Task description
There are 101227 rows of data to be processed in this task. An example is as follows:
18 Jogging 102271561469000 -13.53 16.89 -6.4 18 Jogging 102271641608000 -5.75 16.89 -0.46 18 Jogging 102271681617000 -2.18 16.32 11.07 18 Jogging 3.36 18 Downstairs 103260201636000 -4.44 7.06 1.95 18 Downstairs 103260241614000 -3.87 7.55 3.3 18 Downstairs 103260321693000 -4.06 8.08 4.79 18 Downstairs 103260365577000 -6.32 8.66 4.94 18 Downstairs 103260403083000 -5.37 11.22 3.06 18 Downstairs 103260443305000 -5.79 9.92 2.53 6 Walking 0 0 0 3.214402
Step 1
Delete all rows with abnormal information in the dataset.
For example, in the above example, the data in line 4 has only three elements, while other lines have six elements, so line 4 is the line with abnormal information. Delete it. For another example, the third element of the 12th row of data is obviously problematic, so it is also a row with abnormal information. Delete it.
There may be some other exceptions in the dataset.
After all the information is processed, the elements of each line are written to the file test1 with commas as as separators.
The file test1 has 100471 lines in total. The example is as follows:
6,Walking,23445542281000,-0.72,9.62,0.14982383 6,Walking,23445592299000,-4.02,11.03,3.445948 6,Walking,23470662276000,0.95,14.71,3.636633 ...
Step 2
Count the number of all actions in the data of file test1 and print it to the screen, then round the number of actions to 100 and write it to test2 file, and discard the redundant information lines. For example, if the number of Jogging is counted as 3021 times, print Movement: Jogging Amount: 3021 on the screen, and then write the first 3000 lines of information into the test2 file.
The file test2 has 100200 lines in total.
Step 3
Read the data of the file test2, take the last three column elements of each line, and write the file test3 with a space as a separator.
The file test3 has 100200 lines in total. The example is as follows:
-0.72 9.62 0.14982383 -4.02 11.03 3.445948 0.95 14.71 3.636633 ...
Step 4
Read the data of file test3, each line of data is a group, the elements in each group are separated by spaces, the data between groups are separated by commas, and every 20 groups of elements are a line, which is written to the file finally.
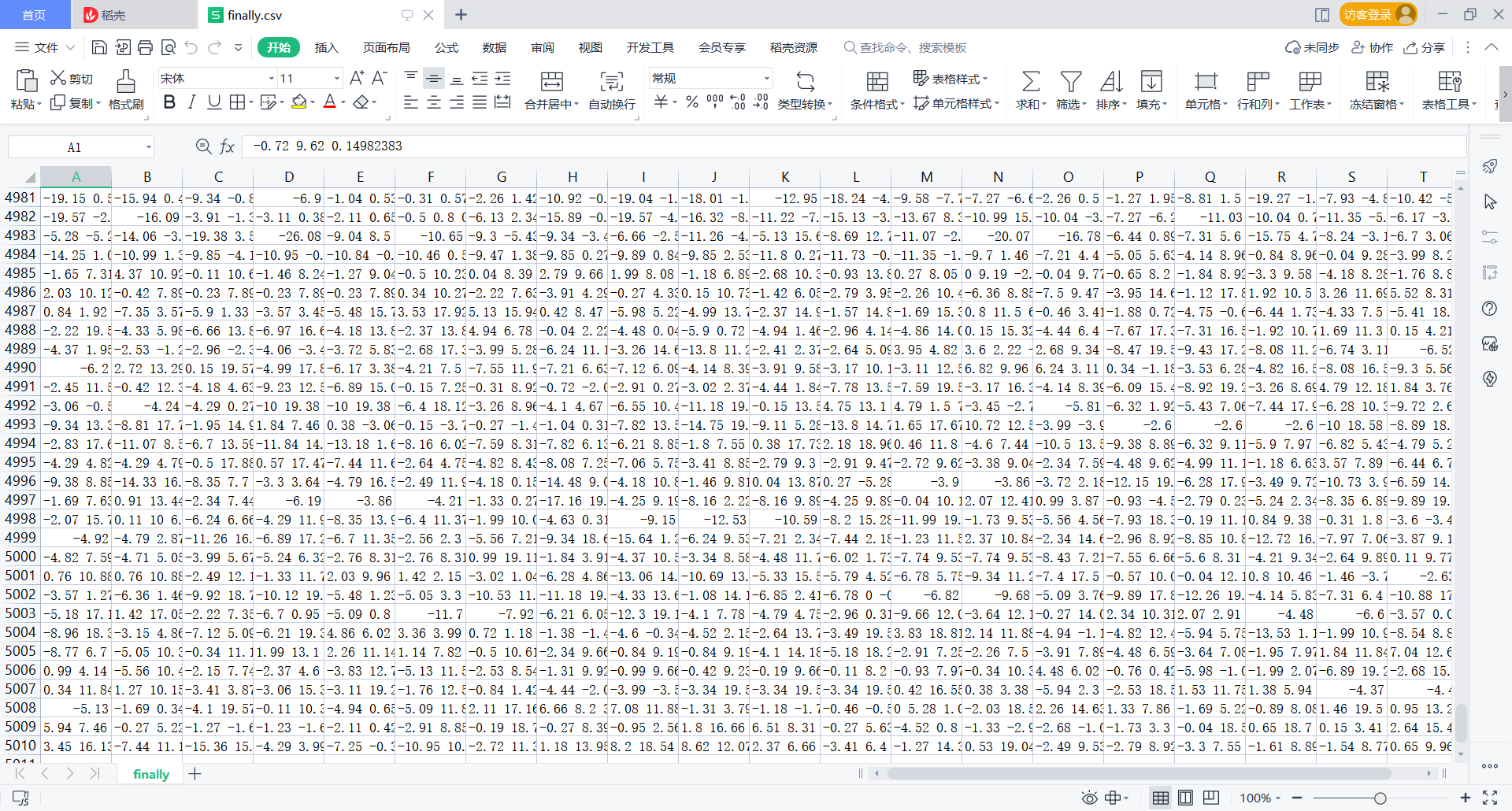
