DCGAN - use paddlepaddle2 0 implementation
brief introduction
- Dcgan (deep convolution generation countermeasure network), which is composed of a generation model and a discrimination model. The generation model is used to generate pictures, and the discrimination model is used to distinguish the authenticity of the generated pictures. Continuously generate and discriminate, and the network can gradually generate more realistic pictures.
- The preview effect is as follows
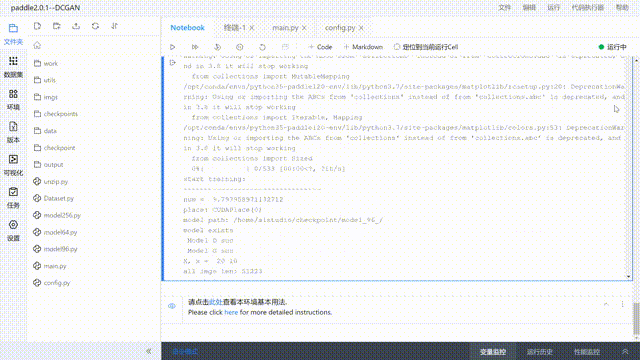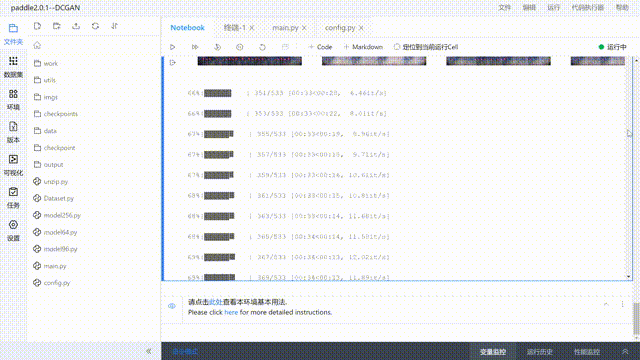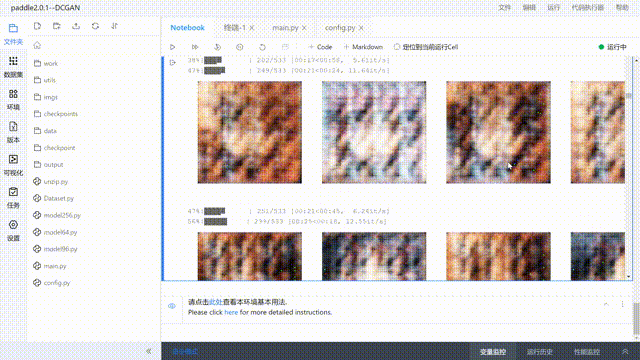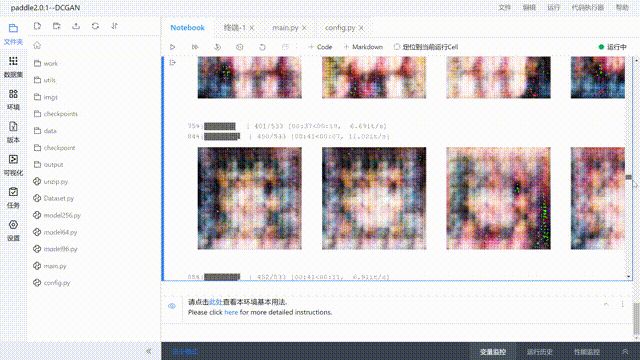
directory structure
-- root
-- data
-- imgs
-- models
-- output
config.py
Dataset.py
main.py
model64.py
model96.py
tools.py
unzip.py
Catalog description
- root is the working directory
- data stores the dataset directory, where the compressed files of the dataset are stored
- imgs stores the decompressed data set
- The intermediate parameters of different models are stored in models
- output stores preview pictures during training
- The rest with suffix are not directories
My code
1.) decompression operation
- Corresponding to unzip Py, which is used to decompress the dataset compressed package to the destination directory.
