Handwritten database connection pool
The returned is a shared with connection_ PTR object
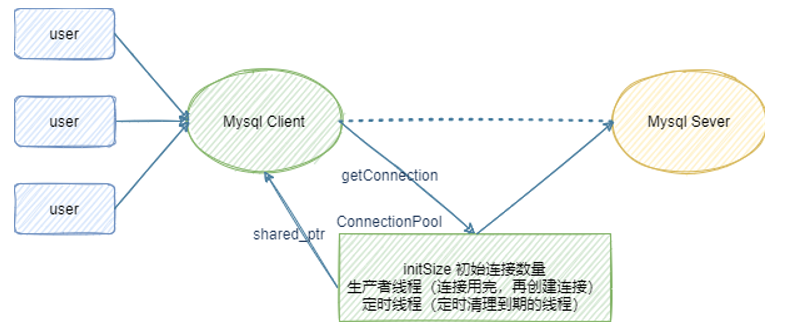
Key technical points
MySQL database programming, singleton mode, queue container, C++11 multithreading programming, thread mutual exclusion, thread synchronous communication (mutex, conditional variables) and unique_lock, CAS based atomic shaping, intelligent pointer shared_ptr, lambda expression, producer consumer thread model
Project background
In order to improve the access bottleneck of MySQL database (based on C/S design), in addition to adding cache server to cache common data (such as redis), you can also add connection pool to improve the access efficiency of MySQL Server. In the case of high concurrency, a large number of TCP triple handshakes, MySQL Server connection authentication The performance time spent by MySQL Server closing connections, recycling resources and TCP waving four times is also obvious. Increasing connection pool is to reduce the performance loss of this part.
Popular connection pools in the market include Alibaba's druid, c3p0 and apache dbcp connection pools. They can significantly improve the performance of a large number of database additions, deletions, changes and queries in a short time, but they have one thing in common: they are all implemented by Java.
Then this project is to provide the access efficiency of MySQL Server and realize the database connection pool module based on C + + code in the C/C + + project.
Introduction to connection pool function point
The connection pool generally includes the ip address, port number, user name, password and other performance parameters used for database connection, such as initial connection volume, maximum connection volume, maximum idle time, connection timeout, etc. this project is a connection pool based on C + + language, and mainly realizes the general basic functions supported by all the above connection pools.
Initial connection size: indicates that the connection pool will create an initSize number of connection connections with MySQL Server in advance. When an application initiates MySQL access, it does not need to create a new connection with MySQL Server. It can directly obtain an available connection from the connection pool. After use, it does not release the connection, Instead, return the current connection to the connection pool.
Maximum connection size: when the number of concurrent requests to access MySQL Server increases, the initial connection is not enough. At this time, more connections will be created for the application according to the number of new requests. However, the upper limit of the number of newly created connections is maxSize. Connections cannot be created indefinitely, because each connection will occupy a socket resource, Generally, the connection pool and server program are deployed on the same host. If the connection pool occupies too many socket resources, the server cannot receive too many client requests. When these connections are used, they are returned to the connection pool again for maintenance.
Maximum idle time: when there are many concurrent requests to access MySQL, the number of connections in the connection pool will increase dynamically. The upper limit is maxSize. When these connections are used up, they will be returned to the connection pool again. If these newly added connections have not been used again in the specified maxIdleTime, the newly added connection resources will be recycled. Just keep the initial connection quantity initSize connections.
Connection timeout: when the number of concurrent requests from MySQL is too large, and the number of connections in the connection pool has reached maxSize, and there are no idle connections available, then the application cannot obtain connections from the connection pool successfully. It obtains connections through blocking methods. If the connection timeout exceeds, the connection acquisition fails, Unable to access database. The project mainly realizes the four functions of the above connection pool, and the other connection pools have more expansion functions, which can be realized by themselves.
Introduction to MySQL Server parameters
mysql> show variables like ‘max_connections’; This command can view the maximum number of connections supported by MySQL Server, exceeding max_ MySQL Server will directly reject connections with the number of connections. Therefore, when using the connection pool to increase the number of connections, MySQL Server's max_ The connections parameter should also be adjusted appropriately to fit the connection upper limit of the connection pool.
