01 introduction
Through the previous blog posts, we know the concept and principle of DataX:
- DataX tutorial (01) - getting started
- DataX tutorial (02) - complete process of running dataX in IDEA (filling all pits)
- DataX tutorial (03) - source code interpretation (super detailed version)
This article needs to explain the configuration of DataX, that is, compiling and packaging the bin directory configuration file:

And the configuration file of the conf Directory:

There are also configuration files for the job directory:

02 bin directory file parsing
To analyze the files in the bin directory, you need to have a certain python foundation. You have written relevant columns before. For interested children's shoes, please refer to the following: Python column
In the bin directory, you can see several files, namely:
- datax.py
- dxprof.py
- perftrace.py
2.1 datax.py
2.1.1 run dataX in the command window py
To execute py files, you need to install the python environment. Generally, the mac system comes with it without installation. If it is a windows system, you can use Baidu or Google by yourself. For mac system upgrade python3, please refer to my blog Installing Python 3 on Mac
datax.py is mainly used to submit tasks, which is equivalent to the entry of dataX. Let's use the command window to execute it, enter the compiled dataX directory, and then execute:
python datax.py ../job/job.json
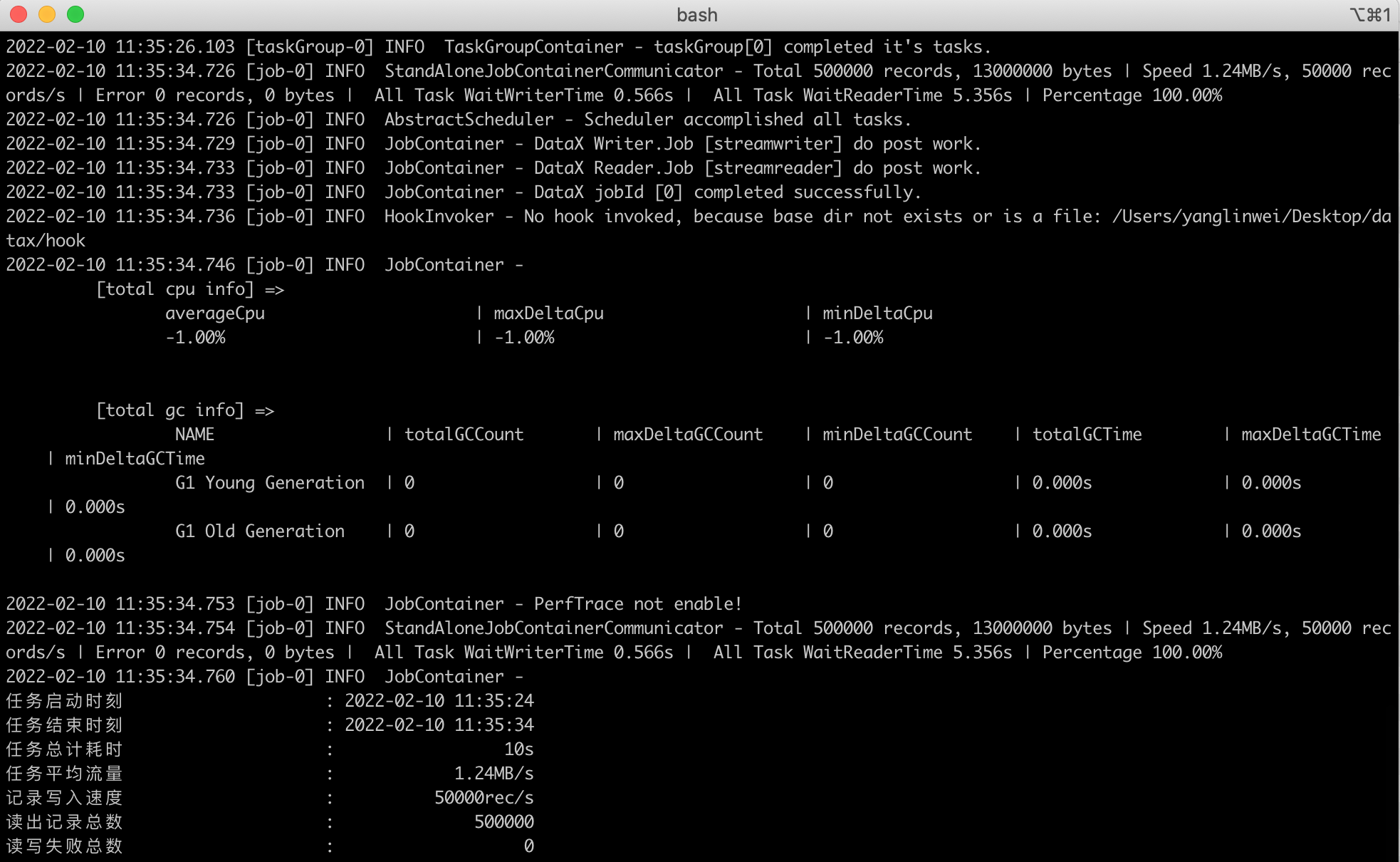
It can be seen that DataX is executed successfully, and the results are as follows (consistent with the effect of running DataX under IDEA, please refer to: DataX tutorial (02) - complete process of running dataX in IDEA (filling all pits)):
2.1.2 running dataX. Using PyCharm py
To interpret dataX Py is the best way to debug breakpoints. I use PyCharm here to debug breakpoints.
