This paper introduces the multitasking learning algorithm published by Ali in 2019. The model shows the Bayesian network causality between targets, integrates and models the complex causality network between features and multiple targets, and eliminates the strong independent assumptions in the general MTL model. Since there is no specific assumption about the target distribution, it can be naturally extended to any form of target.
Multitasking learning background
At present, the recommendation algorithms used in industry are not only limited to single target (ctr) tasks, but also need to pay attention to the subsequent transformation links, such as whether to comment, collect, add purchase, purchase, viewing time and so on.
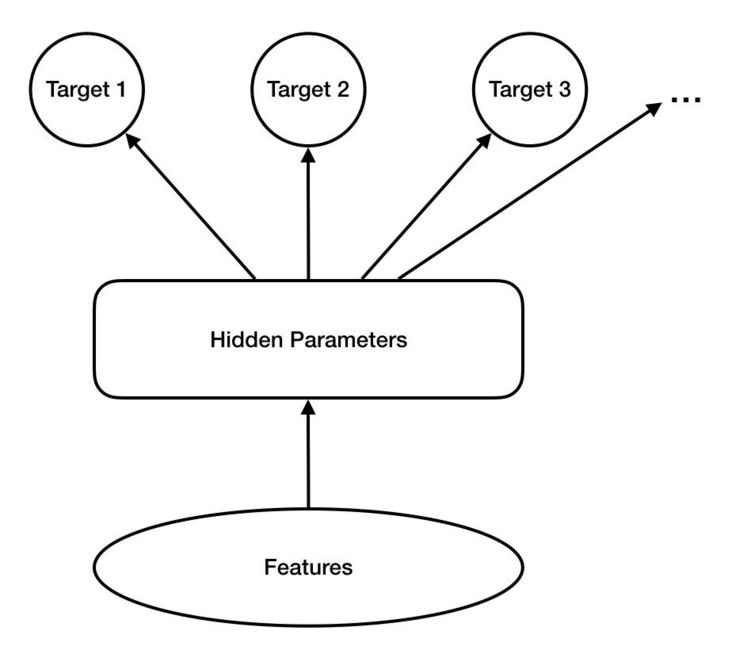
The common multi-objective optimization model starts from the separate model network of each optimization goal, and realizes the appropriate degree of independence and correlation of each goal related model by making these networks share parameters at the bottom. This kind of model framework can be summarized by the structure in the figure above. No matter how the bottom layer shares parameters, these networks should extend some independent branches in the last few layers to predict the final value of each target. The probability model of such networks can be described by the following formula:
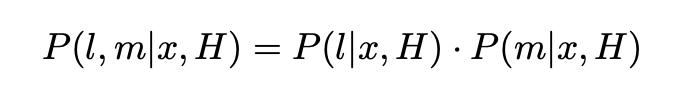
Where l and m are the target, x is the sample feature and H is the model. The assumption that each goal is independent is made here.
Introduction to DBMTL
A starting point of dbmtl (deep Bayesian multi target learning) is to solve the above problems. In fact, applying the simple Bayesian formula, the probability model can be written as:
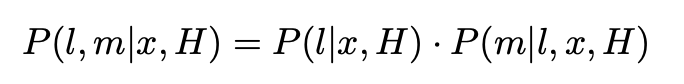
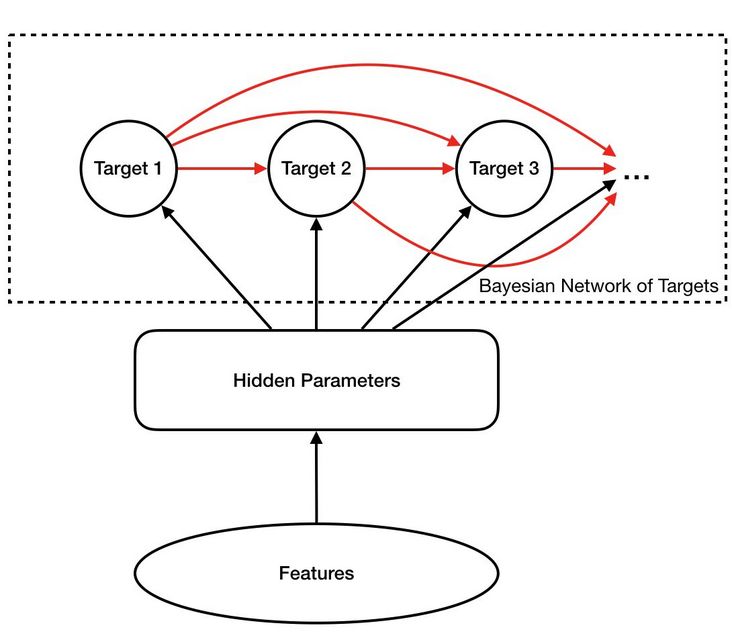
As shown in the figure below, the main difference between DBMTL and traditional MTL structure (considering each target independent) is that the Bayesian network between target node s is constructed to explicitly model the possible causal relationship between targets. Because in the actual business, many behaviors of users often have obvious sequence dependence. For example, in the information flow scenario, users need to click into the picture and text details page before they can carry out subsequent operations such as browsing / comment / forwarding / collection. DBMTL embodies these relationships in the model structure, so it can often learn better results.
