1. Database engine
1.1 INNODB AND MYISAM
| MYISAM | INNODB | |
|---|---|---|
| Transaction support | I won't support it | support |
| Data row locking | I won't support it | support |
| Foreign key | I won't support it | support |
| Full text index | support | Not supported (full text retrieval is supported in InnoDB version 1.2. X) |
| Table space size | less | Larger, about 2 times |
General operation:
- MYISAM: space saving and fast speed
- INNODB: high security, transaction processing, multi table and multi-user operation
Location of controls in the room:
- All database files are stored in the data directory
- The essence is the storage of files
Differences of MySQL engine in physical files
- InnoDB has only one *. In the database table frm file and ibdata1 file in the parent directory (before MySQL 8.0)
- MYISAM corresponding file
- *. frm - definition file for table structure
- *. MYD data file (data)
- *. MYI index file (index)
Set the character set code of the database table -- CHARSET=utf8mb4
If it is not set, it will be the default character set encoding of MySQL ~ (Chinese is not supported!)
The default code of MySQL is Latin1, which does not support Chinese
In my Ini to configure the default encoding
2. DQL query data
SELECT syntax
SELECT [ALL | DISTINCT]
{* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[LEFT | RIGHT | INNER JOIN table_name2] -- Joint query
[ON table1.column_name=table2.column_name] -- Joint query equivalence judgment, and JOIN Use together
[WHERE column_name operator value] -- Specify the conditions to be met for the results
[GROUP BY column_name] -- Specify which fields the results are grouped by
[HAVING aggregate_function(column_name) operator value] -- Secondary conditions that must be met to filter grouped records
[ORDER BY column_name,column_name ASC|DESC] -- Specifies that query records are sorted by one or more criteria
[LIMIT {[offset,]row_count | row_countOFFSET offset}]; -- Specify which records to query from
be careful:[]Represents optional,{}Representative required
2.1 DQL(Data Query Language)
- It is used for all query operations
- It can do simple query and complex query
- The core language and the most important statement in the database
- Most frequently used statements
2.2 query data
SELECT * FROM table_name; -- Query the whole table SELECT column_name,[...column_name] FROM table_name; -- Query specified data SELECT column_name AS xxx FROM table_name AS xxx; -- Alias a table or field SELECT CONCAT(param, column_name) AS xxx FROM table_name; -- Combine fields with other strings to form a new string SELECT DISTINCT column_name FROM table_name; -- Remove the duplicate part of the query data SELECT @@auto_increment_increment; -- Query auto increment step SELECT Expression (1) + 1 (something like that) AS Result; -- Simple calculation SELECT column_name + 1 FROM table_name; -- Achieve increase and decrease
2.3 WHERE clause
Function: retrieve the qualified data in the data
- Logical operator
| operator | grammar | describe |
|---|---|---|
| and && | a and b a && b | Logic and, both are true, and the result is true |
| or | ||
| not ! | not a !a | Logical non, true is false, false is true |
SELECT column_name, [...column_name] FROM table_name WHERE column_name >= xx AND(&&) column_name <= xx; SELECT column_name, [...column_name] FROM table_name WHERE column_name BETWEEN xx AND xx; SELECT column_name, [...column_name] FROM table_name WHERE column_name != xx; SELECT column_name, [...column_name] FROM table_name WHERE NOT column_name = xx;
- Fuzzy query (comparison operator)
| operator | grammar | describe |
|---|---|---|
| IS NULL | a is null | If the operator is NULL, the result is true |
| IS NOT NULL | a is not null | If the operator is not null, the result is true |
| BETWEEN | a between b and c | If a is between b and c, the result is true |
| LIKE | a like b | SQL matches. If a matches b, the result is true |
| IN | a in b(a1,a2,a3...) | Suppose a is in one of a1, or a2... And the result is true |
