Index optimization and query optimization
1, Data preparation
Insert 500000 entries in the student table and 10000 entries in the class table.
Step 1: create a table
#Class table CREATE TABLE `class` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `className` VARCHAR(30) DEFAULT NULL, `address` VARCHAR(40) DEFAULT NULL, `monitor` INT NULL , PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; #Student form CREATE TABLE `student` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `stuno` INT NOT NULL , `name` VARCHAR(20) DEFAULT NULL, `age` INT(3) DEFAULT NULL, `classId` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) #CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Step 2: set parameters
Command on: allows creation of function settings:
set global log_bin_trust_function_creators=1; # Without global, only the current window is valid.
Step 3: create a function
Ensure that each data is different.
#Randomly generated string DELIMITER // CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) BEGIN DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i + 1; END WHILE; RETURN return_str; END // DELIMITER ; #If you want to delete #drop function rand_string;
Randomly generate class number
#Used to randomly generate number to number DELIMITER // CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11) BEGIN DECLARE i INT DEFAULT 0; SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ; RETURN i; END // DELIMITER ; #If you want to delete #drop function rand_num;
Step 4: create a stored procedure
#Create a stored procedure that inserts data into the stu table DELIMITER // CREATE PROCEDURE insert_stu( START INT , max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; #Set up manual commit transactions REPEAT #loop SET i = i + 1; #assignment INSERT INTO student (stuno, name ,age ,classId ) VALUES ((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000)); UNTIL i = max_num END REPEAT; COMMIT; #Commit transaction END // DELIMITER ; #If you want to delete #drop PROCEDURE insert_stu;
Create a stored procedure that inserts data into the class table
#Execute the stored procedure and add random data to the class table DELIMITER // CREATE PROCEDURE `insert_class`( max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO class ( classname,address,monitor ) VALUES (rand_string(8),rand_string(10),rand_num(1,100000)); UNTIL i = max_num END REPEAT; COMMIT; END // DELIMITER ; #If you want to delete #drop PROCEDURE insert_class;
Step 5: call the stored procedure
class
#Execute the stored procedure and add 10000 pieces of data to the class table CALL insert_class(10000);
stu
#Execute the stored procedure and add 500000 pieces of data to the stu table CALL insert_stu(100000,500000);
Step 6: delete the index on a table
Create stored procedure
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY' ;
#Each cursor must use a different declare continue handler for not found set done=1 to control the end of the cursor
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#If no data is returned, the program continues and sets the variable done to 2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
Execute stored procedure
CALL proc_drop_index("dbname","tablename");
2, Index failure cases
1. Full value match my favorite
Equivalent matching of full values
2. Optimal left prefix rule
Extension: Alibaba Java development manual
The index file has the leftmost prefix matching feature of B-Tree. If the value on the left is not determined, this index cannot be used.
3. Primary key insertion order
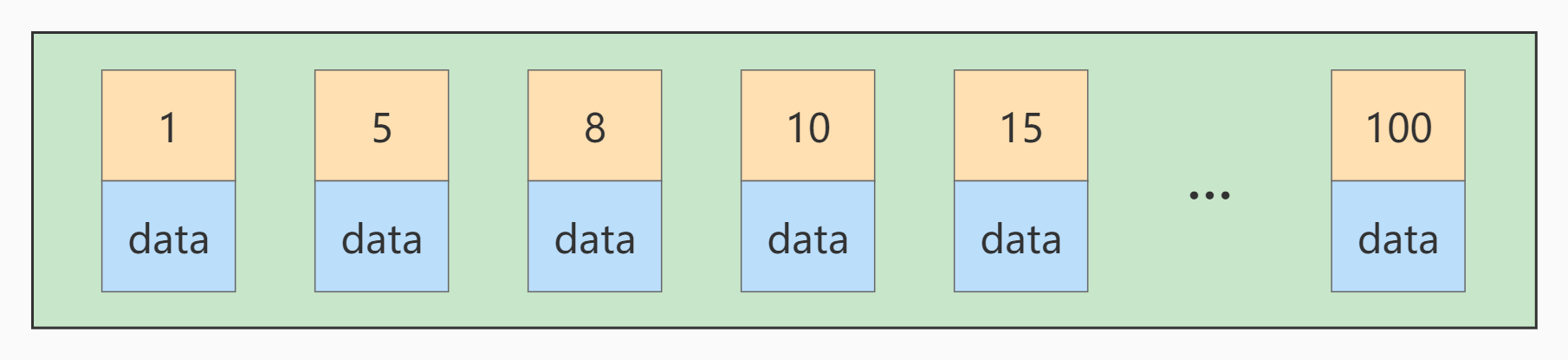
If another record with a primary key value of 9 is inserted at this time, its insertion position is as follows:
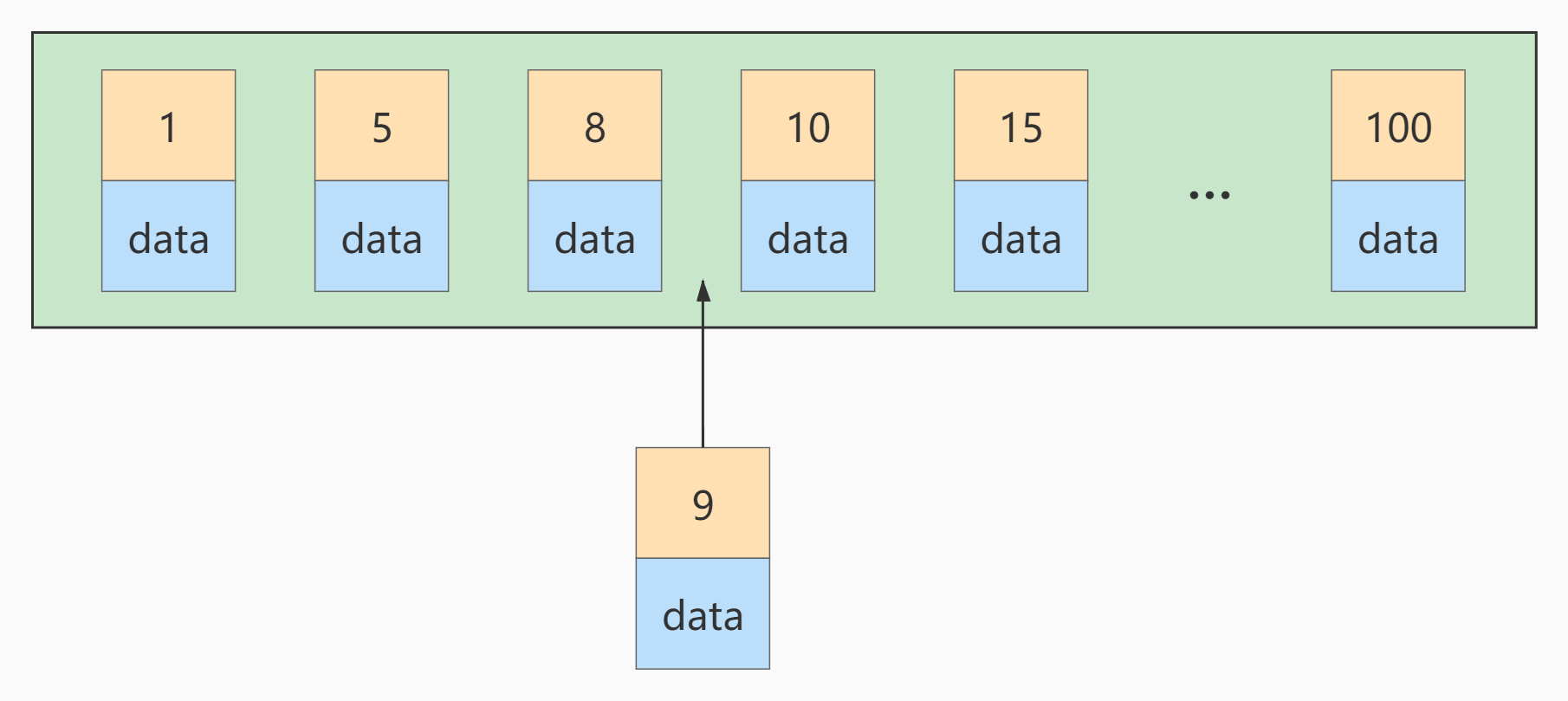
But this data page is full. What if you insert it again? We need to split the current page into two pages and move some records in this page to the newly created page. What does page splitting and record shifting mean? Means: performance loss! Therefore, if we want to avoid such unnecessary performance loss as far as possible, we'd better increase the primary key value of the inserted records in turn, so that such performance loss will not occur.
Therefore, we suggest that the primary key should have AUTO_INCREMENT, let the storage engine generate the primary key for the table itself, instead of inserting it manually, such as person_info table:
CREATE TABLE person_info( id INT UNSIGNED NOT NULL AUTO_INCREMENT, name VARCHAR(100) NOT NULL, birthday DATE NOT NULL, phone_number CHAR(11) NOT NULL, country varchar(100) NOT NULL, PRIMARY KEY (id), KEY idx_name_birthday_phone_number (name(10), birthday, phone_number) );
Our customized primary key column id has auto_ For the increment attribute, the storage engine will automatically fill in the self incremented primary key value for us when inserting records. Such a primary key takes up less space, writes sequentially, and reduces page splitting.
4. Index invalidation due to calculation, function, type conversion (automatic or manual)
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%'; EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
Create index
CREATE INDEX idx_name ON student(NAME);
First: index optimization takes effect
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
mysql> SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
+---------+---------+--------+------+---------+
| id | stuno | name | age | classId |
+---------+---------+--------+------+---------+
| 5301379 | 1233401 | AbCHEa | 164 | 259 |
| 7170042 | 3102064 | ABcHeB | 199 | 161 |
| 1901614 | 1833636 | ABcHeC | 226 | 275 |
| 5195021 | 1127043 | abchEC | 486 | 72 |
| 4047089 | 3810031 | AbCHFd | 268 | 210 |
| 4917074 | 849096 | ABcHfD | 264 | 442 |
| 1540859 | 141979 | abchFF | 119 | 140 |
| 5121801 | 1053823 | AbCHFg | 412 | 327 |
| 2441254 | 2373276 | abchFJ | 170 | 362 |
| 7039146 | 2971168 | ABcHgI | 502 | 465 |
| 1636826 | 1580286 | ABcHgK | 71 | 262 |
| 374344 | 474345 | abchHL | 367 | 212 |
| 1596534 | 169191 | AbCHHl | 102 | 146 |
...
| 5266837 | 1198859 | abclXe | 292 | 298 |
| 8126968 | 4058990 | aBClxE | 316 | 150 |
| 4298305 | 399962 | AbCLXF | 72 | 423 |
| 5813628 | 1745650 | aBClxF | 356 | 323 |
| 6980448 | 2912470 | AbCLXF | 107 | 78 |
| 7881979 | 3814001 | AbCLXF | 89 | 497 |
| 4955576 | 887598 | ABcLxg | 121 | 385 |
| 3653460 | 3585482 | AbCLXJ | 130 | 174 |
| 1231990 | 1283439 | AbCLYH | 189 | 429 |
| 6110615 | 2042637 | ABcLyh | 157 | 40 |
+---------+---------+--------+------+---------+
401 rows in set, 1 warning (0.01 sec)
Second: index optimization failure
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';

