What is feature extraction?


1.1 definitions
Convert any data (such as text or image) into digital features that can be used for machine learning
Note: eigenvalue is for the computer to better understand the data
- Feature extraction classification:
- Dictionary feature extraction (feature discretization)
- Text feature extraction
- Image feature extraction (depth learning will be introduced)
1.2 feature extraction API
sklearn.feature_extraction
1.1 definitions
Convert any data (such as text or image) into digital features that can be used for machine learning
Note: eigenvalue is for the computer to better understand the data
- Feature extraction classification:
- Dictionary feature extraction (feature discretization)
- Text feature extraction
- Image feature extraction (depth learning will be introduced)
1.2 feature extraction API
sklearn.feature_extraction
2 dictionary feature extraction
Function: to characterize dictionary data
- sklearn.feature_extraction.DictVectorizer(sparse=True,...)
- DictVectorizer.fit_transform(X)
- 10: A dictionary or an iterator containing a dictionary returns a value
- Returns the spark matrix
- DictVectorizer.get_feature_names() returns the category name
- DictVectorizer.fit_transform(X)
2.1 application
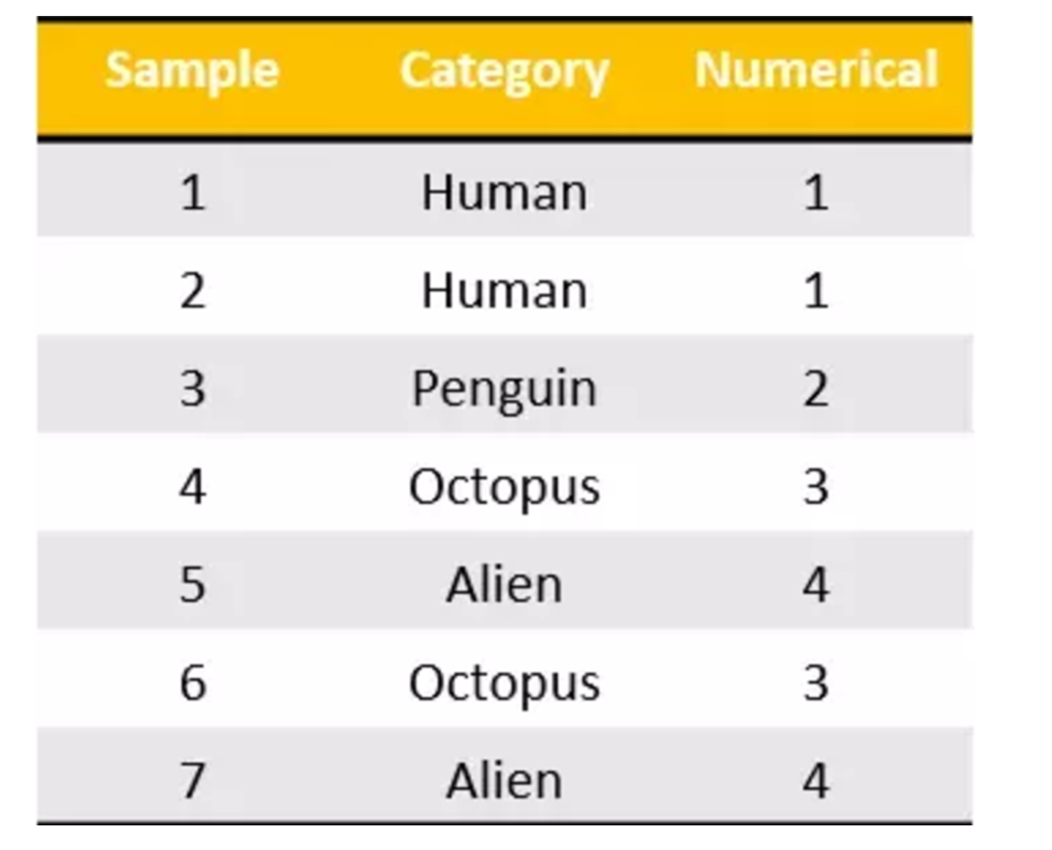
We perform feature extraction on the following data
[{'city': 'Beijing','temperature':100},
{'city': 'Shanghai','temperature':60},
{'city': 'Shenzhen','temperature':30}]
2.1 application
We perform feature extraction on the following data
[{'city': 'Beijing','temperature':100},
{'city': 'Shanghai','temperature':60},
{'city': 'Shenzhen','temperature':30}]
2.1 application
We perform feature extraction on the following data
[{'city': 'Beijing','temperature':100},
{'city': 'Shanghai','temperature':60},
{'city': 'Shenzhen','temperature':30}]

2.2 process analysis
- Instantiate class DictVectorizer
- Call fit_ The transform method inputs data and transforms it (pay attention to the return format)