% -- Wildcard (0)~(any character) _ -- Placeholder (1 character) SELECT column_name,[...column_name] FROM table_name WHERE column_name LIKE x%; -- Query data starting with a word SELECT column_name,[...column_name] FROM table_name WHERE column_name LIKE x_; -- Query data that starts with a word and has only two words IN SELECT column_name FROM table_name WHERE column_name IN(xxx,xxx,xxx); -- Query data in parentheses (equivalent to multiple or),Should be a specific value, not like LIKE So; One IN Range comparison can only be performed on one field. If you want to specify more fields, you can use AND or OR Logical operator SELECT column_name FROM table_name WHERE column_name = '' OR column_name IS NULL;
2.4 associated table query
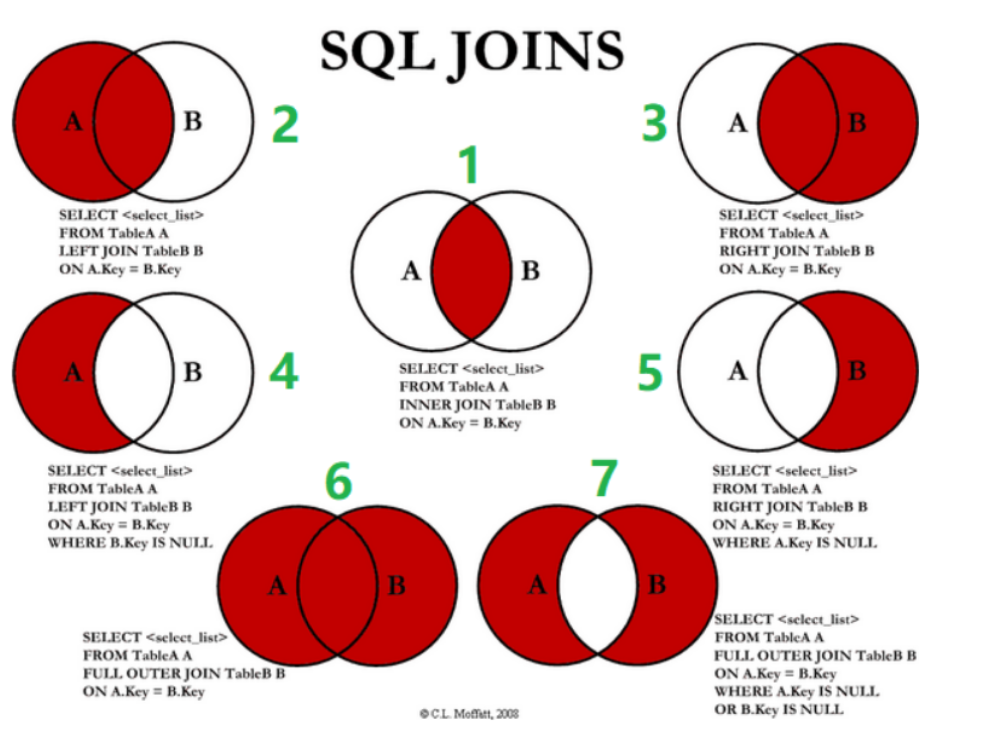
JOIN ON join query -- ON Used for joint table conditions WHERE Equivalent query -- WHERE Used for filtering conditions -- INNER JOIN Return only after matching SELECT a.column_name,[...column_name] FROM table_name AS a INNER JOIN table1_name AS b ON(amount to WHERE) a.column_name = b.column_name; -- For query intersection, the same fields should be distinguished by aliases, otherwise the system cannot distinguish them -- RIGHT JOIN Whether the right table can match the condition or not,Will eventually be retained:Can match,Correct retention; If it cannot match,All fields in the left table are set NULL. SELECT a.column_name,[...column_name] FROM table_name AS a RIGHT JOIN table1_name AS b ON a.column_name = b.column_name; -- LEFT JOIN Whether the left table can match the upper condition or not,Will eventually be retained:Can match,Correct retention; If it cannot match,All fields in the right table are set NULL. SELECT a.column_name,[...column_name] FROM table_name AS a LEFT JOIN table1_name AS b ON a.column_name = b.column_name;
| operation | describe |
|---|---|
| INNER JOIN | If there is at least one match in the table, the row is returned (only when there is a match) |
| LEFT JOIN | All values will be returned from the left table, even if there is no match in the right table (the mismatch is NULL) |
| RIGHT JOIN | All values will be returned from the right table, even if there is no match in the left table (the mismatch is NULL) |
Concatenated tables are nested in logical order
SELECT a.column_name,[...column_name] FROM table_name AS a RIGHT JOIN table1_name AS b ON a.column_name = b.column_name LEFT JOIN table2_name AS b ON a.column_name = b.column_name;
2.5 self connection
In fact, self join query is equivalent to join query. It requires two tables, but its left table (parent table) and right table (child table) are self connected. When doing self join query, it is self connected. Take two different aliases for the parent table and child table respectively, and then attach connection conditions
Simply put, it is to query in a table. The data in this table has hierarchical relationships. We can query the required data through their relationships.
SELECT a.column_name, b.column_name, [...column_name] FROM table_name AS a, table_name AS b WHERE a.column1_name = b.column2_name;
2.6 paging and sorting
- sort
-- ASC Ascending order DESC Descending order ORDER BY Put it in WHERE after SELECT column_name, [...column_name] FROM table_name WHERE column1_name = xx ORDER BY ASC(DESC); -- If the columns have the same data, you can continue to add column names to further sort. For example, use ORDER BY score DESC, gender Means press first score The columns are in reverse order. If there are the same scores, press again gender Column sorting SELECT id, name, gender, score FROM students ORDER BY score DESC, gender;
- paging
-- LIMIT The following parameters limit the display of several pieces of data OFFSET The following parameters are the starting index (starting from 0) LIMIT xx OFFSET xx Can be abbreviated as LIMIT xx((index),xx((size) SELECT column_name, [...column_name] FROM table_name WHERE column1_name = xx ORDER BY ASC(DESC) LIMIT xx OFFSET xx(LIMIT xx, xx);
Paging queries using LIMIT alone will slow down when there is a large amount of data, and should be optimized
2.7 sub query (nested query)
Nested query means that an outer query contains another inner query. That is, the WHERE part of a query uses the value obtained from another query as the query condition, and the execution order is from the inside out.
