8. Find
8.1 introduction to search
A search table is a collection of data elements (or records) of the same type
A key is the value of a data item in a data element, also known as a key value
If this keyword can uniquely identify a record, it is called the primary key
Keywords that can identify multiple data elements (or records) are called secondary keys
Lookup is to determine a data element whose keyword is equal to the given value in the lookup table according to a given value
There are two kinds of lookup tables, static lookup table and dynamic lookup table
Static lookup table: a lookup table that only performs lookup operations. The main operations are
- Query whether a "specific" data element is in the lookup table
- Retrieve a "specific" data element and various attributes
Dynamic lookup table: during the lookup process, insert data elements that do not exist in the lookup table, or delete an existing data element from the lookup table. Obviously, there are two operations of dynamic lookup table:
(1) Insert data elements when searching.
(2) Delete data elements on lookup.
8.2 sequence table lookup
Sequential search, also known as linear search, is the most basic search technology. Its search process is: starting from the first (or last) record in the table, compare the keyword of the record with the given value one by one. If the keyword of a record is equal to the given value, the search is successful and the queried record is found; If the keyword and given value of the last (or first) record are not equal until the comparison, there is no record in the table and the search is unsuccessful.
Sequential table lookup algorithm
//Sequential search: a is the array, n is the number of arrays to be searched, and key is the keyword to be searched
int Sequential_Search(int *a,int n,int key)
{
int i;
for(i=1;i<=n;i++)
{
if(a[i]==key)
return i;
}
return 0;
}
Sequential table lookup optimization
//There are sentinels to search in sequence
int Sequential_Search2(int *a,int n,int key)
{
int i;
a[0]=key; //Set a[0] as the keyword value, which is called "sentry"
i=n; //The loop starts at the end of the array
while(a[i]!=key)
{
i--;
}
return i; //If 0 is returned, the search fails
}
8.3 ordered table lookup
Half search
Binary search technology, also known as binary search. Its premise is that the records in the linear table must be in order of key codes (usually from small to large), and the linear table must be stored in order. The basic idea of half search is: in the ordered table, take the intermediate record as the comparison object. If the given value is equal to the keyword of the intermediate record, the search is successful; If the given value is less than the keyword of the intermediate record, continue to search in the left half of the intermediate record; If the given value is greater than the keyword of the intermediate record, continue to search in the right half of the intermediate record. Repeat the above process until the search is successful or there is no record in all search areas and the search fails
Suppose we now have such an ordered table array {0,1,16,24,35,47,59,62,73,88,99}, with 10 numbers in total except for the 0 subscript. Look it up for the number 62. Let's look at how the half search algorithm works.
int Binary_Search(int *a,int n,int key)
{
int low,high,mid;
low=1; //Define the lowest subscript as the first record
high=n; //Define the highest subscript as the last bit of the record
while(low<=high)
{
mid=(low+high)/2; //Halve
if(key<a[mid]) //If the search value is smaller than the median
high=mid-1; //The highest subscript is adjusted to the middle subscript, and the subscript is one digit lower
else if(key>a[mid]) //If the search value is larger than the median value
low=mid+1; //The lowest subscript is adjusted to the middle subscript, and the subscript is one higher
else
return mid; //If they are equal, it means that mid is the location found
}
return 0;
}
Interpolation search