mysql> SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
+---------+---------+--------+------+---------+
| id | stuno | name | age | classId |
+---------+---------+--------+------+---------+
| 5301379 | 1233401 | AbCHEa | 164 | 259 |
| 7170042 | 3102064 | ABcHeB | 199 | 161 |
| 1901614 | 1833636 | ABcHeC | 226 | 275 |
| 5195021 | 1127043 | abchEC | 486 | 72 |
| 4047089 | 3810031 | AbCHFd | 268 | 210 |
| 4917074 | 849096 | ABcHfD | 264 | 442 |
| 1540859 | 141979 | abchFF | 119 | 140 |
| 5121801 | 1053823 | AbCHFg | 412 | 327 |
| 2441254 | 2373276 | abchFJ | 170 | 362 |
| 7039146 | 2971168 | ABcHgI | 502 | 465 |
| 1636826 | 1580286 | ABcHgK | 71 | 262 |
| 374344 | 474345 | abchHL | 367 | 212 |
| 1596534 | 169191 | AbCHHl | 102 | 146 |
...
| 5266837 | 1198859 | abclXe | 292 | 298 |
| 8126968 | 4058990 | aBClxE | 316 | 150 |
| 4298305 | 399962 | AbCLXF | 72 | 423 |
| 5813628 | 1745650 | aBClxF | 356 | 323 |
| 6980448 | 2912470 | AbCLXF | 107 | 78 |
| 7881979 | 3814001 | AbCLXF | 89 | 497 |
| 4955576 | 887598 | ABcLxg | 121 | 385 |
| 3653460 | 3585482 | AbCLXJ | 130 | 174 |
| 1231990 | 1283439 | AbCLYH | 189 | 429 |
| 6110615 | 2042637 | ABcLyh | 157 | 40 |
+---------+---------+--------+------+---------+
401 rows in set, 1 warning (3.62 sec)
The type is "ALL", which means that the index is not used. The query time is 3.62 seconds, and the query efficiency is much lower than before.
Another example:
- An index is set on the stuno field of the student table
CREATE INDEX idx_sno ON student(stuno); EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;

- Index optimization takes effect:
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;
Another example:
- An index is set on the field name of the student table
CREATE INDEX idx_name ON student(NAME); EXPLAIN SELECT id, stuno, name FROM student WHERE SUBSTRING(name, 1,3)='abc';

EXPLAIN SELECT id, stuno, NAME FROM student WHERE NAME LIKE 'abc%';

5. Index invalidation due to type conversion
Which of the following sql statements can use indexes. (assuming an index is set on the name field)
# Index not used EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;

# Use to index EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';

Type conversion occurred for name=123, and the index became invalid. (implicit type conversion)
6. The column index to the right of the range condition fails
ALTER TABLE student DROP INDEX idx_name; ALTER TABLE student DROP INDEX idx_age; ALTER TABLE student DROP INDEX idx_age_classid; EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ; # student. Student on the right of CLassID > 20 The index with name = 'ABC' will become invalid

create index idx_age_name_classid on student(age,name,classid);
- Place the range query criteria at the end of the statement:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abc' AND student.classId>20 ; #It is useless to directly exchange the location of sql statements. You need to change the location of the joint index

7. Not equal to (! = or < >) index failure
When there is in the sql statement= Or < > the index will become invalid. Try to rewrite it to equal or overwrite the index
8. is null can use the index, is not null cannot use the index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL; EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
9. like index invalidation starting with wildcard%

Extension: Alibaba Java development manual
[mandatory] page search is strictly prohibited from left blur or full blur. If necessary, please go to the search engine to solve it.
10. There are non indexed columns before and after OR, and the index is invalid
Make the conditions before and after OR have indexes. If one is missing, the index will become invalid
# Index not used EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

#Use to index EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR name = 'Abel';

11. The character sets of database and table are used utf8mb4
Unified use utf8mb4 (supported by version 5.5.3 and above) has better compatibility, and unified character set can avoid garbled code caused by character set conversion. Conversion is required before comparing different character sets, which will cause index invalidation.
3, Association query optimization
1. Data preparation
2. Left outer connection
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

Conclusion: type has All
Add index optimization
ALTER TABLE book ADD INDEX Y ( card); #[driven table] can avoid full table scanning EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

You can see that the type of the second line changes to ref, and the rows also become optimized, which is obvious. This is determined by the left connection feature.
The left outer join condition is used to determine how to search rows from the right table. There must be rows on the left, so the right is our key point, and we must establish an index.
ALTER TABLE `type` ADD INDEX X (card); #[drive table] cannot avoid full table scanning EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

then
DROP INDEX Y ON book; EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

3. Internal connection
drop index X on type; drop index Y on book;(If it has been deleted, you don't need to perform this operation)
Change to inner join (MySQL auto select driver table)
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;

Add index optimization
ALTER TABLE book ADD INDEX Y ( card); EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;

ALTER TABLE type ADD INDEX X (card); EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
next:
DROP INDEX X ON `type`; EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;

next:
ALTER TABLE `type` ADD INDEX X (card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;

4. Principle of join statement
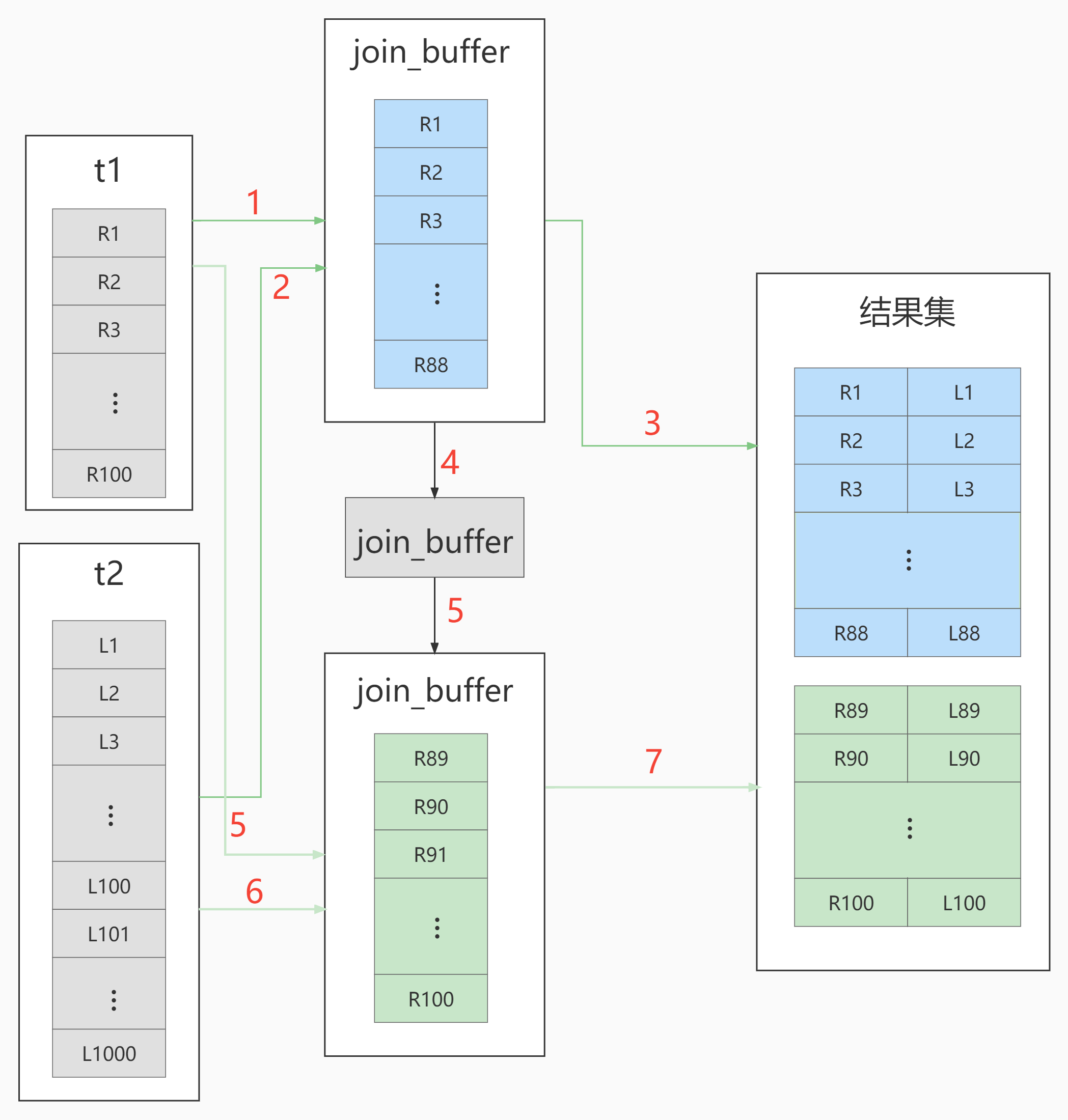
- Index Nested-Loop Join
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);
If you directly use the join statement, the MySQL optimizer may select table t1 or t2 as the driving table, which will affect the execution process of analyzing SQL statements.
Therefore, in order to analyze the performance problems during execution, I use straight instead_ Join allows MySQL to execute queries using a fixed join method, so that the optimizer will only join in the way we specify. In this statement, t1 is the driven table and t2 is the driven table.