A query that embeds another SELECT statement in the WHERE clause or HAVING clause of a SELECT statement is called a nested query, also known as a subquery. Subquery is an extension of SQL statement. Its statement form is as follows:
Select < target expression 1 > [,...]
From < table or view name1 >
WHERE [expression ](select < target expression 2 > [,...]
From < table or view name 2 >)
[group by < group condition >
Having [< expression > comparison operator] (select < target expression 2 > [,...]
From < table or view name 2 >)]
1. A subquery that returns a value
When there is only one return value of a subquery, you can use comparison operators, such as =, <, >, > =, < == Connect rich queries and subqueries.
2. A subquery that returns a set of values
If the return value of a subquery is more than one but a collection, the comparison operator cannot be used directly. You can insert ANY, SOME or ALL between the comparison operator and the subquery. Among them, the equivalence relationship can use the IN operator.
-- Sub queries generally do not use sorting SELECT column_name, [...column_name] FROM table_name WHERE column_name = ( SELECT column_name, [...column_name] FROM table_name WHERE column_name = xxx ) ORDER BY column_name DESC;
2.8 grouping and filtering
GROUP BY statementgroups a result set based on one or more columns.
On grouped columns, we can use COUNT, SUM, AVG, and other functions.
The reason for adding the HAVING clause in SQL is that the WHERE keyword cannot be used with aggregate functions.
The HAVING clause allows us to filter the grouped groups of data.
SELECT column_name, function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name; -- Specify which fields the results are grouped by HAVING column_name operator value -- Secondary conditions that must be met to filter grouped records
3. MySQL function
3.1 common functions
-- Mathematical operation
SELECT ABS(-8) --absolute value
SELECT CEILING(9.4) -- Round up
SELECT FLOOR(9.4) -- Round down
SELECT RAND() -- Returns a 0~1 Random number between
SELECT SIGN() -- Sign 0 for judging a number -> 0 Negative return-1,A positive number returns 1
-- String function
SELECT CHAR_LENGTH('SolitudeAlma') -- String length
SELECT CONCAT('I', 'LOVE', 'YOU') -- Splice string
SELECT INSERT('I LOVE YOU', 1 , 1, 'He also') -- Query replacement
SELECT LOWER('I LOVE YOU') -- Convert to lowercase
SELECT UPPER('i love you') -- Convert to uppercase
SELECT INSTR('I LOVE YOU', 'Y') -- Returns the index of the first occurrence of the target string
SELECT REPLACE('I LOVE YOU', 'YOU', 'ME') -- Replace specified string
SELECT SUBSTR('I LOVE YOU', 3, 4) -- Returns the specified substring param (string, offset, length)
SELECT REVERSE('You are strong and great') -- Reverse string
-- Time and date functions
SELECT CURRENT_DATE() -- Get current date
SELECT CURDATE() -- Get current date
SELECT NOW() -- Get current time
SELECT LOCALTIME() -- Local time
SELECT SYSDATE() -- system time
SELECT YEAR(NOW) -- Other analogies
-- system
SELECT SYSTEM_USER()
SELECT USER()
SELECT VERSION()
3.2 aggregate function (common)
| Function name | describe |
|---|---|
| COUNT() | count |
| SUM() | Sum |
| AVG() | average value |
| MAX() | Maximum |
| MIN() | minimum value |
| ... | ... |
-- COUNT SELECT COUNT(column_name) FROM table_name; -- Specify columns, COUNT(field)Will ignore NULL value SELECT COUNT(*) FROM table_name; -- COUNT(*)Will not ignore NULL Number of rows for value calculation SELECT COUNT(1) FROM table_name; -- COUNT(1)Will not ignore NULL Number of rows for value calculation -- SUM SELECT SUM(column_name) AS xxx FROM table_name; -- AVG SELECT AVG(column_name) AS xxx FROM table_name; -- MAX SELECT MAX(column_name) AS xxx FROM table_name; -- MIN SELECT MIN(column_name) AS xxx FROM table_name;
3.3 MD5 encryption (extension) at database level
What is MD5?
It mainly enhances the complexity and irreversibility of the algorithm
MD5 is irreversible. In fact, it is a mapping relationship. MD5 of the same value is the same, and there may be hash collision. After MD5 of different values, it is the same, but the probability is small
The principle of MD5 website is that they have a rainbow table, but the table is not very large, so only some common strings can be decrypted correctly
INSERT INTO table_name (column_name[,column_name][,...]) VALUES(xx, xx, MD5(xx)); SELECT column_name FROM table_name WHERE column_name = MD5(xxx);
4. Services
4.1 what is a transaction
Either all succeed or all fail
- SQL execution A transfers A1000 to B - > 200 B200
- SQL executive B receives a's money A800 - > B400
Put a group of SQL into a batch for execution
Transaction principle: ACID principle, atomicity, consistency, isolation, persistence (dirty read, phantom read)
Transaction ACID understanding
Atomicity
Either all succeed or all fail
Consistency
The data integrity before and after the transaction should be consistent, 1000
Durability - commit of a transaction
Once the transaction is committed, it is irreversible and is persisted to the database
Isolation
Transaction isolation is that when multiple users access the database concurrently, the transactions opened by the database for each user cannot be disturbed by the operation data of other transactions. Multiple concurrent transactions should be isolated from each other.
