Java sorting
catalogue
1, Simple sort
preface
Sorting is a very common requirement. It provides some data elements and sorts them according to certain rules. The sorting algorithms are described in turn below. The content comes from the dark horse programmer.
1, Simple sort
1. Bubble sorting

Code implementation:
package sort;
import javax.sound.midi.Soundbank;
import java.awt.image.ImageFilter;
import java.util.Arrays;
/**
* @Date: 2022/1/6 - 01 - 06 - 14:04
* @Description:
*/
public class Bubble {
public static void sort(Comparable[] a){
for (int i = a.length-1; i >0 ; i--) {
for (int j = 0; j <i ; j++) {
if (greater(a[j],a[j+1])){
exch(a,j,j+1);
}
}
}
}
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
private static void exch(Comparable[] a,int i,int j){
Comparable t=a[i];
a[i]=a[j];
a[j]=t;
}
public static void main(String[] args) {
Integer[] a={4,5,2,3,7,8,0};
Bubble.sort(a);
System.out.println(Arrays.toString(a));
}
}
2. Select Sorting

Code implementation:
package sort;
import java.util.Arrays;
/**
* @Date: 2022/1/6 - 01 - 06 - 14:51
* @Description:
*/
public class Selection {
public static void sort(Comparable[] a){
for (int i = 0; i <a.length-1; i++) {//Because there is no need to select the remaining element, I < a.length-1
//Cycle the value of the minimum index in turn
int min=i;
for (int j = i+1; j <a.length ; j++) {
if (greater(a[min],a[j])){//Compare the value with the minimum index. If the minimum index is large, exchange the subscript value
min=j;
}
}
exch(a,min,i);//Swap element positions after exchanging Subscripts
}
}
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
private static void exch(Comparable[] a,int i,int j){
Comparable t=a[i];
a[i]=a[j];
a[j]=t;
}
public static void main(String[] args) {
Integer[] a={4,5,2,3,7,8,0};
Bubble.sort(a);
System.out.println(Arrays.toString(a));
}
}
Time complexity analysis of selective sorting: selective sorting uses a double-layer for loop, in which the outer loop completes data exchange and the inner loop completes data comparison, So we count the data exchange times and data comparison times respectively: data comparison times: (n-1) + (n-2) + (n-3) ++ 2+1=((N-1)+1)*(N-1)/2=N^2/2-N/2; Data exchange times: n-1 time complexity: n ^ 2 / 2-N / 2 + (n-1) = N^2/2+N/2-1; According to the large o derivation rule, the highest order term is retained and the constant factor is removed. The time complexity is O(N^2);
3. Insert sort
As shown in the figure:

Code implementation:
package sort;
/**
* @Date: 2022/1/6 - 01 - 06 - 15:30
* @Description:
*/
public class Insertion {
public static void sort(Comparable[] a){
for(int i=1;i<a.length;i++){//Traverse from the second element
for(int j=i;j>0;j--){
//Compare the value at index j with the value at index j-1. If the value at index j-1 is larger than the value at index j, exchange data. If it is not large, find the appropriate position and exit the loop;
if (greater(a[j-1],a[j])){
exch(a,j-1,j);
}else{
break;
}
}
}
}
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
private static void exch(Comparable[] a,int i,int j){
Comparable temp;
temp = a[i];
a[i]=a[j];
a[j]=temp;
}
}
2, Advanced sorting
1. Hill sort
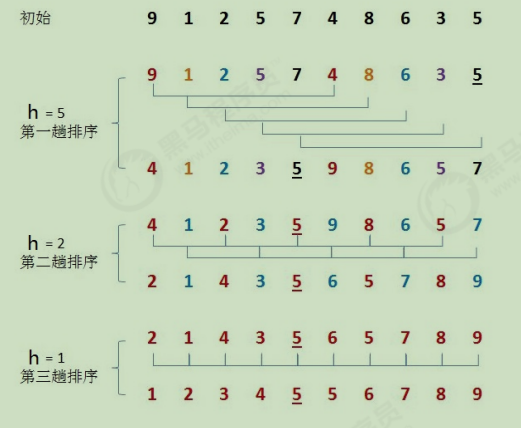
Code implementation:
package sort;
/**
* @Date: 2022/1/6 - 01 - 06 - 15:44
* @Description:
*/
public class Shell {