from sklearn.feature_extraction import DictVectorizer def dict_demo(): """ Feature extraction of dictionary type data :return: None """ data = [{'city': 'Beijing','temperature':100}, {'city': 'Shanghai','temperature':60}, {'city': 'Shenzhen','temperature':30}] # 1,Instantiate a converter class transfer = DictVectorizer(sparse=False) # 2,call fit_transform data = transfer.fit_transform(data) print("Returned results:\n", data) # Print feature name print("Feature Name:\n", transfer.get_feature_names()) return None
Note that observe the result without adding the spark = false parameter
Returned results: (0, 1) 1.0 (0, 3) 100.0 (1, 0) 1.0 (1, 3) 60.0 (2, 2) 1.0 (2, 3) 30.0 Feature Name: ['city=Shanghai', 'city=Beijing', 'city=Shenzhen', 'temperature']
This result is not what we want to see, so add parameters to get the desired result:
Returned results: [[ 0. 1. 0. 100.] [ 1. 0. 0. 60.] [ 0. 0. 1. 30.]] Feature Name: ['city=Shanghai', 'city=Beijing', 'city=Shenzhen', 'temperature']
A similar effect was achieved when learning the discretization in pandas.
We call this data processing technique "one hot" coding:
Convert to:
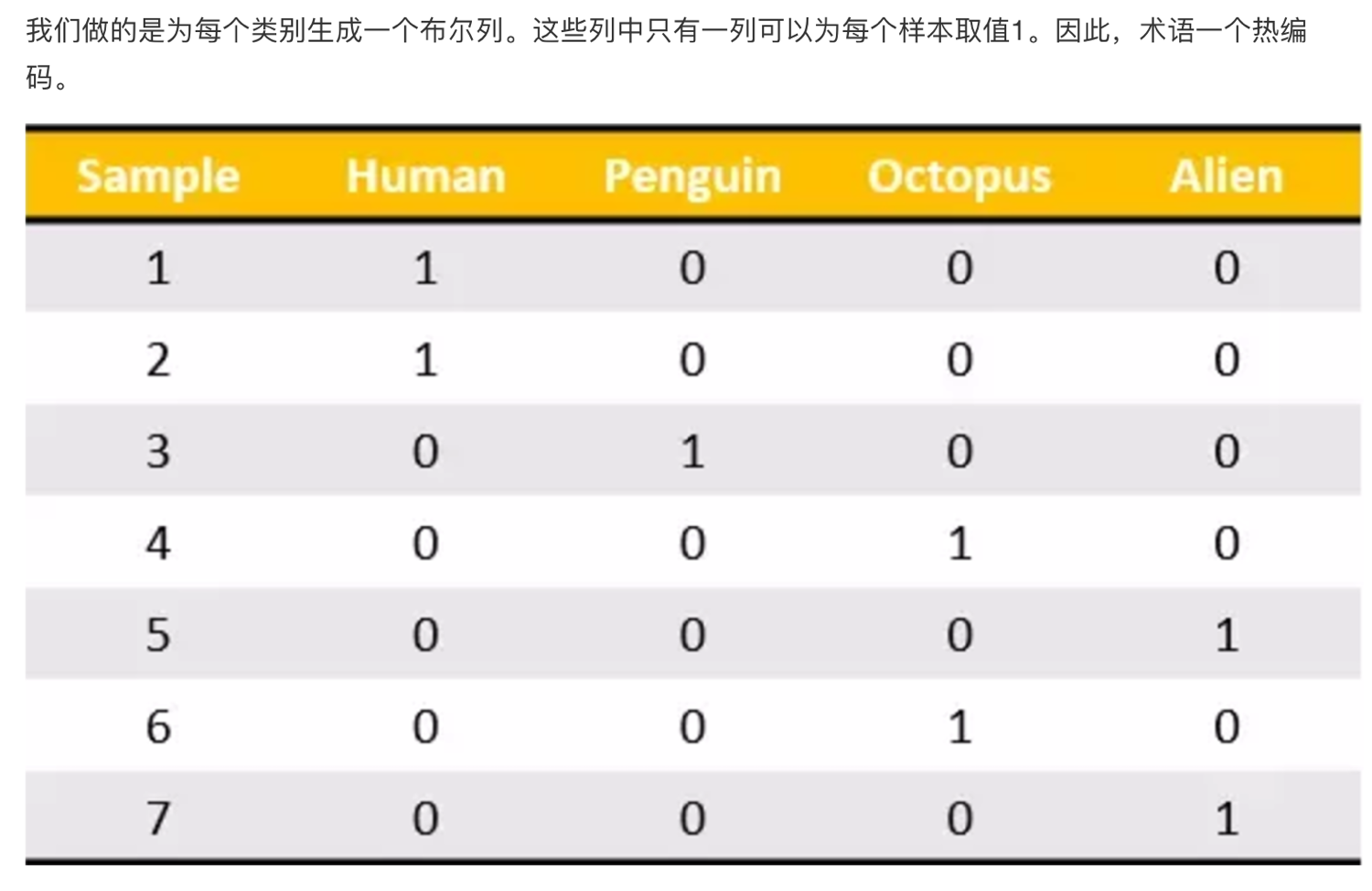
2.3 summary
If there is category information in the feature, we will do one hot coding
3 text feature extraction
Function: to characterize text data
-
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- Return word frequency matrix
- CountVectorizer.fit_transform(X)
- 10: Text or an iteratable object containing a text string
- Return value: returns the sparse matrix
- CountVectorizer.get_feature_names() return value: word list
-
sklearn.feature_extraction.text.TfidfVectorizer
3.1 application
We perform feature extraction on the following data
["life is short,i like python", "life is too long,i dislike python"]

3.2 process analysis
- Instantiate class CountVectorizer
- Call the fit_transform method to input data and convert it (pay attention to the return format, and use toarray() to convert the sparse matrix into array array)
from sklearn.feature_extraction.text import CountVectorizer def text_count_demo(): """ Feature extraction of text, countvetorizer :return: None """ data = ["life is short,i like like python", "life is too long,i dislike python"] # 1,Instantiate a converter class # transfer = CountVectorizer(sparse=False) # Note that there is no sparse parameter transfer = CountVectorizer() # 2,call fit_transform data = transfer.fit_transform(data) print("Results of text feature extraction:\n", data.toarray()) print("Return feature Name:\n", transfer.get_feature_names()) return None