finally, there are 5010 lines in the file. The example is as follows:
-0.72 9.62 0.14982383,-4.02 11.03 3.445948,0.95 14.71 3.636633,-3.57 5.75 -5.407278,-5.28 8.85 -9.615966,-1.14 15.02 -3.8681788,7.86 11.22 -1.879608,6.28 4.9 -2.3018389,0.95 7.06 -3.445948,-1.61 9.7 0.23154591,6.44 12.18 -0.7627395,5.83 12.07 -0.53119355,7.21 12.41 0.3405087,6.17 12.53 -6.701211,-1.08 17.54 -6.701211,-1.69 16.78 3.214402,-2.3 8.12 -3.486809,-2.91 0 -4.7535014,-2.91 0 -4.7535014,-4.44 1.84 -2.8330324
Acceptance content
-
4 * py file
- test1.py
- test2.py
- test3.py
- finally.py
-
4 files generated after running Python script
- test1
- test2
- test3
- finally
1. Change the data file type to CSV file
Create a new csv file, replace the spaces in the original file with commas, and then write to the new csv file
The code is as follows:
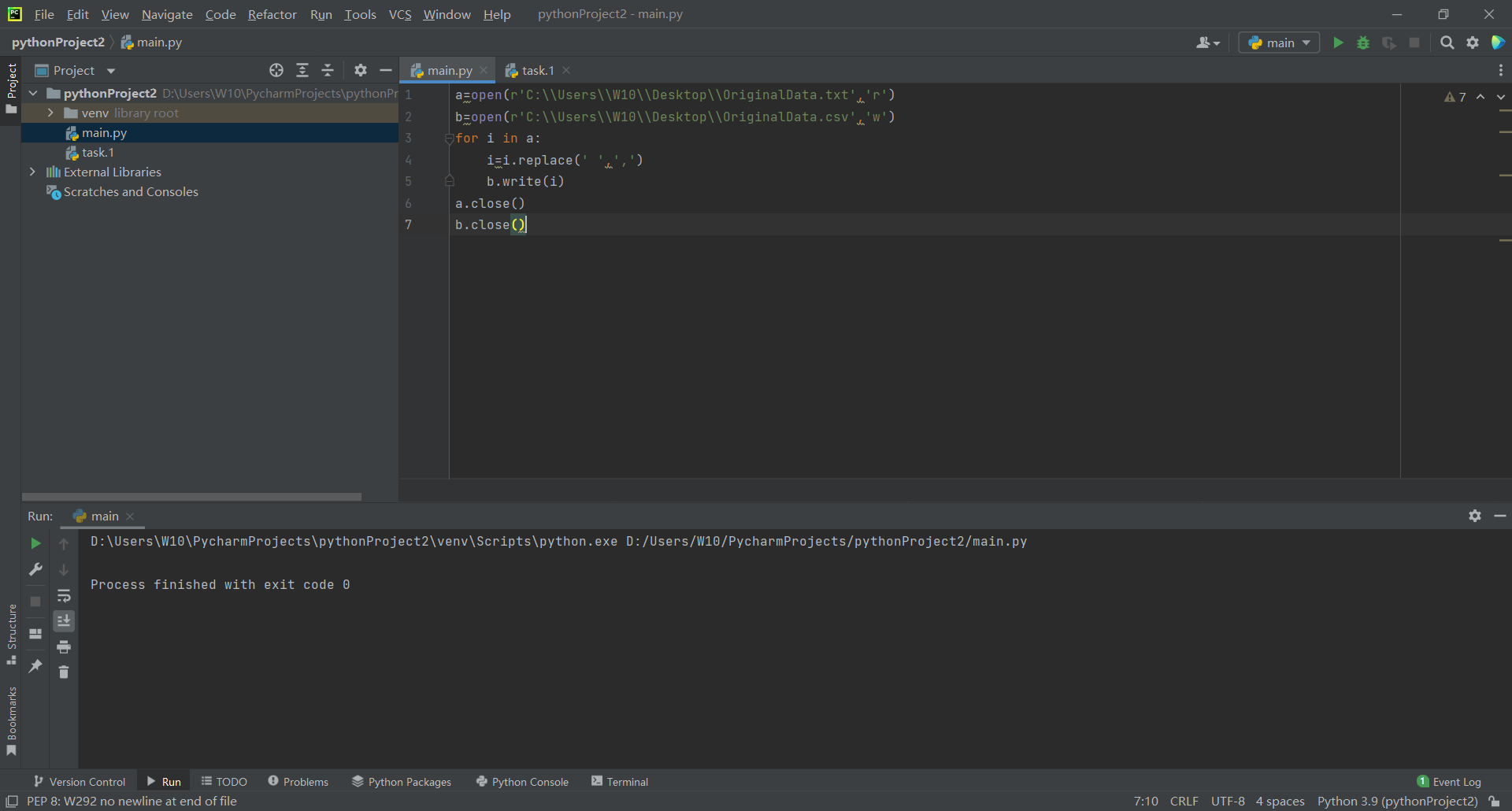
a=open(r'C:\\Users\\W10\\Desktop\\OriginalData.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\OriginalData.csv','w')
for i in a:
i=i.replace(' ',',')
b.write(i)
a.close()
b.close()
 Then the csv file will look like this
Then the csv file will look like this
2.test1