Problems caused by isolation
- Dirty read: refers to that one transaction reads uncommitted data from another transaction.
- Non repeatable reading: a row of data in a table is read in a transaction, and the results are different for multiple times. (this is not necessarily a mistake, but it is wrong on some occasions)
- Virtual reading (phantom reading): refers to reading the data inserted by other transactions in one transaction, resulting in inconsistent reading.
Execute transaction
-- MySQL Transaction auto commit is enabled by default SET autocommit = 0; -- close SET autocommit = 1; -- open -- Manual transaction processing SET autocommit = 0; -- Turn off auto submit -- Transaction on START TRANSACTION -- Mark the beginning of the transaction, starting after this sql All within the same transaction -- Commit: persistent once committed COMMIT; -- Rollback: rollback to the original state ROLLBACK; -- End of transaction SET autocommit = 1; -- Turn on auto submit -- understand SAVEPOINT savepoint_name; -- Set a transaction savepoint ROLLBACK TO SAVEPOINT savepoint_name; -- Rollback to savepoint RELEASE SAVEPOINT savepoint_name; -- Delete savepoint
5. Index
MySQL's official definition of Index is: Index is a data structure that helps MySQL obtain data efficiently.
By extracting the sentence trunk, we can get the essence of index: index is a data structure.
5.1 index classification
- Primary key (PRIMARY KEY)
- Unique identifier. The primary key cannot be repeated. There is only one column as the primary key
- Unique key
- Avoid duplicate columns. Unique indexes can be repeated, and multiple columns can be identified as unique indexes
- General index (KEY/INDEX)
- By default, it is set with the index/key keyword
- Full text index (FULLTEXT)
- Fast positioning data
Basic grammar
-- Use of index
-- 1,Add indexes to fields when creating tables
-- 2,After creation, increase the index
-- Show all index information
SHOW INDEX FROM table_name;
-- Add an index
ALTER TABLE table_name ADD index_name(column_name);
-- EXPLAIN analysis sql Status of implementation
EXPLAIN SELECT * FROM table_name; -- Non full text index
EXPLAIN SELECT * FROM table_name WHERE MATCH(column_name) AGAINST('xx'); -- Full text index
5.2 test index
Insert a million pieces of data
--Insert 100 w Data bar
DELIMITER $$ -- The flag must be written before the function is written
SET GLOBAL log_bin_trust_function_creators = TRUE; -- Function creation is not allowed until it is set
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
-- Insert statement
INSERT INTO da(id) VALUES(i);
SET i = i + 1;
END WHILE;
RETURN i;
END;
SELECT mock_data() -- Execute this function to generate one million pieces of data
SELECT * FROM table_name WHERE column_name = 'Middle value, not too forward'; -- time: 0.47s
CREATE INDEX index_name ON table_name(column_name); -- Create index
SELECT * FROM table_name WHERE column_name = 99999; -- time: 0.001s
EXPLAIN SELECT * FROM table_name WHERE column_name = 99999;
EXPLAIN results:

Index plays an important role when there is a large amount of data
5.3 indexing principle
- The more indexes, the better
- Do not index data that changes frequently
- Tables with small amounts of data do not need to be indexed
- Indexes are usually added to fields commonly used for queries
Indexed data structure
Hash type index
Btree: default data structure of InnoDB
read:
https://blog.codinglabs.org/articles/theory-of-mysql-index.html https://blog.csdn.net/jiadajing267/article/details/81269067
6. Rights management and backup
6.1 user management
SQL command operation
User table: MySQL user
Essence: add, delete, modify and query this table
-- Create user
CREATE USER user_name IDENTIFIED BY 'password'; -- user_name Is the user name, password It's a password
-- Modify password (modify the password of the current user)
SET PASSWORD = PASSWORD('password');
-- Change password (specify user)
SET PASSWORD FOR user_name = PASSWORD('password');
-- rename
RENAME USER pri_user_name TO now_user_name;
-- User authorization
GRANT ALL PRIVILEGES ON *.* TO user_name; -- ALL PRIVILEGES All rights (except authorizing others, root (only) *.* library.surface
-- Query authority
SHOW GRANTS FOR user_name -- Specify the user's permissions
SHOW GRANTS FOR root@localhost
-- Revoke permissions
REVOKE ALL PRIVILEGES ON *.* FROM user_name;
-- delete user
DROP USER user_name;
6.2 database backup
Why backup:
- Ensure that important data is not lost
- Data transfer
MySQL database backup method
- Copy physical files directly
- Export in visualizer
- Export -- > mysqldump using the command line
-- h host_name u user_name p password database_name table_name > path mysqldump -h localhost - u root -p password database_name table_name > path; -- h host_name u user_name p password database_name table1_name table2_name table3_name > path mysqldump -h localhost - u root -p password database_name table1_name table2_name table3_name> path; -- h host_name u user_name p password database_name > path mysqldump -h localhost - u root -p password database_name > path; -- Import -- In case of login, switch to the specified database -- source file source path; mysql -u root -ppassword database_name < path;
7. Standardize database design
7.1 why design is needed
When the database is complex, we need to design it
Poor database design:
- Data redundancy, waste of space
- Database insertion and deletion are troublesome and abnormal
- Poor program performance
Good database design:
- Save memory space
- Ensure the integrity of the database
- It is convenient for us to develop the system
In software development, the design of database
- Analysis requirements: analyze the requirements of the business and the database to be processed
- Outline design: design relationship diagram E-R diagram
Steps to design database: (personal blog)
- Collect information and analyze requirements
- User table (user login and logout, user's personal information, blogging, creating categories (multi person blog))
- Classification table (article classification, who created it)
- Article class (information of the article)
- Friend chain list (friend chain information)
- User defined table (system information, a key word, or some main fields) key:value
- Identify entities (implement requirements to each field)
- Identify relationships between entities
- Write an article: user -- > blog
- Create category: user -- > category
- Attention: user -- > User
- Friend chain: links
- Comment: user -- > user -- > blog
7.2 three paradigms
Why data normalization?