The following figure shows the specific implementation of DBMTL model. The network includes input layer, shared embedding layer, shared layer, distinction layer and Bayesian layer.
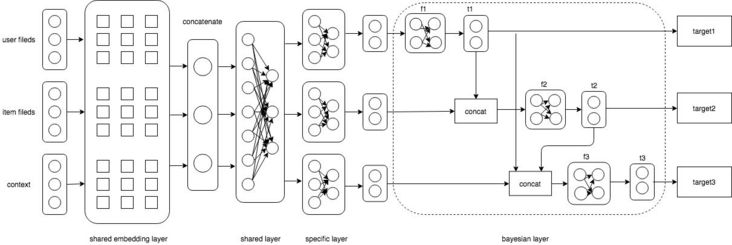
- The shared embedding layer is a shared lookup table shared by each target training center.
- The sharing layer and separation layer are general multilayer perceptron (MLP), which respectively model the shared / differentiated representation of each target.
- The Bayesian layer is the most important part of DBMTL. It implements the following probability model:
The corresponding log likelihood loss function is:
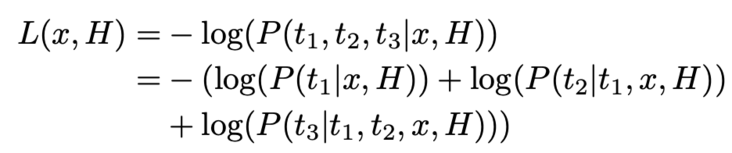
In practical application, it still plays a great practical role in adjusting power for different objectives. When giving different weights to the target, it is equivalent to re expressing the loss function as:

In the Bayesian layer of the network, the functions F1, F2 and F3 are implemented as fully connected MLP to learn the implicit causality between objectives. They cascade the embedding of function input variables as input, and input an embedding representing the function output variables. The embedding of each target finally passes through a layer of MLP to output the probability of the final target.
code implementation
be based on EasyRec recommended algorithm framework , we have implemented the DBMTL algorithm. The specific implementation can be moved to github: EasyRec-DBMTL.
Introduction to EasyRec: EasyRec is an open-source large-scale distributed recommendation algorithm framework of the machine learning PAI team of Alibaba cloud computing platform. EasyRec is as simple and easy to use as its name. It integrates many excellent cutting-edge recommendation system thesis ideas, and has achieved excellent results in the actual industrial implementation. It integrates training, evaluation and deployment, Seamlessly connected with Alibaba cloud products, EasyRec can build a cutting-edge recommendation system in a short time. As Alibaba cloud's flagship product, it has stably served hundreds of enterprise customers.
Model feedforward network
def build_predict_graph(self):
"""Forward function.
Returns:
self._prediction_dict: Prediction result of two tasks.
"""
# Here, the generation logic is omitted from the tensor (self._features) after sharing the embedding layer
# shared layer
if self._model_config.HasField('bottom_dnn'):
bottom_dnn = dnn.DNN(
self._model_config.bottom_dnn,
self._l2_reg,
name='bottom_dnn',
is_training=self._is_training)
bottom_fea = bottom_dnn(self._features)
else:
bottom_fea = self._features
# MMOE block
if self._model_config.HasField('expert_dnn'):
mmoe_layer = mmoe.MMOE(
self._model_config.expert_dnn,
l2_reg=self._l2_reg,
num_task=self._task_num,
num_expert=self._model_config.num_expert)
task_input_list = mmoe_layer(bottom_fea)
else:
task_input_list = [bottom_fea] * self._task_num
tower_features = {}
# specific layer
for i, task_tower_cfg in enumerate(self._model_config.task_towers):
tower_name = task_tower_cfg.tower_name
if task_tower_cfg.HasField('dnn'):
tower_dnn = dnn.DNN(
task_tower_cfg.dnn,
self._l2_reg,
name=tower_name + '/dnn',
is_training=self._is_training)
tower_fea = tower_dnn(task_input_list[i])
tower_features[tower_name] = tower_fea
else:
tower_features[tower_name] = task_input_list[i]
tower_outputs = {}
relation_features = {}
# bayesian network
for task_tower_cfg in self._model_config.task_towers:
tower_name = task_tower_cfg.tower_name
relation_dnn = dnn.DNN(
task_tower_cfg.relation_dnn,
self._l2_reg,
name=tower_name + '/relation_dnn',
is_training=self._is_training)
tower_inputs = [tower_features[tower_name]]
for relation_tower_name in task_tower_cfg.relation_tower_names:
tower_inputs.append(relation_features[relation_tower_name])
relation_input = tf.concat(
tower_inputs, axis=-1, name=tower_name + '/relation_input')
relation_fea = relation_dnn(relation_input)
relation_features[tower_name] = relation_fea
output_logits = tf.layers.dense(
relation_fea,
task_tower_cfg.num_class,
kernel_regularizer=self._l2_reg,
name=tower_name + '/output')