Here, we can put each element in each line of the original file into the list to see whether the length of the list is 6 and whether the third element of the list is' 0 '. If the length is 6 and the third element is not' 0 ', the line information is normal, and there is the following code:
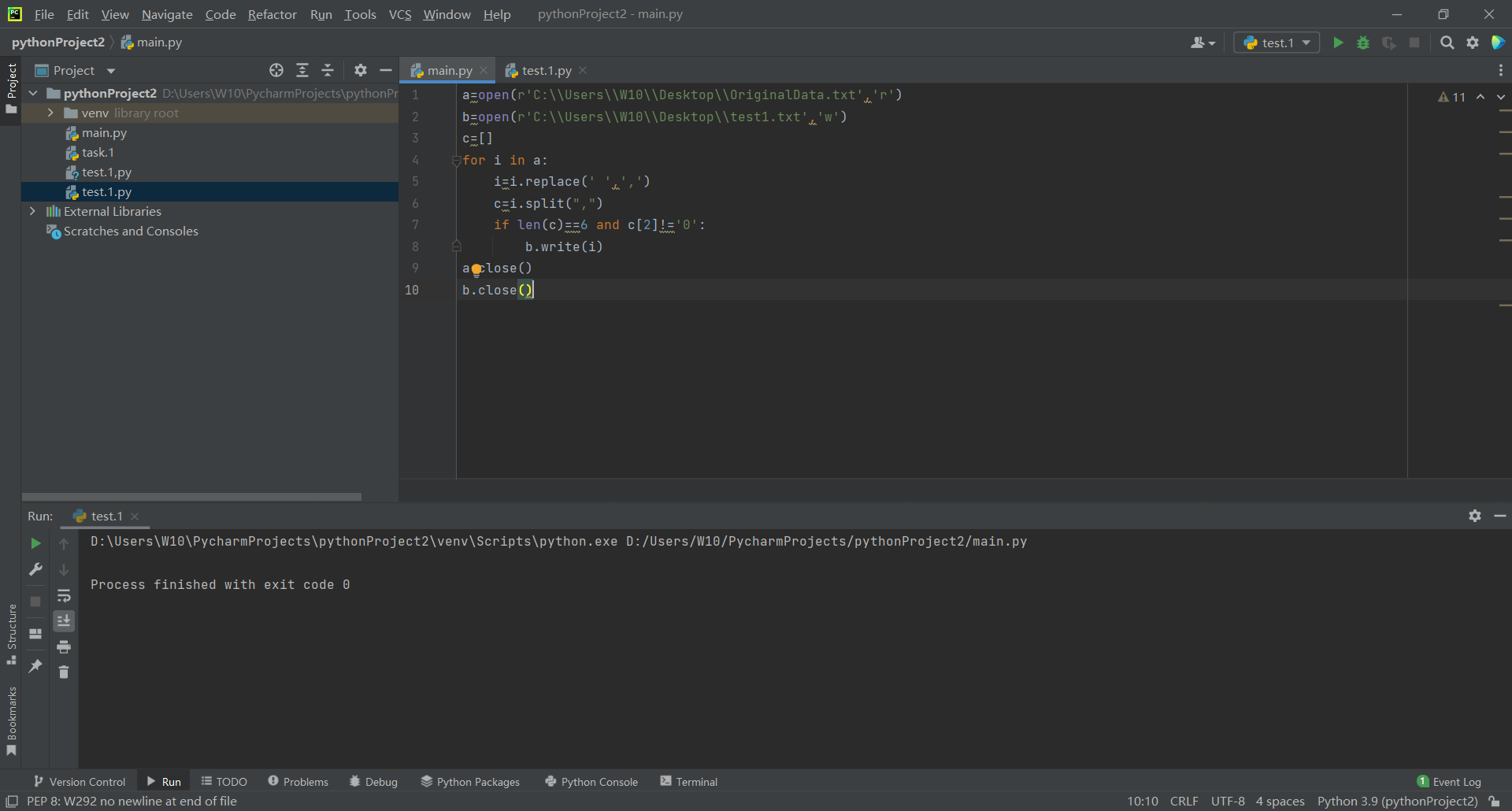
a=open(r'C:\\Users\\W10\\Desktop\\OriginalData.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\test1.txt','w')
c=[]
for i in a:
i=i.replace(' ',',')
c=i.split(",")
if len(c)==6 and c[2]!='0':
b.write(i)
a.close()
b.close()
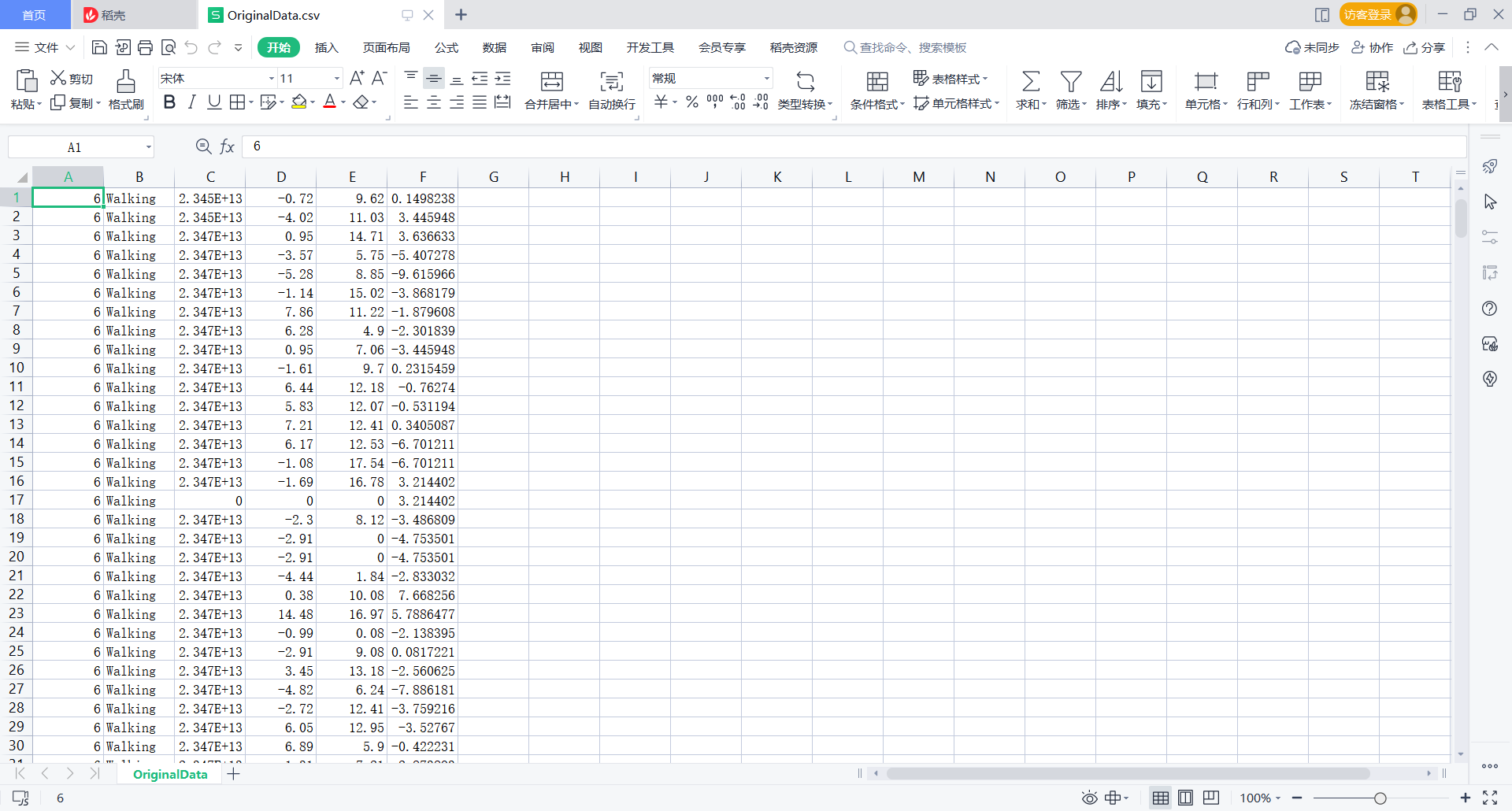
 Then there is the following test1 txt
Then there is the following test1 txt
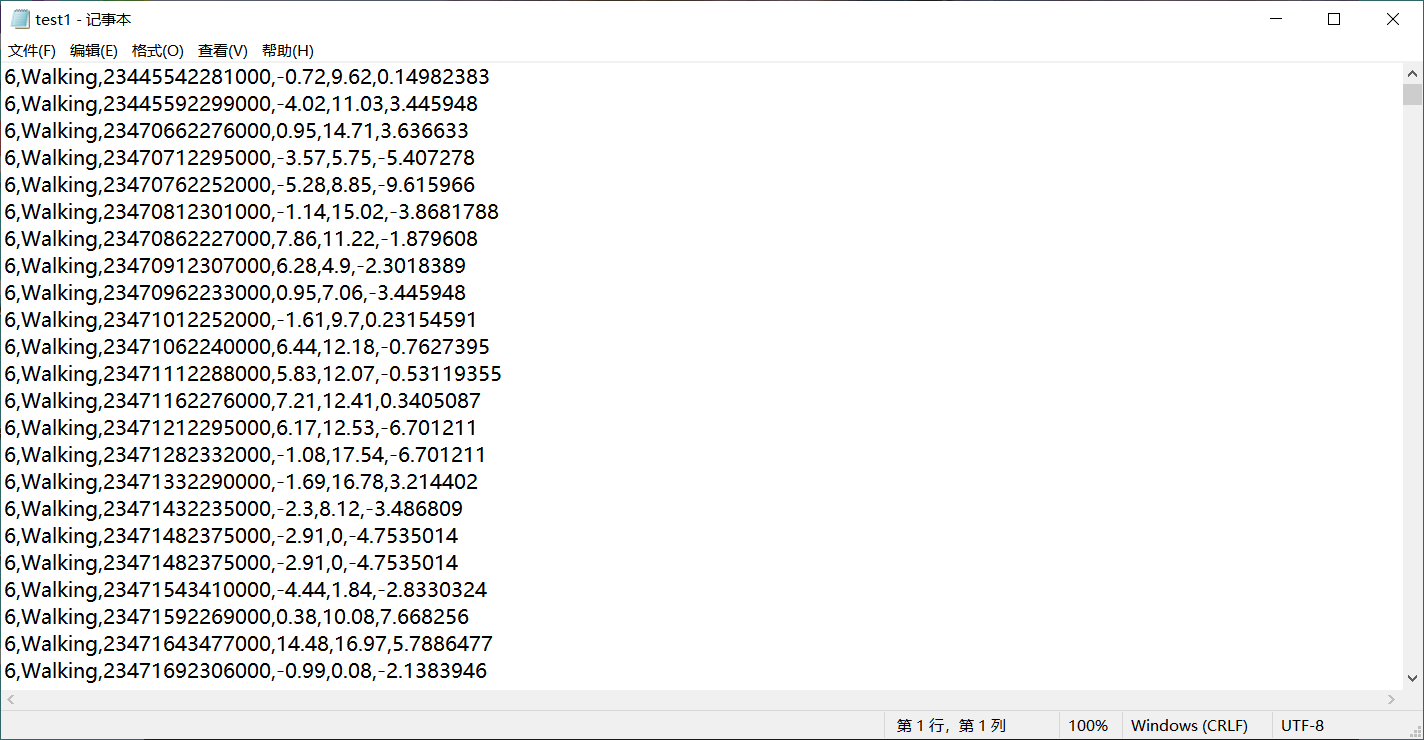 If test1 is required to be csv type, the following code can be used:
If test1 is required to be csv type, the following code can be used:
a=open(r'C:\\Users\\W10\\Desktop\\OriginalData.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\test1.csv','w')
c=[]
for i in a:
i=i.replace(' ',',')
c=i.split(",")
if len(c)==6 and c[2]!='0':
b.write(i)
a.close()
b.close()
Get Text1 CSV is as follows:
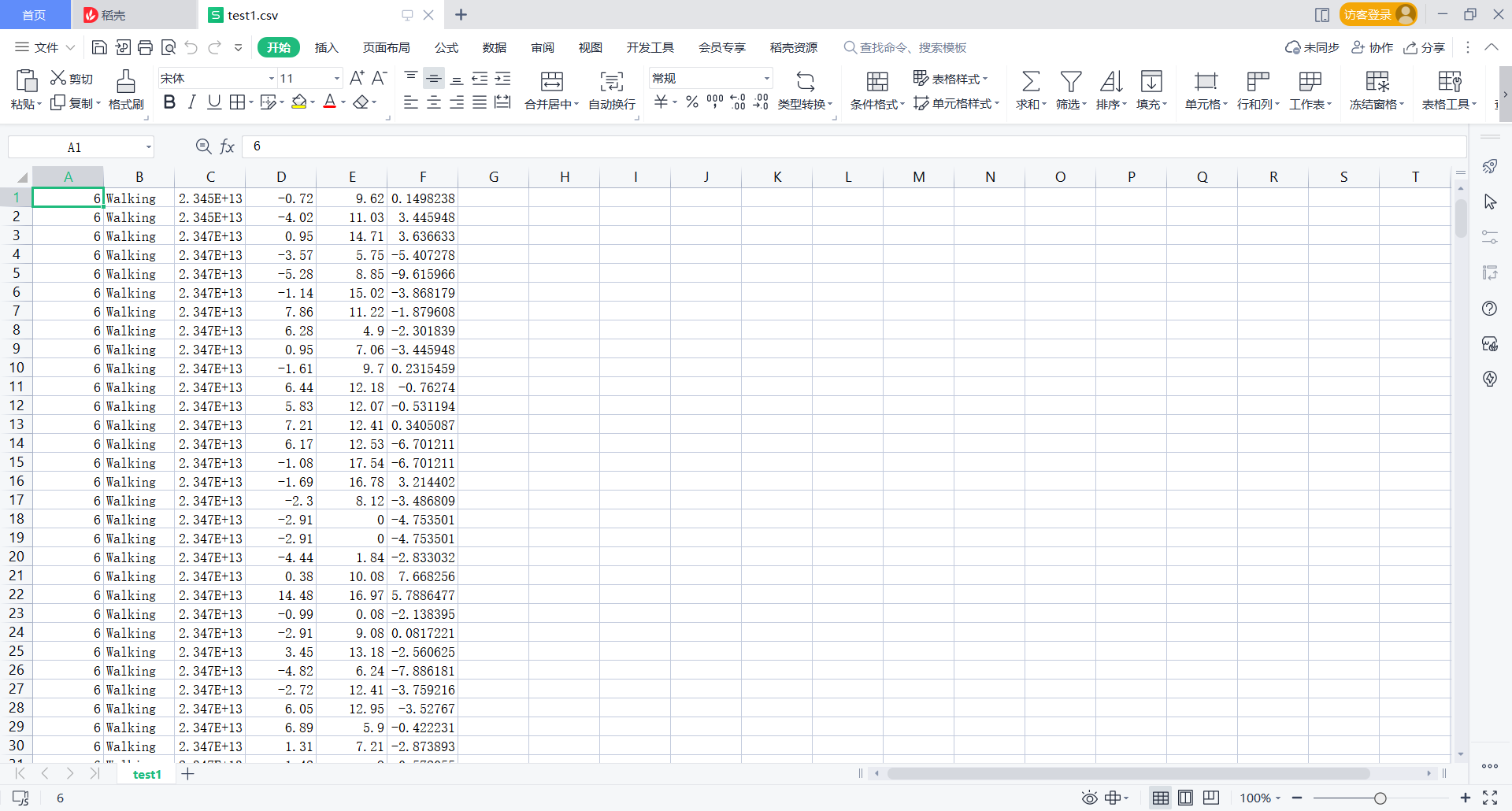
3.test2
It's a little more complicated here
