Feature extraction without data enhancement
Code first.
import os import numpy as np from keras.preprocessing.image import ImageDataGenerator base_dir = '/Users/fchollet/Downloads/cats_and_dogs_small' train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') test_dir = os.path.join(base_dir, 'test') datagen = ImageDataGenerator(rescale=1./255) batch_size = 20
First, import the required module, create the required directory, and preliminarily set up the generator.
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
return features, labels
Now we construct a feature extraction function. The size of the first numpy array is: sample size * 4 * 4 * 512, corresponding to the size of the network output, then the label is naturally only one-dimensional array of sample size. Later, generators are used to package data in batches for easy processing. The generator determines the size of the picture, and then obtains the label of the picture and stores it in the array. The label here is the name of the folder. In this example, there are two folders, so 0 and 1. The processed image is in the form of data stream, which is equivalent to 20 pictures per batch forming a data stream, and the label is the root. According to the catalogue's automatic calculation, the order of pictures is disruptive. Specific things can be seen here:
https://blog.csdn.net/mieleizhi0522/article/details/82191331
In the later for loop, the processed data stream is input directly into the existing model and output the result. Then the result is stored in the feature array which is defined at the beginning, and the labels are stored in the labels array. In order to avoid infinite loops, a number of restrictions are added to ensure that all data is used without duplication.
train_features, train_labels = extract_features(train_dir, 2000) validation_features, v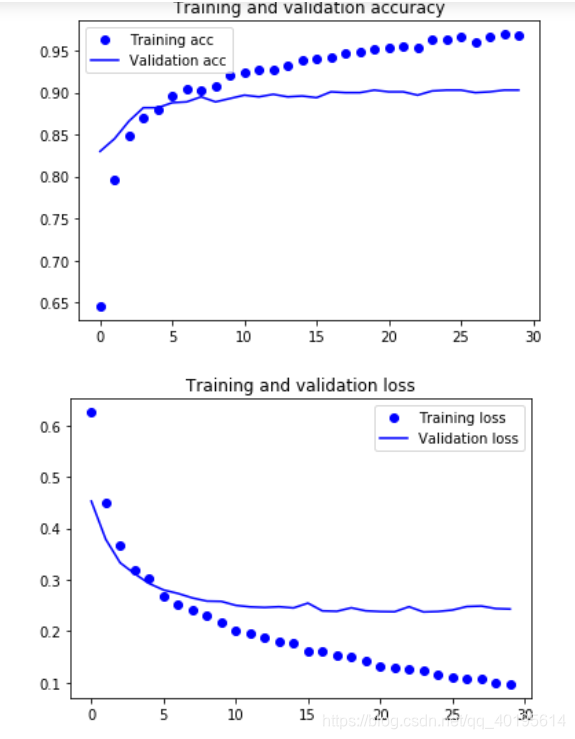alidation_labels = extract_features(validation_dir, 1000) test_features, test_labels = extract_features(test_dir, 1000)
Here is the training set, test set, verification set used this method once, equivalent to three sets from the network once, and keep their labels.
train_features = np.reshape(train_features, (2000, 4 * 4 * 512)) validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512)) test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
Next, the output results are removed from reshape, so that the data can be transformed into two-dimensional tensors for training on the basis of existing models.
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))
Here is a simple two-class training network, after all, we use the trained model, just need to output after classification. The drawing code has been pasted many times, but it is not pasted here.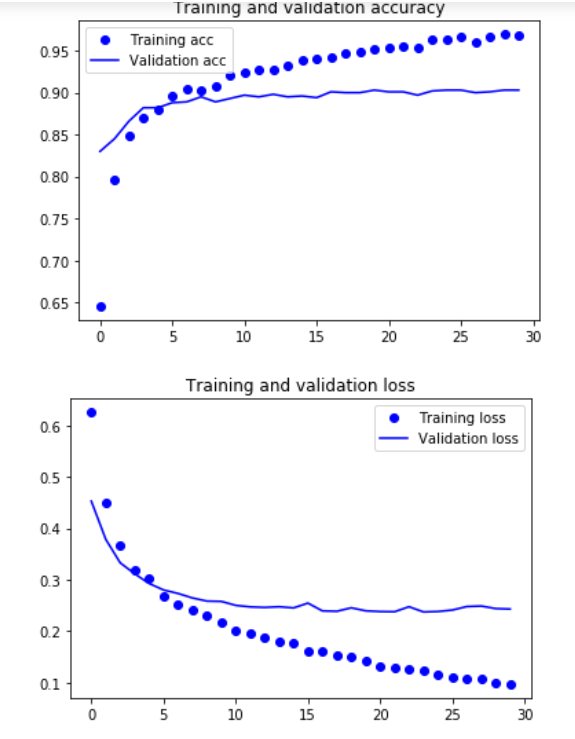
It can be seen that if the data enhancement method is not used, the training model can get high accuracy, but the problem of fitting from the beginning is very serious, obviously still need to use data enhancement.