- Duplicate information
- Update exception
- Insert exception
- Unable to display information normally
- Delete exception
- Missing valid information
Three paradigms
First normal form (1NF)
Each column of the database table is required to be an indivisible atomic data item
Atomicity: ensure that each column cannot be further divided
Second paradigm (2NF)
Premise: meet the first paradigm
Each table describes only one thing
Third paradigm (3NF)
Premise: meet the second paradigm
The third paradigm needs to ensure that each column of data in the data table is directly related to the primary key, not the profile.
Normative and performance issues
The associated query cannot have more than three tables
- Considering the needs and objectives of commercialization, the performance of database (cost, user experience) is more important
- In the problem of specification performance, we need to properly consider the standardization
- Deliberately add some redundant fields to some tables. (multi table query -- > single table query)
- Deliberately add some calculated columns (query with large data volume reduced to small data volume: index)
8. JDBC
8.1 JDBC
In order to simplify the (unified database) operation of developers, SUN company provides a (Java database operation) specification, commonly known as JDBC
The implementation of these specifications is done by specific manufacturers
For developers, we only need to master the operation of JDBC interface
java.sql
javax.sql
Database driver package
8.2 first JDBC program
Create test database
CREATE DATABASE `jdbc_study` CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
USE `jdbc_study`;
CREATE TABLE `users`(
`id` INT PRIMARY KEY,
`name` VARCHAR(40),
`password` VARCHAR(40),
`email` VARCHAR(60),
birthday DATE
);
INSERT INTO `users`(`id`,`NAME`,`PASSWORD`,`email`,`birthday`)
VALUES('1','zhangsan','123456','zs@sina.com','1980-12-04'),
('2','lisi','123456','lisi@sina.com','1981-12-04'),
('3','wangwu','123456','wangwu@sina.com','1979-12-04')
-
Create a project
-
Import database driver
-
Write test code
package com.JDBC.MySQL;
import java.sql.*;
public class JDBC_TEST {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//1. Load drive
Class.forName("com.mysql.cj.jdbc.Driver"); //Fixed writing, loading driver 8.0 writing
//com. mysql. jdbc. Below Driver 8
//2. User information and url
String url = "jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true";
String userName = "root";
String password = "";
//3. The connection is successful, and the database object
Connection connection = DriverManager.getConnection(url, userName, password);
//4. Execute SQL object
Statement statement = connection.createStatement();
//5. The object executing SQL executes SQL. There may be results. View the returned results
String sql = "SELECT * FROM users";
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
System.out.println("id:" + resultSet.getInt("id"));
System.out.println("name:" + resultSet.getString("name"));
System.out.println("password:" + resultSet.getString("password"));
System.out.println("email:" + resultSet.getString("email"));
System.out.println("birthday:" + resultSet.getString("birthday"));
}
//6. Release the connection
resultSet.close();
statement.close();
connection.close();
}
}
Steps:
- Load driver
- Connect to database Drive Manager
- Get the Statement object executing sql
- Get the returned result set
- Release connection
DriverManager
// DriverManager.registerDriver(new com.mysql.jdbc.Driver());
Class.forName("com.mysql.cj.jdbc.Driver"); //Fixed writing, loading driver 8.0 writing
Connection connection = DriverManager.getConnection(url, userName, password);
// connection represents the database
// Database settings auto commit
// Transaction commit
// Transaction rollback
connection.rollback();
connection.commit();
connection.setAutoCommit(true);
URL
String url = "jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true"; // mysql -- 3306 // Protocol: / / hostname: port / database_ name? param1¶m2... //oralce -- 1521 // jdbc:oralce:thin:@localhost:1521:sid
Statement object executing SQL PrapareStatement object executing SQL
String sql = "SELECT * FROM users"; statement.executeQuery();// Query operation, return ResultSet statement.execute(); // Execute any SQL statement.executeUpdate(); // Update, insert, delete. This is used to return the number of affected rows
ResultSet query result set: encapsulates all query results
Gets the specified data type
// unknown type
resultSet.getObject("id");
// Specify type
resultSet.getString("id");
resultSet.getFloat("id");
resultSet.getDouble("id");
resultSet.getInt("id");
Traversal (pointer)
//As for why it's OK, just Baidu resultSet.next();//Move to next data resultSet.previous();//Move to previous line resultSet.beforeFirst();//Move to first data resultSet.afterLast();//Move to last data resultSet.absolute(row);//Move to specified row
Release resources
//Release resources resultSet.close(); statement.close(); connection.close();
8.3 Statement object
The Statement object in JDBC is used to send SQL statements to the database. To complete the addition, deletion, modification and query of the database, you only need to send the addition, deletion, modification and query statements to the database through this object.