I used the following code:
a=open(r'C:\\Users\\W10\\Desktop\\test1.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\test2.txt','w')
c=[]
w=0
j=0
s=0
x=0
u=0
d=0
w2=[]
j2=[]
s2=[]
x2=[]
u2=[]
d2=[]
for i in a:
c=i.split(',')
if c[1]=='Walking':
w+=1
w2.append(i)
if c[1]=='Jogging':
j+=1
j2.append(i)
if c[1]=='Standing':
s+=1
s2.append(i)
if c[1]=='Sitting':
x2.append(i)
x+=1
if c[1]=='Upstairs':
u2.append(i)
u+=1
if c[1]=='Downstairs':
d+=1
d2.append(i)
print("Movement: Walking Amount:%d"%w)
print("Movement: Jogging Amount:%d"%j)
print("Movement: Standing Amount:%d"%s)
print("Movement: Sitting Amount:%d"%x)
print("Movement: Upstairs Amount:%d"%u)
print("Movement: Downstairs Amount:%d"%d)
w1=w-w%100
j1=j-j%100
s1=s-s%100
x1=x-x%100
u1=u-u%100
d1=d-d%100
for i in range(w1):
b.write(w2[i])
for i in range(j1):
b.write(j2[i])
for i in range(s1):
b.write(s2[i])
for i in range(x1):
b.write(x2[i])
for i in range(u1):
b.write(u2[i])
for i in range(d1):
b.write(d2[i])
b.close()
a.close()
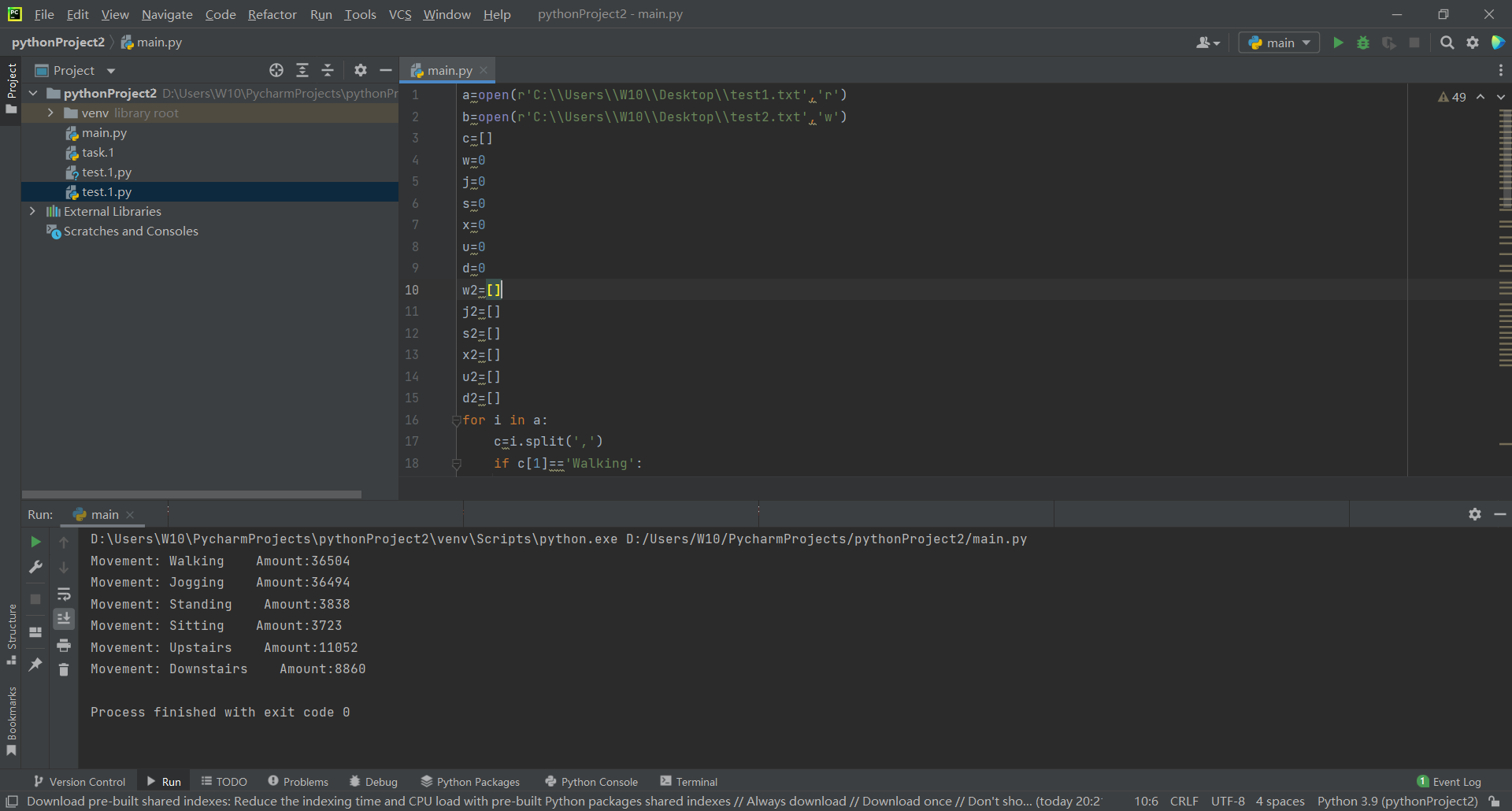 Then there is the following test2 txt
Then there is the following test2 txt
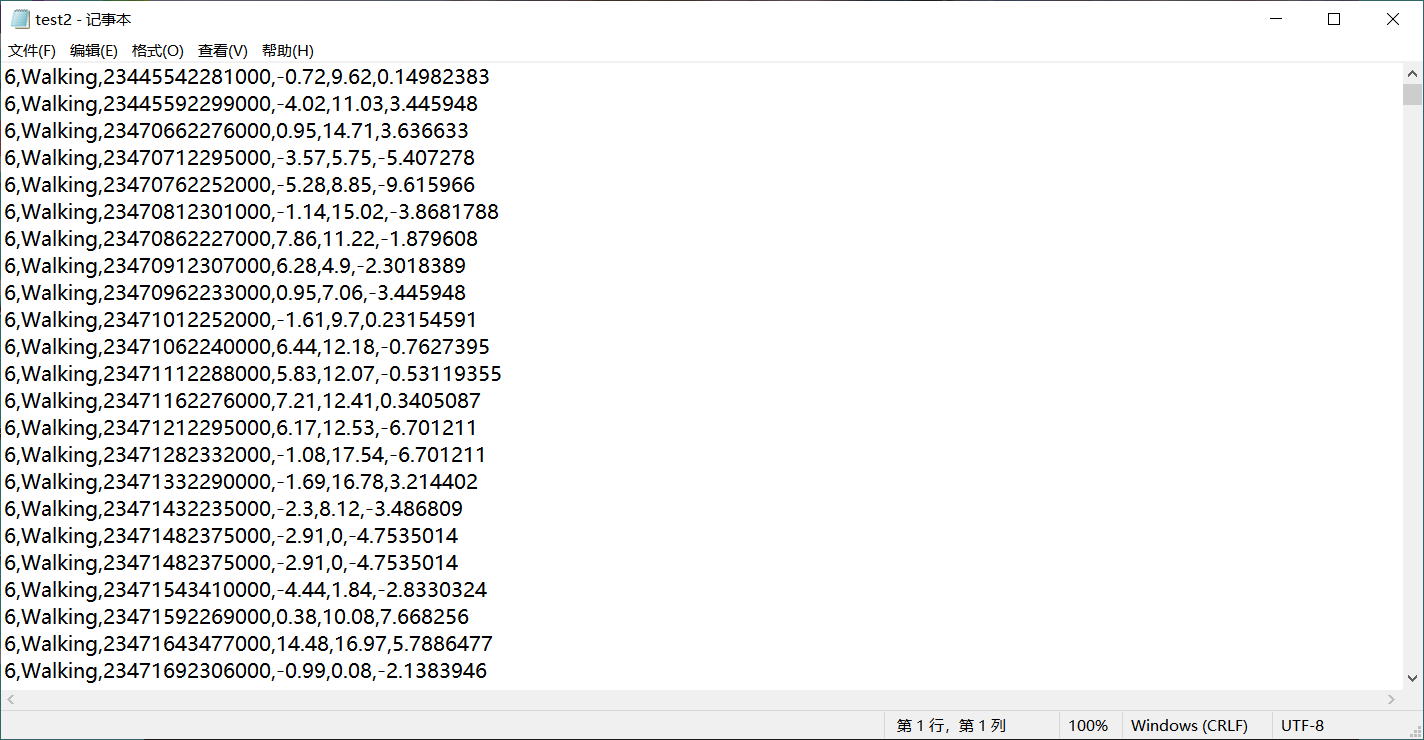 If test2 is required to be csv type, the following code can be used:
