Author: Lemon Nan
Original address: https://mp.weixin.qq.com/s/SUUHF9R_FKg-3vq7Q3cwBQ
The original text and address shall be indicated
introduce
Clickhouse itself is an analytical database, which provides many synchronization schemes with other components. This paper will take Kafka as the data source to introduce how to synchronize Kafka's data to Clickhouse.
flow chart
I won't say much. Let's start with the previous flow chart of data synchronization
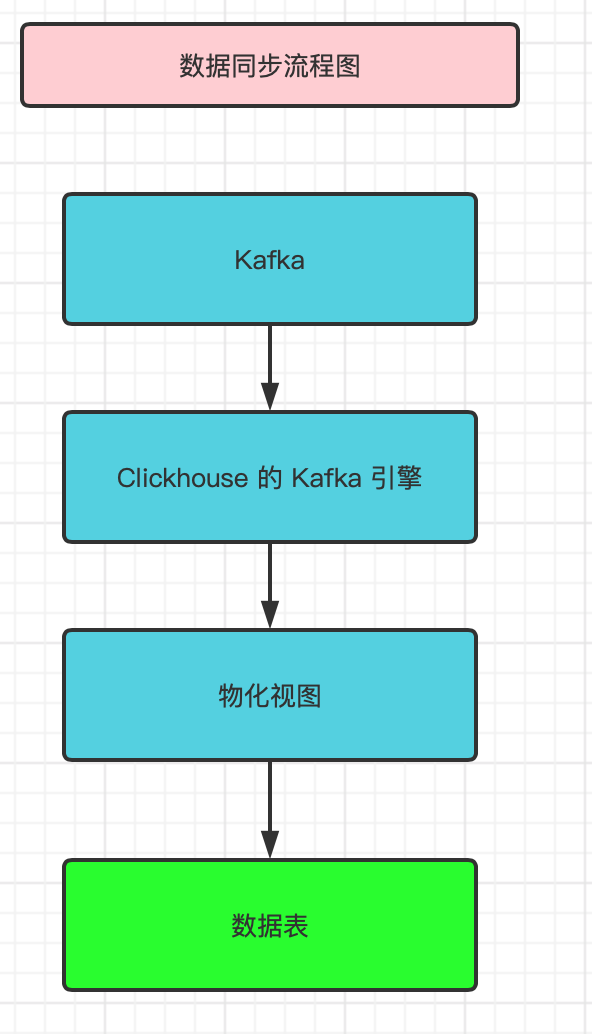
Build table
Before data synchronization, we need to create the corresponding clickhouse table. According to the above flow chart, we need to create three tables:
1. Data sheet
2.kafka engine table
3. Materialized view
data sheet
# Create data table
CREATE DATABASE IF NOT EXISTS data_sync;
CREATE TABLE IF NOT EXISTS data_sync.test
(
name String DEFAULT 'lemonNan' COMMENT 'full name',
age int DEFAULT 18 COMMENT 'Age',
gongzhonghao String DEFAULT 'lemonCode' COMMENT 'official account',
my_time DateTime64(3, 'UTC') COMMENT 'time'
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(my_time)
ORDER BY my_time
Engine table
# Create kafka engine table, address: 172.16.16.4, topic: lemonCode
CREATE TABLE IF NOT EXISTS data_sync.test_queue(
name String,
age int,
gongzhonghao String,
my_time DateTime64(3, 'UTC')
) ENGINE = Kafka
SETTINGS
kafka_broker_list = '172.16.16.4:9092',
kafka_topic_list = 'lemonCode',
kafka_group_name = 'lemonNan',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n',
kafka_schema = '',
kafka_num_consumers = 1
Materialized view
# Create materialized view CREATE MATERIALIZED VIEW IF NOT EXISTS test_mv TO test AS SELECT name, age, gongzhonghao, my_time FROM test_queue;
Data simulation
The following is the data trend of the simulation flowchart. If Kafka is installed, you can skip the installation steps.