Function realization design
ConnectionPool.cpp and ConnectionPool.h: connection pool code implementation
Connection.cpp and Connection.h: implementation of database operation code, addition, deletion, modification and query code
Connection pool mainly includes the following function points:
1. Connection pool only needs one instance, so ConnectionPool is designed in singleton mode
2. The Connection to MySQL can be obtained from the ConnectionPool
3. All idle connections are maintained in a thread safe Connection queue, and thread mutex lock is used to ensure thread safety of the queue
4. If the Connection queue is empty, you need to obtain another Connection. At this time, you need to dynamically create a Connection. The upper limit is maxSize
5. If the idle connection time of the queue exceeds maxIdleTime, it will be released. Only the initial initSize connections can be retained. This function node must be placed in an independent thread
6. If the Connection queue is empty and the number of connections has reached the maximum maxSize at this time, wait for connectionTimeout time. If idle connections cannot be obtained, obtaining connections fails. Here, obtain idle connections from the Connection queue. You can use mutex mutex with timeout to realize Connection timeout
7. Shared for the connection obtained by the user_ PTR is managed by smart pointer, and the function of connection release is customized with lambda expression (instead of releasing the connection, the connection is returned to the connection pool)
8. The producer consumer thread model is used to design the production and consumption of connections, and the synchronous communication mechanism between threads, condition variables and mutual exclusion locks are used
Connection pool code and detailed introduction
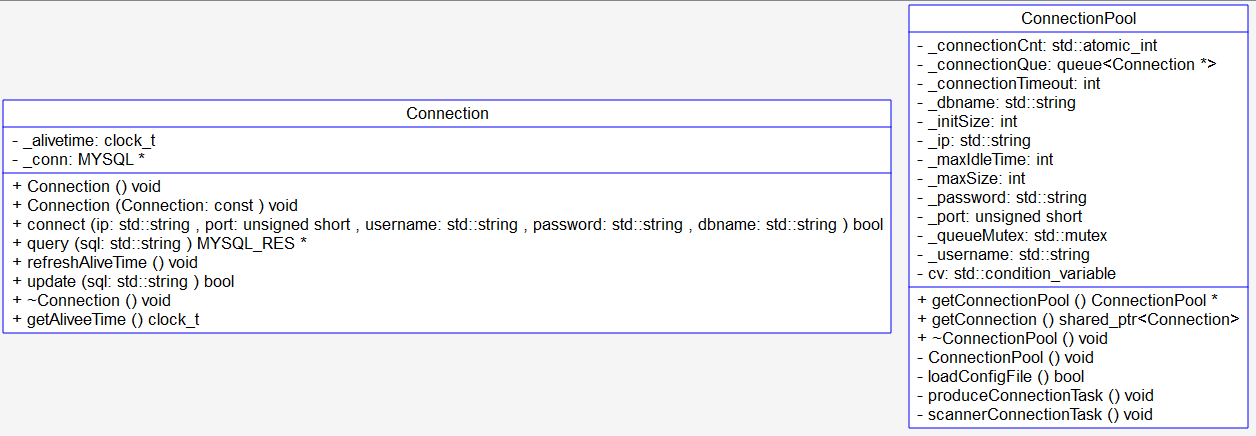
The main functions are 6 functions
Get instance, load configuration item, constructor
Producer thread (add a little when the connection is used up), consumer (Interface), timed thread (recycle resources)
shared_ptr destructor, custom delete, thread back
class ConnectionPool
{
public:
// Get connection pool object instance
static ConnectionPool* getConnectionPool();
// Provide an interface to the outside to obtain an available free connection from the connection pool
shared_ptr<Connection> getConnection(); // The interface adopts RAII and does not require user management resources
private:
// Singleton #1 constructor privatization
ConnectionPool();
// Load configuration item from configuration file
bool loadConfigFile();
// Run in a separate thread, dedicated to producing new connections
void produceConnectionTask();
// Scan idle connections that exceed maxIdleTime for connection recycling
void scannerConnectionTask();
string _ip; // mysql ip address
unsigned short _port; // mysql port number 3306
string _username; // mysql login user name
string _password; // mysql login password
string _dbname; // Connected database name
int _initSize; // Initial number of connections to the connection pool
int _maxSize; // Maximum number of connections in the connection pool
int _maxIdleTime; // Connection pool maximum idle time
int _connectionTimeout; // Timeout for connection pool to get connections
queue<Connection*> _connectionQue; // Queue for storing mysql connections
mutex _queueMutex; // Maintain thread safe mutexes for connection queues
atomic_int _connectionCnt; // Record the total number of connection connections created by the connection
condition_variable cv; // Set the condition variable, which is used to connect the communication between the production thread and the consumption thread
};
Connection pool constructor
// Construction of connection pool
ConnectionPool::ConnectionPool()
{
// Configuration item loaded
if (!loadConfigFile())
{
return;
}
// Create initial number of connections