tower_outputs[tower_name] = output_logits
self._add_to_prediction_dict(tower_outputs)Loss calculation
def build(loss_type, label, pred, loss_weight=1.0, num_class=1, **kwargs):
if loss_type == LossType.CLASSIFICATION:
if num_class == 1:
return tf.losses.sigmoid_cross_entropy(
label, logits=pred, weights=loss_weight, **kwargs)
else:
return tf.losses.sparse_softmax_cross_entropy(
labels=label, logits=pred, weights=loss_weight, **kwargs)
elif loss_type == LossType.CROSS_ENTROPY_LOSS:
return tf.losses.log_loss(label, pred, weights=loss_weight, **kwargs)
elif loss_type in [LossType.L2_LOSS, LossType.SIGMOID_L2_LOSS]:
logging.info('%s is used' % LossType.Name(loss_type))
return tf.losses.mean_squared_error(
labels=label, predictions=pred, weights=loss_weight, **kwargs)
elif loss_type == LossType.PAIR_WISE_LOSS:
return pairwise_loss(pred, label)
else:
raise ValueError('unsupported loss type: %s' % LossType.Name(loss_type))
def _build_loss_impl(self,
loss_type,
label_name,
loss_weight=1.0,
num_class=1,
suffix=''):
loss_dict = {}
if loss_type == LossType.CLASSIFICATION:
loss_name = 'cross_entropy_loss' + suffix
pred = self._prediction_dict['logits' + suffix]
elif loss_type in [LossType.L2_LOSS, LossType.SIGMOID_L2_LOSS]:
loss_name = 'l2_loss' + suffix
pred = self._prediction_dict['y' + suffix]
else:
raise ValueError('invalid loss type: %s' % LossType.Name(loss_type))
loss_dict[loss_name] = build(loss_type,
self._labels[label_name],
pred,
loss_weight, num_class)
return loss_dict
def build_loss_graph(self):
"""Build loss graph for multi task model."""
for task_tower_cfg in self._task_towers:
tower_name = task_tower_cfg.tower_name
loss_weight = task_tower_cfg.weight * self._sample_weight
if hasattr(task_tower_cfg, 'task_space_indicator_label') and \
task_tower_cfg.HasField('task_space_indicator_label'):
in_task_space = tf.to_float(
self._labels[task_tower_cfg.task_space_indicator_label] > 0)
loss_weight = loss_weight * (
task_tower_cfg.in_task_space_weight * in_task_space +
task_tower_cfg.out_task_space_weight * (1 - in_task_space))
# The EasyRec framework automatically updates self_ loss_ Add the loss in dict.
self._loss_dict.update(
self._build_loss_impl(
task_tower_cfg.loss_type,
label_name=self._label_name_dict[tower_name],
loss_weight=loss_weight,
num_class=task_tower_cfg.num_class,
suffix='_%s' % tower_name))
return self._loss_dictapplication
Because of its excellent algorithm effect, DBMTL is widely used in PAI.
Taking a live broadcast recommendation service as an example, the scenario includes is_click, is_view, view_costtime, is_on_mic, on_mic_duration multiple targets, where is_click, is_view, is_on_mic is a two category task, view_costtime, on_mic_duration is the regression task of the predicted duration. The dependencies of user behavior are:
- is_click=> is_view
- is_click+is_view=> view_costtime
- is_click=> is_on_mic
- is_click+is_on_mic => on_mic_duration
Therefore, the configuration is as follows:
dbmtl {
bottom_dnn {
hidden_units: [512, 256]
}
task_towers {
tower_name: "is_click"
label_name: "is_click"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "is_view"
label_name: "is_view"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "view_costtime"
label_name: "view_costtime"
loss_type: L2_LOSS
metrics_set: {
mean_squared_error {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click", "is_view"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "is_on_mic"
label_name: "is_on_mic"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "on_mic_duration"
label_name: "on_mic_duration"
loss_type: L2_LOSS
metrics_set: {
mean_squared_error {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click", "is_on_mic"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
l2_regularization: 1e-6
}
embedding_regularization: 5e-6
}It is worth mentioning that after the DBMTL model was launched, the online onlooking rate increased by 18% and the wheat rate increased by 14% compared with GBDT+FM (onlooking single target).
reference
Introduction to easyrec dbmtl model
Easyrec dbmtl model source code
Note: the pictures and formulas in this paper are quoted from the paper: DBMTL paper