Install kafka
kafka here is a stand-alone installation for demonstration
# Start zookeeper docker run -d --name zookeeper -p 2181:2181 wurstmeister/zookeeper # Start Kafka, Kafka_ ADVERTISED_ The ip address after listeners is the machine ip address docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --link zookeeper -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.16.16.4:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
Sending data using kafka command
# Start the producer and send a message to topic lemonCode
kafka-console-producer.sh --bootstrap-server 172.16.16.4:9092 --topic lemonCode
# Send the following message
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 18:00:00.001"}
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 18:00:00.001"}
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 18:00:00.002"}
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 23;59:59.002"}
View the data table of Clickhouse
select * from test;

At this stage, the data has been synchronized from Kafka to Clickhouse. How to say, it is more convenient.
About data copies
The table engine used here is ReplicateMergeTree. One reason for using ReplicateMergeTree is to generate multiple data copies to reduce the risk of data loss. If ReplicateMergeTree engine is used, the data will be automatically synchronized to other nodes of the same partition.
In practice, there is another way to synchronize data by using different Kafka consumer groups.
See the following figure for details:
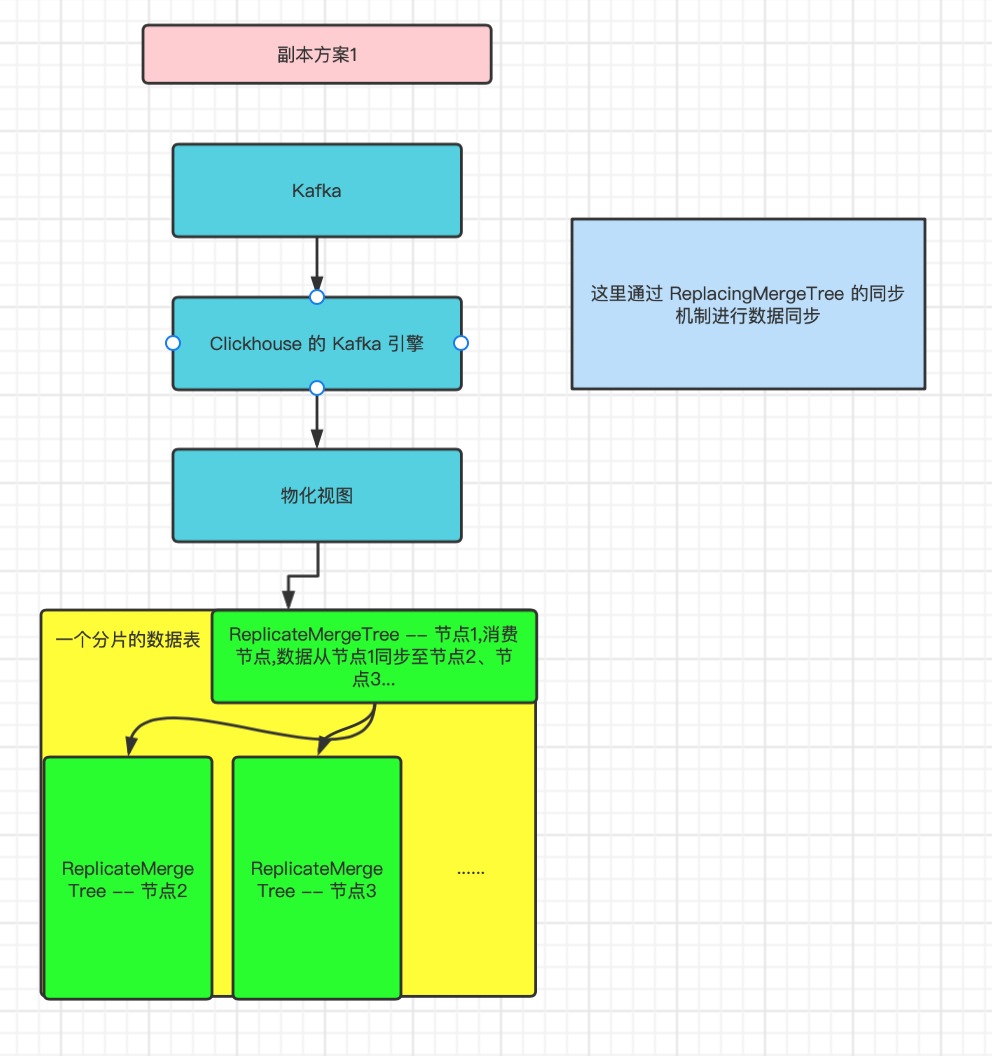
Copy scheme 1
The data is synchronized to other nodes under the same partition through the synchronization mechanism of ReplicateMergeTree, which occupies the resources of consumption nodes.