It can be seen that in this statement, there is an index on field a of driven table t2, which is used in the join process. Therefore, the execution process of this statement is as follows:
- Read a row of data R from table t1;
- From the data row R, take out the a field and look it up in table t2;
- Take out the qualified row in table t2 and form a row with R as part of the result set;
- Repeat steps 1 through 3 until the end of the loop at the end of table t1.
This process first traverses table t1, and then finds the records that meet the conditions in table t2 according to the a value in each row of data taken from table t1. Formally, this process is similar to the nested query when we write the program, and the index of the driven table can be used. Therefore, we call it "index nested loop join", or NLJ for short.
Its corresponding flow chart is as follows:
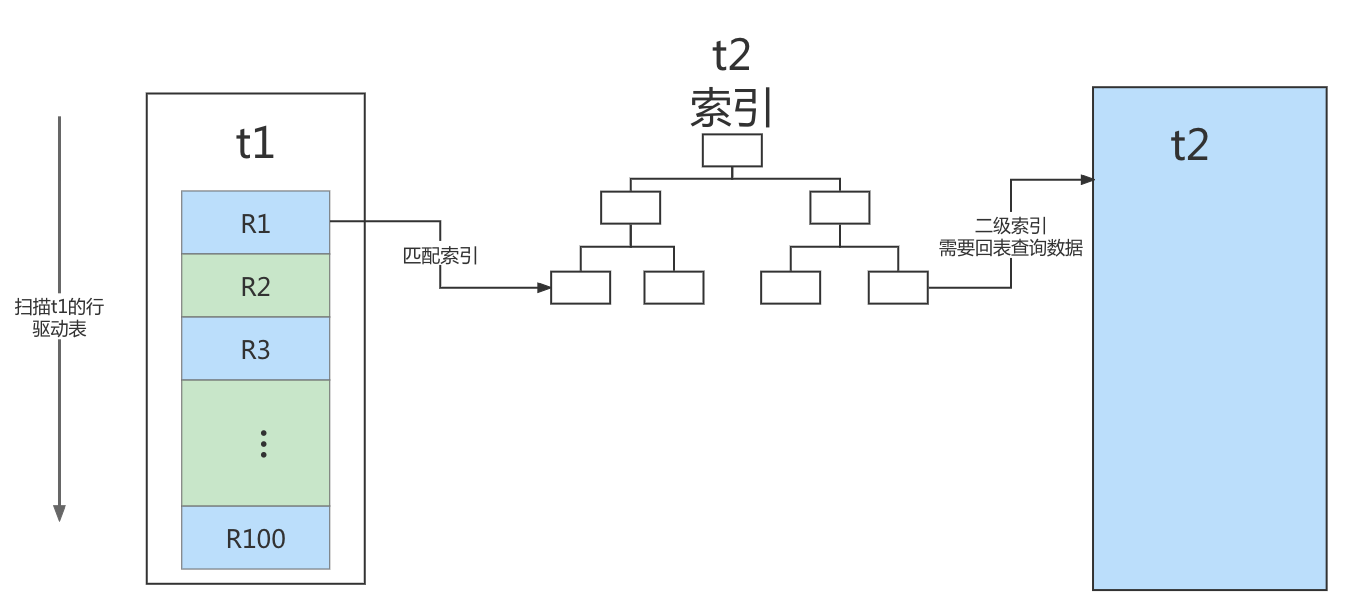
In this process:
- A full table scan is performed on the drive table t1, and 100 rows need to be scanned in this process;
- For each row R, table t2 is searched according to the a field, and the tree search process is followed. Because the data we constructed are one-to-one corresponding, only one line is scanned in each search process, and a total of 100 lines are scanned;
- Therefore, the total number of scanning lines in the whole execution process is 200.
Extended question 1: can I use join?
Extended question 2: how to select the driving table?
For example:
If N is expanded 1000 times, the number of scanning lines will be expanded 1000 times; M expands 1000 times and the number of scanning lines is less than 10 times.
Two conclusions:
- Using the join statement, the performance is better than forcibly splitting into multiple single tables to execute SQL statements;
- If you use the join statement, you need to use the small table as the driving table.
- Simple Nested-Loop Join
- Block Nested-Loop Join
The flow chart of this process is as follows:
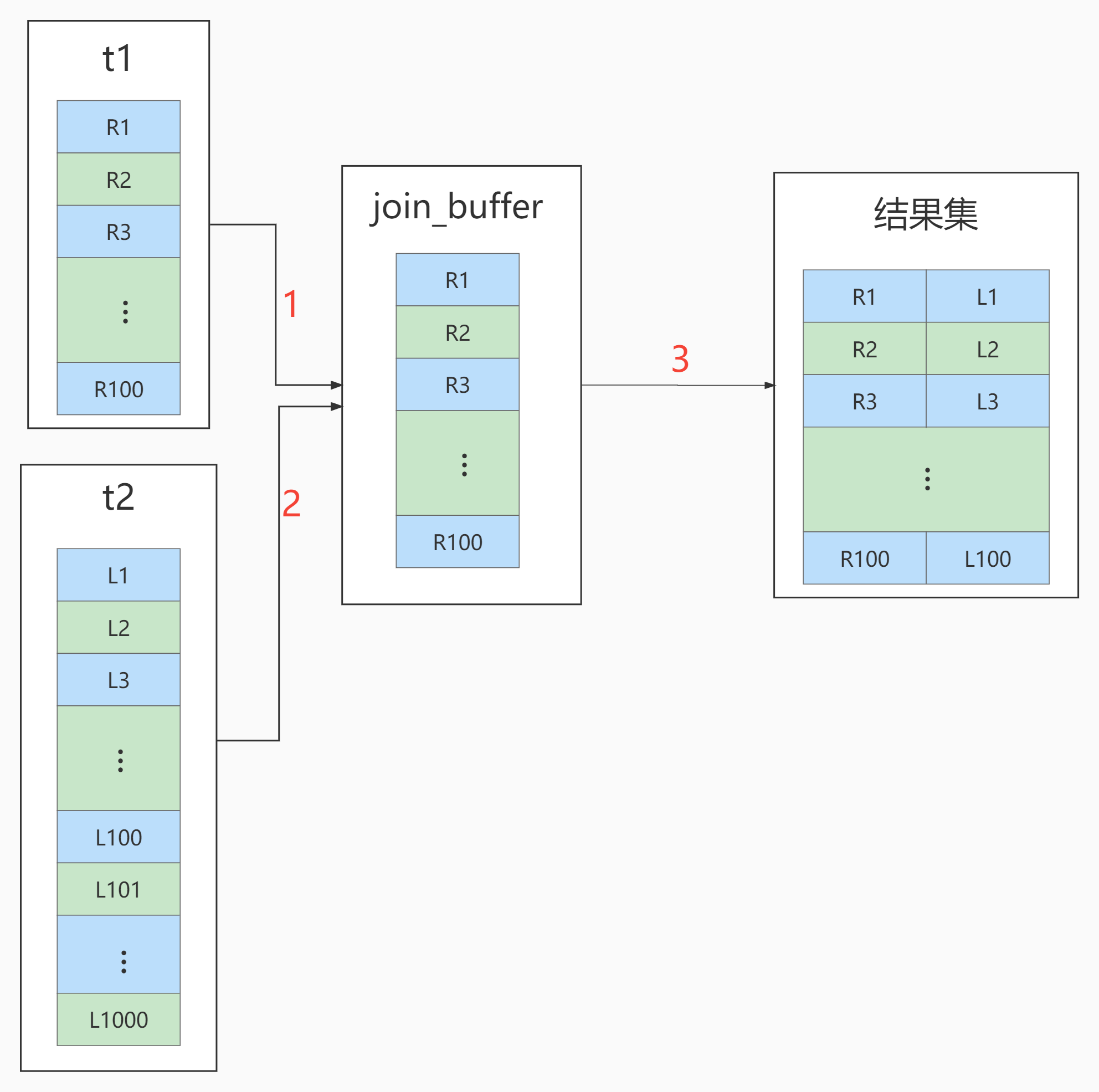
The execution flow chart becomes like this:
Summary 1: can I use xxx join statement?
Summary 2: if you want to use join, should you choose large table as the driving table or small table as the driving table?
Summary 3: what is called "small table"?
When deciding which table to use as the driving table, the two tables should be filtered according to their respective conditions. After filtering, the total data volume of each field participating in the join is calculated. The table with small data volume is the "small table" and should be used as the driving table.
5. Summary
- Ensure that the JOIN field of the driven table has been indexed
- The data types of the fields that need to be joined are absolutely consistent.
- When LEFT JOIN, select the small table as the driven table and the large table as the driven table. Reduce the number of outer cycles.
- When an INNER JOIN is performed, MySQL will automatically select the table of the small result set as the driving table. Select MySQL optimization strategy.
- Those that can be directly associated with multiple tables should be directly associated as far as possible without sub query. (reduce the number of queries)
- It is not recommended to use sub query. It is recommended to split the sub query SQL and combine the program for multiple queries, or use JOIN instead of sub query.
- Derived tables cannot be indexed
4, Subquery optimization
See if you can optimize sub queries into internal and external join queries
MySQL supports subqueries from version 4.1. You can use subqueries to perform nested queries of SELECT statements, that is, the results of one SELECT query are used as the conditions of another SELECT statement. Subqueries can complete many SQL operations that logically require multiple steps at one time.
Subquery is an important function of MySQL, which can help us realize more complex queries through an SQL statement. However, the execution efficiency of sub query is not high.
reason:
① When executing a subquery, MySQL needs to create a temporary table for the query results of the inner query statement, and then the outer query statement queries the records from the temporary table. After the query is completed, undo these temporary tables. This will consume too much CPU and IO resources and generate a large number of slow queries.
② The temporary tables stored in the result set of sub query, whether memory temporary tables or disk temporary tables, will not have indexes, so the query performance will be affected to some extent.
③ For subqueries with large return result sets, the greater the impact on query performance.
In MySQL, you can use JOIN queries instead of subqueries.
Join queries do not need to establish temporary tables, which is faster than sub queries. If indexes are used in queries, the performance will be better.
Conclusion:
Try not to use NOT IN or NOT EXISTS, and use LEFT JOIN xxx ON xx WHERE xx IS NULL instead
5, Sorting optimization
1. Sorting optimization
Question:
Add an index to the WHERE condition field, but why do you need to add an index to the ORDER BY field?
Optimization suggestions:
- In SQL, indexes can be used in WHERE clause and ORDER BY clause to avoid full table scanning in WHERE clause and FileSort sorting in ORDER BY clause. Of course, in some cases, full table scanning or FileSort sorting is not necessarily slower than indexing. But in general, we still need to avoid it in order to improve query efficiency.
- Try to use Index to complete ORDER BY sorting. If WHERE and ORDER BY are followed by the same column, a single Index column is used; If different, use a federated Index.
- When Index cannot be used, the FileSort mode needs to be tuned.
INDEX a_b_c(a,b,c) order by The leftmost prefix of the index can be used - ORDER BY a - ORDER BY a,b - ORDER BY a,b,c - ORDER BY a DESC,b DESC,c DESC If WHERE Defined as a constant using the leftmost prefix of the index, then order by Can use index - WHERE a = const ORDER BY b,c - WHERE a = const AND b = const ORDER BY c - WHERE a = const ORDER BY b,c - WHERE a = const AND b > const ORDER BY b,c You cannot sort using an index - ORDER BY a ASC,b DESC,c DESC /* Inconsistent sorting */ - WHERE g = const ORDER BY b,c /*Missing a index*/ - WHERE a = const ORDER BY c /*Missing b index*/ - WHERE a = const ORDER BY a,d /*d Is not part of the index*/ - WHERE a in (...) ORDER BY b,c /*For sorting, multiple equality conditions are also range queries*/
2. Case practice
In the ORDER BY clause, try to sort by Index rather than by FileSort.
Clear the index on the student before executing the case, leaving only the primary key:
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid_stuno ON student;
DROP INDEX idx_age_classid_name ON student;
#perhaps
call proc_drop_index('atguigudb2','student');
Scenario: query students aged 30 with student number less than 101000 and sort by user name
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;