8.4 linear index lookup
Indexing is the process of associating a keyword with its corresponding record
Linear index technology organizes the set of index items into a linear structure, also known as index table
Dense index
In a linear index, each record in the dataset corresponds to an index item
For the dense index table, the index entries must be arranged in order according to the key
Block index
Block order is to divide the records of the data set into several blocks, and these blocks need to meet two conditions
- Intra block disorder
- Inter block ordering
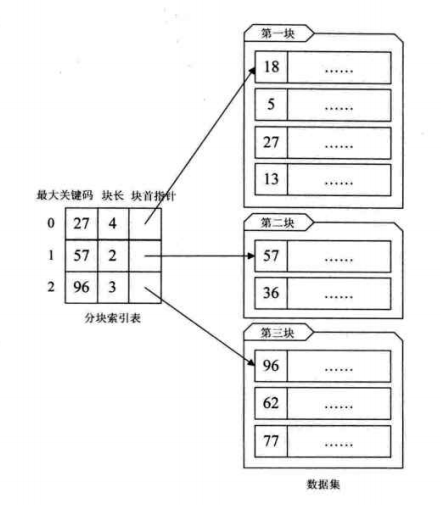
For a block ordered data set, each block corresponds to an index item. This index method is called block index. As shown in the figure, the index item structure of the block index defined by us is divided into three data items:
-
The largest key stores the largest keyword in each block, which has the advantage that the smallest keyword in the next block after it can be larger than the largest keyword in this block;
-
The number of records in the block is stored to facilitate circulation;
-
Pointer to the data element at the beginning of the block to facilitate the traversal of records in this block.
8.5 binary sort tree
Binary sort tree, also known as binary search tree. It is either an empty tree or a binary tree with the following properties.
- If its left subtree is not empty, the value of all nodes on the left subtree is less than the value of its root structure;
- If its right subtree is not empty, the value of all nodes on the right subtree is greater than that of its root node;
- Its left and right subtrees are also binary sort trees
//Definition of binary linked list node structure of binary tree
typedef struct BiTNode //Node structure
{
int data; //Node data
struct BiTNode *lchild,*rchild; //Left and right child pointers
}BiTNode,*BiTree;
Implementation of binary sort tree search
/*Recursively find out whether there is a key in the binary sort tree T,*/
/*Pointer f points to the parent of T and its initial call value is NULL*/
/*If the search is successful, the pointer p points to the data element node and returns TRUE*/
/*Otherwise, the pointer p points to the last node accessed on the lookup path and returns FALSE*/
Status SearchBST ( BiTree T ,int key,BiTree f,BiTree *p)
{
if(!T)/*The search was unsuccessful*/
{
*p=f;
return FALSE;
}
else if(key=-T->data)/*Search succeeded*/
{
*p=T;
return TRUE;
}
else if (key<T->data)
return SearchBST(T->1child,key,T,p);/*Continue searching in the left subtree*/
else
return SearchBST(T->rchild,key,T,p);/*Continue searching in the right subtree*/
}
8.6 hash table lookup (hash table) overview
Hash table lookup definition
Storage location = f (keyword)
Hash technology is to establish a certain corresponding relationship f between the storage location of the record and its keywords, so that each keyword key corresponds to a storage location f(key).
Correspondence f is called hash function, also known as hash function.
Hash technology is used to store records in a continuous storage space, which is called hash table or hash table
Hash table lookup procedure
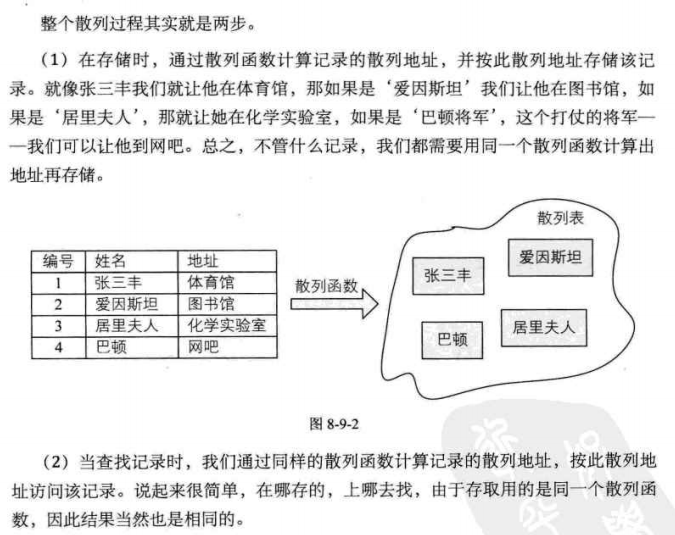
Hash technology is not only a storage method, but also a search method
The most suitable solution of hash technology is to find records equal to the given value
We often encounter two keywords key1=/key2, but there is f(key1)=f(key2). This phenomenon is called collision, and key1 and key2 are called synonyms of this hash function.
8.7 construction method of hash function
Two principles of good hash function
- Simple calculation
- Hash addresses are evenly distributed
Direct address method
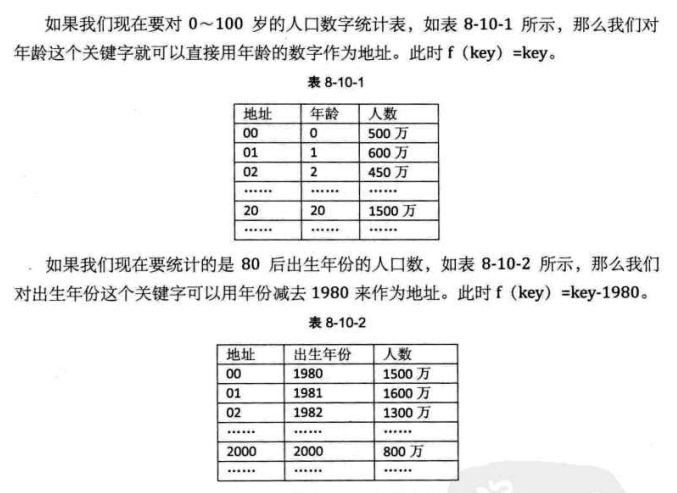
Take the value of a linear function of the keyword as the hash address
f(key)=a x key+b(a,b are constants)
Digital analysis