'''decompression zip File to destination directory'''
import zipfile
import os
# zip_src: the path of the file that needs to be unzipped
# dst_dir: file storage path after decompression
def unzip_file(zip_src, dst_dir):
r = zipfile.is_zipfile(zip_src)
if r:
fz = zipfile.ZipFile(zip_src, 'r')
for file in fz.namelist():
fz.extract(file, dst_dir)
else:
print('This is not a zip file !!!')
2.) configuration file
- Corresponding to config Py, which can be modified according to personal needs
import os
class Config:
img_size=96
lr = 0.0002
z_dim = 100 # Noise dimension
g_every = 4 # Train the generator every 5 batch es
d_every = 2 # The discriminator is trained every three batch es
test = False
epoch = 100 # Number of iterations
batch_size = 24 #
# Two parameters of BCELOSS
beta1=0.5
beta2=0.999
imgs_path = os.getcwd() + "/imgs/faces/" # Picture path
# output='/root/paddlejob/workspace/output'
output = os.getcwd()
output_path = output + '/output/' # Output picture path
checkpoints_path= output + f'/models/models_{img_size}/' #Checkpoint directory
3.) dataset
- Corresponding dataset Py, which is mainly convenient for asynchronous data reading and main Dataloader in PY
import os
import paddle
from paddle.io import Dataset
from PIL import Image
import paddle.vision.transforms as T
import cv2
from config import Config
opt=Config()
class DataGenerater(Dataset):
def __init__(self,opt=opt):
super(DataGenerater, self).__init__()
self.dir = opt.imgs_path
self.datalist = os.listdir(self.dir) if opt.test==False else os.listdir(self.dir)[:100]
self.batch_size=opt.batch_size
img=Image.open(self.dir+self.datalist[0])
self.image_size = img.size
img.close()
self.transform=T.Compose([
T.Resize(opt.img_size),
T.CenterCrop(opt.img_size),
T.ToTensor(),
])
self.num_path_dict={}
# Data and corresponding tags are returned at each iteration
def __getitem__(self, idx):
path=self.dir + self.datalist[idx]
img=cv2.imread(path)
if self.transform:
img=self.transform(img)
self.num_path_dict[idx]=path
return (img, idx)
def get_img_path(self, idx):
return self.num_path_dict[idx]
# Returns the total number of the entire dataset
def __len__(self):
return len(self.datalist)
4.) generator and discriminator
-
The generator and discriminator may be difficult to understand. It is recommended to refer to them Wu danen's class . Through learning, you can understand the convolution, pooling process and some professional concepts more easily than reading books;
-
Then I built a model with a training picture size of 96 x 96128 x 128256 x 256, but the effect was not very good, so I didn't put it out;
-
Can refer to My project paddle2 0.1-DCGAN
-
First import the necessary libraries
import paddle import paddle.nn as nn import paddle.nn.functional as F from tools import conv_initializer,bn_initializer
- Then the discriminator is defined
class Discriminator(nn.Layer):
def __init__(self, channels_img, features_d):
super(Discriminator, self).__init__()
# Input : N x C x 64 x 64
self.disc=nn.Sequential(
nn.Conv2D( # 32 x 32
channels_img, features_d, kernel_size=4, stride=2, padding=1,
weight_attr=paddle.ParamAttr(initializer=conv_initializer())
),
nn.LeakyReLU(0.2),
self._block(features_d , features_d*2 , 4, 2, 1), # 16 x 16
self._block(features_d*2 , features_d*4 , 4, 2, 1), # 8 x 8
self._block(features_d*4 , features_d*8 , 4, 2, 1), # 4 x 4
nn.Conv2D( features_d*8, 1, kernel_size=4, stride=2, padding=0,# 1 x 1
weight_attr=paddle.ParamAttr(initializer=conv_initializer() )
),
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2D(
in_channels, out_channels, kernel_size, stride, padding, bias_attr=False,
weight_attr=paddle.ParamAttr(initializer=conv_initializer() )
),
nn.LeakyReLU(0.2),
)
def forward(self, input):
