1 Basic Concepts
Trie tree (dictionary tree), also known as word lookup tree, is a data structure that can efficiently store and find string sets (not limited to strings). In y's eyes, it is a very simple data structure.
It includes the following three properties:
- The root node does not contain characters. Except for the root node, each node contains only one character
- From the root node to a node, the characters passing through the path are connected to the corresponding string of the node
- All child nodes of each node contain different characters
for instance:
Suppose the Trie tree stores abcdef, abdef, acef, bcdf, bcff, cdaa, bcdc, and finds aced, abcf, abcd through the tree.
Q1: how to store efficiently?
A1: it is simply summarized as: create nodes and mark the end. Taking abcdef as an example, start from the root node and find the character a
- If it exists, take a as the parent node and look for the next character b
- If it does not exist, create node a, and then take a as the parent node to find the next character b
- The whole process is a recursive process. After the node corresponding to the character f is generated, mark the node, indicating that there is a string ending with F.
The Trie tree storing the above strings is shown in the following figure:
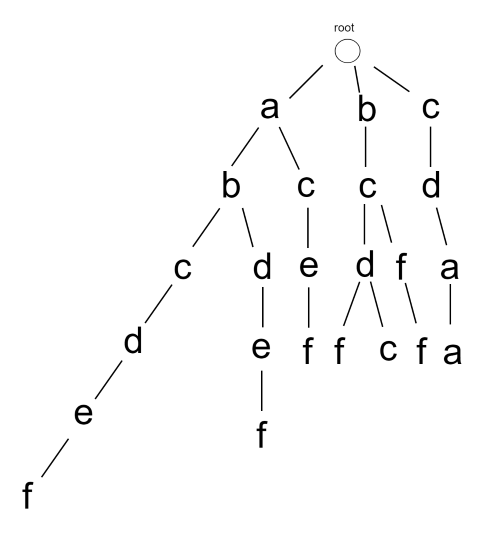
Q2: how to find efficiently?
A2:
For acef: traverse the tree a → c → e → f until node f is found and marked (representing the end of a string)
For abcf: f cannot be traversed
For abcd: traverse to d, but the d node is unmarked, indicating that the Trie tree does not store this string
2 code implementation
2.1 some details
In the dictionary tree, we often use the following arrays and variables:
1.son[M][N]
The whole tree is stored in the son array. M represents each parent node and N represents the corresponding child nodes. During initialization, it is necessary to find out the maximum number of nodes m and the maximum number of child nodes n in each node. (tree array)
2.cnt[M]
Short for count, cnt[i] indicates the number of strings ending with nodes with index I. Because the maximum number of nodes is m, the capacity should also be opened to M.
3.idx
index. Each new node is assigned a unique idx. idx = 0 indicates that this is the root node (also an empty node).
4. String traversal
In C + +, the end of the string is' \ 0 ', which can be used as the critical point of the loop, i.e
for(int i = 0; str[i]; i ++){
// String traversal
}
5. Error free scanf ('% C', & OP) method
As mentioned in previous 1, if it is determined that op has only one character, you can do this:
char op[2];
scanf("%s", op); // Here, scanf is used to filter carriage returns and spaces when reading strings
if(op[0] == 'I') insert(...)
// It's also possible to replace op[0] with * op
Note 1: the previous method can refer to: [data structure] algorithm implementation of single linked list and double linked list 3.3 bug
2.2 storage
When storing a string, start from the root node (take the root node as the parent node) and first judge whether there are points to store
- If so, next
- If not, create
Take this point as the parent node, and then judge the next node. Record the last node until it exists. The code implementation is as follows:
void insert(char str[]){
int p = 0; // Starting from the root node
for(int i = 0; str[i]; i ++){
int u = str[i] - 'a'; // 'a'~'z' -> 0 ~ 25
if(!son[p][u]) son[p][u] = ++ idx;
p = son[p][u];
}
cnt[p] ++; // record
}
2.3 search
The thinking of finding and storing is similar.