The executeUpdate method of the Statement object is used to send the sql Statement of addition, deletion and modification to the database. After the executeUpdate is executed, an integer will be returned (that is, the addition, deletion and modification Statement causes several rows of data in the database to change)
The executeQuery method of the Statement object is used to send query statements to the database, and the executeQuery method returns the ResultSet object representing the query results.
CRUD operation - create
Use the executeUpdate(String sql) method to add data. Example operations:
Statement statement = connection.createStatement();
String sql = "INSERT INTO table_name(...)VALUES(...)";
int num = statement.executeUpdate(sql);
if(num > 0) {
System.out.println("Insert successful");
}
CRUD operation - delete
Use the executeUpdate(String sql) method to delete data. Examples:
Statement statement = connection.createStatement();
String sql = "DELETE FROM table_name WHERE column_name = xx";
int num = statement.executeUpdate(sql);
if(num > 0) {
System.out.println("Delete succeeded");
}
CRUD operation - update
Use the executeUpdate(String sql) method to modify the data. Examples:
Statement statement = connection.createStatement();
String sql = "UPDATE table_name SET column_name = 'xx' WHERE column1_name = 'xx'";
int num = statement.executeUpdate(sql);
if(num > 0) {
System.out.println("Modified successfully");
}
CRUD operation - read
Use the executeQuery(String sql) method to complete the data query operation. Example operations:
Statement statement = connection.createStatement();
String sql = "SELECT * FROM table_name WHERE column_name = xx";
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()) {
//According to the data type of the obtained column, respectively call the corresponding methods of resultSet to map to java objects
}
code implementation
- Extraction tool class
package com.JDBC.MySQL.utils;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JDBC_Utils {
private static String url = null;
private static String username = null;
private static String password = null;
static {
try {
InputStream inputStream = JDBC_Utils.class.getClassLoader().getResourceAsStream("db.properties");
Properties properties = new Properties();
properties.load(inputStream);
String driver = properties.getProperty("driver");
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
//The driver only needs to be loaded once
Class.forName(driver);
} catch (Exception e) {
e.printStackTrace();
}
}
//Get connection
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(url, username, password);
}
//Release resources
public static void release(Connection connection, Statement statement, ResultSet resultSet) {
if(resultSet != null) {
try {
resultSet.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(statement != null) {
try {
statement.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(connection != null) {
try {
connection.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//db.properties should be placed under src. The following is also used. web projects are different
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true
username=root
password=
- Preparation, addition, deletion and modification
//You only need to modify the SQL to add, delete or modify
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class InsertTest {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//Get database connection
statement = connection.createStatement();//Get SQL execution object
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(4, 'SolitudeAlma', " +
"'123', '2333@qq.com', '2021-08-07')";
int i = statement.executeUpdate(sql);
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,statement,resultSet);
}
}
}
- query
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.*;
public class SelectTest {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try{
connection = JDBC_Utils.getConnection();
statement = connection.createStatement();
String sql = "SELECT * FROM users WHERE id = 1";
resultSet = statement.executeQuery(sql);
while(resultSet.next()) {
String name = resultSet.getString("name");
System.out.println(name);
}
}catch(SQLException e) {
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,statement,resultSet);
}
}
}
SQL injection
There is a vulnerability in SQL, which will be attacked, resulting in data disclosure, and SQL may be spliced
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class SQLInjection {
public static void main(String[] args) {
//login("zhangsan", "123456");
login("'or' 1=1", "'or' 1=1");
}
//Sign in
public static void login(String username, String password) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//Get database connection
statement = connection.createStatement();//Get SQL execution object
// SELECT * FROM users WHERE `name` = '' or '1=1' AND `password` = '' or '1=1';
String sql = "SELECT * FROM users WHERE `name` = '" + username + "' AND `password` = '" + password + "'";
resultSet = statement.executeQuery(sql);
while(resultSet.next()) {
String name = resultSet.getString("name");
String pwd = resultSet.getString("password");
System.out.println(name);
System.out.println(pwd);
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,statement,resultSet);
}
}
}
8.4 PrepareStatement object
PreparementStatement can prevent SQL injection and is more efficient
- Add, delete, modify and query
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.util.Date;
import java.sql.*;
public class InsertTest01 {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//Get database connection
//difference
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(?, ?, ?, ?, ?)";
//Assign parameters manually
preparedStatement = connection.prepareStatement(sql);//Precompiled SQL, write SQL first, and then do not execute
preparedStatement.setInt(1, 5);
preparedStatement.setString(2, "solitudealma");
preparedStatement.setString(3, "1223");
