Image classification on Kaggle (CIFAR-10)
Now, we will use the knowledge we learned in the previous sections to participate in the Kaggle competition, which solves the problem of CIFAR-10 image classification. The competition website is https://www.kaggle.com/c/cifar-10
# The network in this section needs a long training time # You can visit at Kaggle: # https://www.kaggle.com/boyuai/boyu-d2l-image-classification-cifar-10 import numpy as np import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms import os import time
print("PyTorch Version: ",torch.__version__)#PyTorch Version: 1.3.0
Getting and organizing datasets
The competition data is divided into training set and test set. The training set contains 50000 pictures. The test set contains 300000 pictures. The image format of the two data sets is PNG, the height and width are 32 pixels, and there are three color channels (RGB). The images cover 10 categories: aircraft, cars, birds, cats, deer, dogs, frogs, horses, boats and trucks. To make it easier, we provide a small sample of the above data set. "Train. Zip" contains 80 training samples, while "test. Zip" contains 100 test samples. Their uncompressed folder names are "train" and "test" respectively.
image enhancement
data_transform = transforms.Compose([ transforms.Resize(40), transforms.RandomHorizontalFlip(), transforms.RandomCrop(32), transforms.ToTensor() ]) trainset = torchvision.datasets.ImageFolder(root='/home/kesci/input/CIFAR102891/cifar-10/train' , transform=data_transform)
trainset[0][0].shape
torch.Size([3, 32, 32])
data = [d[0].data.cpu().numpy() for d in trainset] np.mean(data)
0.4676536
np.std(data)
0.23926772
# image enhancement transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), #First fill in 0 around, then cut the image randomly to 32 * 32 transforms.RandomHorizontalFlip(), #Half the probability of image flipping, half the probability of image not flipping transforms.ToTensor(), transforms.Normalize((0.4731, 0.4822, 0.4465), (0.2212, 0.1994, 0.2010)), #R. Mean and variance used for normalization of each layer of G, B ]) transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4731, 0.4822, 0.4465), (0.2212, 0.1994, 0.2010)), ])
Import dataset
train_dir = '/home/kesci/input/CIFAR102891/cifar-10/train' test_dir = '/home/kesci/input/CIFAR102891/cifar-10/test' trainset = torchvision.datasets.ImageFolder(root=train_dir, transform=transform_train) trainloader = torch.utils.data.DataLoader(trainset, batch_size=256, shuffle=True) testset = torchvision.datasets.ImageFolder(root=test_dir, transform=transform_test) testloader = torch.utils.data.DataLoader(testset, batch_size=256, shuffle=False) classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'forg', 'horse', 'ship', 'truck']
Definition model
ResNet-18 network structure: ResNet full name Residual Network. Kaiming He's deep recurrent learning for image recognition won the best paper of CVPR. The deep Residual Network proposed by him in 2015 can be said to have washed all the major competitions in the aspect of image, and won many championships with absolute advantage. Moreover, on the premise of ensuring the accuracy of the network, the depth of the network has reached 152 layers, and then further increased to 1000 layers.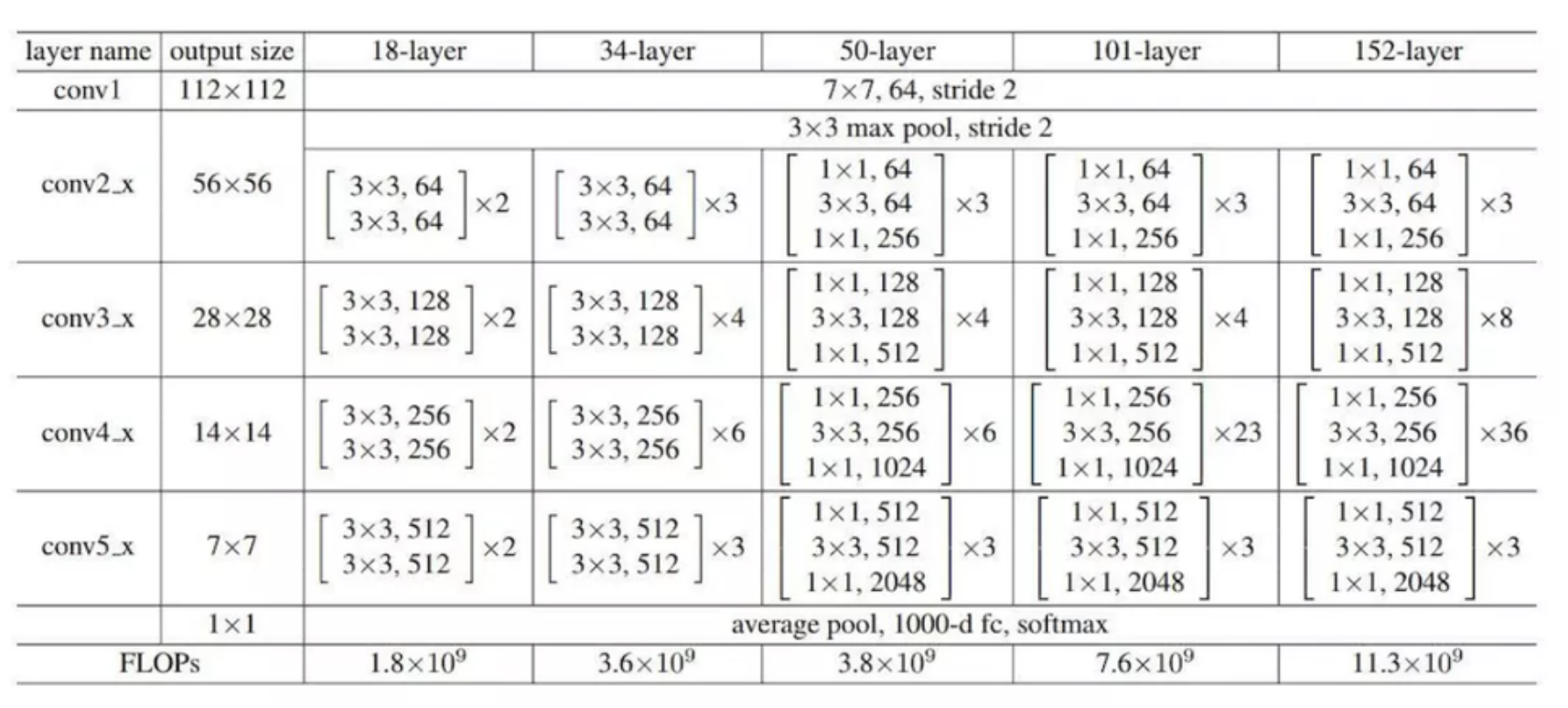
