1. Introduction
the name of googlenet is not googlenet, but googlenet. This is to pay tribute to LeNet. Googlenet and AlexNet/VGGNet, which rely on deepening the depth of the network structure, are not exactly the same. Googlenet makes structural innovation while adding depth, and introduces a structure called Inception to replace the previous convolution plus activation classic component. Googlenet's Top-5 error rate in the ImageNet classification competition was reduced to 6.7%.
1.1 Inception block
the basic convolution block in GoogLeNet is called the Inception block, which is complex in structure, as shown in the following figure:
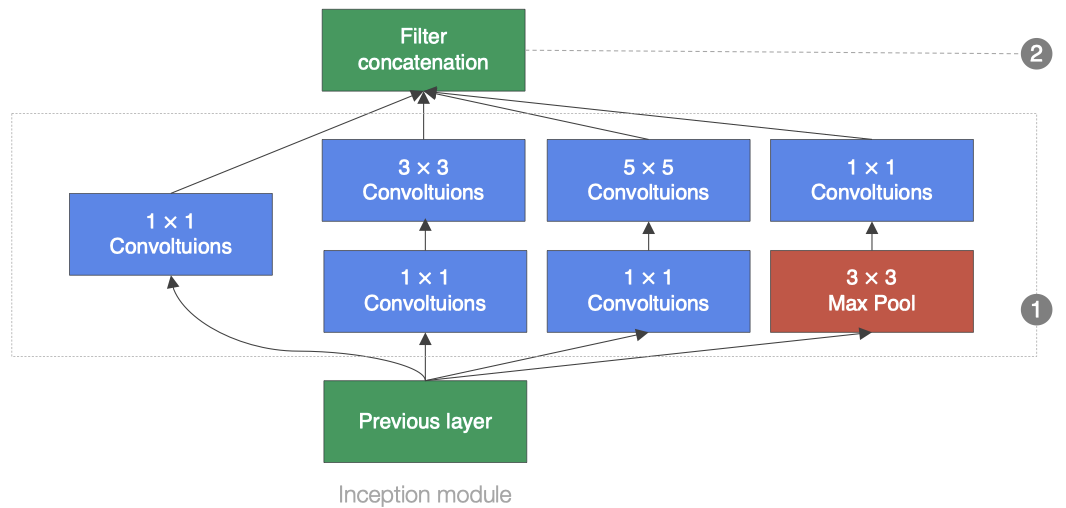
there are four parallel lines in the Inception block. The window size of the first three lines is 1 × 1,3 × 3 and 5 × 5 to extract information under different spatial sizes, in which the middle two lines will first do 1 to the input × 1 convolution to reduce the number of input channels to reduce the complexity of the model. For line 4, use 3 × 3 maximum pool layer, followed by 1 × 1 convolution layer to change the number of channels. All 4 lines use appropriate padding to make the input and output consistent in height and width. Finally, we connect the output of each line in the channel dimension and transmit it backward.
Code implementation:
class Inception(tf.keras.layers.Layer):
# Composition of setting module
def __init__(self,c1,c2,c3,c4):
super().__init__()
# Line 1:1*1 RELU same c1
self.p1_1 = tf.keras.layers.Conv2D(c1,kernel_size=1,activation="relu",padding ="same")
# Line 2:1*1 RELU same c2[0]
self.p2_1 = tf.keras.layers.Conv2D(c2[0],kernel_size=1,activation="relu",padding="same")
# Line 2:3*3 RELU same c2[1]
self.p2_2 = tf.keras.layers.Conv2D(c2[1],kernel_size=3,activation="relu",padding='same')
# Line 3:1*1 RELU same c3[0]
self.p3_1 = tf.keras.layers.Conv2D(c3[0],kernel_size=1,activation="relu",padding="same")
# Line 3:5*5 RELU same c3[1]
self.p3_2 = tf.keras.layers.Conv2D(c3[1],kernel_size=5,activation="relu",padding='same')
# Line 4: max pool
self.p4_1 = tf.keras.layers.MaxPool2D(pool_size=3,padding="same",strides=1)
# Line 4:1 * 1
self.p4_2 = tf.keras.layers.Conv2D(c4,kernel_size=1,activation="relu",padding="same")
# Forward propagation process
def call(self,x):
# Line 1
p1 = self.p1_1(x)
# Line 2
p2 = self.p2_2(self.p2_1(x))
# Line 3
p3 = self.p3_2(self.p3_1(x))
# Line 4
p4 = self.p4_2(self.p4_1(x))
# concat
outputs = tf.concat([p1,p2,p3,p4],axis=-1)
return outputs
1.2 1 * 1 convolution
its calculation method is the same as other convolution kernels, except that its size is 1 × 1. The relationship between local information in the feature map is not considered.