The query results are as follows:
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME; +---------+--------+--------+------+---------+ | id | stuno | name | age | classId | +---------+--------+--------+------+---------+ | 922 | 100923 | elTLXD | 30 | 249 | | 3723263 | 100412 | hKcjLb | 30 | 59 | | 3724152 | 100827 | iHLJmh | 30 | 387 | | 3724030 | 100776 | LgxWoD | 30 | 253 | | 30 | 100031 | LZMOIa | 30 | 97 | | 3722887 | 100237 | QzbJdx | 30 | 440 | | 609 | 100610 | vbRimN | 30 | 481 | | 139 | 100140 | ZqFbuR | 30 | 351 | +---------+--------+--------+------+---------+ 8 rows in set, 1 warning (3.16 sec)
Conclusion:
type is ALL, which is the worst case. Using filesort also appears in Extra, which is also the worst case. Optimization is necessary.
Optimization ideas:
Scheme 1: in order to get rid of filesort, we can build the index
#create new index CREATE INDEX idx_age_name ON student(age,NAME);
Scheme 2: try to make the filter conditions and sorting of where use the upper index
Create a combined index of three fields:
DROP INDEX idx_age_name ON student; CREATE INDEX idx_age_stuno_name ON student (age,stuno,NAME); EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
mysql> SELECT SQL_NO_CACHE * FROM student -> WHERE age = 30 AND stuno <101000 ORDER BY NAME ; +-----+--------+--------+------+---------+ | id | stuno | name | age | classId | +-----+--------+--------+------+---------+ | 167 | 100168 | AClxEF | 30 | 319 | | 323 | 100324 | bwbTpQ | 30 | 654 | | 651 | 100652 | DRwIac | 30 | 997 | | 517 | 100518 | HNSYqJ | 30 | 256 | | 344 | 100345 | JuepiX | 30 | 329 | | 905 | 100906 | JuWALd | 30 | 892 | | 574 | 100575 | kbyqjX | 30 | 260 | | 703 | 100704 | KJbprS | 30 | 594 | | 723 | 100724 | OTdJkY | 30 | 236 | | 656 | 100657 | Pfgqmj | 30 | 600 | | 982 | 100983 | qywLqw | 30 | 837 | | 468 | 100469 | sLEKQW | 30 | 346 | | 988 | 100989 | UBYqJl | 30 | 457 | | 173 | 100174 | UltkTN | 30 | 830 | | 332 | 100333 | YjWiZw | 30 | 824 | +-----+--------+--------+------+---------+ 15 rows in set, 1 warning (0.00 sec)
As a result, the sql running speed of filesort is much faster than that of the sql optimized with filesort, and the results appear almost instantly.
Conclusion:
- If the two indexes exist at the same time, mysql automatically selects the best scheme. (for this example, mysql selects
idx_age_stuno_name). However, as the amount of data changes, the selected index will also change. - When one of the two fields of [range condition] and [group by or order by] appears, the filter quantity of the condition field shall be observed first. If there are enough filtered data but not enough data to be sorted, the index shall be placed on the range field first. And vice versa.
Think: is it feasible for us to use the following index here?
DROP INDEX idx_age_stuno_name ON student; CREATE INDEX idx_age_stuno ON student(age,stuno);
4. filesort algorithm: two-way sorting and one-way sorting
Two way sorting (slow)
- MySQL 4.1 used to use two-way sorting, which literally means to scan the disk twice to finally get the data, read the row pointer and order by column, sort them, then scan the sorted list, and re read the corresponding data output from the list according to the values in the list
- Get the sort field from the disk, sort in the buffer, and then get other fields from the disk.
Take a batch of data and scan the disk twice. As we all know, IO is very time-consuming, so in MySQL4 After 1, a second improved algorithm appeared, which is one-way sorting.
Single channel sorting (fast)
Read all the columns required for the query from the disk, sort them in the buffer according to the order by column, and then scan the sorted list for output. It is more efficient and avoids reading data for the second time. And it turns random IO into sequential IO, but it uses more null
Because it saves every row in memory.
Conclusion and extended problems
- Since single channel is backward, it is better than double channel in general
- But there is a problem with one-way
Optimization strategy:
- Try to improve sort_buffer_size
- Try to improve max_length_for_sort_data
- select * is a taboo when Order by. It is best to Query only the required fields.
6, GROUP BY optimization
- The principle of group by using index is almost the same as that of order by. Group by can directly use index even if it does not have filter conditions.
- group by sorts first and then groups, following the best left prefix rule for index creation
- When the index column cannot be used, increase max_length_for_sort_data and sort_ buffer_ Setting of size parameter
- Where is more efficient than having. If you can write in where, don't write in having
- Reduce the use of order by, communicate with the business, do not sort without sorting, or put the sorting on the program side. The statements order by, group by and distinct consume CPU, and the CPU resources of the database are extremely valuable.
- For the query statements including order by, group by and distinct, please keep the result set filtered by the where condition within 1000 rows, otherwise the SQL will be very slow.
7, Optimize paging queries
Optimization idea 1:
The sorting and paging operation is completed on the index. Finally, other column contents required by the original table query are associated according to the primary key.
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a WHERE t.id = a.id;

Optimization idea 2:
This scheme is applicable to tables with self incremented primary keys. You can convert the Limit query into a query at a certain location.
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;