public static void sort(Comparable[] a){
//1. Determine the initial value of the growth amount h according to the length of array a;
int h = 1;
while(h<a.length/2){
h=2*h+1;
}
//2. Hill sort
while(h>=1){
//sort
//2.1. Find the element to insert
for (int i=h;i<a.length;i++){
//2.2 insert the elements to be inserted into the ordered sequence
for (int j=i;j>=h;j-=h){
//The element to be inserted is a[j], compare a[j] and a[j-h]
if (greater(a[j-h],a[j])){
//Exchange element
exch(a,j-h,j);
}else{
//The element to be inserted has found the appropriate position and ends the loop;
break;
}
}
}
//Decrease the value of h
h= h/2;
}
}
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
private static void exch(Comparable[] a,int i,int j){
Comparable temp;
temp = a[i];
a[i]=a[j];
a[j]=temp;
}
}
public class SortCompare {
//Call different test methods to complete the test
public static void main(String[] args) throws Exception{
//1. Create an ArrayList set and save the read integers
ArrayList<Integer> list = new ArrayList<>();
//2. Create a cache read stream BufferedReader, read data and store it in ArrayList;
BufferedReader reader = new BufferedReader(new InputStreamReader(SortCompare.class.getClassLoader().getResourceAsStream("reverse_arr.txt")));
String line=null;
while((line=reader.readLine())!=null){
//Line is a string. Convert line to Integer and store it in the collection
int i = Integer.parseInt(line);
list.add(i);
}
reader.close();
//3. Convert the ArrayList set into an array
Integer[] a = new Integer[list.size()];
list.toArray(a);
//4. Call the test code to complete the test
//testInsertion(a);//37499 MS
testShell(a);//30 ms
// testMerge(a);//70 ms
}
//Test Hill sort
public static void testShell(Integer[] a){
//1. Get the time before execution
long start = System.currentTimeMillis();
//2. Execute algorithm code
Shell.sort(a);
//3. Get the time after execution
long end = System.currentTimeMillis();
//4. Calculate the execution time of the program and output it
System.out.println("The execution time of Hill sort is:"+(end-start)+"millisecond");
}
//Test insert sort
public static void testInsertion(Integer[] a){
//1. Get the time before execution
long start = System.currentTimeMillis();
//2. Execute algorithm code
Insertion.sort(a);
//3. Get the time after execution
long end = System.currentTimeMillis();
//4. Calculate the execution time of the program and output it
System.out.println("Insert sort execution time:"+(end-start)+"millisecond");
}
//Test merge sort
public static void testMerge(Integer[] a){
//1. Get the time before execution
long start = System.currentTimeMillis();
//2. Execute algorithm code
Merge.sort(a);
//3. Get the time after execution
long end = System.currentTimeMillis();
//4. Calculate the execution time of the program and output it
System.out.println("The execution time of merge sort is:"+(end-start)+"millisecond");
}
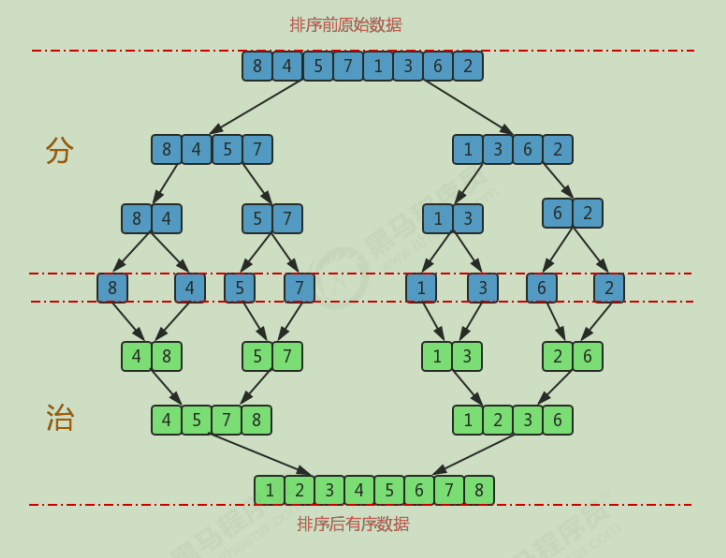
}2. Merge and sort
Filling principle: divide the original array into left subgroup and right subgroup. p1 pointer is the left subgroup pointer, p2 is the right subgroup pointer, and set i as the auxiliary array pointer. Compare the size of the element indicated by the current p1 and p2 pointers, and put the small one at the pointer i; Then move the p1,p2,i pointers backward to continue the comparison.