First import the compiled project, file - > Open, And open dataX py:
Click Run to see the error report:
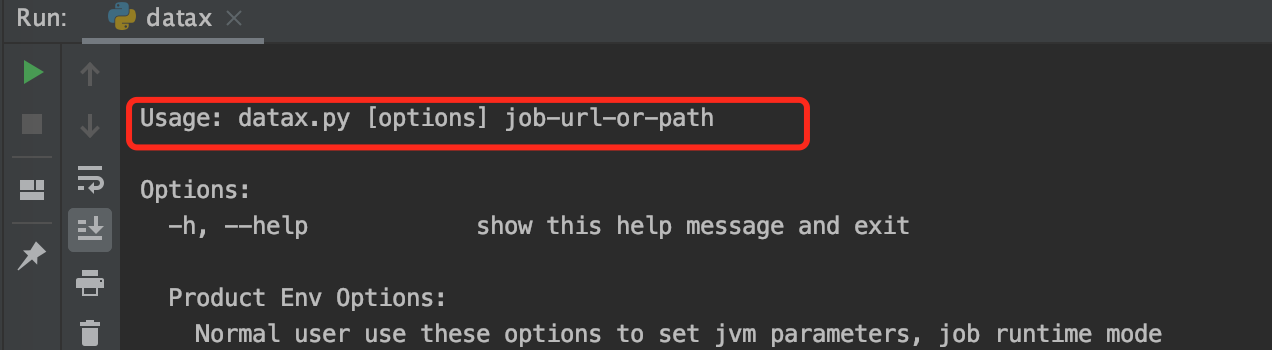
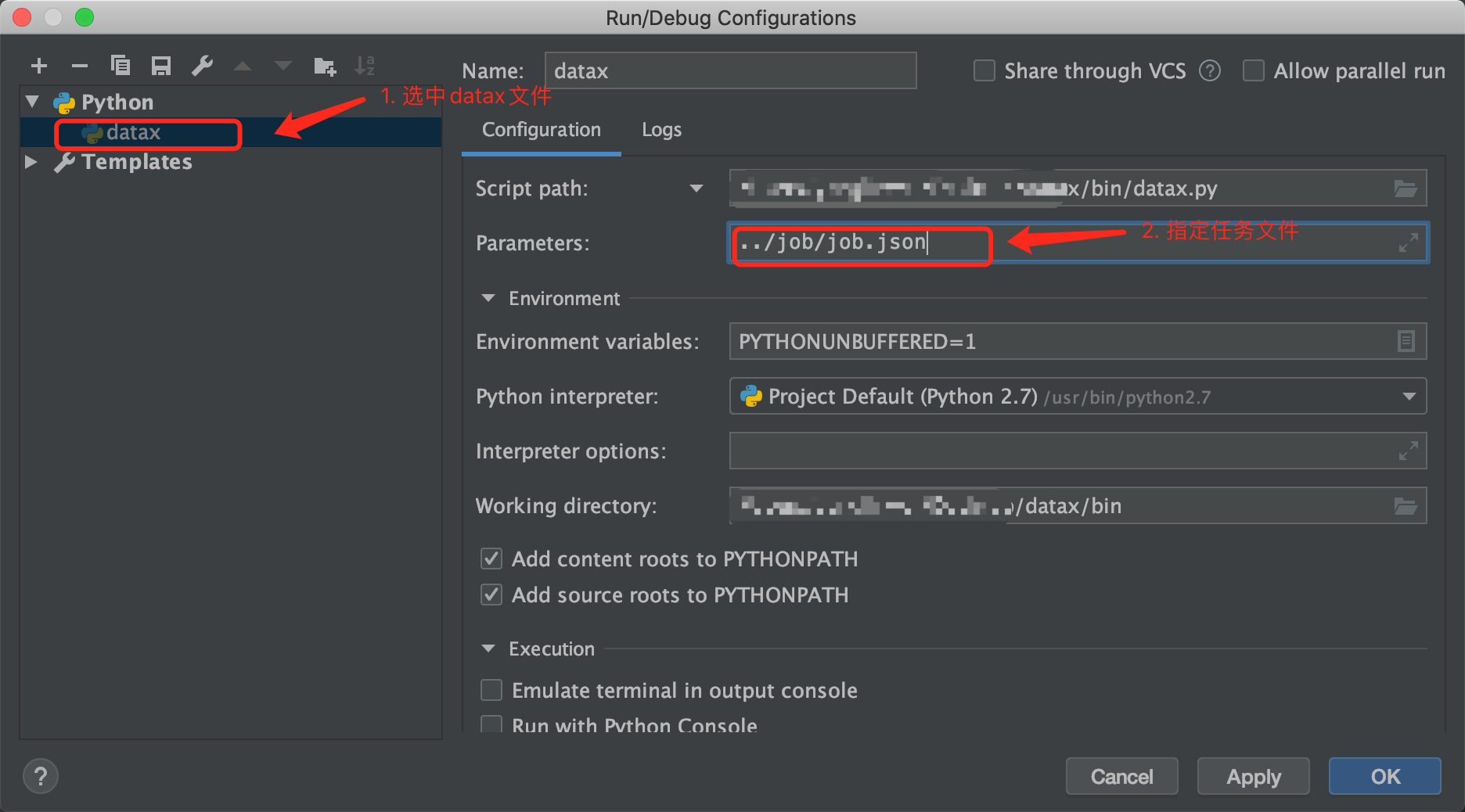
In fact, there is no configuration file with specified task. Click "Edit Configuration...":
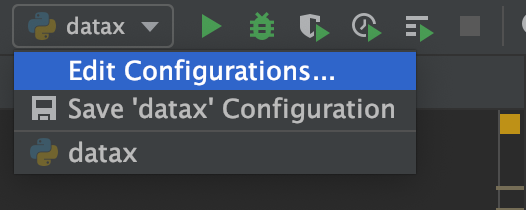
Path of configuration task file:
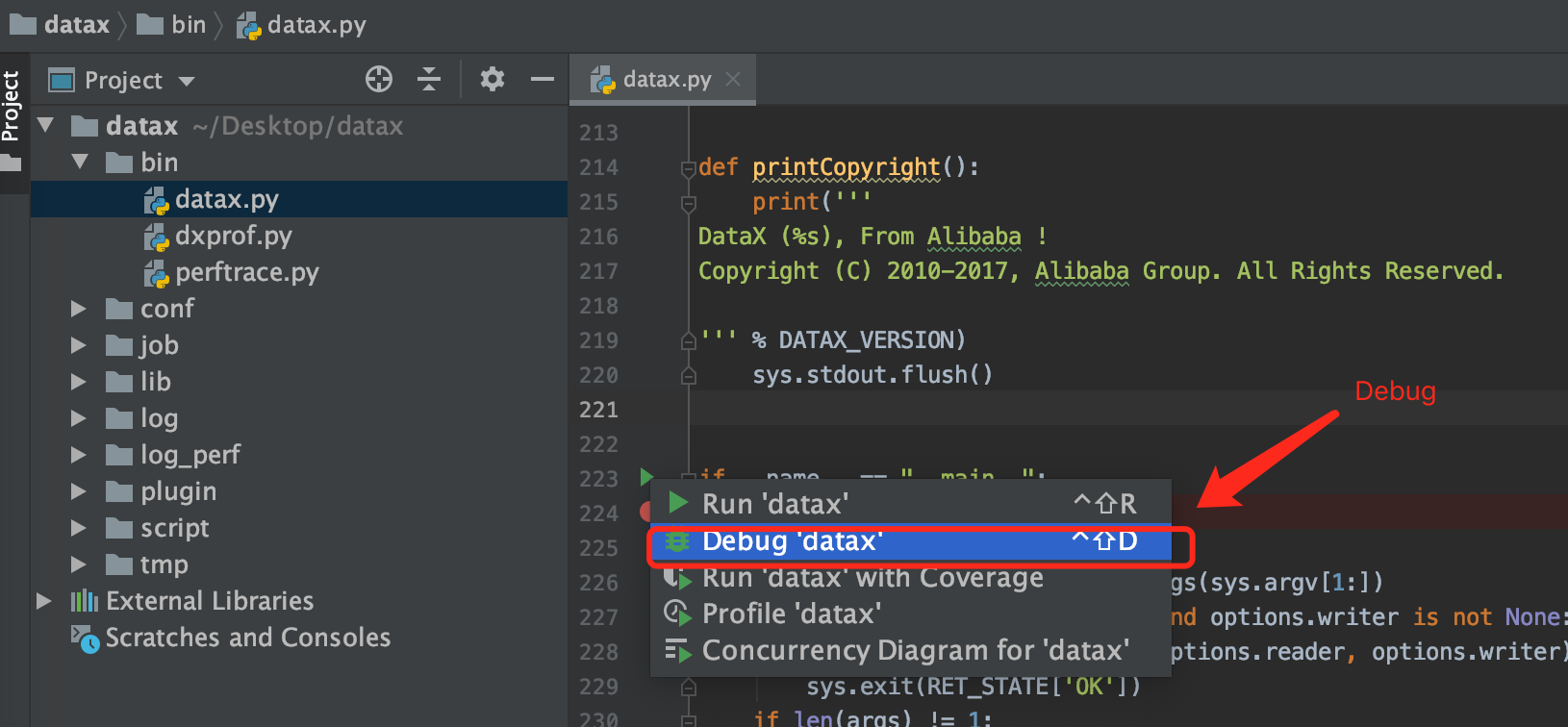
Right click the break point Debug:
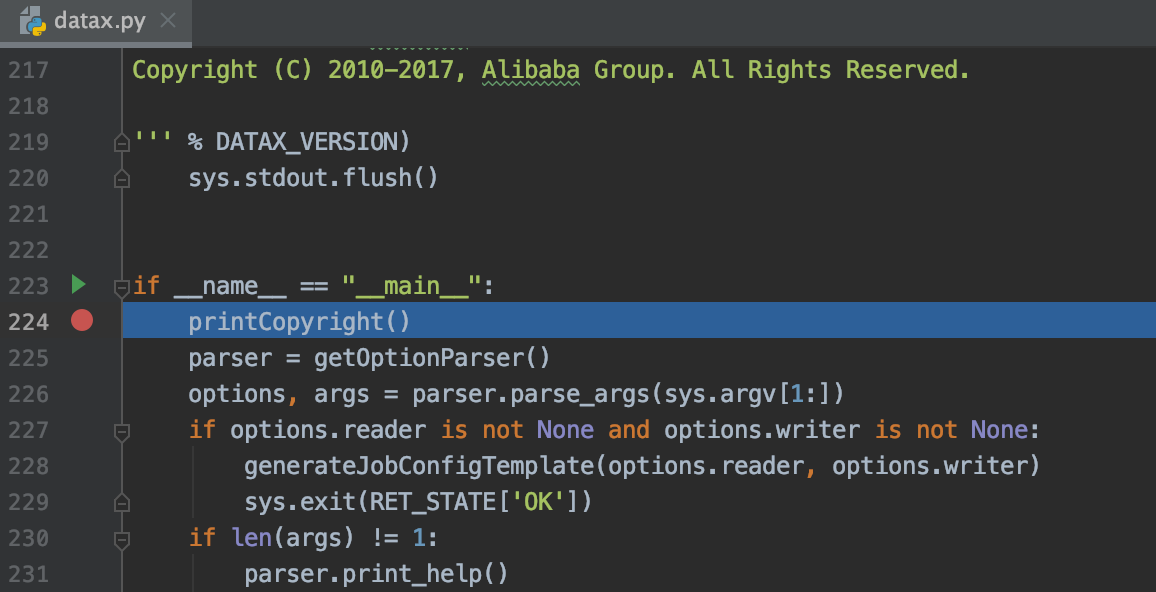
Next, you can happily follow the breakpoint to interpret dataX Py source code:
2.1.3 datax.py interpretation
datax. The main thing py does is to generate a command and use cmd to execute it.
The entry of the program is in "_main _" Method, let's look at the content of the entry code:
if __name__ == "__main__":
printCopyright()
parser = getOptionParser()
options, args = parser.parse_args(sys.argv[1:])
if options.reader is not None and options.writer is not None:
generateJobConfigTemplate(options.reader, options.writer)
sys.exit(RET_STATE['OK'])
if len(args) != 1:
parser.print_help()
sys.exit(RET_STATE['FAIL'])
startCommand = buildStartCommand(options, args)