8, Override index is preferred
1. What is an overlay index?
The query results are found directly through the data corresponding to the secondary index without returning to the table
-
Understanding method 1: index is an efficient way to find rows, but general databases can also use index to find the data of a column, so it does not have to read the whole row. After all, index leaf nodes store the data they index; When the desired data can be obtained by reading the index, there is no need to read rows. An index that contains data that meets the query results is called an overlay index.
-
Understanding method 2: a form of non clustered composite index, which includes all columns used in the SELECT, JOIN and WHERE clauses of the query (that is, the fields to be indexed are exactly the fields involved in the covering query conditions).
In short, the index column + primary key contains the columns queried FROM SELECT to FROM.
2. Advantages and disadvantages of overwriting indexes
Benefits:
- Avoid secondary query (back to table) of Innodb table index
- Random IO can be changed into sequential IO to speed up query efficiency
Disadvantages:
The maintenance of index fields always comes at a price. Therefore, a trade-off needs to be considered when establishing redundant indexes to support overlay indexes. This is the job of a business DBA, or business data architect.
9, How to add an index to a string
There is a teacher table, which is defined as follows:
create table teacher( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb;
Lecturers need to log in by email, so statements like this must appear in the business code:
mysql> select col1, col2 from teacher where email='xxx';
If there is no index on the email field, the statement can only do a full table scan.
1. Prefix index
MySQL supports prefix indexing. By default, if the statement you create the index does not specify the prefix length, the index will contain the entire string.
mysql> alter table teacher add index index1(email); #or mysql> alter table teacher add index index2(email(6));
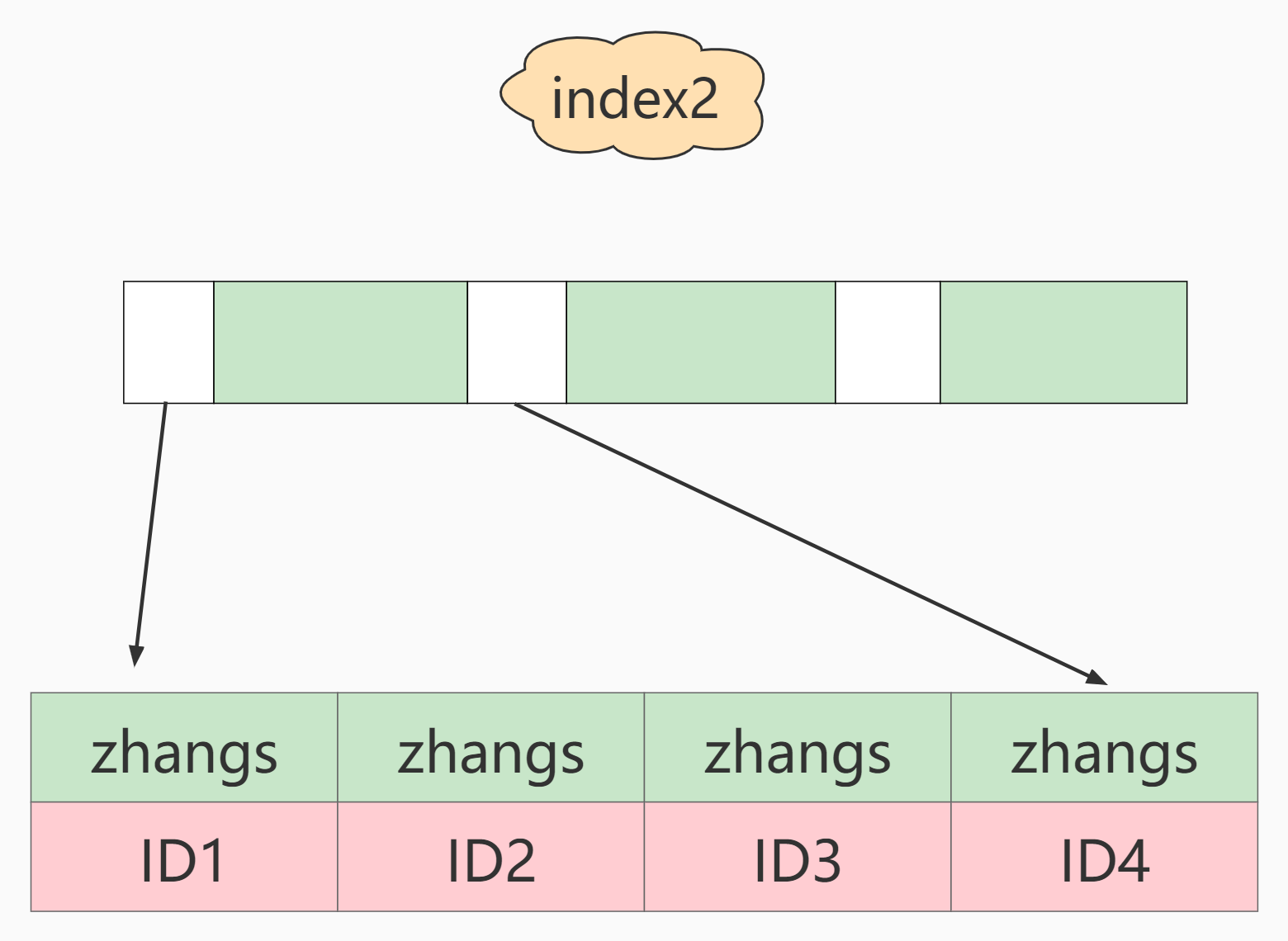
What are the differences between these two different definitions in data structure and storage? The following figure is a schematic diagram of these two indexes.
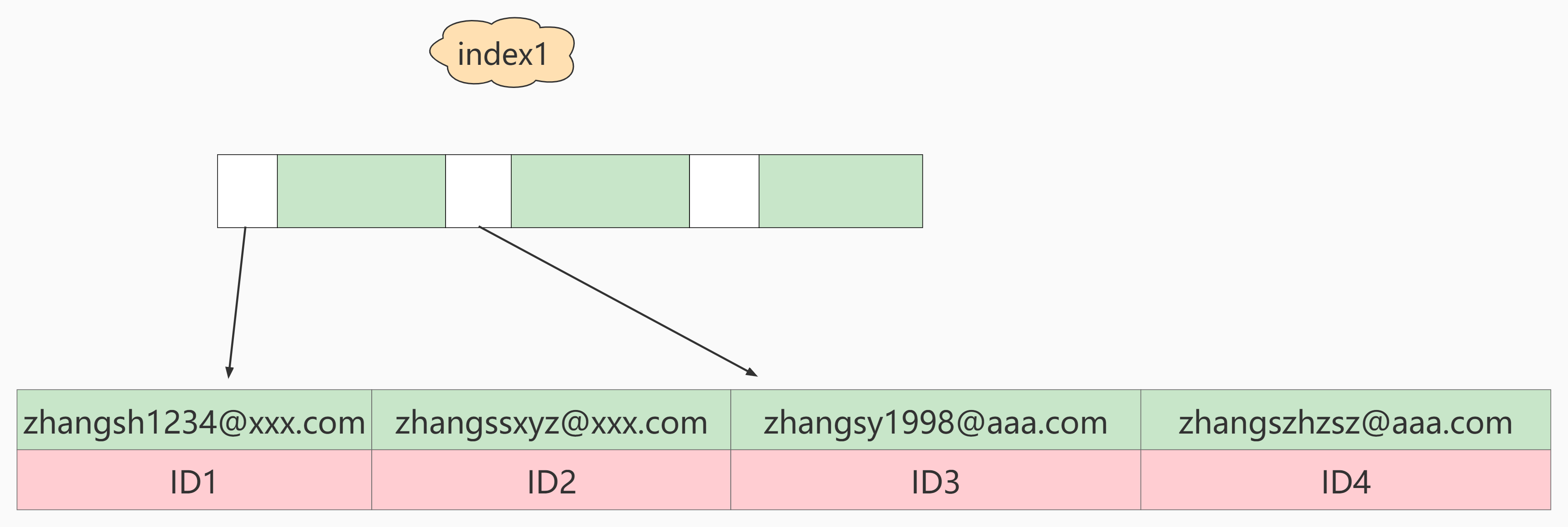
as well as
If index1 (the index structure of the whole email string) is used, the execution order is as follows:
- From the index1 index tree, find that the index value is zhangssxyz@xxx.com ’Obtain the value of ID2 for this record;
- Find the row whose primary key value is ID2 on the primary key, judge that the email value is correct, and add this row of records to the result set;
- Take the next record of the position just found in the index1 index tree and find that it does not meet the email='zhangssxyz@xxx.com ’The condition is, and the loop ends.
In this process, you only need to retrieve data from the primary key index once, so the system thinks that only one row has been scanned.
If index2 (i.e. email(6) index structure) is used, the execution order is as follows:
- Find the record satisfying the index value of 'zhangs' from the index2 index tree, and the first one found is ID1;
- Find the row whose primary key value is ID1 on the primary key, and judge that the value of email is not ' zhangssxyz@xxx.com ’, this line of record is discarded;
- Take the next record at the position just found on index2 and find that it is still 'zhangs'. Take ID2 and then take the whole line on the ID index. Then judge that the value is correct this time and add this line of record to the result set;
- Repeat the previous step until the value obtained on idxe2 is not 'zhangs', and the loop ends.
In other words, by using prefix index and defining the length, we can save space without adding too much query cost. As mentioned earlier, the higher the degree of discrimination, the better. Because the higher the discrimination, the fewer duplicate key values.
2. Influence of prefix index on overlay index
Conclusion:
If you use prefix index, you will not need to overwrite index to optimize query performance, which is also a factor you need to consider when choosing whether to use prefix index.
10, Index push down
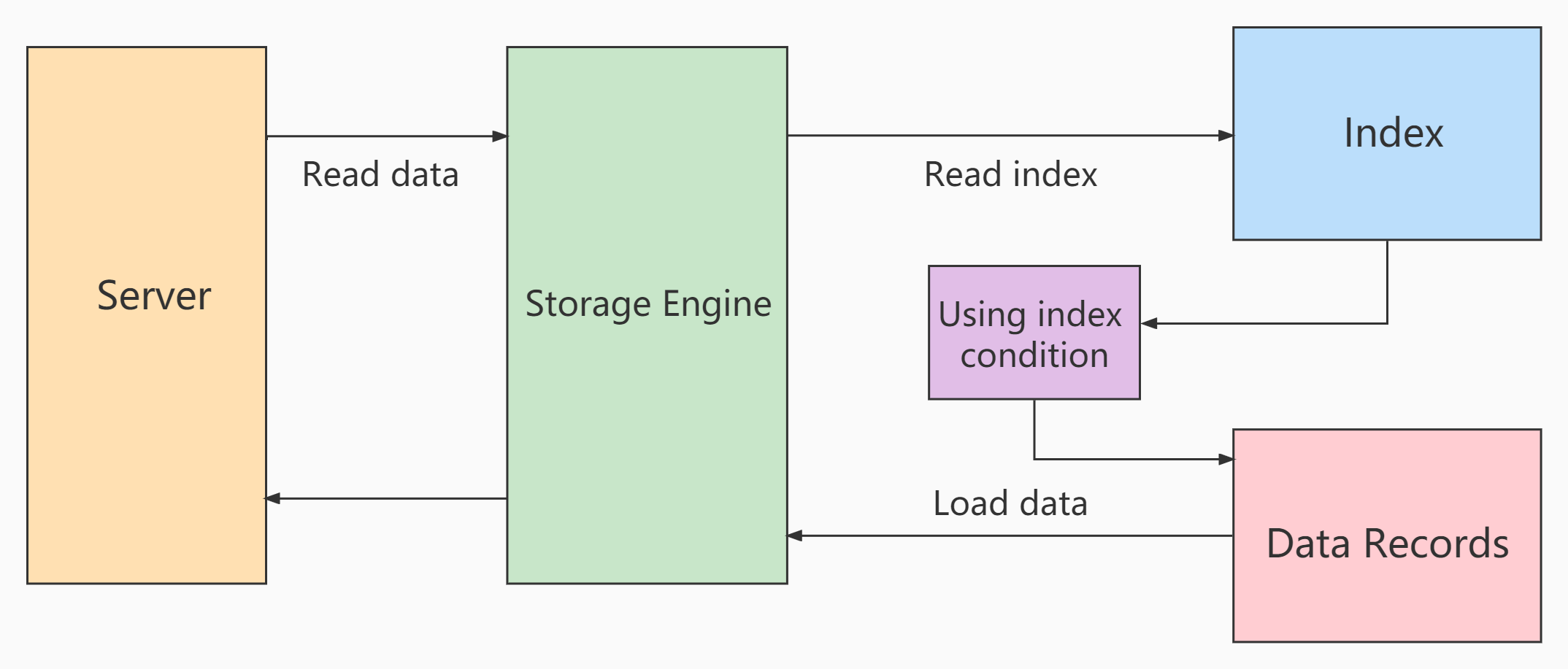
Index Condition Pushdown(ICP) is a new feature in MySQL 5.6. It is an optimized way to use index to filter data in the storage engine layer.
ICP can reduce the number of times the storage engine accesses the base table and MySQL server accesses the storage engine.
1. Scanning process before and after use
In the process of scanning without ICP index:
storage layer: only the whole row of records corresponding to the index records that meet the index key conditions are taken out and returned to the server layer
server layer: filter the returned data using the following where condition until the last row is returned.
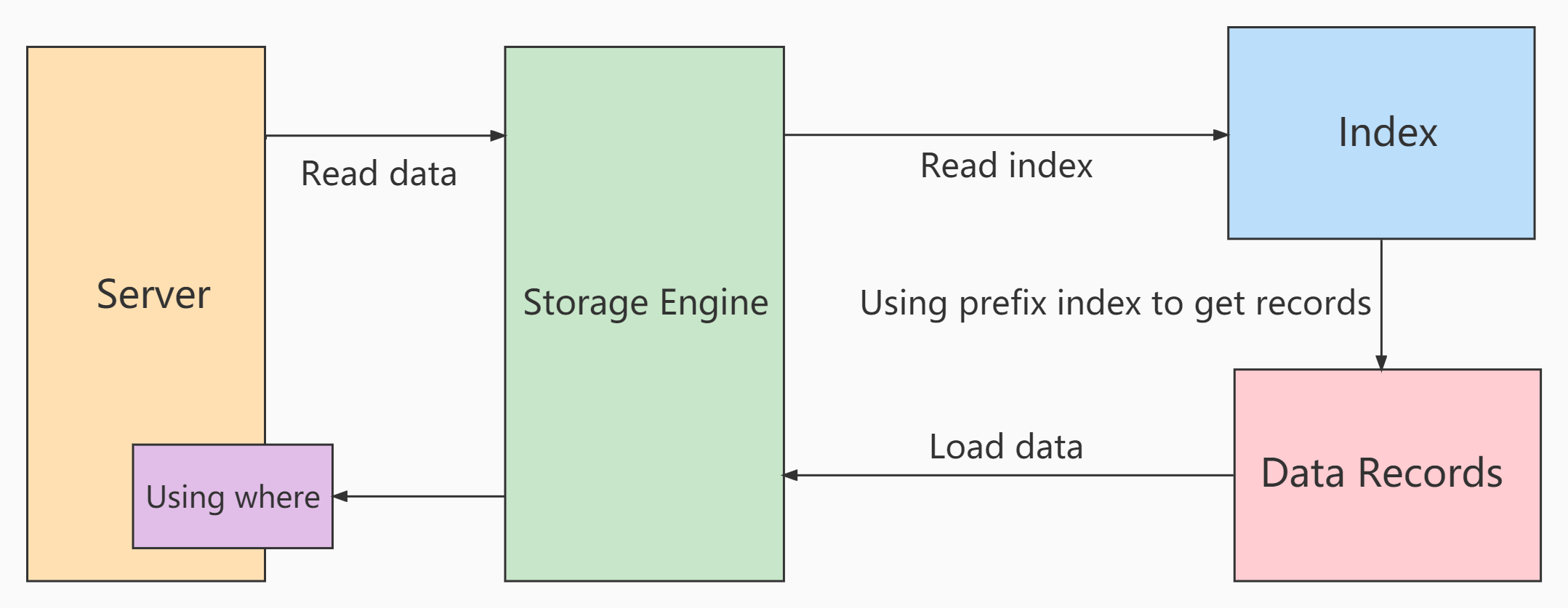
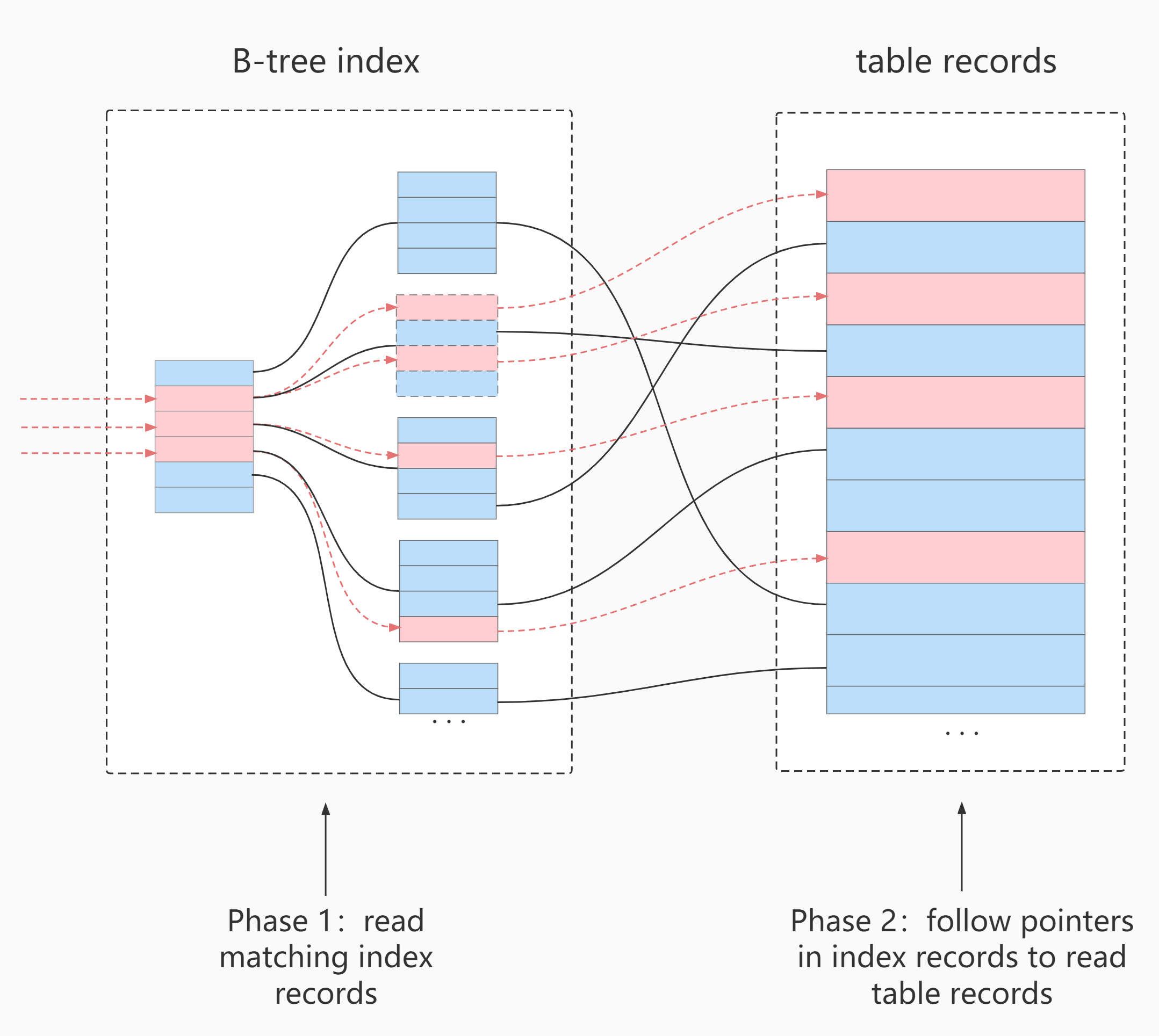
Process using ICP scanning:
- storage layer:
First, determine the index record interval that meets the index key condition, and then use index filter to filter the index. Only the index records meeting the indexfilter conditions are returned to the table, and the whole row of records are taken out and returned to the server layer. Index records that do not meet the index filter conditions are discarded, and will not return to the table or the server layer. - server layer:
For the returned data, use the table filter condition for final filtering.
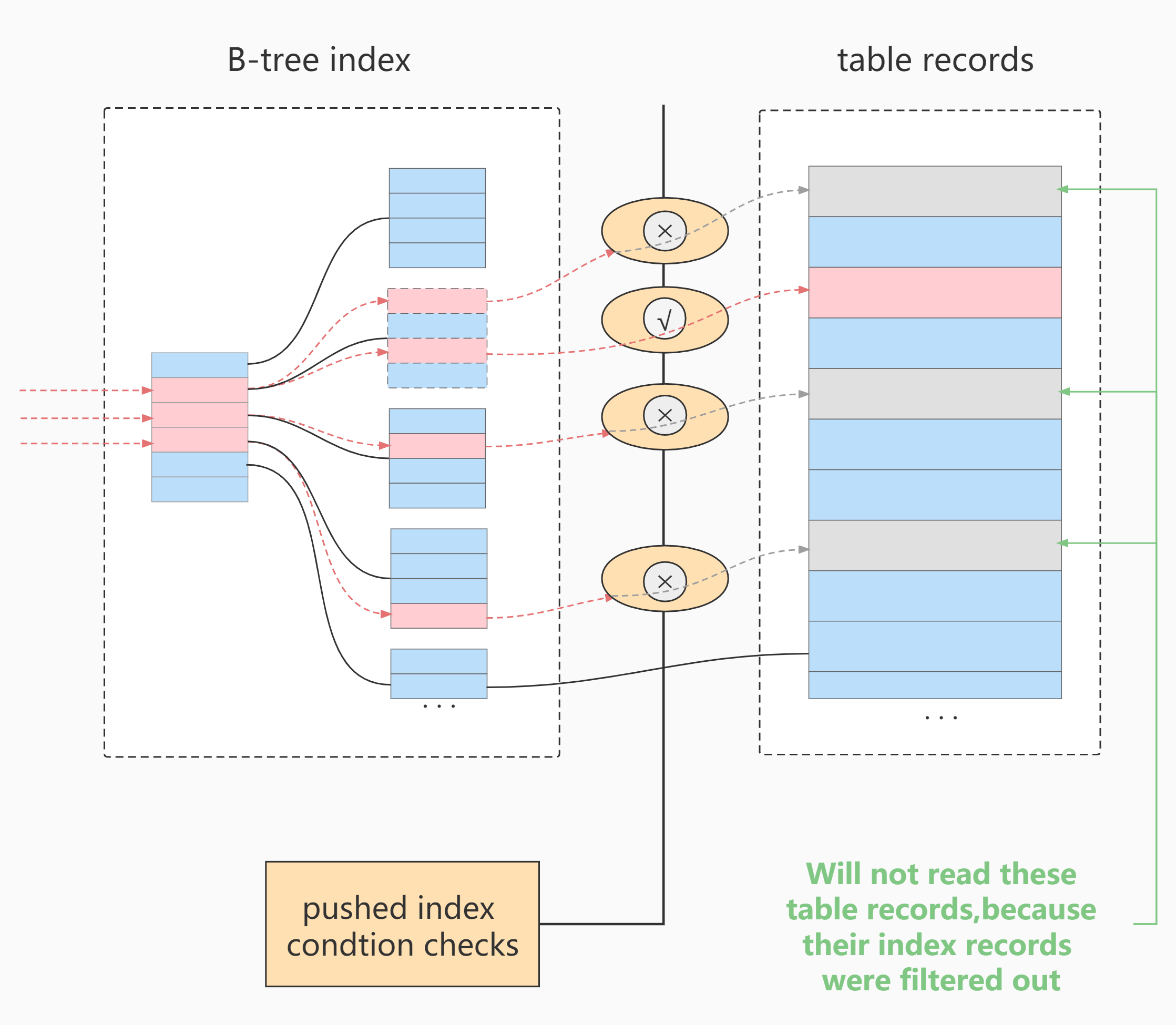
Cost difference before and after use:
Before use, the storage layer returns more than one row of records that need to be filtered out by the index filter
After using ICP, the records that do not meet the index filter conditions are directly removed, and the cost of returning to the table and transmitting to the server layer is saved.
The acceleration effect of ICP depends on the proportion of data filtered by ICP in the storage engine.
2. Service conditions of ICP
Service conditions of ICP:
① Can only be used for secondary indexes
② The type values (join types) in the execution plan displayed in explain are range, ref and eq_ref or ref_or_null.
③ Not all where conditions can be filtered by ICP. If the field of where condition is not in the index column, you still need to read the records of the whole table to the server for where filtering.
④ ICP can be used for MyISAM and InnnoDB storage engines
⑤ MySQL version 5.6 does not support the ICP function of partition table, which is supported from version 5.7.
⑥ ICP optimization method is not supported when SQL uses overlay index.
3. ICP use cases
Case 1:
SELECT * FROM tuser WHERE NAME LIKE 'Zhang%' AND age = 10 AND ismale = 1;
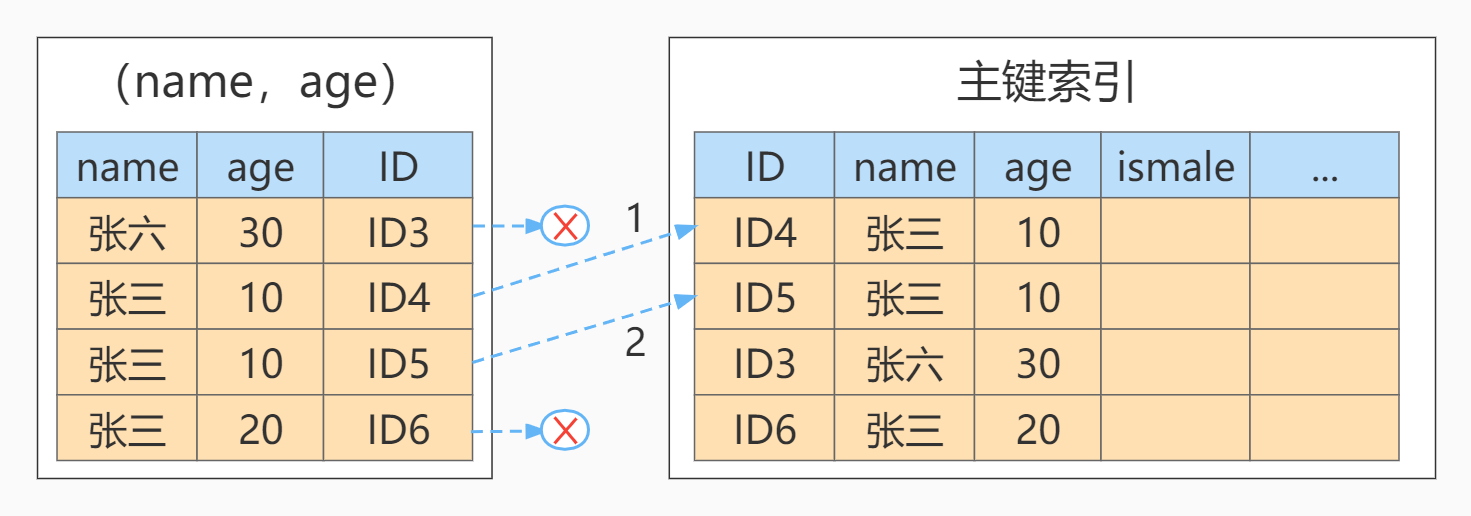
Case 2:
11, Normal index vs unique index
From the perspective of performance, do you choose a unique index or a normal index? What is the basis for selection?
Suppose that we have a table whose primary key column is ID. there is a field K in the table and an index on K. suppose that the values on field k are not repeated. The table creation statement of this table is:
The table creation statement of this table is:
mysql> create table test( id int primary key, k int not null, name varchar(16), index (k) )engine=InnoDB;
The (ID,k) values of R1~R5 in the table are (100,1), (200,2), (300,3), (500,5) and (600,6) respectively.
1. Query process
Suppose that the statement executing the query is select id from test where k=5.
- For ordinary indexes, after finding the first record (5500) that meets the condition, you need to find the next record until you encounter the first record that does not meet the k=5 condition.
- For the unique index, because the index defines uniqueness, the retrieval will stop after finding the first qualified record.
So, how many performance gaps will this difference bring? The answer is, very little.
2. Update process
To illustrate the impact of common indexes and unique indexes on the performance of update statements, let's introduce changebuffer.
When a data page needs to be updated, if the data page is in memory, it will be updated directly. If the data page is not in memory, InooDB will cache these update operations in the change buffer without affecting the data consistency, so there is no need to read the data page from the disk. When the next query needs to access this data page, read the data page into memory, and then perform the operations related to this page in the changebuffer. In this way, the correctness of the data logic can be guaranteed.
The process of applying the operations in the change buffer to the original data page to get the latest results is called merge. Except that accessing this data page will trigger a merge, the system has a background thread that will merge regularly. During the normal shutdown of the database, the merge operation will also be performed.