If test2 is required to be csv type, the following code can be used:
a=open(r'C:\\Users\\W10\\Desktop\\test1.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\test2.csv','w')
c=[]
w=0
j=0
s=0
x=0
u=0
d=0
w2=[]
j2=[]
s2=[]
x2=[]
u2=[]
d2=[]
for i in a:
c=i.split(',')
if c[1]=='Walking':
w+=1
w2.append(i)
if c[1]=='Jogging':
j+=1
j2.append(i)
if c[1]=='Standing':
s+=1
s2.append(i)
if c[1]=='Sitting':
x2.append(i)
x+=1
if c[1]=='Upstairs':
u2.append(i)
u+=1
if c[1]=='Downstairs':
d+=1
d2.append(i)
print("Movement: Walking Amount:%d"%w)
print("Movement: Jogging Amount:%d"%j)
print("Movement: Standing Amount:%d"%s)
print("Movement: Sitting Amount:%d"%x)
print("Movement: Upstairs Amount:%d"%u)
print("Movement: Downstairs Amount:%d"%d)
w1=w-w%100
j1=j-j%100
s1=s-s%100
x1=x-x%100
u1=u-u%100
d1=d-d%100
for i in range(w1):
b.write(w2[i])
for i in range(j1):
b.write(j2[i])
for i in range(s1):
b.write(s2[i])
for i in range(x1):
b.write(x2[i])
for i in range(u1):
b.write(u2[i])
for i in range(d1):
b.write(d2[i])
b.close()
a.close()
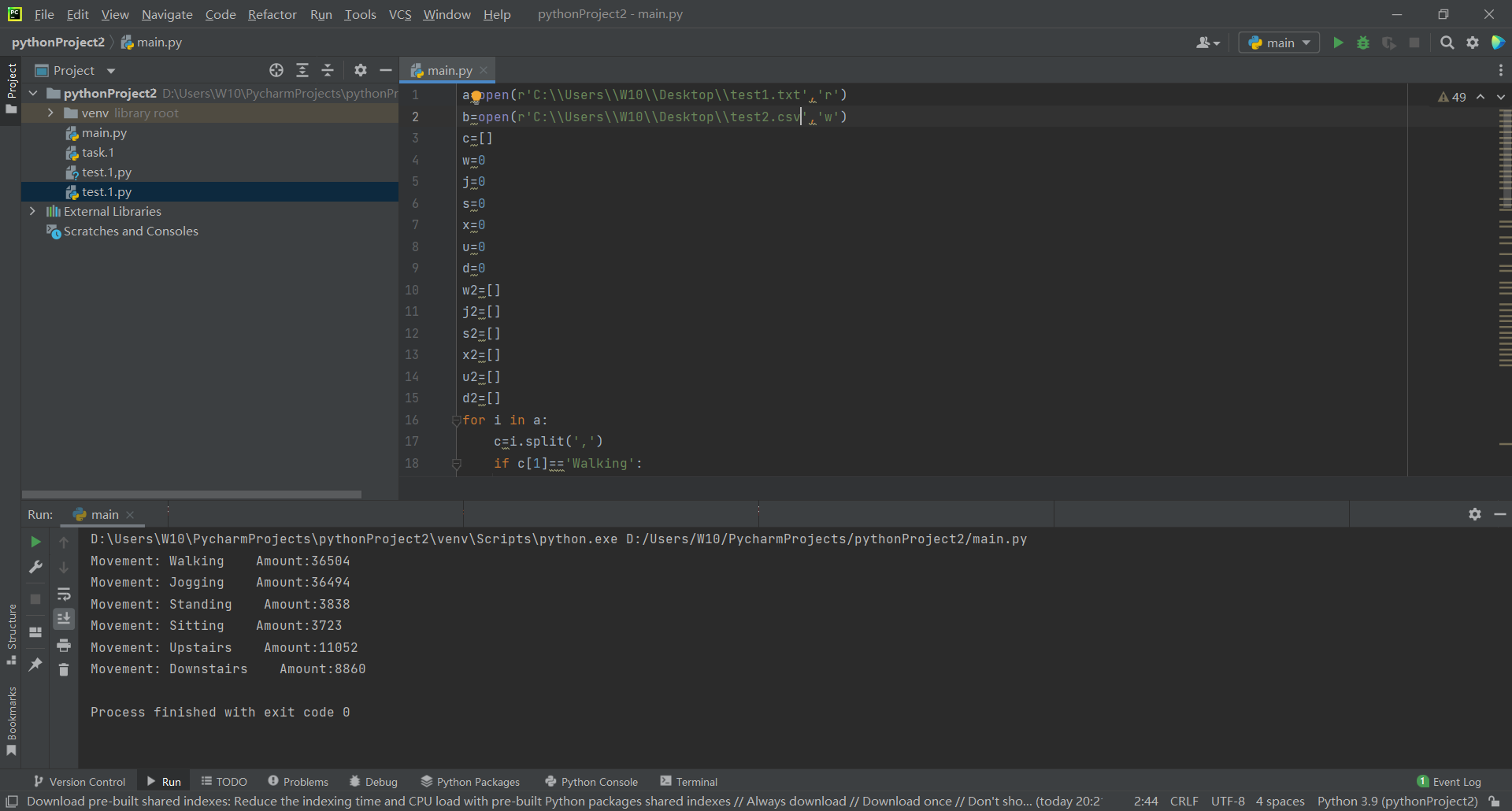 Then the csv file will look like this