It should be noted that there are two cases of search failure:
- No corresponding node was found during traversal
- After traversal (end of the for loop), return value is 0, which means no tag (no tag means no storage)
int query(char str[]){
int p = 0;
for(int i = 0; str[i]; i ++){
int u = str[i] - 'a';
if(!son[p][u]) return 0; // Search failed
p = son[p][u];
}
return cnt[p];
}
3 topic
3.1 naked questions
Title Link: AcWing 835. Trie string statistics
code:
#include<iostream>
using namespace std;
const int N = 100010;
int son[N][26];
int cnt[N]; // How many words end at the current point
int idx; // Currently used subscript, subscript = 0: it is both a root node and an empty node
char str[N];
void insert(char str[]){
int p = 0; // Start at the root node
for(int i = 0; str[i]; i ++){
// Traversal string
int u = str[i] - 'a'; // 'a'~'z' -> 0 ~ 25
if(!son[p][u]) son[p][u] = ++ idx; // Whether or not it exists now, and each node has a unique idx
p = son[p][u]; // This node is the parent node of the next character
}
cnt[p] ++;
}
int query(char str[]){
int p = 0;
for(int i = 0; str[i]; i ++){
int u = str[i] - 'a';
if(!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
int main(){
int n;
scanf("%d", &n);
while(n --){
char op[2];
scanf("%s%s", op, str);
if(*op == 'I'){
insert(str);
}
else printf("%d\n", query(str));
}
return 0;
}
3.2 maximum XOR pair
Title Link: AcWing 143. Maximum XOR pair
Solution:
In fact, I have thought of some points when thinking about this problem, but I still pursue one step in place, so I didn't come up with a more specific solution.
Detail 1
105 means that this is the time complexity 1 of * O(nlogn) *. This time complexity can be traversed at least once, so you can control one branch of the tree (i.e. one tree), and then find the maximum value from another branch, that is:
int res = 0;
for(int i = 0; i < n; i ++){
res = max(res, search(a[i])); // Fix one before searching
}
Note: the time complexity derived from the data range can be referred to: [skill] calculate the complexity of the method and the content of the algorithm from the data range
Detail 2
At first, I wanted to express all the binaries of a number at one time, but it's not necessary to think about it. The data range is > = 0, < 231 indicates that there are at most 31 binary bits, so take one bit each time during traversal:
Assuming that a bit is 0 bit, the ith bit of a number can be expressed as: x > > i & 1
int p = 0;
for(int i = 30; i >= 0; i --){
int &s = son[p][x >> i & 1];
if(!s) s = ++ idx;
p = s;
}
Complete code
#include<iostream>
using namespace std;
const int N = 100010;
const int M = 3100000; // Ai < 2 ^ 31 ^, indicating that Ai is up to 31 bits, all 1. 31 * 100000
int a[N];
int son[M][2];
int idx;
void insert(int x){
int p = 0; // Start at the root node
for(int i = 30; i >= 0; i --){
int &s = son[p][x >> i & 1];
if(!s) s = ++ idx;
p = s;
}
}
int search(int x){
int p = 0, res = 0;
for(int i = 30; i >= 0; i --){
int s = x >> i & 1;
if(son[p][!s]){
res += 1 << i; // < < priority over+=
p = son[p][!s];
}
else{
res += 0 << i; // In fact, this step can not be
p = son[p][s];
}
}
return res;
}
int main(){
int n;
scanf("%d", &n);
for(int i = 0; i < n; i ++){
scanf("%d", &a[i]);
insert(a[i]);
}
int res = 0;
for(int i = 0; i < n; i ++){
res = max(res, search(a[i])); // Fix one before searching
}
cout << res;
}
3.3 questions to be brushed
Source of the following topic: ZZUACM Zhaoxin group (Group No.: 562888278)
1.leetcode interview question 16.02 Word frequency
2. The longest word in leetcode 720 dictionary
3.leetcode interview questions 17.17 Multiple searches
4.leetcode interview questions 17.15 Longest word
5.leetcode 139. Word splitting
6.leetcode 140. Word splitting II
7.leetcode 212. Word search II
8.leetcode interview questions 17.13 Restore space