Square middle method

Folding method

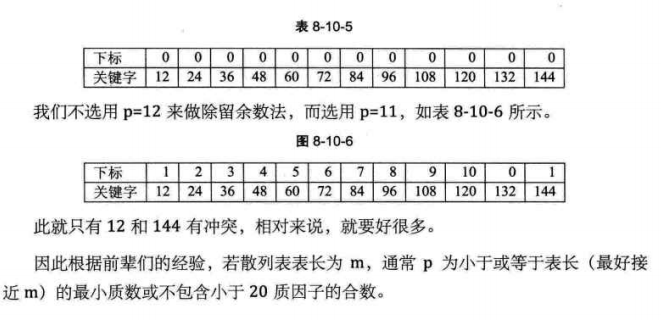
Division method

Random number method

Conflict handling method
Open addressing



Hashing function method

Chain address method

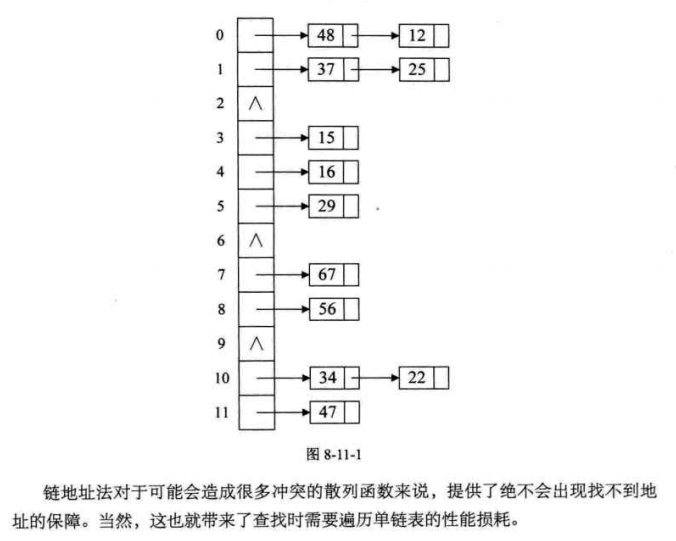
Public spillover area act


8.9 hash table lookup implementation
Algorithm implementation
Define hash table structure and related constants
#define success 1
#define unsuccess 0
#define hashsize 12 // Defines the length of the hash table as the length of the array
#define nullkey -32768
typedef struct
{
int *elem; //Data element storage base address, dynamic allocation array
int count; //Number of current data elements
}hashtable;
int m=0; //Hash table length, global variable
Hash table initialization
/*Initialize hash table*/
Status InitHashTable(HashTable *H)
{
int i;
m=HASHSIZE;
H->count=m;
H->elem=(int *)malloc(m*sizeof(int));
for(i=0;i<m;i++)
H->elem[i]=NULLKEY;
return OK;
}
Define hash function
//Hash function
int Hash(int key)
{
return key % m;//Division method
}
Insert operation
/*Insert keyword into hash table*/
void InsertHash(HashTable*H,int key)
{
int addr-Hash(key);/*Hash address*/
while(H->elem[addr]!=NULLKEY)/*If it is not empty, there is a conflict*/
addr-(addr+1)%m;/*Linear detection of open addressing method*/
H->elem[addr]=key;/*Insert keyword until there is space*/
}
lookup
/*Hash table lookup keyword*/
Status SearchHash (HashTable H,int key,int*addr)
{
*addr=Hash(key);/*Hash address*/
while(H.elem[*addr]!=key)/*If it is not empty, there is a conflict*/
{
*addr=(*addr+1)%m;/*Linear detection of open addressing method*/
if (H.elem[*addr]==NULLKEY || *addr==Hash(key))
{
/*If the loop returns to the origin*/
return UNSUCCESS ;/*The keyword does not exist*/
}
}
return SUCCESS;
}
performance analysis