Then the csv file will look like this
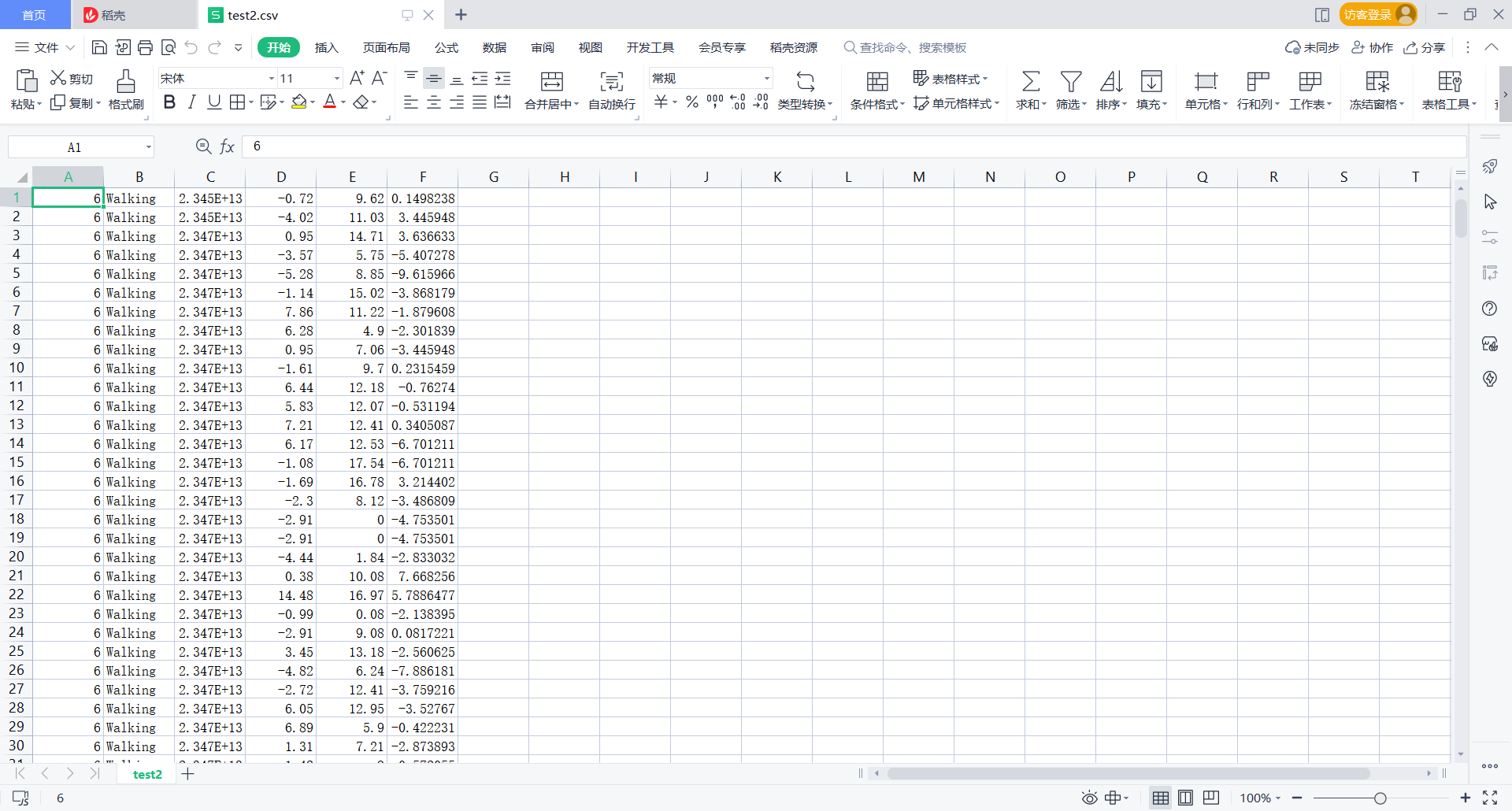 The main idea is to set a counter for each action, define a list to store the data of each action, and finally write the specified number of data to test2
The main idea is to set a counter for each action, define a list to store the data of each action, and finally write the specified number of data to test2
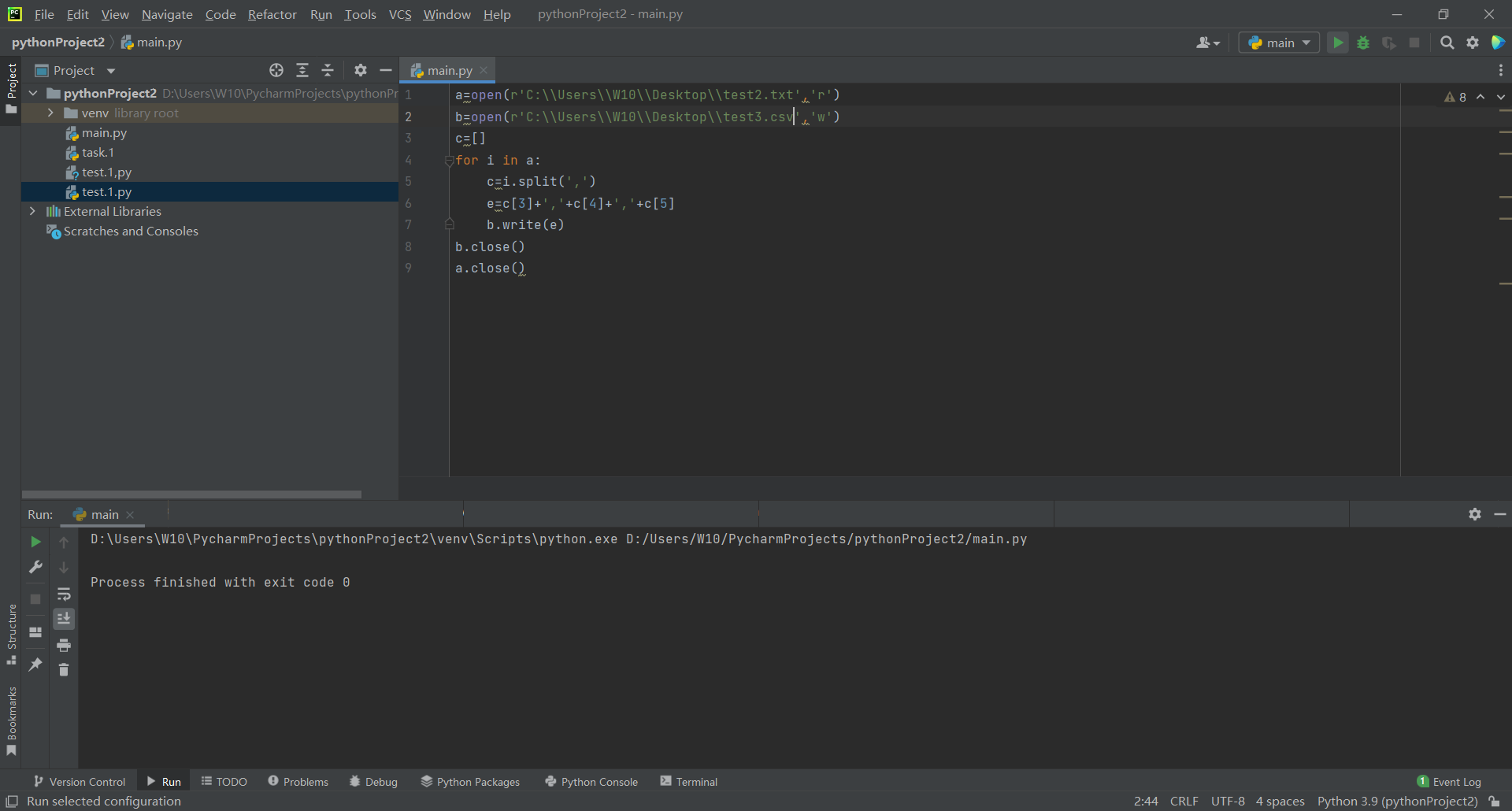
4.test3
a=open(r'C:\\Users\\W10\\Desktop\\test2.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\test3.txt','w')
c=[]
for i in a:
c=i.split(',')
e=c[3]+','+c[4]+','+c[5]
b.write(e)
b.close()
a.close()
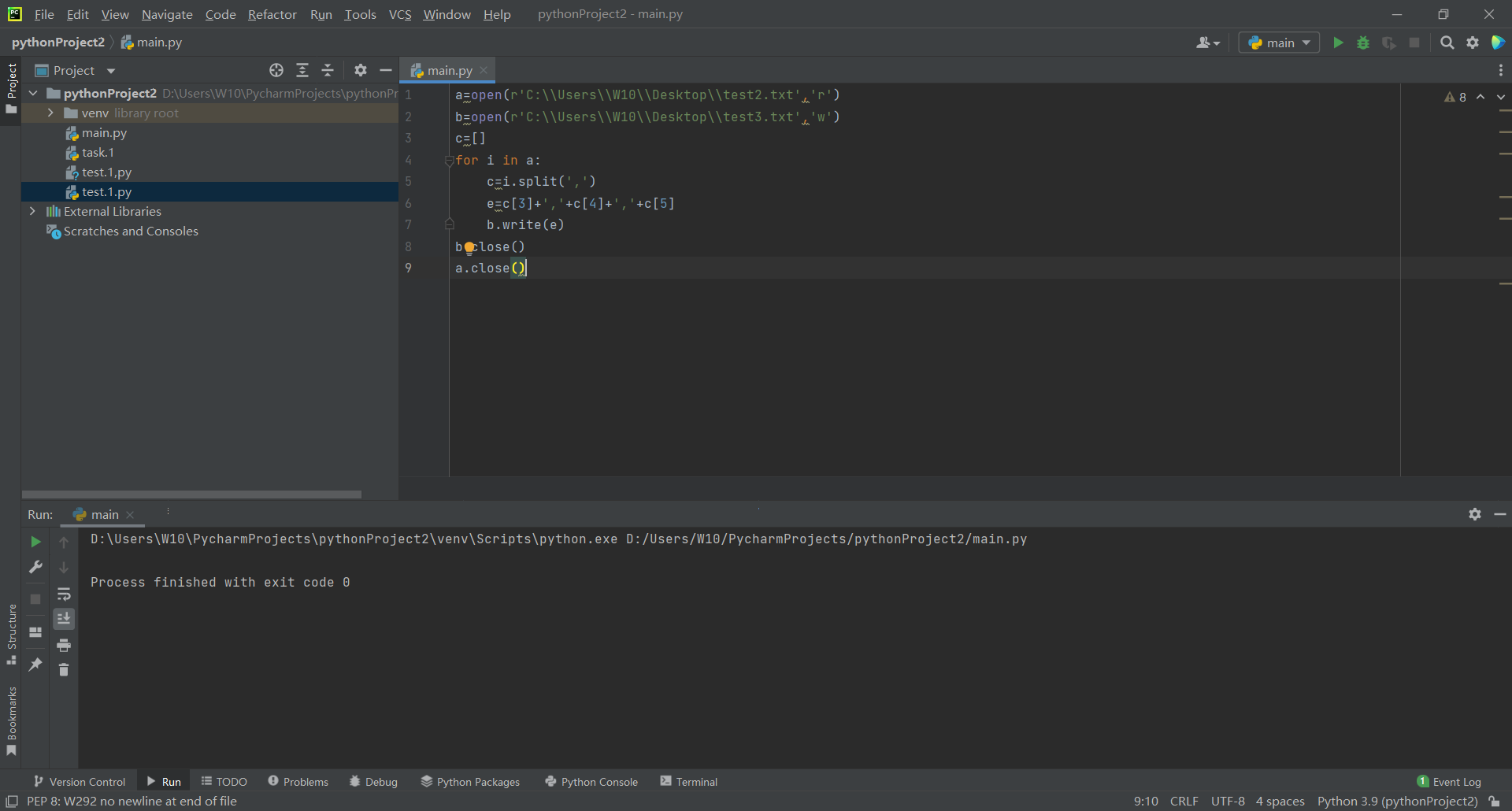
Then there is the following test3 txt
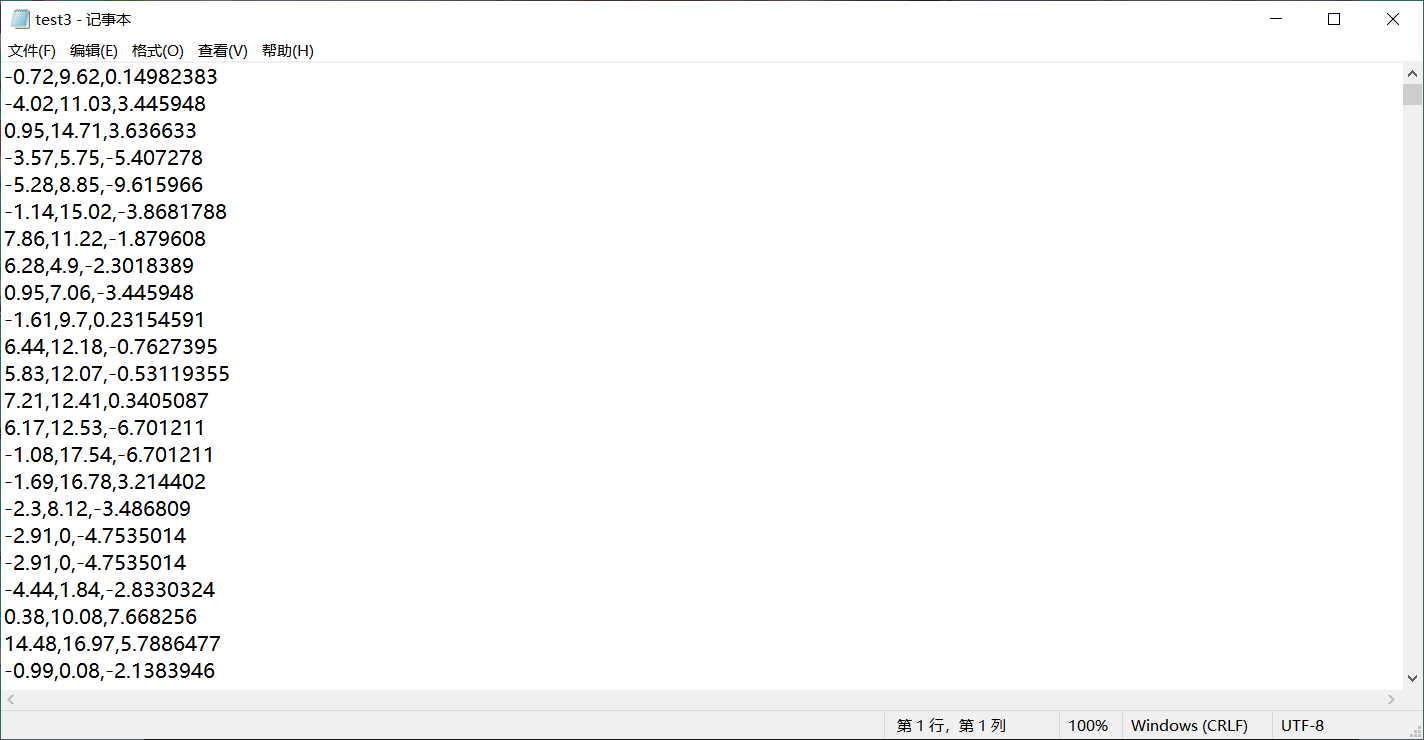 If you want test3 to be a csv type, you can use the following code:
If you want test3 to be a csv type, you can use the following code:
a=open(r'C:\\Users\\W10\\Desktop\\test2.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\test3.csv','w')
c=[]
for i in a:
c=i.split(',')
e=c[3]+','+c[4]+','+c[5]
b.write(e)
b.close()
a.close()
 Then the csv file will look like this
Then the csv file will look like this