return self.disc(input)
- Then the generator
class Generator(nn.Layer):
def __init__(self, z_dim, channels_img, features_g):
super(Generator, self).__init__()
self.gen=nn.Sequential(
# Input: N x z_dim x 1 x 1
self._block(z_dim , features_g*16 , 4, 1, 0), # N x f_g x 16 x 16
self._block(features_g*16 , features_g*8 , 4, 2, 1), # N x f_g x 32 x 32
self._block(features_g*8 , features_g*4 , 4, 2, 1), # N x f_g x 64 x 64
self._block(features_g*4 , features_g*2 , 4, 2, 1), # N x f_g x 128 x 128
nn.Conv2DTranspose(
features_g*2, channels_img, kernel_size=4, stride=2, padding=1, bias_attr=False,
weight_attr=paddle.ParamAttr(initializer=conv_initializer() )
),
nn.Tanh() # [-1, 1]
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2DTranspose(
in_channels, out_channels, kernel_size, stride, padding, bias_attr=False,
weight_attr=paddle.ParamAttr(initializer=conv_initializer() )
),
nn.BatchNorm2D(
out_channels,
weight_attr=paddle.ParamAttr(initializer=bn_initializer() ) ,
momentum=0.8
),
nn.ReLU(),
)
def forward(self, input):
return self.gen(input)
- Finally, test the code to detect whether the output shape is wrong
def test():
N, C, H, W= 8, 3, 64, 64
z_dim = 100
X=paddle.randn( (N, C, H, W ))
disc = Discriminator(C, N)
print("1:",disc(X).shape)
assert disc(X).shape == [N, 1, 1 ,1]
z=paddle.randn( (N, z_dim, 1, 1) )
gen=Generator(z_dim, C, N)
print("2:",gen(z).shape)
test()
5.) main function
- Import the necessary libraries
import os
import paddle
import paddle.nn as nn
import paddle.fluid as fluid
import paddle.optimizer as optim
import paddle.vision.transforms as T
import cv2
from tqdm import tqdm
import matplotlib
matplotlib.use('Agg')
# %matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import time
from tools import tensor_to_img
from Dataset import DataGenerater
from unzip import unzip_file
from config import Config
import warnings
import math
import random
- Initialize the configuration and decompress the dataset
opt = Config()
if opt.img_size==64:
from model64 import Generator,Discriminator
elif opt.img_size==96:
from model96 import Generator,Discriminator
elif opt.img_size==256:
from model256 import Generator,Discriminator
if not os.path.exists(opt.imgs_path):
print("Start decompression")
unzip_file('data/data_test/test_faces.zip', './imgs')
print("Decompression complete")
if not os.path.exists(os.getcwd() + f'/models/'):
os.mkdir( os.getcwd() + f'/models/' )
os.mkdir( opt.checkpoints_path )
warnings.filterwarnings('ignore')
paddle.disable_static()
use_gpu = paddle.is_compiled_with_cuda()
place = paddle.fluid.CUDAPlace(0) if use_gpu else paddle.fluid.CPUPlace()
- The main module includes reading in the trained model, training, displaying, and saving the model
if __name__=="__main__":
batch_size=opt.batch_size
lr=opt.lr
z_dim = opt.z_dim
beta1,beta2=opt.beta1,opt.beta2
losses =[[],[]]
real_label = paddle.full( (opt.batch_size,1,1,1), 1., dtype='float32')
fake_label = paddle.full( (opt.batch_size,1,1,1), 0., dtype='float32')
X = 20 #Window size
#Number of child windows in a row
num=math.sqrt(batch_size)
x=round(num) if math.fabs( math.floor(num)**2-batch_size )<1e-6 else math.floor(num)+1
print("start training: ")
print("---------------------------------")
print("num = ",num)
with paddle.fluid.dygraph.guard(place):
#loss function
loss = nn.BCELoss()
netD = Discriminator(channels_img=3, features_d=10)
netG = Generator(z_dim=z_dim, channels_img=3, features_g=10)
optimizerD = optim.Adam(parameters=netD.parameters(), learning_rate=lr, beta1=beta1, beta2=beta2)
optimizerG = optim.Adam(parameters=netG.parameters(), learning_rate=lr, beta1=beta1, beta2=beta2)
if not os.path.exists( opt.checkpoints_path ):
os.mkdir( opt.checkpoints_path )
if not os.path.exists( opt.output_path ):