preparedStatement.setString(4, "123@qq.com");
//Note: SQL Date database
// util.Date Java new Date().getTime() get timestamp
preparedStatement.setDate(5, new java.sql.Date(new Date().getTime()));
int i = preparedStatement.executeUpdate();
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,preparedStatement,resultSet);
}
}
}
- SQL injection
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.*;
public class SQLInjection01 {
public static void main(String[] args) {
//login("zhangsan", "123456");
login("'or' 1=1", "'or' 1=1");
}
//Sign in
public static void login(String username, String password) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();//Get database connection
// PrepareStatement prevents the essence of SQL injection from treating the parameters passed in as characters
// Suppose there are escape characters, such as' will be directly escaped
String sql = "SELECT * FROM users WHERE `name` = ? AND `password` = ?";
preparedStatement = connection.prepareStatement(sql);//Get SQL execution object
preparedStatement.setString(1, username);
preparedStatement.setString(2, password);
resultSet = preparedStatement.executeQuery();
while(resultSet.next()) {
String name = resultSet.getString("name");
String pwd = resultSet.getString("password");
System.out.println(name);
System.out.println(pwd);
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils.release(connection,preparedStatement,resultSet);
}
}
}
8.5 affairs
code implementation
- Open transaction
connection.setAutoCommit(false);
- After a group of business is executed, submit the transaction
- You can define the rollback statement displayed in the catch statement, but the default failure will rollback
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.*;
public class TransactionTest {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();
//Turning off the transaction auto commit of the database automatically turns on the transaction
connection.setAutoCommit(false);// Open transaction
String sql1 = "UPDATE account SET money = money - 100 WHERE name = 'A'";
preparedStatement = connection.prepareStatement(sql1);
preparedStatement.executeUpdate();
String sql2 = "UPDATE account SET money = money + 100 WHERE name = 'B'";
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();
//After the business is completed, submit the transaction
connection.commit();
System.out.println("Success");
} catch (SQLException e) {
//Failure is automatically rolled back (default)
try {
assert connection != null;
connection.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally {
JDBC_Utils.release(connection, preparedStatement, resultSet);
}
}
}
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class TransactionTest01 {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils.getConnection();
//Turning off the transaction auto commit of the database automatically turns on the transaction
connection.setAutoCommit(false);// Open transaction
String sql1 = "UPDATE account SET money = money - 100 WHERE name = 'A'";
preparedStatement = connection.prepareStatement(sql1);
preparedStatement.executeUpdate();
String sql2 = "SELECT * FROM account WHERE name = 'A'";
preparedStatement = connection.prepareStatement(sql2);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
String name = resultSet.getString("name");
float money = resultSet.getFloat("money");
System.out.println(name + " " + money);
}
// Manufacturing error
int error = 1 / 0;
String sql3 = "UPDATE account SET money = money + 100 WHERE name = 'B'";
preparedStatement = connection.prepareStatement(sql3);
preparedStatement.executeUpdate();
//After the business is completed, submit the transaction
connection.commit();
System.out.println("Success");
} catch (SQLException e) {
//Failure is automatically rolled back (default)
try {
assert connection != null;
connection.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally {
JDBC_Utils.release(connection, preparedStatement, resultSet);
}
}
}
8.6 database connection pool
Database connection - execution complete - release
Connection -- > release is a waste of system resources
Pooling Technology: prepare some pre prepared resources and connect the pre prepared resources
Minimum number of connections: 10
Maximum number of connections: 100. The service carrying limit exceeds the queuing limit
Waiting timeout: 100ms
Write a connection pool to implement an interface DataSource
Open source data source implementation
DBCP
C3P0
Druid: Ali
After using these database connection pools, we don't need to write code to connect to the database in the project development
DBCP
Required jar packages:
commons-dbcp-1.4,commons-pool-1.6
package com.JDBC.MySQL.utils;
import org.apache.commons.dbcp.BasicDataSource;
import org.apache.commons.dbcp.BasicDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JDBC_Utils_DBCP {
private static DataSource dataSource = null;
static {
try {
InputStream inputStream = JDBC_Utils.class.getClassLoader().getResourceAsStream("dbcpConfig.properties");
Properties properties = new Properties();
properties.load(inputStream);
//Create data source factory pattern -- > create
dataSource = BasicDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
//Get connection
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();// Get connection from data source
}
//Release resources
public static void release(Connection connection, Statement statement, ResultSet resultSet) {
if(resultSet != null) {
try {
resultSet.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(statement != null) {
try {
statement.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(connection != null) {
try {
connection.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//Test code
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils_DBCP;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Date;
public class DBCP_TEST {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils_DBCP.getConnection();//Get database connection