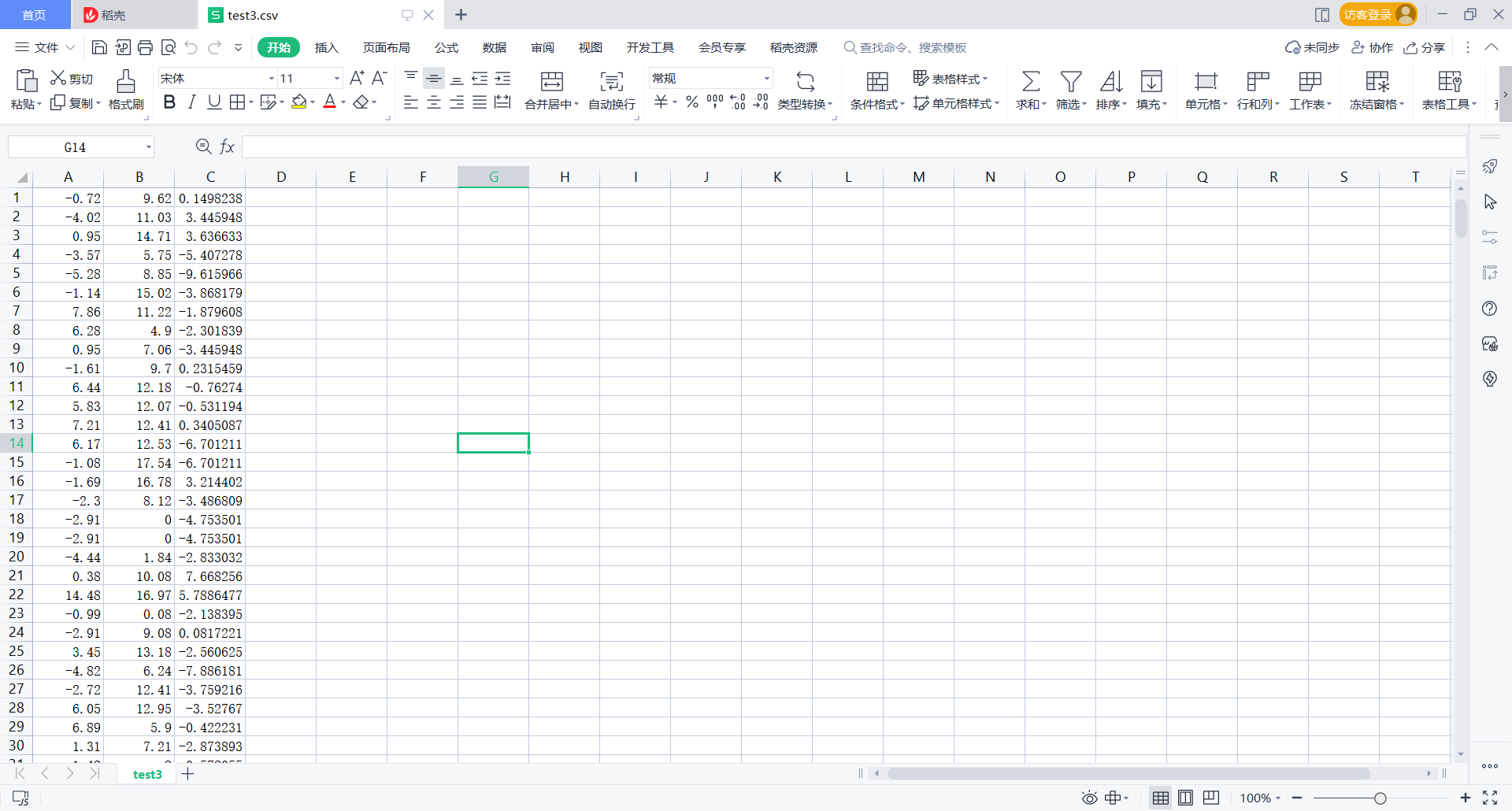 The main idea is to define a list, store the last three in the list, and then change it into a corresponding string and write it to test3
The main idea is to define a list, store the last three in the list, and then change it into a corresponding string and write it to test3
5.finally
a=open(r'C:\\Users\\W10\\Desktop\\test3.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\finally.txt','w')
c=[]
d=0
for i in a:
d+=1
if d%20==0:
i=i.replace(',',' ')
b.write(i)
if d%20!=0:
i=i.replace(',',' ')
i=i.replace('\n',',')
b.write(i)
b.close()
a.close()
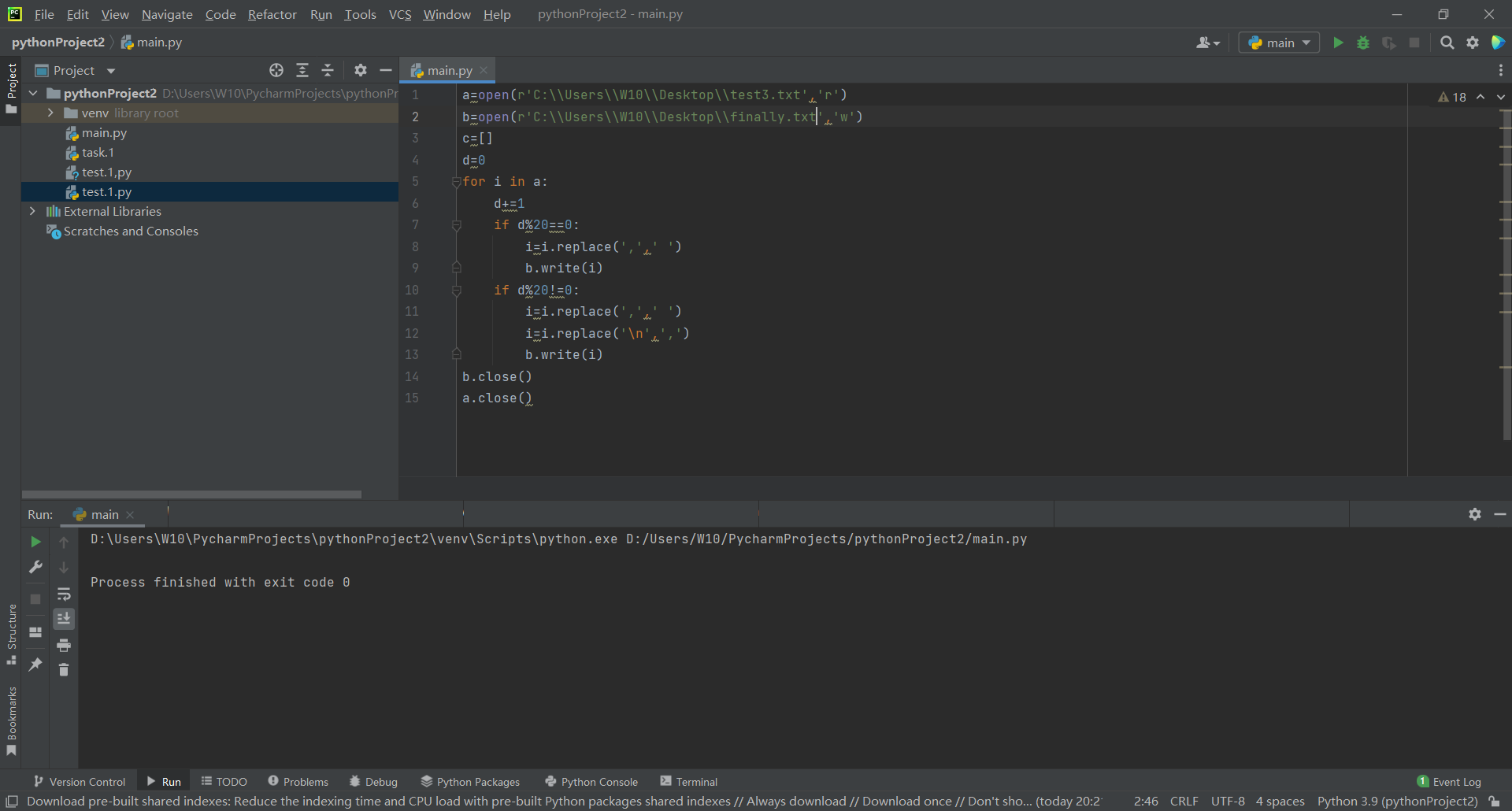
Then there is the following finally txt
 If the finally file is required to be csv type, the following code can be used:
If the finally file is required to be csv type, the following code can be used:
a=open(r'C:\\Users\\W10\\Desktop\\test3.txt','r')
b=open(r'C:\\Users\\W10\\Desktop\\finally.csv','w')
c=[]
d=0
for i in a:
d+=1
if d%20==0:
i=i.replace(',',' ')
b.write(i)
if d%20!=0:
i=i.replace(',',' ')
i=i.replace('\n',',')
b.write(i)
b.close()
a.close()
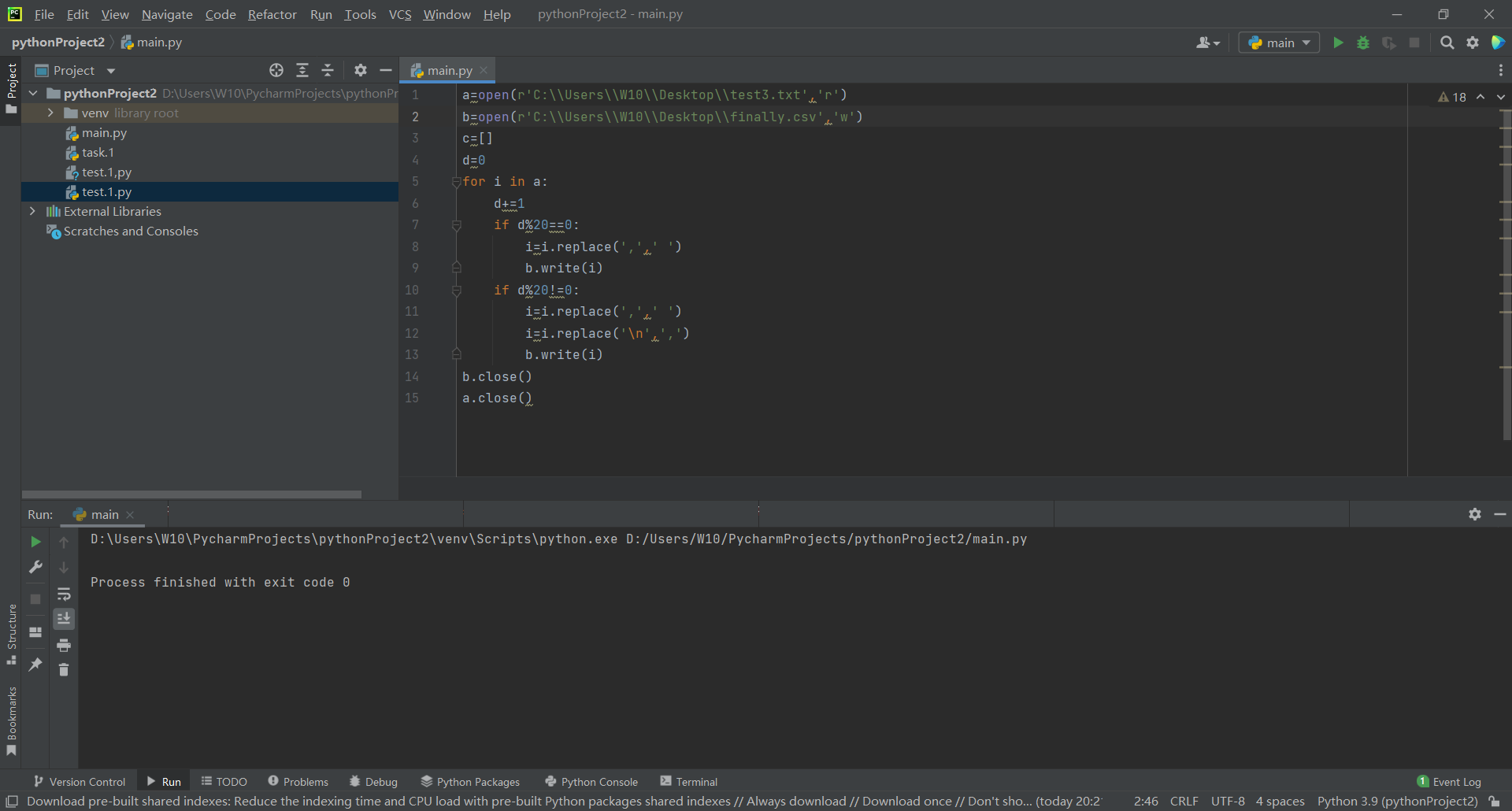
Then the csv file will look like this