Return result: Results of text feature extraction: [[0 1 1 2 0 1 1 0] [1 1 1 0 1 1 0 1]] Return feature Name: ['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too'] problem:If we replace the data with Chinese? "Life is short. I like it Python","Life is too long. I don't like it Python"
So the final result is
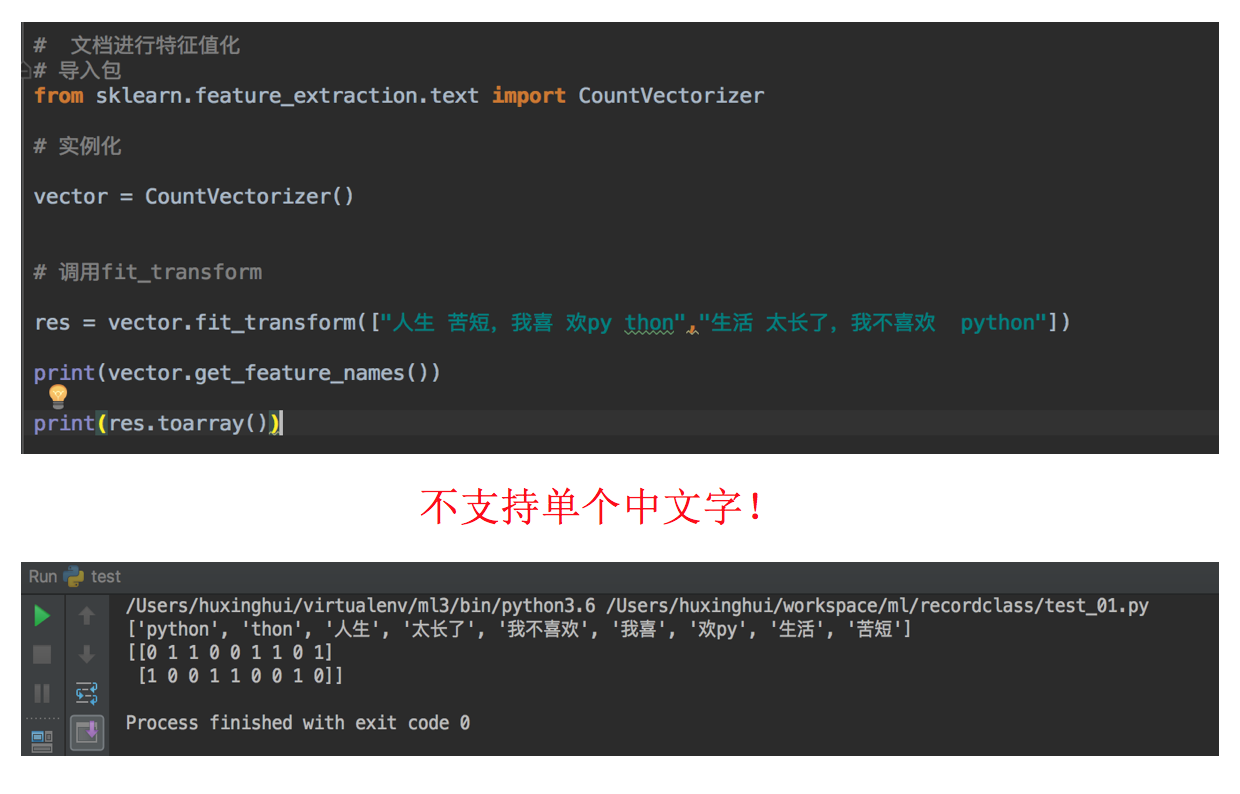
Why do you get such a result? After careful analysis, you will find that English is separated by spaces by default. In fact, it achieves the effect of word segmentation, so we need to deal with Chinese word segmentation
3.3 jieba word segmentation
- jieba.cut()
- Returns a generator of words
The jieba library needs to be installed
pip3 install jieba
3.4 case analysis
Eigenvalue the following three sentences
Today is cruel, tomorrow is more cruel, and the day after tomorrow is beautiful, But most of them will die tomorrow night, so don't give up today. The light we see from distant galaxies was emitted millions of years ago, So when we see the universe, we are looking at its past. If you only know something in one way, you won't really know it. The secret of understanding the true meaning of things depends on how to connect them with what we know.
- analysis
- Prepare sentences and use jieba.cut for word segmentation
- Instantiate CountVectorizer
- Turn the word segmentation result into a string as the input value of fit_transform

from sklearn.feature_extraction.text import CountVectorizer import jieba def cut_word(text): """ Chinese word segmentation "I Love Beijing Tiananmen "-->"I love Beijing Tiananmen Square" :param text: :return: text """ # Word segmentation of Chinese strings by stuttering text = " ".join(list(jieba.cut(text))) return text def text_chinese_count_demo2(): """ Feature extraction of Chinese :return: None """ data = ["One or another, today is cruel, tomorrow is more cruel, and the day after tomorrow is beautiful, but most of them die tomorrow night, so everyone should not