//difference
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(?, ?, ?, ?, ?)";
//Assign parameters manually
preparedStatement = connection.prepareStatement(sql);//Precompiled SQL, write SQL first, and then do not execute
preparedStatement.setInt(1, 6);
preparedStatement.setString(2, "solitudealma");
preparedStatement.setString(3, "1223");
preparedStatement.setString(4, "123@qq.com");
//Note: SQL Date database
// util.Date Java new Date().getTime() get timestamp
preparedStatement.setDate(5, new java.sql.Date(new Date().getTime()));
int i = preparedStatement.executeUpdate();
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils_DBCP.release(connection,preparedStatement,resultSet);
}
}
}
// dbcpConfig.properties #connections setting up driverClassName=com.mysql.cj.jdbc.Driver url=jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true username=root password= #!-- Initialize connection-- initialSize=10 #Maximum number of connections maxActive=50 #!-- Maximum idle connections-- maxIdle=20 #!-- Minimum idle connection-- minIdle=5 #!-- The timeout wait time is in milliseconds. 6000 milliseconds / 1000 equals 60 seconds-- maxWait=60000 #The format of the connection property attached when the JDBC driver establishes a connection must be: [property name = property;] #Note: the user and password attributes will be explicitly passed, so there is no need to include them here. connectionProperties=useUnicode=true;characterEncoding=UTF8 #Specifies the auto commit status of connections created by the connection pool. defaultAutoCommit=true #driver default specifies the read-only status of connections created by the connection pool. #If this value is not set, the "setReadOnly" method will not be called. (some drivers do not support read-only mode, such as Informix) defaultReadOnly= #driver default specifies the transaction level (TransactionIsolation) of the connection created by the connection pool. #Available values are one of the following: (see javadoc for details.) NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE defaultTransactionIsolation=READ_UNCOMMITTED
C3P0
Required jar package
c3p0-0.9.5.5,mchange-commons-java-0.2.20
//encapsulation
package com.JDBC.MySQL.utils;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBC_Utils_C3P0 {
private static ComboPooledDataSource dataSource = null;
static {
try {
//Code configuration
//dataSource = new ComboPooledDataSource();
//dataSource.setDriverClass();
//dataSource.setUser();
//dataSource.setPassword();
//dataSource.setJdbcUrl();
//dataSource.setMaxPoolSize();
//dataSource.setMinPoolSize();
//Create data source factory mode -- > use default configuration without parameters
dataSource = new ComboPooledDataSource("MySQL");//Configuration file writing
} catch (Exception e) {
e.printStackTrace();
}
}
//Get connection
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();// Get connection from data source
}
//Release resources
public static void release(Connection connection, Statement statement, ResultSet resultSet) {
if(resultSet != null) {
try {
resultSet.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(statement != null) {
try {
statement.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
if(connection != null) {
try {
connection.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
}
}
package com.JDBC.MySQL;
import com.JDBC.MySQL.utils.JDBC_Utils_C3P0;
import com.JDBC.MySQL.utils.JDBC_Utils_DBCP;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Date;
public class C3P0_TEST {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBC_Utils_C3P0.getConnection();//Get database connection
//difference
String sql = "INSERT INTO users(`id`, `name`, `password`, `email`, `birthday`)VALUES(?, ?, ?, ?, ?)";
//Assign parameters manually
preparedStatement = connection.prepareStatement(sql);//Precompiled SQL, write SQL first, and then do not execute
preparedStatement.setInt(1, 7);
preparedStatement.setString(2, "solitudealma");
preparedStatement.setString(3, "1223");
preparedStatement.setString(4, "123@qq.com");
//Note: SQL Date database
// util.Date Java new Date().getTime() get timestamp
preparedStatement.setDate(5, new java.sql.Date(new Date().getTime()));
int i = preparedStatement.executeUpdate();
if(i > 0) {
System.out.println("Success to insert");
}
}catch (SQLException e){
e.printStackTrace();
}finally {
JDBC_Utils_C3P0.release(connection,preparedStatement,resultSet);
}
}
}
//The file name must be c3p0 config xml
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<!--
c3p0 Default (default) configuration for
If in code ComboPooledDataSource ds=new ComboPooledDataSource();This means that c3p0 Default for (default)
-->
<default-config>
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=UTC</property>
<property name="user">root</property>
<property name="password">1209zyy,</property>
<property name="acquireIncrement">5</property>
<property name="initialPoolSize">10</property>
<property name="minPoolSize">5</property>
<property name="maxPoolSize">20</property>
</default-config>
<!--
c3p0 Named configuration for,
If in code“ ComboPooledDataSource ds = new ComboPooledDataSource("MySQL");"This means that the name yes mysql Default for (default)
-->
<named-config name="MySQL">
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/jdbc_study?useUnicode=true&characterEncoding=utf8&useSSL=true</property>
<property name="user">root</property>
<property name="password">1209zyy,</property>
<property name="acquireIncrement">5</property>
<property name="initialPoolSize">10</property>
<property name="minPoolSize">5</property>
<property name="maxPoolSize">20</property>
</named-config>
</c3p0-config>
conclusion
No matter what data source is used, the essence is the same. The DataSource interface will not change, and the method will not change
Subsidiary code
All resources come from the submission video of station B of crazy God