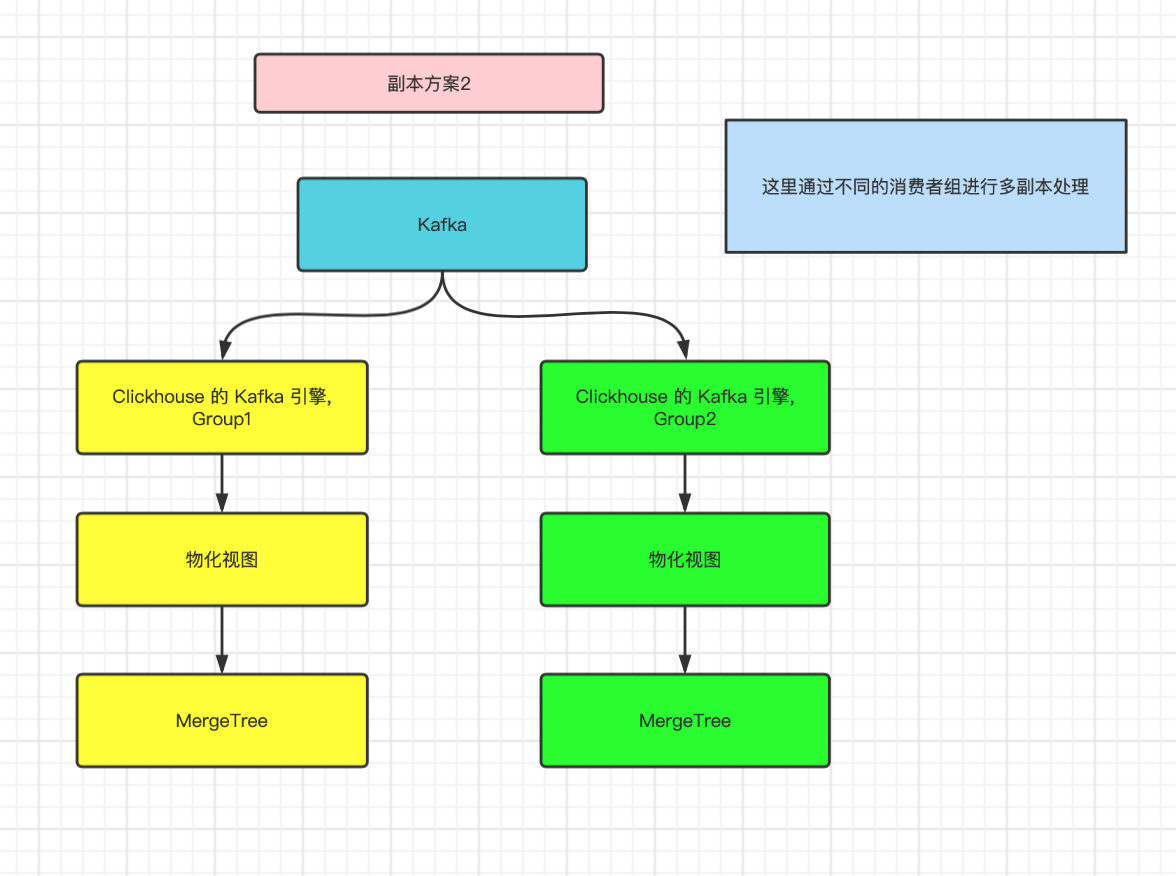
Copy scheme 2
Through Kafka's own consumption mechanism, messages are broadcast to multiple Clickhouse nodes, and data synchronization does not occupy additional resources of Clickhouse.
Pay attention to the place
Points that may need attention in the construction process
- 172.16.16.4 in this paper is the intranet ip address of the machine
- Generally, the engine table ends with queue and the materialized view ends with mv, so the recognition degree will be higher
summary
This paper introduces the scheme of data synchronization from Kafka to Clickhouse and multiple copies. Clickhouse also provides many other integration schemes, including Hive, MongoDB, S3, SQLite, Kafka, etc. for details, see the link below.
Integrated table engine: https://clickhouse.com/docs/zh/engines/table-engines/integrations/
last
Welcome to search official account number LemonCode, exchange learning together!