give up today.", "The light we see from distant galaxies was emitted millions of years ago, so when we see the universe, we are looking at its past.", "If you only know something in one way, you won't really know it. The secret of understanding the true meaning of things depends on how to connect it with what we know."] # Convert raw data into good word form text_list = [] for sent in data: text_list.append(cut_word(sent)) print(text_list) # 1,Instantiate a converter class # transfer = CountVectorizer(sparse=False) transfer = CountVectorizer() # 2,call fit_transform data = transfer.fit_transform(text_list) print("Results of text feature extraction:\n", data.toarray()) print("Return feature Name:\n", transfer.get_feature_names()) return None
Return result:
Building prefix dict from the default dictionary ... Dumping model to file cache /var/folders/mz/tzf2l3sx4rgg6qpglfb035_r0000gn/T/jieba.cache Loading model cost 1.032 seconds. ['One or another, today is cruel, tomorrow is more cruel, and the day after tomorrow is beautiful, but most of them die tomorrow night, so everyone should not give up today.', 'The light we see from distant galaxies was emitted millions of years ago, so when we see the universe, we are looking at its past.', 'If you only know something in one way, you won't really know it. The secret of understanding the true meaning of things depends on how to connect it with what we know.'] Prefix dict has been built succesfully. Results of text feature extraction: [[2 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 1 0] [0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 0 1] [1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0 0]] Return feature Name: ['one kind', 'can't', 'No', 'before', 'understand', 'thing', 'today', 'Just in', 'Millions of years', 'issue', 'Depending on', 'only need', 'the day after tomorrow', 'meaning', 'gross', 'how', 'If', 'universe', 'We', 'therefore', 'give up', 'mode', 'tomorrow', 'Galaxy', 'night', 'Some kind', 'cruel', 'each', 'notice', 'real', 'secret', 'absolutely', 'fine', 'contact', 'past times', 'still', 'such']
But if such word features are used for classification, what problems will arise?