for (int i = 0; i < _initSize; ++i)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAliveTime(); // Refresh the start time of idle
_connectionQue.push(p);
_connectionCnt++;
}
// Start a new thread as the connection producer Linux thread = > pthread_ create
thread produce(std::bind(&ConnectionPool::produceConnectionTask, this));
produce.detach();
// Start a new timing thread, scan idle connections that exceed maxIdleTime, and recycle connections
thread scanner(std::bind(&ConnectionPool::scannerConnectionTask, this));
scanner.detach();
}
Get singleton
// Thread safe lazy singleton function is reconstructed when the interface is called
ConnectionPool* ConnectionPool::getConnectionPool()
{
static ConnectionPool pool; // lock and unlock
return &pool;
}
Producer thread
// Run in a separate thread, dedicated to producing new connections
void ConnectionPool::produceConnectionTask()
{
for (;;)
{
unique_lock<mutex> lock(_queueMutex);
while (!_connectionQue.empty())
{
cv.wait(lock); // The queue is not empty. Here, the production thread enters the waiting state and releases the lock
}
// The number of connections has not reached the maximum. Continue to create new connections
if (_connectionCnt < _maxSize)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAliveTime(); // Refresh the start time of idle
_connectionQue.push(p);
_connectionCnt++;
}
// Notify the consumer thread that it is ready to consume the connection
cv.notify_all();
}
}
Consumer thread interface
// Provide an interface to the outside to obtain an available free connection from the connection pool
shared_ptr<Connection> ConnectionPool::getConnection()
{
unique_lock<mutex> lock(_queueMutex);
while (_connectionQue.empty())
{
// sleep
if (cv_status::timeout == cv.wait_for(lock, chrono::milliseconds(_connectionTimeout)))
{
if (_connectionQue.empty())
{
LOG("Getting idle connections timed out...Failed to get connection!");
return nullptr;
}
}
}
/*
shared_ptr When the smart pointer is destructed, the connection resource will be delete d directly, which is equivalent to
Call the destructor of the connection, and the connection is close d.
You need to customize shared here_ PTR releases resources by returning the connection directly to the queue
*/
shared_ptr<Connection> sp(_connectionQue.front(),
[&](Connection* pcon) {
// This is called in the server application thread, so we must consider the thread safe operation of the queue.
unique_lock<mutex> lock(_queueMutex);
pcon->refreshAliveTime(); // Refresh the start time of idle
_connectionQue.push(pcon);
});
_connectionQue.pop();
cv.notify_all(); // After consuming the connection, notify the producer thread to check. If the queue is empty, hurry to produce the connection
return sp;
}
Timed thread (reclaim connection)
// Scan idle connections that exceed maxIdleTime for connection recycling
void ConnectionPool::scannerConnectionTask()
{
for (;;)
{
// Simulation of timing effect through sleep
this_thread::sleep_for(chrono::seconds(_maxIdleTime));
// Scan the entire queue to release redundant connections
unique_lock<mutex> lock(_queueMutex);
while (_connectionCnt > _initSize)
{
Connection* p = _connectionQue.front();
if (p->getAliveeTime() >= (_maxIdleTime * 1000))
{
_connectionQue.pop();
_connectionCnt--;
delete p; // Call ~ Connection() to release the connection
}
else
{
break; // The connection of the queue head does not exceed_ maxIdleTime, there must be no other connection
}
}
}
}
Pressure test
Development platform selection
MySQL database programming, multithreading programming, thread mutual exclusion and synchronous communication operation, intelligent pointer, design pattern, container and so on can be directly implemented at the C + + language level. Therefore, the project chooses to develop directly on the windows platform. Of course, it can also be compiled and run directly with g + + on the Linux platform.