# print startCommand
child_process = subprocess.Popen(startCommand, shell=True)
register_signal()
(stdout, stderr) = child_process.communicate()
sys.exit(child_process.returncode)
There are not many codes above. You can mainly see the code in line 12:
startCommand = buildStartCommand(options, args)
Before the 12th line of code, we encapsulated the startCommand command. Through breakpoint debugging, the encapsulated command is as follows:
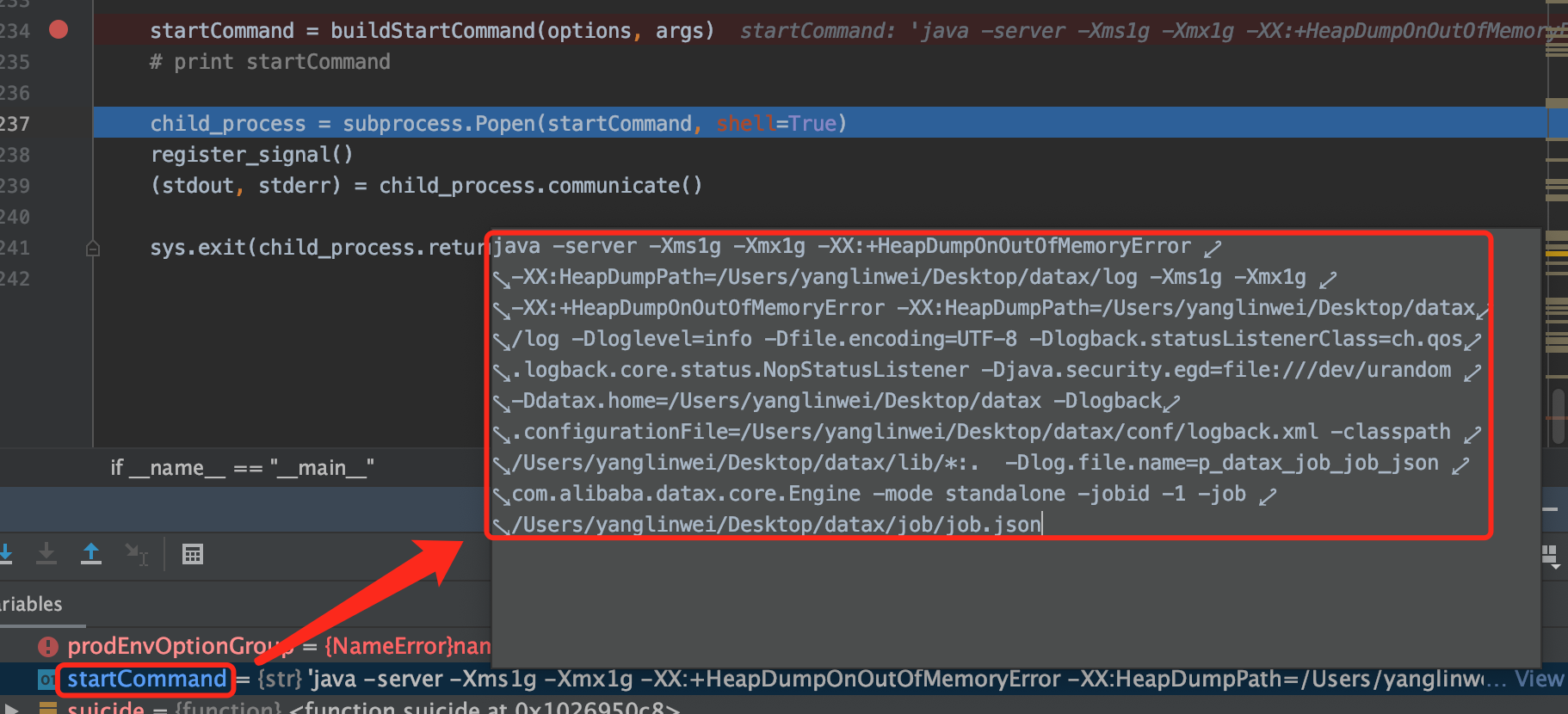
From the above figure, you can see that it is actually a java command. After line 12, the main task is to create a process to execute the startCommand command command:
# Create a process and execute the specified shell script child_process = subprocess.Popen(startCommand, shell=True) # Save the execution result in the semaphore register_signal() # The parent-child processes communicate and save the communication results to stdout and stderr (stdout, stderr) = child_process.communicate() # Exit (according to the status code of the child process) sys.exit(child_process.returncode)
Well, the main method has been interpreted here. What other methods are there? Cotrol+O look:
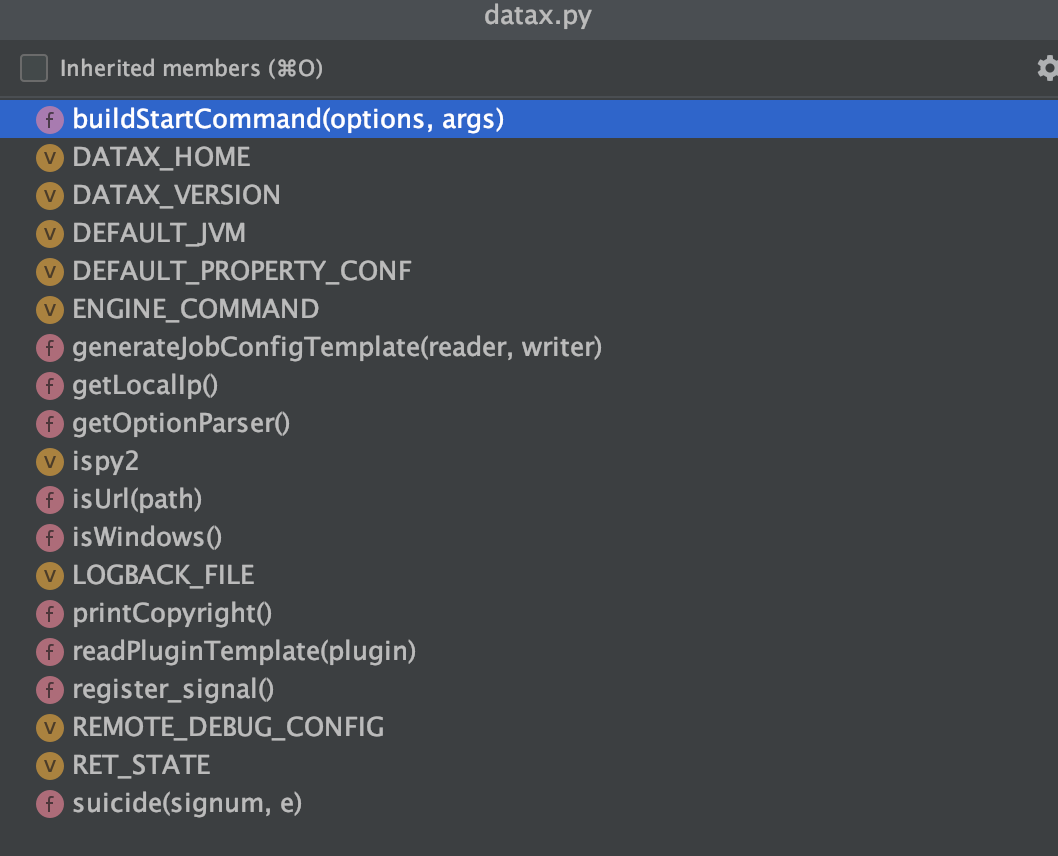
After finishing, it is as follows:
| classification | Logical name | analysis |
|---|---|---|
| variable | DATAX_HOME | The root path of the current running datax directory after compilation, such as: / Users / user name / Desktop/datax ' |
| DATAX_VERSION | Version number of DataX, such as DATAX-OPENSOURCE-3.0 | |
| DEFAULT_JVM | jvm configuration and dump path, such as' - Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users / username / Desktop/datax/log ' | |
| DEFAULT_PROPERTY_CONF | Configuration of some default properties, such as: - dfile encoding=UTF-8 -Dlogback. statusListenerClass=ch.qos. logback. core. status. NopStatusListener -Djava. security. egd= file:///dev/urandom -Ddatax. Home = / users / username / desktop / dataX - dlogback Configurationfile = / users / username / desktop / dataX / conf / logback xml | |
| ENGINE_COMMAND | The complete startup command format of the engine, such as Java - server ${JVM} - dfile encoding=UTF-8 -Dlogback. statusListenerClass=ch.qos. logback. core. status. NopStatusListener -Djava. security. egd= file:///dev/urandom -Ddatax. Home = / users / username / desktop / dataX - dlogback Configurationfile = / users / username / desktop / dataX / conf / logback XML - classpath / users / username / desktop / dataX / lib / *:$ {params} com. alibaba. datax. core. Engine -mode ${mode} -jobid ${jobid} -job ${job} | |
| ispy2 | Is it python2 x | |
| LOGBACK_FILE | logback.xml path, such as: / users / yanglinwei / desktop / dataX / conf / logback xml | |
| REMOTE_DEBUG_CONFIG | Remote debugging configuration, such as: - Xdebug -Xrunjdwp:transport=dt_socket,server=y,address=9999 | |
| RET_STATE | Return code definition, such as: {"KILL": 143,"FAIL": -1,"OK": 0,"RUN": 1,"RETRY": 2} | |
| method | buildStartCommand(options, args) | Build startup commands through various if else. The startup command contains 2 parts of JVM parameters + environment variables |
| generateJobConfigTemplate(reader, writer) | According to the names of writer and reader, pull the corresponding template from github, and finally create the template of json task | |
| getLocalIp() | Get local ip address | |
| getOptionParser() | Parser to get options | |
| isUrl(path) | Determine whether the input parameter is a url | |
| isWindows() | Is the current environment windows | |
| printCopyright() | Print copyright information | |
| readPluginTemplate(plugin) | Read the plug-in template according to the plug-in name | |
| register_signal() | Save the execution result in the semaphore | |
| suicide(signum, e) | According to the signal value, end this sub process |
2.2 dxprof.py
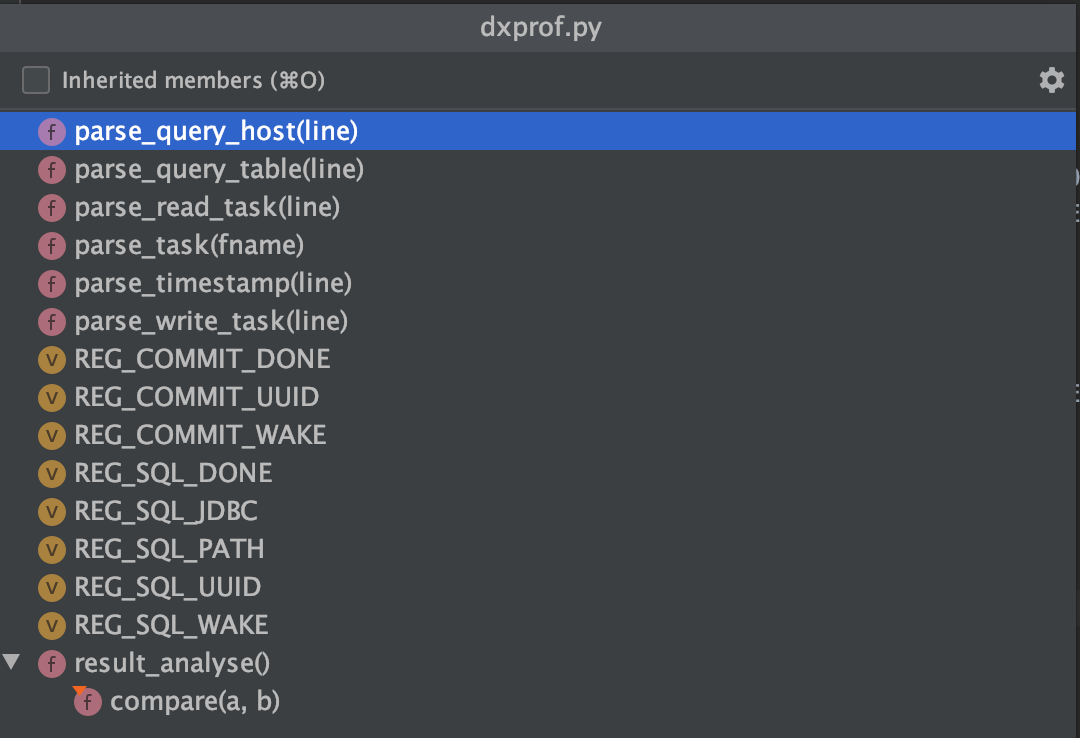
In the datax project, I can't find where this file is called. By reading the source code, I probably know that this class is a tool class used to query the host information, table information and task execution result information of the database.
control+o view dxprof The variables and methods in the PY file are not explained here. The meaning can be seen from the method name:
2.3 perftrace.py
2.3.1 perftrace. Usage of PY
Learn perftrace Py source code, you can know its main function is that users can pass in json strings to generate json for tasks, and then execute them.