Look at the question:
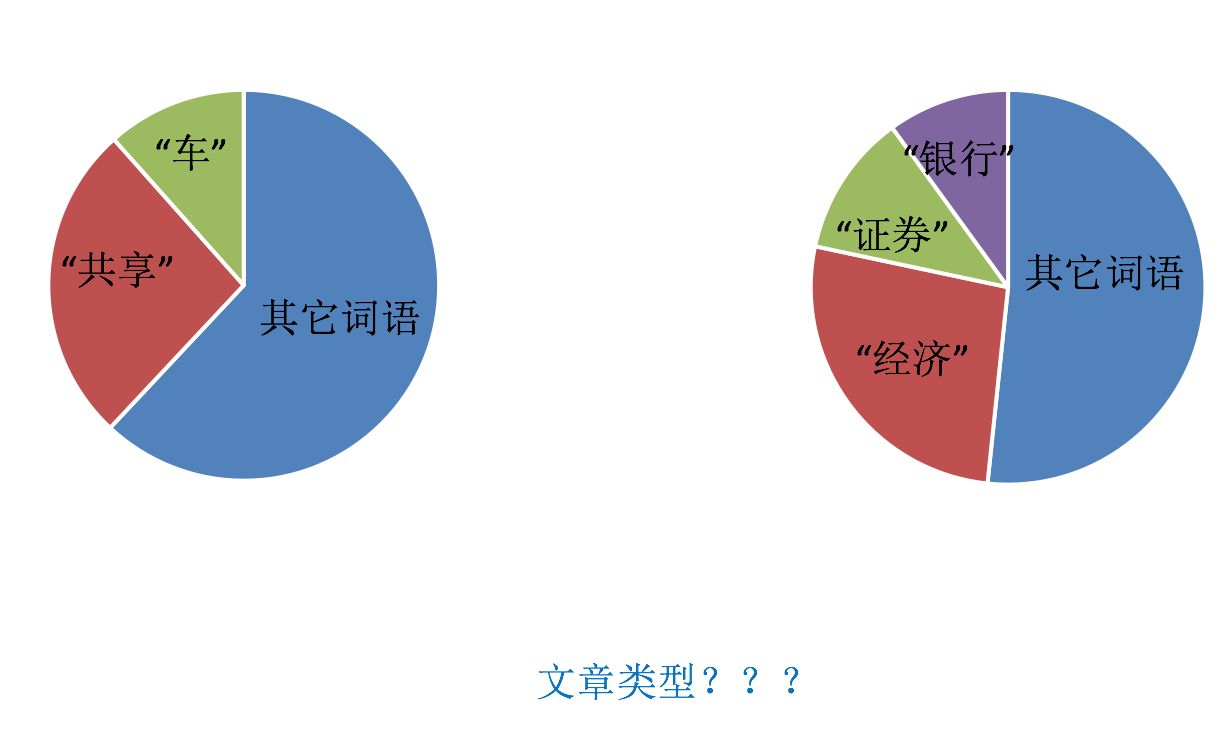
How to deal with the situation that a word or phrase appears more frequently in multiple articles
3.5 TF IDF text feature extraction
- The main idea of TF-IDF is that if a word or phrase has a high probability of appearing in one article and rarely appears in other articles, it is considered that this word or phrase has good classification ability and is suitable for classification.
- TF-IDF function: used to evaluate the importance of a word to a document set or one of the documents in a corpus.