os.mkdir( opt.output_path)
last = opt.img_size
order_name = 9
model_path = opt.checkpoints_path+ f"model_{last}_{order_name}/"
print("model path:", model_path)
if os.path.exists(model_path):
print("model exists")
netD_dict, optD_dict = paddle.load(model_path+"netD.pdparams" ), \
paddle.load(model_path+"adamD.pdopt" )
netD.set_state_dict( netD_dict )
optimizerD.set_state_dict( optD_dict )
print(" Model D suc")
netG_dict, optG_dict = paddle.load(model_path+"netG.pdparams" ), \
paddle.load(model_path+"adamG.pdopt" )
netG.set_state_dict( netG_dict )
optimizerG.set_state_dict( optG_dict )
print(" Model G suc")
plt.ion()
train_dataset = DataGenerater(opt=opt)
train_loader = paddle.io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
print("X, x = ",X,x)
count=0
print("all imgs len:", len(train_dataset))
for pass_id in range(opt.epoch):
print(f"epotch {pass_id}: ", end=" " )
for batch_id, (data, labels) in enumerate( tqdm(train_loader) ):
#Training discriminator
if batch_id % opt.d_every==0:
# print("train dis:")
optimizerD.clear_grad()
output = netD(data)
errD_real = loss(output, real_label)
errD_real.backward()
optimizerD.step()
optimizerD.clear_grad()
noise = paddle.randn([batch_size, z_dim, 1, 1],'float32')
fake = netG(noise)
output = netD(fake.detach())
errD_fake = loss(output, fake_label)
errD_fake.backward()
optimizerD.step()
optimizerD.clear_grad()
errD = errD_real + errD_fake
losses[0].append(errD.numpy()[0])
if batch_id % opt.g_every==0:
###Training generator
# print("train gen:")
optimizerG.clear_grad()
noise = paddle.randn([batch_size, z_dim, 1, 1] , 'float32')
fake = netG(noise)
output = netD(fake)
errG = loss(output, real_label)
errG.backward()
optimizerG.step()
optimizerG.clear_grad()
losses[1].append(errG.numpy()[0])
if batch_id % 50 == 0:
# Generation results of each round
generated_image = netG(noise).numpy()
imgs=np.split(generated_image, generated_image.shape[0], 0)
plt.figure(figsize=(16, 4))
for i, ele in enumerate(imgs):
if i==4:
break
temp_img=ele.squeeze(0)
temp_img=tensor_to_img(temp_img)
plt.subplot(1, 4, i+1)
plt.axis('off') #Remove the coordinate axis
plt.imshow(temp_img)
plt.savefig(opt.output_path+f"{pass_id}_{count}.jpg")
count+=1
plt.pause(1e-10)
if pass_id % 2==0:
order = order_name+ 1+ pass_id//2
model_path = opt.checkpoints_path + f"model_{opt.img_size}_{order}/"
if not os.path.exists(model_path):
os.mkdir(model_path)
netD_path, optimD_path = model_path+"netD.pdparams", model_path+"adamD.pdopt"
netD_dict, optD_dict = netD.state_dict(), optimizerD.state_dict()
paddle.save(netD_dict , netD_path )
paddle.save(optD_dict , optimD_path)
netG_path, optimG_path = model_path+"netG.pdparams", model_path+"adamG.pdopt"
netG_dict, optG_dict = netG.state_dict(), optimizerG.state_dict()
paddle.save(netG_dict , netG_path )
paddle.save(optG_dict , optimG_path)
other
-
When I first saw the video explaining the algorithm, I thought it would be easy to write code as long as I knew the principle, but the fact is just the opposite. Because what I learned from the video is only a general idea, I still need to pay attention to many details in the specific implementation process, such as hardware and software configuration, and how to obtain data, how to read and write data, and how to analyze data. For example, when I write a DataLoader, I try to rewrite it in my own way. It does have some results, but the efficiency of data loading and access is low. Even if I try to improve the speed of data loading through multithreading and multiprocessing, there will still be many bug s; Limited to their own knowledge reserves, they have to borrow stones from other mountains.
-
Next, take time to look at various algorithms.
2021-04-10 update, thanks for watching-