In perftrace Py's getUsage() method describes perftrace Usage of Py:
perftrace.py --channel=10 --reader='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/database", "username":"", "password":"", "table": "", "where":"", "splitPk":"", "writer-print":"false"}'
perftrace.py --channel=10 --writer='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/database", "username":"", "password":"", "table": "", "reader-sliceRecordCount": "10000", "reader-column": [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]}'
perftrace.py --file=/tmp/datax.job.json --type=reader --reader='{"writer-print": "false"}'
perftrace.py --file=/tmp/datax.job.json --type=writer --writer='{"reader-sliceRecordCount": "10000", "reader-column": [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]}'
Note that the parameters inside are also required. For reader:
The following params are available for -r --reader:
[these params is for rdbms reader, used to trace rdbms read performance, it's like datax's key]
*datasourceType: datasource type, may be mysql|drds|oracle|ads|sqlserver|postgresql|db2 etc...
*jdbcUrl: datasource jdbc connection string, mysql as a example: jdbc:mysql://ip:port/database
*username: username for datasource
*password: password for datasource
*table: table name for read data
column: column to be read, the default value is ['*']
splitPk: the splitPk column of rdbms table
where: limit the scope of the performance data set
fetchSize: how many rows to be fetched at each communicate
[these params is for stream reader, used to trace rdbms write performance]
reader-sliceRecordCount: how man test data to mock(each channel), the default value is 10000
reader-column : stream reader while generate test data(type supports: string|long|date|double|bool|bytes; support constant value and random function),demo: [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]
For writer:
The following params are available for -w --writer:
[these params is for rdbms writer, used to trace rdbms write performance, it's like datax's key]
datasourceType: datasource type, may be mysql|drds|oracle|ads|sqlserver|postgresql|db2|ads etc...
*jdbcUrl: datasource jdbc connection string, mysql as a example: jdbc:mysql://ip:port/database
*username: username for datasource
*password: password for datasource
*table: table name for write data
column: column to be writed, the default value is ['*']
batchSize: how many rows to be storeed at each communicate, the default value is 512
preSql: prepare sql to be executed before write data, the default value is ''
postSql: post sql to be executed end of write data, the default value is ''
url: required for ads, pattern is ip:port
schme: required for ads, ads database name
[these params is for stream writer, used to trace rdbms read performance]
writer-print: true means print data read from source datasource, the default value is false
For global configuration:
The following params are available global control:
-c --channel: the number of concurrent tasks, the default value is 1
-f --file: existing completely dataX configuration file path
-t --type: test read or write performance for a datasource, couble be reader or writer, in collaboration with -f --file
-h --help: print help message
2.3.2 perftrace.py example
For example, you need to print the information of a table in the local database, as follows:

The following commands are directly used here:
perftrace.py --channel=1 --reader='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/bm_wxcp?useSSL=false", "username":"root", "password":"123456", "table": "t_sync_log", "where":"", "splitPk":"id", "writer-print":"true"}'
The printing results are as follows:
yanglineideMBP2:bin yanglinwei$ perftrace.py --channel=1 --reader='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/bm_wxcp?useSSL=false", "username":"root", "password":"123456", "table": "t_sync_log", "where":"", "splitPk":"id", "writer-print":"true"}'
DataX Util Tools (UNKNOWN_DATAX_VERSION), From Alibaba !
Copyright (C) 2010-2016, Alibaba Group. All Rights Reserved.
trace environments:
dataxJobPath: /Users/yanglinwei/Desktop/datax/bin/perftrace-c336d159-8a57-11ec-b78e-f45c89ba8565
dataxHomePath: /Users/yanglinwei/Desktop/datax
dataxCommand: /Users/yanglinwei/Desktop/datax/bin/datax.py /Users/yanglinwei/Desktop/datax/bin/perftrace-c336d159-8a57-11ec-b78e-f45c89ba8565
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2022-02-10 17:56:49.547 [main] INFO VMInfo - VMInfo# operatingSystem class => com.sun.management.internal.OperatingSystemImpl
2022-02-10 17:56:49.560 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 11 11.0.2+9-LTS
jvmInfo: Mac OS X x86_64 10.15.1
cpu num: 4
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [G1 Young Generation, G1 Old Generation]
MEMORY_NAME | allocation_size | init_size
CodeHeap 'profiled nmethods' | 117.22MB | 2.44MB
G1 Old Gen | 1,024.00MB | 970.00MB
G1 Survivor Space | -0.00MB | 0.00MB
CodeHeap 'non-profiled nmethods' | 117.22MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
Metaspace | -0.00MB | 0.00MB
G1 Eden Space | -0.00MB | 54.00MB
CodeHeap 'non-nmethods' | 5.56MB | 2.44MB
2022-02-10 17:56:49.614 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"*"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://127.0.0.1:3306/bm_wxcp?useSSL=false"
],
"table":[
"t_sync_log"
]
}
],
"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/bm_wxcp?useSSL=false",
"password":"******",
"sliceRecordCount":"10000",
"splitPk":"id",
"table":"t_sync_log",
"username":"root",
"where":""
}
},
"writer":{
"name":"streamwriter",
"parameter":{
"print":"true"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
2022-02-10 17:56:49.665 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2022-02-10 17:56:49.668 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2022-02-10 17:56:49.668 [main] INFO JobContainer - DataX jobContainer starts job.
2022-02-10 17:56:49.671 [main] INFO JobContainer - Set jobId = 0
2022-02-10 17:56:50.356 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://127.0.0.1:3306/bm_wxcp?useSSL=false&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.
