml file is:. xml
First line of document declaration required
<?xml version="1.0" encoding="UTF-8" ?>
Version: The default version number of the XML, this property must exist
encoding: encoding of this XML file
Labeling rules for XML:
- A tag consists of a pair of angle brackets and legal identities: <name></name>, there must be one root tag, one and only one
- Labels must exist in pairs, start again, end
- Special tags can be mismatched, but must have an end tag <br/>
- Tags can define attributes separated by attributes and tag name spaces. Attribute values must be quoted: <studengt id = "1"></name>
- Labels need to be nested correctly
<student id="1">
<name>Zhang San</name>
</student>
Other components of XML
- Annotation information can be defined in an XML file: <!- Comment Content-->
- The following special words can exist in an XML file
< < Less than
> > greater than
& Ampersand sign
' 'Single quotation marks
" "Quotes"
What are document constraints
Document Constraints: Used to limit how tags and attributes in an xml file are written.
Classification of document constraints
DTD
schema
XML Document Constraints - Use of DTD s (Understanding)
Requirements: Constrain the writing of an XML file using DTD document constraints
Analysis:
1. Write dtd constraint documentation with a suffix of. dtd
2. Import the DTD constraint document into the XML file you need to write
3. Write the contents of an XML file as required by the constraints
XML Document Constraints - Use of schema (Understanding)
1. Schemas can constrain specific data types and are more constrained.
2. The schema itself is also an xml file and is required by other constraints, so write it more carefully
Requirements: Constrain the writing of an XML file using schema file constraints
Analysis:
1. Write a schema constraint document with a suffix of. xsd, see it in code
2. Import the schema constraint document into the XML file you need to write
3. Write tags for XML files based on Constraints
XML VS HTML
Both are products of the w3c organization whose primary function is storage and data transfer
* HTML is now widely used on the web
* Fixed and semantical labels (label names cannot be customized)
Improper grammar (no header tags will do no harm)
* XML is now widely used in data configuration
Completely customized labels (unlike HTTP)
* Very strict grammar
What is XML parsing
Using programs to read data in XML
Two ways of parsing
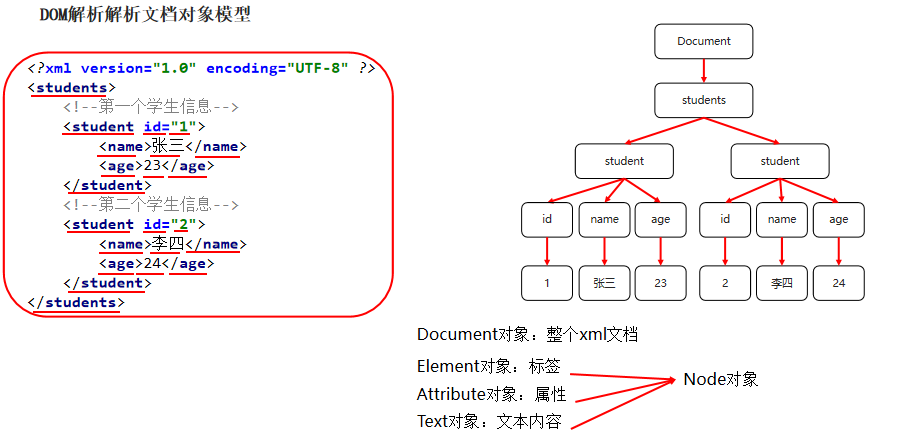
DOM Resolution
* SAX parsing
- DOM Resolution
- Generating a DOM (document) tree when parsing XML allows us to access and modify the contents of the tree arbitrarily
- Disadvantages: If there are too many contents or levels in the document, the larger the tree generated and the higher the memory usage
- Advantages: Any access and modification (can be added or deleted)
- SAX parsing
- For DOM parsing, it is a faster and more efficient way to parse, mainly using tree traversal algorithm for node access. Where do you need to go, you just need to traverse the nodes on the path.
- Disadvantages: Do not know the full extent of the spanning tree, all can not be added or deleted (read while parsing, not sure if there are elements below)
- Advantages: faster, more efficient, less memory
Common parsing tools for DOM

Parsing XML files using Dom4J
Requirement: Use Dom4J to parse data from an XMl file
Analysis:
- Download Dom4J Framework, Official Download ( dom4j ), download. jar file
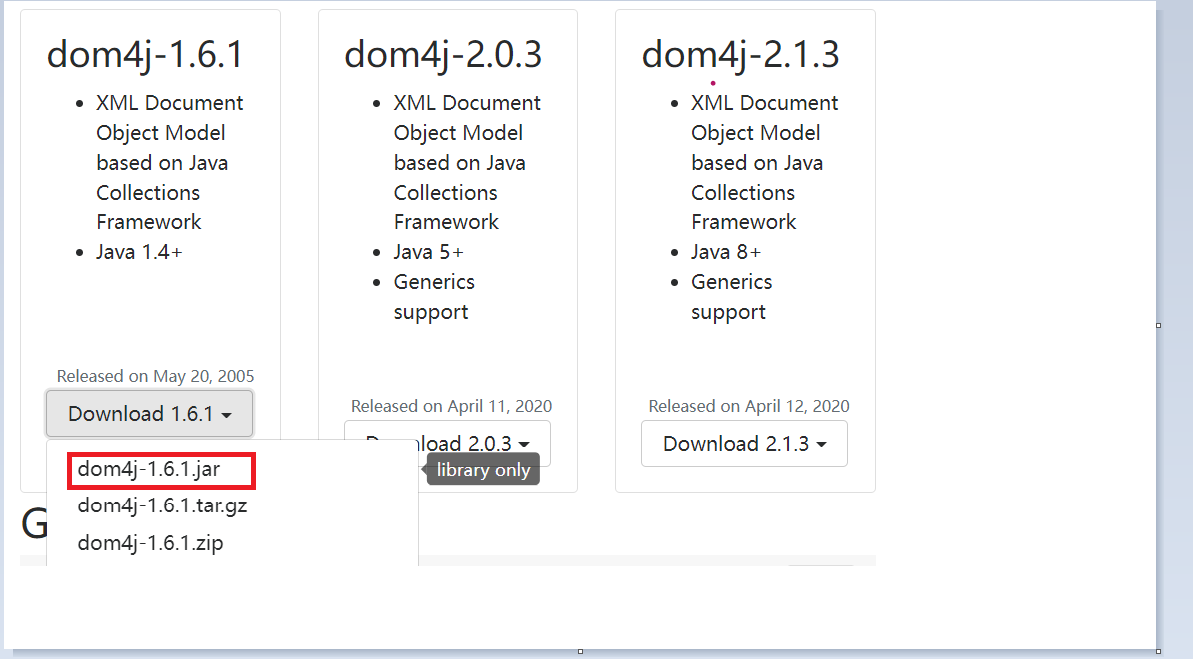
- Create a file in the project plus: lib

- Will dom4j-2.1.1.jar file copied to lib file
- Right-click on the jar file, select Build Path ->click Add path...