If the update operation can be recorded in the change buffer first and the disk reading can be reduced, the execution speed of the statement will be significantly improved. Moreover, data reading into memory needs to occupy buffer pool, so this method can also avoid occupying memory and improve memory utilization.
The change buffer cannot be used for the update of unique indexes. In fact, only ordinary indexes can be used.
If you want to insert a new record (4400) into this table, what is the processing flow of InnoDB?
3. Usage scenario of change buffer
- How to choose a common index and a unique index? In fact, there is no difference in query ability between the two types of indexes. The main consideration is the impact on update performance. Therefore, it is recommended that you try to choose a common index.
- In actual use, it will be found that the combination of ordinary index and change buffer is obvious for the update optimization of tables with large amount of data.
- If all updates are immediately followed by the query of this record, you should close the change buffer. In other cases, change buffer can improve update performance.
- Since the unique index does not refer to the optimization mechanism of change buffer, if the service is acceptable, it is recommended to give priority to non unique indexes from the perspective of performance. But what if "the business may not be guaranteed"?
- First, business correctness takes priority. Our premise is to discuss the performance problem when "the business code has guaranteed that duplicate data will not be written". If the business cannot be guaranteed, or the business requires the database to be constrained, there is no choice but to create a unique index. In this case, the significance of this section is to provide you with more troubleshooting ideas when you encounter a large number of slow data insertion and low memory hit rate.
- Then, in some "archive library" scenarios, you can consider using a unique index. For example, online data only needs to be retained for half a year, and then historical data is saved in the archive library. At this time, archiving data is to ensure that there is no single key conflict. To improve the archiving efficiency, consider changing the unique index in the table to an ordinary index.
12, Other query optimization strategies
1. Distinction between EXISTS and IN
Question:
I don't quite understand which case should use EXISTS and which case should use IN. Is the selection criteria based on whether the table index can be used?
2. COUNT(*) and count (specific field) efficiency
Q: there are three ways to count the rows of a data table in MySQL: SELECT COUNT(*), SELECT COUNT(1) and select count (specific fields). What is the query efficiency of using these three methods?
3. About SELECT(*)
In table query, it is recommended to specify the field, not use * as the field list of query, and it is recommended to use Select < field list > query. reason:
① In the process of parsing, MySQL will convert "*" into all column names in order by querying the data dictionary, which will greatly consume resources and time.
② Cannot overwrite index with
4. Impact of LIMIT 1 on Optimization
For SQL statements that can scan the whole table, if you can determine that there is only one result set, when LIMIT 1 is added, the scan will not continue when a result is found, which will speed up the query.
If the data table has established a unique index for fields, you can query through the index. If the whole table is not scanned, you do not need to add LIMIT 1.
5. Multi use COMMIT
Whenever possible, use COMMIT as much as possible in the program, so that the performance of the program can be improved and the requirements will be released due to COMMIT
Reduced resources.
COMMIT will release resources:
- Information on the rollback segment used to recover data
- Lock acquired by program statement
- Space in redo / undo log buffer
- Manage internal expenses in the above three resources
13, How to design the primary key of Taobao database?
Let's talk about a practical problem: how is the primary key designed for Taobao's database?
Some wrong and outrageous answers are still circulating on the Internet year after year, and even become the so-called MySQL military regulations.
One of the most obvious mistakes is the primary key design of MySQL.
Most people's answer is so confident: use 8-byte BIGINT as the primary key instead of INT. wrong!
Such an answer only stands at the database level, and does not think about the primary key from a business perspective. Is a primary key a self incrementing ID? Standing at the new year's slot in 2022 and using self increment as the primary key, you may not even get a pass in architecture design.
1. Self increasing ID problem
Self incrementing ID as the primary key is easy to understand. Almost all databases support self incrementing type, but their implementation is different. In addition to being simple, self incrementing IDs are all disadvantages. Generally speaking, there are the following problems:
- Low reliability
There is a problem of self incrementing ID backtracking, which was not fixed until the latest version of MySQL 8.0. - Low security
The exposed interface can easily guess the corresponding information. For example, with an interface such as: / User/1 /, you can easily guess the value of user ID and the total number of users. You can also easily crawl data through the interface. - Poor performance
The self incrementing ID has poor performance and needs to be generated on the database server. - More interaction
The business needs to perform an additional similar last_insert_id() function can know the self increment just inserted, which requires one more network interaction. In a massive concurrent system, one more SQL will increase the one-time overhead. - Local uniqueness
The most important point is that the self incrementing ID is locally unique. It is only unique in the current database instance, not globally. It is unique among any server. For the current distributed system, this is a nightmare.
2. Business field as primary key
In order to uniquely identify the information of a member, you need to set a primary key for the member information table. So, how can we set the primary key for this table to achieve our ideal goal? Here we consider business fields as primary keys.
The data in the table are as follows:
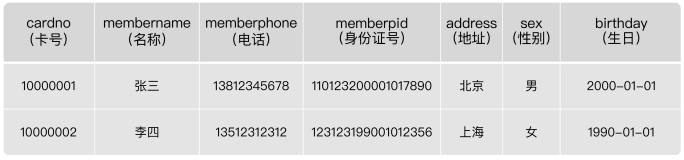
Which field is more appropriate in this table?
- Select card number (cardno)
The membership card number (cardno) looks more appropriate, because the membership card number cannot be empty and unique, which can be used to identify a member record.
mysql> CREATE TABLE demo.membermaster -> ( -> cardno CHAR(8) PRIMARY KEY, -- Membership card number is the primary key -> membername TEXT, -> memberphone TEXT, -> memberpid TEXT, -> memberaddress TEXT, -> sex TEXT, -> birthday DATETIME -> ); Query OK, 0 rows affected (0.06 sec)
Different membership card numbers correspond to different members, and the field "cardno" uniquely identifies a member. If this is the case, the member card number corresponds to the member one by one, and the system can operate normally.
However, the actual situation is that the membership card number may be reused. For example, Zhang San moved away from his original address due to work change and no longer spent in the merchant's store (returned his membership card), so Zhang San is no longer a member of the merchant's store. However, the merchant didn't want the membership card to be empty, so he sent the membership card with the card number of "10000001" to Wang Wu.
From the perspective of system design, this change only modifies the member information that the card number in the member information table is "10000001", which will not affect the data consistency. In other words, if the membership card number is "10000001", each module of the system will obtain the modified membership information, and there will be no situation that "some modules obtain the member information before modification, and some modules obtain the modified member information, resulting in inconsistent internal data of the system". Therefore, from the perspective of information system, it is no problem.
However, from the business level of using the system, there are great problems, which will have an impact on businesses.
For example, we have a sales flow table (trans), which records all sales flow details. On December 1, 2020, Zhang San bought a book in the store and consumed 89 yuan. Then, the system has the daily record of Zhang San's book purchase, as shown below:

Next, let's check the member sales records on December 1, 2020:
mysql> SELECT b.membername,c.goodsname,a.quantity,a.salesvalue,a.transdate -> FROM demo.trans AS a -> JOIN demo.membermaster AS b -> JOIN demo.goodsmaster AS c -> ON (a.cardno = b.cardno AND a.itemnumber=c.itemnumber); +------------+-----------+----------+------------+---------------------+ | membername | goodsname | quantity | salesvalue | transdate | +------------+-----------+----------+------------+---------------------+ | Zhang San | book | 1.000 | 89.00 | 2020-12-01 00:00:00 | +------------+-----------+----------+------------+---------------------+ 1 row in set (0.00 sec)
If the membership card "10000001" is sent to Wang Wu, we will change the membership information form. When causing a query:
mysql> SELECT b.membername,c.goodsname,a.quantity,a.salesvalue,a.transdate -> FROM demo.trans AS a -> JOIN demo.membermaster AS b -> JOIN demo.goodsmaster AS c -> ON (a.cardno = b.cardno AND a.itemnumber=c.itemnumber); +------------+-----------+----------+------------+---------------------+ | membername | goodsname | quantity | salesvalue | transdate | +------------+-----------+----------+------------+---------------------+ | Wang Wu | book | 1.000 | 89.00 | 2020-12-01 00:00:00 | +------------+-----------+----------+------------+---------------------+ 1 row in set (0.01 sec)
The result of this time is: Wang Wu bought a book on December 1, 2020, with a consumption of 89 yuan. Obviously wrong!
Conclusion: never use the membership card number as the primary key.
- Choose a member's phone number or ID number.
Can member phone be used as primary key? No. In practice, the mobile phone number is also taken back by the operator and reissued to others.
Can ID number be ok? I think so. Because ID cards will never be duplicated, and ID number is one-to-one with a person. The problem is that the ID number is personal privacy and the customer will not be willing to give it to you. If the member is required to register his ID number, he will drive many guests away. In fact, the customer phone also has this problem, which is when we design the membership information table, allowing the ID number and telephone are empty.
Therefore, it is recommended not to use business-related fields as primary keys. After all, as technicians of project design, none of us can predict which business fields will be repeated or reused due to the business requirements of the project in the whole life cycle of the project.
Experience:
At the beginning of using MySQL, many people easily make the mistake of using business fields as primary keys. They take it for granted that they understand business requirements, but the actual situation is often unexpected, and the cost of changing the primary key setting is very high.
3. Primary key design of Taobao
In Taobao's e-commerce business, order service is a core business. How is the primary key of the order table designed by Taobao? Is it a self increasing ID?
Open Taobao and have a look at the order information:
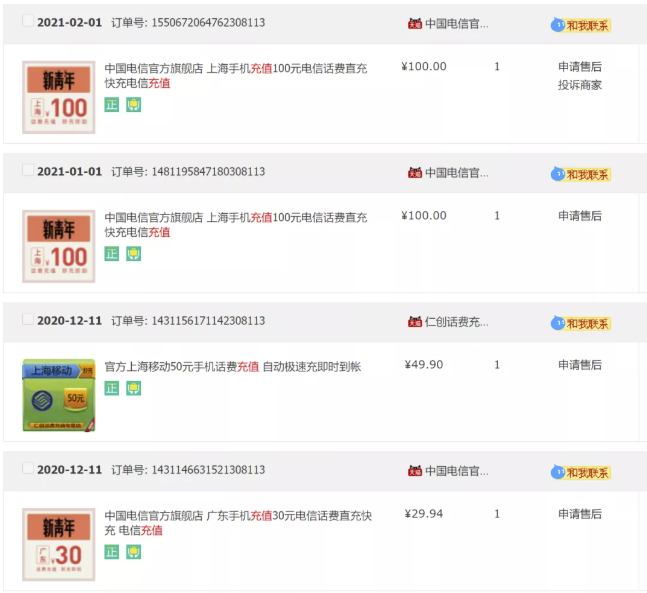
It can be seen from the above figure that the order number is not a self incrementing ID! Let's take a detailed look at the above four order numbers:
1550672064762308113 1481195847180308113 1431156171142308113 1431146631521308113
The order number is 19 digits long, and the last 5 digits of the order are the same, all 08113. And the first 14 digits of the order number are monotonically increasing.
It is a bold guess that the order ID design of Taobao should be:
order ID = time + De duplication field + user ID Last 6 digits
This design can be globally unique and friendly to distributed system query.
4. Recommended primary key design
The order can be achieved by changing the time sorting of UUID s and putting the hours, minutes and seconds in front instead of the default seconds, minutes and seconds
Non core business: self incrementing ID of the primary key of the corresponding table, such as alarm, log, monitoring and other information.
Core business: the primary key design should at least be globally unique and monotonically increasing. Global uniqueness is guaranteed to be unique among all systems. Monotonic increment is to hope that the database performance will not be affected during insertion.
Here we recommend the simplest primary key design: UUID.
UUID features:
Globally unique, occupying 36 bytes, disordered data and poor insertion performance.
Recognize UUID:
- Why is UUID globally unique?
- Why does UUID occupy 36 bytes?
- Why are UUID s out of order?
The UUID composition of MySQL database is as follows:
UUID = time+UUID Version (16 bytes)- Clock sequence (4 bytes) - MAC Address (12 bytes)
Take UUID value e0ea12d4-6473-11eb-943c-00155dbaa39d as an example:
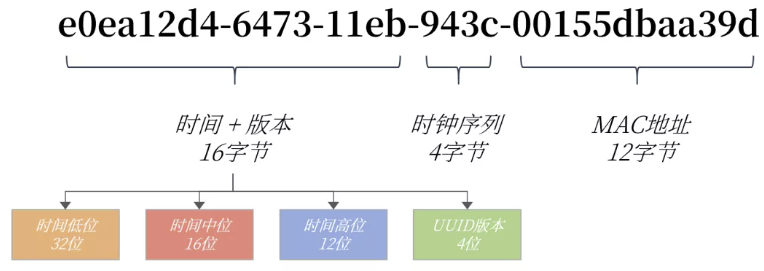
Why is UUID globally unique?
In the UUID, the time part occupies 60 bits. The TIMESTAMP is similar to that of TIMESTAMP, but it represents the count of 100ns from 1582-10-15 00:00:00.00 to the present. It can be seen that the time accuracy of UUID storage is higher than that of TIMESTAMP, and the probability of repetition of time dimension is reduced to 1/100ns.
The clock sequence is to avoid the possibility of time repetition caused by clock callback. The MAC address is used for global uniqueness.
Why does UUID occupy 36 bytes?
UUID is stored according to the string, and it is also designed with useless "-" string, so a total of 36 bytes are required.
Why are UUID s random and unordered?
Because in the design of UUID, the low order of time is put in the front, and the data in this part is always changing and out of order.
Modified UUID
If the high and low positions of time are exchanged, time is monotonically increasing, and it will become monotonically increasing. MySQL 8.0 can change the storage mode of low time and high time, so that UUIDs are ordered UUIDs.
MySQL 8.0 also solves the problem of space occupation of UUID, removes the meaningless "-" string in UUID string, and saves the string in binary type, so that the storage space is reduced to 16 bytes.
You can use MySQL 8 UUID provided by 0_ to_ The bin function implements the above functions. Similarly, MySQL also provides bin_to_uuid function
Conversion:
SET @uuid = UUID(); SELECT @uuid,uuid_to_bin(@uuid),uuid_to_bin(@uuid,TRUE);