class ResidualBlock(nn.Module): # When we define a network, we usually create a new subclass by inheriting torch.nn.Module def __init__(self, inchannel, outchannel, stride=1): super(ResidualBlock, self).__init__() #torch.nn.Sequential is a Sequential container where modules are added to the modules in the order passed in the constructor. self.left = nn.Sequential( nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False), # Add the first volume accumulation layer and call Conv2d() in nn nn.BatchNorm2d(outchannel), # Normalize the data nn.ReLU(inplace=True), # The modified linear element is a commonly used activation function in artificial neural network nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(outchannel) ) self.shortcut = nn.Sequential() if stride != 1 or inchannel != outchannel: self.shortcut = nn.Sequential( nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(outchannel) ) # For later Union, judge whether the shape of Y = self.left(X) is the same as X def forward(self, x): # The features of the two modules are combined and the final features are obtained by using the ReLU activation function. out = self.left(x) out += self.shortcut(x) out = F.relu(out) return out class ResNet(nn.Module): def __init__(self, ResidualBlock, num_classes=10): super(ResNet, self).__init__() self.inchannel = 64 self.conv1 = nn.Sequential( # Three 3 x 3 convolution kernels are used instead of 7 x 7 convolution kernels to reduce model parameters nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(64), nn.ReLU(), ) self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1) self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2) self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2) self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2) self.fc = nn.Linear(512, num_classes) def make_layer(self, block, channels, num_blocks, stride): strides = [stride] + [1] * (num_blocks - 1) #The stride of the first ResidualBlock is specified by the function parameter string of make? Layer # , the next num ﹣ blocks-1 ResidualBlock stride is 1 layers = [] for stride in strides: layers.append(block(self.inchannel, channels, stride)) self.inchannel = channels return nn.Sequential(*layers) def forward(self, x): out = self.conv1(x) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.fc(out) return out def ResNet18(): return ResNet(ResidualBlock)
Training and testing
# Define whether to use GPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # Super parameter setting EPOCH = 20 #Number of traversal data sets pre_epoch = 0 # Define the number of times the dataset has been traversed LR = 0.1 #Learning rate # Model definition ResNet net = ResNet18().to(device) # Define loss function and optimization method criterion = nn.CrossEntropyLoss() #The loss function is cross entropy, which is often used in multi classification problems optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4) #The optimization method is mini batch momentum SGD, and L2 regularization (weight attenuation) is adopted # train if __name__ == "__main__": print("Start Training, Resnet-18!") num_iters = 0 for epoch in range(pre_epoch, EPOCH): print('\nEpoch: %d' % (epoch + 1)) net.train() sum_loss = 0.0 correct = 0.0 total = 0 for i, data in enumerate(trainloader, 0): #Used to combine a traversable data object (such as a list, tuple, or string) into an index sequence, listing both data and data subscripts, #The subscript starts at 0 and returns the enumerate object. num_iters += 1 inputs, labels = data inputs, labels = inputs.to(device), labels.to(device) optimizer.zero_grad() # Clear gradient # forward + backward outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() sum_loss += loss.item() * labels.size(0) _, predicted = torch.max(outputs, 1) #Select the largest value in each column as the prediction result total += labels.size(0) correct += (predicted == labels).sum().item() # loss and accuracy printed every 20 batch es if (i + 1) % 20 == 0: print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% ' % (epoch + 1, num_iters, sum_loss / (i + 1), 100. * correct / total)) print("Training Finished, TotalEPOCH=%d" % EPOCH)