The time spent in verifying the data insertion operation. The first test uses ordinary database access operation and the second test uses database access operation with connection pool. Compared with the time spent in the same amount of data in the two operations, the performance stress test results are as follows (the computer configuration is not too high - Intel) ® Core ™ i5-8300H CPU @ 2.30GHz 2.30 GHz);
| Amount of data per thread | Time spent unused connection pool | Time spent using connection pool |
|---|---|---|
| 1000 | Single thread: 5160ms four thread: 8783ms | Single thread: 869ms four thread: 1346ms |
| 2500 | Single thread: 11614ms four thread: 18742ms | Single thread: 2170ms four thread: 3403ms |
| 5000 | Single thread: 4173ms four thread: 6813ms |
(different computers have different reduction rates)
Test code and configuration file:
- Dependency
#Configuration file for database connection pool ip=127.0.0.1 port=3306 username=root password=12345678 dbname=chat initSize=10 maxSize=1024 #The default unit of maximum idle time is seconds maxIdleTime=60 #The connection timeout is in milliseconds connectionTimeOut=100
CREATE DATABASE chart;
CREATE TABLE IF NOT EXISTS `user`(
`id` INT(11) UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(50),
`age` VARCHAR(11),
`sex` enum('male', 'female'),
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
#define _CRT_SECURE_NO_WARNINGS
#include "pch.h"
#include <iostream>
using namespace std;
#include "Connection.h"
#include "CommonConnectionPool.h"
void f() {
ConnectionPool *cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 5000; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "male");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
/*Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "male");
conn.connect("127.0.0.1", 3306, "root", "12345678", "chat");
conn.update(sql);*/
}
}
int main()
{
// Connection conn;
// conn.connect("127.0.0.1", 3306, "root", "12345678", "chat");
#if 1
clock_t begin = clock();
f();
clock_t end = clock();
std::cout << (end - begin) << "ms" << endl;
#endif
#if 1
clock_t begin4 = clock();
thread t1(f);
thread t2(f);
thread t3(f);
thread t4(f);
t1.join();
t2.join();
t3.join();
t4.join();
clock_t end4 = clock();
std::cout << (end4 - begin4) << "ms" << endl;
#endif
return 0;
}
Lazy singleton class. Instantiate yourself at the first call!
Hungry Chinese singleton class. It has been instantiated by itself during class initialization
Singleton mode is to ensure that a class has only one instance
Connection operation code
#include "pch.h"
#include "public.h"
#include "Connection.h"
#include <iostream>
using namespace std;
Connection::Connection()
{
// Initialize database connection
_conn = mysql_init(nullptr);
}
Connection::~Connection()
{
// Release database connection resources
if (_conn != nullptr)
mysql_close(_conn);
}
bool Connection::connect(string ip, unsigned short port,
string username, string password, string dbname)
{
// Connect to database
MYSQL* p = mysql_real_connect(_conn, ip.c_str(), username.c_str(),
password.c_str(), dbname.c_str(), port, nullptr, 0);
return p != nullptr;
}
bool Connection::update(string sql)
{
// Update operations insert, delete, update
if (mysql_query(_conn, sql.c_str()))
{
LOG("Update failed:" + sql);
return false;
}
return true;
}
MYSQL_RES* Connection::query(string sql)
{
// Query operation select
if (mysql_query(_conn, sql.c_str()))
{
LOG("Query failed:" + sql);
return nullptr;
}
return mysql_use_result(_conn);
}