- Import package use in class
Dom4J parses the XML - gets the Document object
SAXReader class
| Construction method | Explain |
| public SAXReader() | Create parser object for Dom4J |
| Document read(String url) | Loading an XML file into a Document object |
Document class
| Method Name | Explain |
| Element getRootElement() | Get the root element object |
Common methods in Dom4J
| Method Name | Explain |
| List<Element> elements() | Get all the elements under the current element |
| List<Element> elements(String name) | Returns a collection of child elements with the specified name under the current element |
| Element elements(String name) | Gets the child element with the specified name under the current element, and returns the first one if there are many children with the same name |
| String getName() | Get the element name |
| String attributeValue(String name) | Get the attribute value directly from the attribute name |
| String elementText (child element name) | Gets the text of the child element with the specified name |
| String getText() | To text |
Code demonstration:
Create an xml file in the project
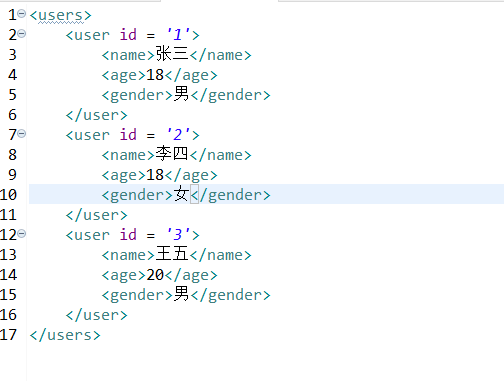
Parse Code:
import java.io.File;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4JDemo {
public static void main(String[] args) throws DocumentException {
//Create DOM4J Parser Object
SAXReader reader = new SAXReader();
//Pass in an xml file to the interpreter object that needs to be parsed
//document is the object of the xml file
Document document = reader.read(new File("users.xml"));
//Get the root node element in the xml file
Element root = document.getRootElement(); //Here root node root=users
//Get all under the root element
List<Element> elements = root.elements();
//Traversing elements in a node
for (Element element1 : elements) {
//Elements that traverse each node
// System.out.println(element.asXML());
//Gets the list of properties of the current node Output: id:1 id:2 id:3
List<Attribute> att = element1.attributes();
// for (Attribute attbu : att) {
// System.out.println(attbu.getName() + ":" + attbu.getValue());
// }
//Gets the specified property value
System.out.println("id"+":" + element1.attributeValue("id"));
//Get all child elements
List<Element> ele = element1.elements();
for (Element elet : ele) {
System.out.println(elet.getName() + ":" + elet.getText());
}
System.out.println("==========");
//Gets the specified element
System.out.println("name" + ":" + element1.element("name").getText());
}
}
}
There are many results to run, which is not shown here. Friends of interest can run the following on their own.
JSOUP parsing
Features of jsoup parsing:
Not only can xml be parsed, but html can also be parsed
Get our elements by name
-
Download JSOUP framework, download address ( jsoup: Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety)
- The rest of the installation steps are the same as xDmo4J
- Put it in the lib file of the project
Resolve using JSOUP:
Code directly:
import java.io.File;
import java.io.IOException;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.jsoup.Jsoup;
public class JSOUPTest {
public static void main(String[] args) throws IOException {
//1. Get the document object for the xml file
//Note: The Document class imports ORG here. Jsoup. Nodes. Document, dare not import under Dom4J package
Document document = Jsoup.parse(new File("users.xml"), "utf-8");
//Getting a single tag element object can only be obtained through the id attribute In xml/html, each tag can define the id attribute but the value cannot be the same
// Element elementById = document.getElementById("1");
// //Print out all the contents of the label with id of "1" (including the contents of sublabels)
// System.out.println(elementById);
//Getting all the label objects named user elementsByTag is essentially a list
Elements elementsByTag = document.getElementsByTag("user");
//Print all elements under user's label label, two ways to get them
//1. Consider elementsByTag as a list traversal output
// for (Element element : elementsByTag) {
// System.out.println(element);
// }
//2. Direct Output
System.out.println(elementsByTag);
}
}