2022-02-10 17:56:50.358 [job-0] WARN OriginalConfPretreatmentUtil - The column configuration in your profile is at risk. Because you are not configured to read the columns of the database table, when the number and type of fields in your table change, the correctness of the task may be affected or even an error may occur. Please check your configuration and make changes.
2022-02-10 17:56:50.369 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2022-02-10 17:56:50.369 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .
2022-02-10 17:56:50.371 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2022-02-10 17:56:50.372 [job-0] INFO JobContainer - jobContainer starts to do split ...
2022-02-10 17:56:50.372 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2022-02-10 17:56:50.377 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [1] tasks.
2022-02-10 17:56:50.378 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks.
2022-02-10 17:56:50.423 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2022-02-10 17:56:50.429 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2022-02-10 17:56:50.432 [job-0] INFO JobContainer - Running by standalone Mode.
2022-02-10 17:56:50.440 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2022-02-10 17:56:50.465 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to 2000000.
2022-02-10 17:56:50.467 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2022-02-10 17:56:50.498 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2022-02-10 17:56:50.505 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select * from t_sync_log
] jdbcUrl:[jdbc:mysql://127.0.0.1:3306/bm_wxcp?useSSL=false&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2022-02-10 17:56:50.572 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select * from t_sync_log
] jdbcUrl:[jdbc:mysql://127.0.0.1:3306/bm_wxcp?useSSL=false&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
5941 cc01b87e-abd9-4c9d-9da7-2103987db5ae 8888 0 1 SYNC_ORG 2021-10-28 09:57:45 2021-10-28 09:57:46 true 1 0 false Yang Linwei Yang Linwei 2021-10-28 01:57:44 2021-10-28 01:57:46
5942 cc01b87e-abd9-4c9d-9da7-2103987db5ae 8888 1026081 1 SYNC_DEPT 2021-10-28 09:57:46 null false 1 0 false Yang Linwei Yang Linwei 2021-10-28 01:57:46 2021-10-28 01:57:46
2022-02-10 17:56:50.803 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[309]ms
2022-02-10 17:56:50.803 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2022-02-10 17:57:00.482 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 191 bytes | Speed 19B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.076s | Percentage 100.00%
2022-02-10 17:57:00.482 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2022-02-10 17:57:00.483 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2022-02-10 17:57:00.483 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.
2022-02-10 17:57:00.484 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2022-02-10 17:57:00.492 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
G1 Young Generation | 1 | 1 | 1 | 0.009s | 0.009s | 0.009s
G1 Old Generation | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2022-02-10 17:57:00.492 [job-0] INFO JobContainer - PerfTrace not enable!
2022-02-10 17:57:00.493 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 191 bytes | Speed 19B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.076s | Percentage 100.00%
2022-02-10 17:57:00.495 [job-0] INFO JobContainer -
Start task at any time : 2022-02-10 17:56:49
Task end time : 2022-02-10 17:57:00
Total task time : 10s
Task average flow : 19B/s
Record write speed : 0rec/s
Total number of read records : 2
Total number of read and write failures : 0
03 config directory file parsing
The config directory mainly contains the following two files:
- core.json
- logback.xml
For students doing Javak development, logback XML is already very common. It mainly controls the level of printing and the format of printing log. It will not be described here.
This is mainly about core json.
3.1 core.json
core. The contents in the JSON file are as follows:
{
"entry": {
"jvm": "-Xms1G -Xmx1G",
"environment": {}
},
"common": {
"column": {
"datetimeFormat": "yyyy-MM-dd HH:mm:ss",
"timeFormat": "HH:mm:ss",
"dateFormat": "yyyy-MM-dd",
"extraFormats":["yyyyMMdd"],
"timeZone": "GMT+8",
"encoding": "utf-8"
}
},
"core": {
"dataXServer": {
"address": "http://localhost:7001/api",
"timeout": 10000,
"reportDataxLog": false,
"reportPerfLog": false
},
"transport": {
"channel": {
"class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",
"speed": {
"byte": 2000000,
"record": -1
},
"flowControlInterval": 20,
"capacity": 512,
"byteCapacity": 67108864
},
"exchanger": {
"class": "com.alibaba.datax.core.plugin.BufferedRecordExchanger",
"bufferSize": 32
}
},
"container": {
"job": {
"reportInterval": 10000
},
"taskGroup": {
"channel": 5
},
"trace": {
"enable": "false"
}
},
"statistics": {
"collector": {
"plugin": {
"taskClass": "com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector",
"maxDirtyNumber": 10
}
}
}
}
}
The main contents of these classes are* Variable:
Due to space and time, the meaning of each configuration will be supplemented later.
04 job directory file parsing
The job directory has only one job JSON file is also an example file. The specific contents are as follows:
{
"job": {
"setting": {
"speed": {
"byte":10485760
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19890604,
"type": "long"
},
{
"value": "1989-06-04 00:00:00",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 100000
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false,
"encoding": "UTF-8"
}
}
}
]
}
}
In fact, in the source code, each reader or writer plug-in already has a doc document. What is written here is certainly not as good as the official website. You can clone the source code and have a look:
05 end
This article is sorted out after reading the source code. Children's shoes with questions are welcome to leave a message. The end of this article!