By function uuid_to_bin(@uuid,true) converts UUIDs into ordered UUIDs. Globally unique + monotonically increasing, this is not the primary key we want!
Ordered UUID performance test
How is the performance and storage space of the 16 byte ordered UUID compared with the previous 8-byte self incrementing ID?
Let's do a test and insert 100 million pieces of data. Each data occupies 500 bytes and contains three secondary indexes. The final results are as follows:
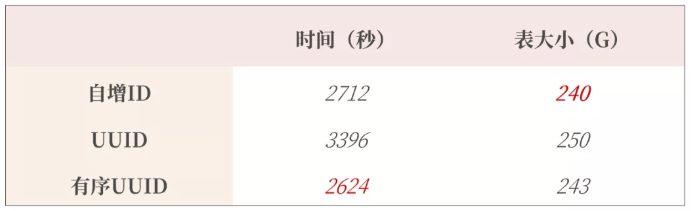 As can be seen from the figure above, inserting 100 million data ordered UUIDs is the fastest, and in actual business use, ordered UUIDs can be generated at the business end.
As can be seen from the figure above, inserting 100 million data ordered UUIDs is the fastest, and in actual business use, ordered UUIDs can be generated at the business end.
You can also further reduce the number of SQL interactions. In addition, although the ordered UUID is 8 bytes more than the self incrementing ID, it only increases the storage space of 3G, which is acceptable
In today's Internet environment, the database design with self incrementing ID as the primary key is not recommended. A globally unique implementation similar to ordered UUID s is more recommended.
In addition, in the real business system, the primary key can also add business and system attributes, such as the user's tail number, the information of the computer room, etc. Such primary key design will test the level of architects.
If it's not MySQL 8 What about 0 swelling?
Manually assign fields as primary keys!
For example, design the primary key of the member table of each branch, because if the data generated by each machine needs to be merged, there may be a problem of duplicate primary keys.
There is a management information table in the MySQL database of the headquarters. A field is added to this table to record the maximum value of the current member number.
When adding a member, the store first obtains the maximum value in the headquarters MySQL database, adds 1 on this basis, then uses this value as the "id" of the new member, and updates the maximum value of the current member number in the management information table of the headquarters MySQL database.
In this way, when each store adds members, it operates on the data table fields in the MySQL database of the same headquarters, which solves the problem of member number conflict when each store adds members.