3.5.1 formula
- term frequency (tf) refers to the frequency of a given word in the file
- inverse document frequency (idf) is a measure of the general importance of a word. The idf of a specific word can be obtained by dividing the total number of files by the number of files containing the word, and then taking the logarithm of the bottom 10 as the quotient
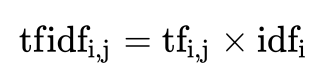
The final result can be understood as the degree of importance.
give an example: If the total number of words in an article is 100, and words"very"Five times, then"very"The word frequency in the file is 5/100=0.05. And calculate the file frequency( IDF)The method is to divide the total number of files in the file set by the number of files that appear"very"Number of files with the word. So, if"very"The word in 1,0000 Documents have appeared, and the total number of documents is 10,000,000 If you have a share, The reverse file frequency is lg(10,000,000 / 1,0000)=3. last"very"For this document tf-idf Your score is 0.05 * 3=0.15
3.5.2 cases
from sklearn.feature_extraction.text import TfidfVectorizer import jieba def cut_word(text): """ Chinese word segmentation "I Love Beijing Tiananmen "-->"I love Beijing Tiananmen Square" :param text: :return: text """ # Word segmentation of Chinese strings by stuttering text = " ".join(list(jieba.cut(text))) return text def text_chinese_tfidf_demo(): """ Feature extraction of Chinese :return: None """ data = ["One or another, today is cruel, tomorrow is more cruel, and the day after tomorrow is beautiful, but most of them die tomorrow night, so everyone should not give up today.", "The light we see from distant galaxies was emitted millions of years ago, so when we see the universe, we are looking at its past.", "If you only know something in one way, you won't really know it. The secret of understanding the true meaning of things depends on how to connect it with what we know."] # Convert raw data into good word form text_list = [] for sent in data: text_list.append(cut_word(sent)) print(text_list) # 1,Instantiate a converter class # transfer = CountVectorizer(sparse=False) transfer = TfidfVectorizer(stop_words=['one kind', 'can't', 'No']) # 2,call fit_transform data = transfer.fit_transform(text_list) print("Results of text feature extraction:\n", data.toarray()) print("Return feature Name:\n", transfer.get_feature_names()) return None
Return result:
Building prefix dict from the default dictionary ... Loading model from cache /var/folders/mz/tzf2l3sx4rgg6qpglfb035_r0000gn/T/jieba.cache Loading model cost 0.856 seconds. Prefix dict has been built succesfully. ['One or another, today is cruel, tomorrow is more cruel, and the day after tomorrow is beautiful, but most of them die tomorrow night, so everyone should not give up today.', 'The light we see from distant galaxies was emitted millions of years ago, so when we see the universe, we are looking at its past.', 'If you only know something in one way, you won't really know it. The secret of understanding the true meaning of things depends on how to connect it with what we know.'] Results of text feature extraction: [[ 0. 0. 0. 0.43643578 0. 0. 0. 0. 0. 0.21821789 0. 0.21821789 0. 0. 0. 0. 0.21821789 0.21821789 0. 0.43643578 0. 0.21821789 0. 0.43643578 0.21821789 0. 0. 0. 0.21821789 0.21821789 0. 0. 0.21821789 0. ] [ 0.2410822 0. 0. 0. 0.2410822 0.2410822 0.2410822 0. 0. 0. 0. 0. 0. 0. 0.2410822 0.55004769 0. 0. 0. 0. 0.2410822 0. 0. 0. 0. 0.48216441 0. 0. 0. 0. 0. 0.2410822 0. 0.2410822 ] [ 0. 0.644003 0.48300225 0. 0. 0. 0. 0.16100075 0.16100075 0. 0.16100075 0. 0.16100075 0.16100075 0. 0.12244522 0. 0. 0.16100075 0. 0. 0. 0.16100075 0. 0. 0. 0.3220015 0.16100075 0. 0. 0.16100075 0. 0. 0. ]] Return feature Name: ['before', 'understand', 'thing', 'today', 'Just in', 'Millions of years', 'issue', 'Depending on', 'only need', 'the day after tomorrow', 'meaning', 'gross', 'how', 'If', 'universe', 'We', 'therefore', 'give up', 'mode', 'tomorrow', 'Galaxy', 'night', 'Some kind', 'cruel', 'each', 'notice', 'real', 'secret', 'absolutely', 'fine', 'contact', 'past times', 'still', 'such']
3.6 importance of TF IDF
Classification machine learning algorithm for article classification in the early stage of data processing