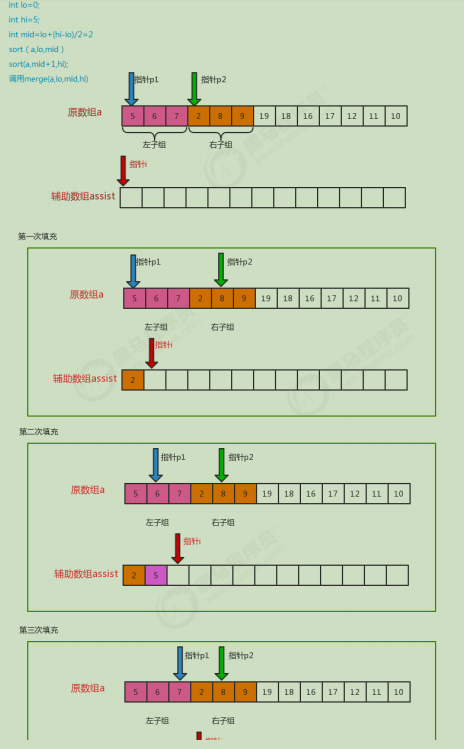
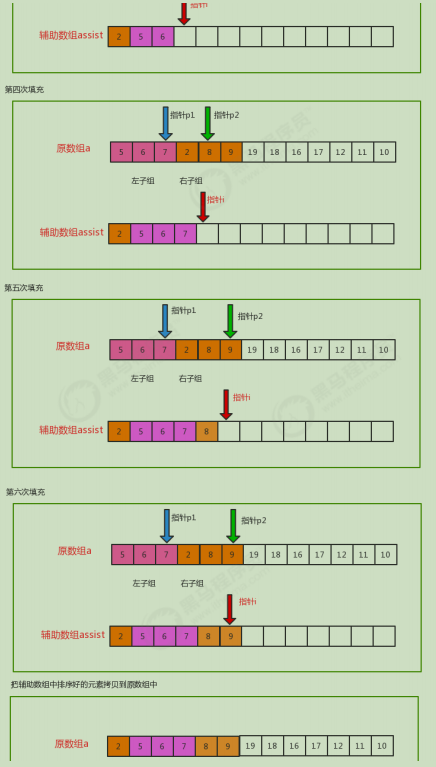
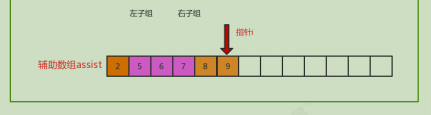
Code implementation:
package sort;
/**
* @Date: 2022/1/7 - 01 - 07 - 10:14
* @Description:
*/
public class Merge {
//Auxiliary array required for merging
private static Comparable[] assist;
private static boolean less(Comparable v, Comparable w) {
return v.compareTo(w)<0;
}
private static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
public static void sort(Comparable[] a) {
//1. Initialize auxiliary array assist;
assist = new Comparable[a.length];
//2. Define a lo variable and a hi variable to record the minimum index and the maximum index in the array respectively;
int lo=0;
int hi=a.length-1;
//3. Call the sort overloaded method to sort the elements in array a from index lo to index hi
sort(a,lo,hi);
}
private static void sort(Comparable[] a, int lo, int hi) {
//Conduct safety verification;
if (hi<=lo){
return;
}
//The data between lo and hi are divided into two groups
int mid = lo+(hi-lo)/2;// 5,9 mid=7
//Sort each group of data separately
sort(a,lo,mid);
sort(a,mid+1,hi);
//Then merge the data in the two groups
merge(a,lo,mid,hi);
}
private static void merge(Comparable[] a, int lo, int mid, int hi) {
//Define three pointers
int i=lo;
int p1=lo;
int p2=mid+1;
//Traverse, move the p1 pointer and p2 pointer, compare the value at the corresponding index, find the small one, and put it at the corresponding index of the auxiliary array
while(p1<=mid && p2<=hi){
//Compare the values at the corresponding index
if (less(a[p1],a[p2])){
assist[i++] = a[p1++];
}else{
assist[i++]=a[p2++];
}
}
//Traversal. If the p1 pointer is not completed, move the p1 pointer in sequence and put the corresponding element at the corresponding index of the auxiliary array
while(p1<=mid){
assist[i++]=a[p1++];
}
//Traversal. If the p2 pointer is not completed, move the p2 pointer in sequence and put the corresponding elements at the corresponding index of the auxiliary array
while(p2<=hi){
assist[i++]=a[p2++];
}
//Copy the elements in the auxiliary array to the original array
for(int index=lo;index<=hi;index++){
a[index]=assist[index];
}
}
}Merge sort time complexity analysis:
3. Quick sort
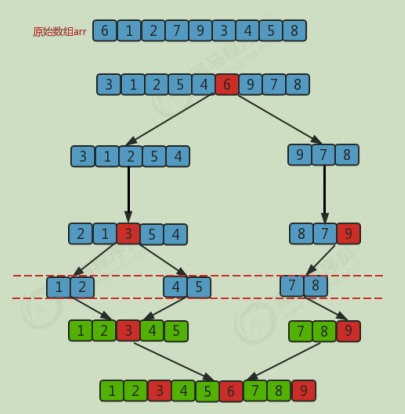
Code implementation:
package sort;
/**
* @Date: 2022/1/7 - 01 - 07 - 10:36
* @Description:
*/
public class Quick {
private static boolean less(Comparable v, Comparable w) {
return v.compareTo(w) < 0;
}
private static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
public static void sort(Comparable[] a) {
int lo = 0;
int hi = a.length-1;
sort(a,lo,hi);
}
private static void sort(Comparable[] a, int lo, int hi) {
//Security verification
if (hi<=lo){
return;
}
//The elements from lo index to hi index in the array need to be grouped (left subgroup and right subgroup);
int partition = partition(a, lo, hi);//Returns the index of the boundary value of the group, and the index after the boundary value position transformation
//Order the left subgroup
sort(a,lo,partition-1);
//Order the right subgroup
sort(a,partition+1,hi);
}
//Group the elements in array a from index lo to index hi, and return the index corresponding to the grouping boundary
public static int partition(Comparable[] a, int lo, int hi) {
//Determining the boundary value is the first element
Comparable key = a[lo];
//Define two pointers to point to the next position at the minimum index and the maximum index of the element to be segmented
int left=lo;
int right=hi+1;
//segmentation
while(true){
//Scan from right to left, move the right pointer, find an element with small score boundary value, and stop
while(less(key,a[--right])){
if (right==lo){
break;
}
}
//Scan from left to right, move the left pointer, find an element with a large score boundary value, and stop
while(less(a[++left],key)){
if (left==hi){
break;
}
}
//Judge left > = right. If yes, it proves that the element scanning is completed and ends the cycle. If not, it can exchange elements
if (left>=right){
break;
}else{
exch(a,left,right);
}
}
//Exchange the boundary value. right=left refers to the position
exch(a,lo,right);
//Finally, the boundary value can be returned
return right;
}
}3, Stability of sorting
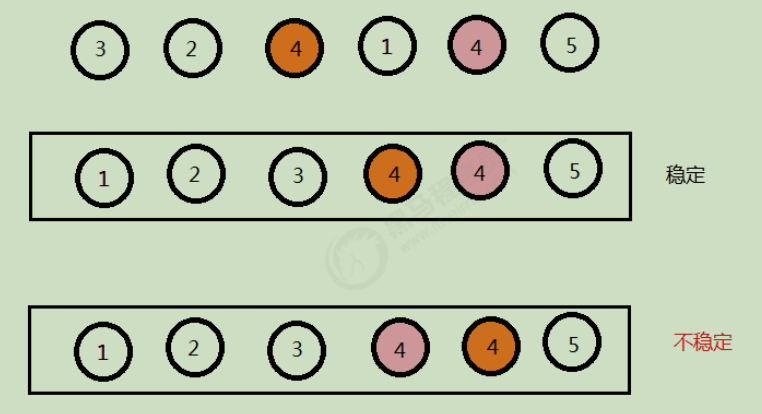
- Bubble sort: only when arr [i] > arr [i + 1], the positions of elements will be exchanged, and when they are equal, they will not be exchanged. Therefore, bubble sort is a stable sort algorithm.
- Selective sorting: selective sorting is to select the smallest current element for each position. For example, there is data {5 (1), 8, 5 (2), 2, 9}. The smallest element selected for the first time is 2, so 5 (1) will exchange positions with 2. At this time, the stability is destroyed when 5 (1) comes behind 5 (2). Therefore, selective sorting is an unstable sorting algorithm.
- Insertion sort: the comparison starts from the end of the ordered sequence, that is, the element to be inserted starts from the largest one that has been ordered. If it is larger than it, it will be inserted directly behind it. Otherwise, it will look forward until it finds the insertion position. If you encounter an element that is equal to the inserted element, put the element to be inserted after the equal element. Therefore, the sequence of equal elements has not changed. The order out of the original unordered sequence is the order after the order is arranged, so the insertion sort is stable.
- Hill sort: Hill sort sorts the elements according to the unsynchronized length. Although one insertion sort is stable and does not change the relative order of the same elements, in different insertion sort processes, the same elements may move in their own insertion sort, and finally their stability will be disturbed. Therefore, Hill sort is unstable.
- Merge sort: in the process of merge sort, only when arr [i] < arr [i + 1] will the position be exchanged. If the two elements are equal, the position will not be exchanged, so it will not destroy the stability. Merge sort is stable.
- Quick sort: quick sort requires a benchmark value. Find an element smaller than the benchmark value on the right side of the benchmark value, find an element larger than the benchmark value on the left side of the benchmark value, and then exchange the two elements. At this time, stability will be destroyed. Therefore, quick sort is an unstable algorithm.