Its main functions are:
- Realize cross channel interaction and information integration
- The number of convolution kernel channels is reduced and dimensioned, and the network parameters are reduced
Take inception module as an example to illustrate how 1x1 convolution can reduce model parameters:
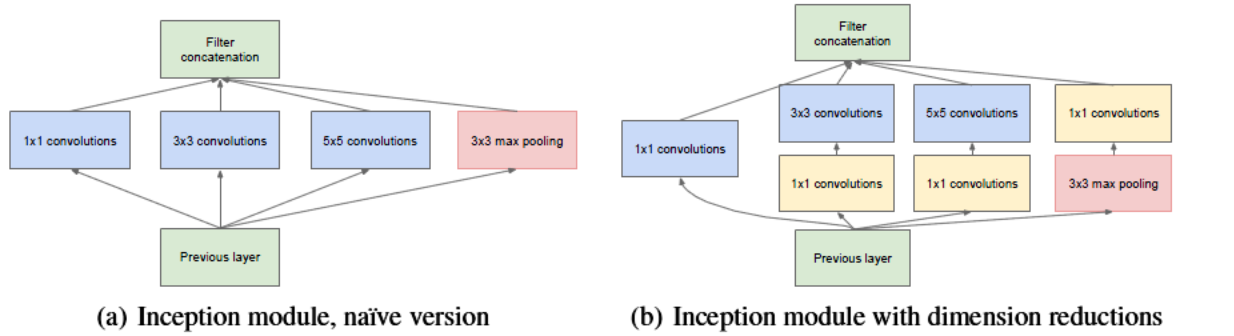
(a) Is the inception module without 1x1 convolution, (b) is the inception module with 1x1 convolution.
We take 3x3 convolution line as an example, assuming that the size of the input characteristic graph is (28x28x192) and the number of channels of the output characteristic graph is 128:
(a) The parameter quantity of the line in the figure is 3x3x192x128 = 221184
(b) After adding 1x1 convolution in the figure, the channel is 96, and the parameter quantity sent into 3x3 convolution is: (1x1x192x96)+(3x3x96x128)=129024
The comparison shows that the amount of parameters is reduced after 1x1 convolution.
2.GoogLeNet model
GoogLeNet is mainly composed of Inception module, as shown in the figure below:
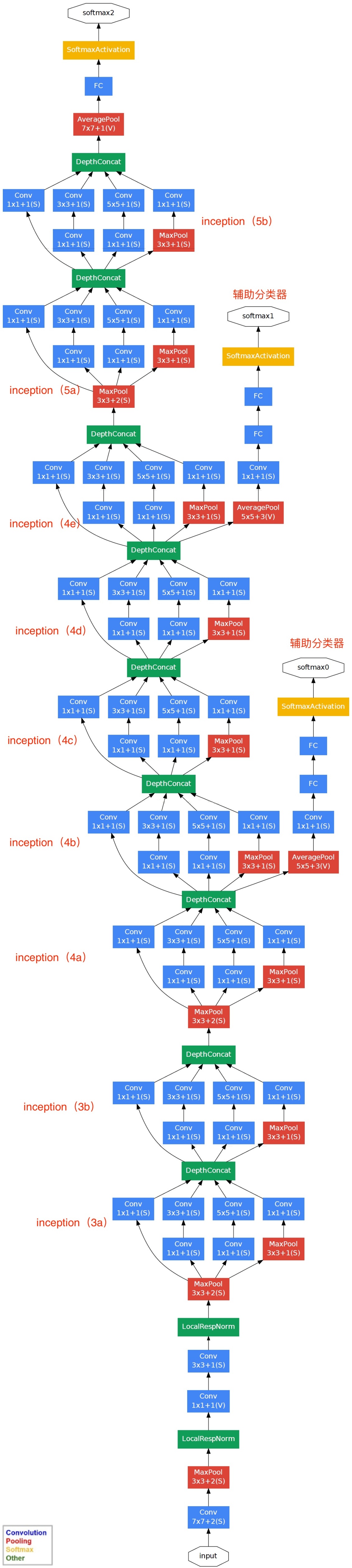
- Note: the LocalRespNorm module has been discontinued in V2, V3 and V4, which does not affect the accuracy of the model
the whole network architecture is divided into five modules, and each module uses 3 with a step of 2 × 3. Maximize the pool layer to reduce the output height and width.
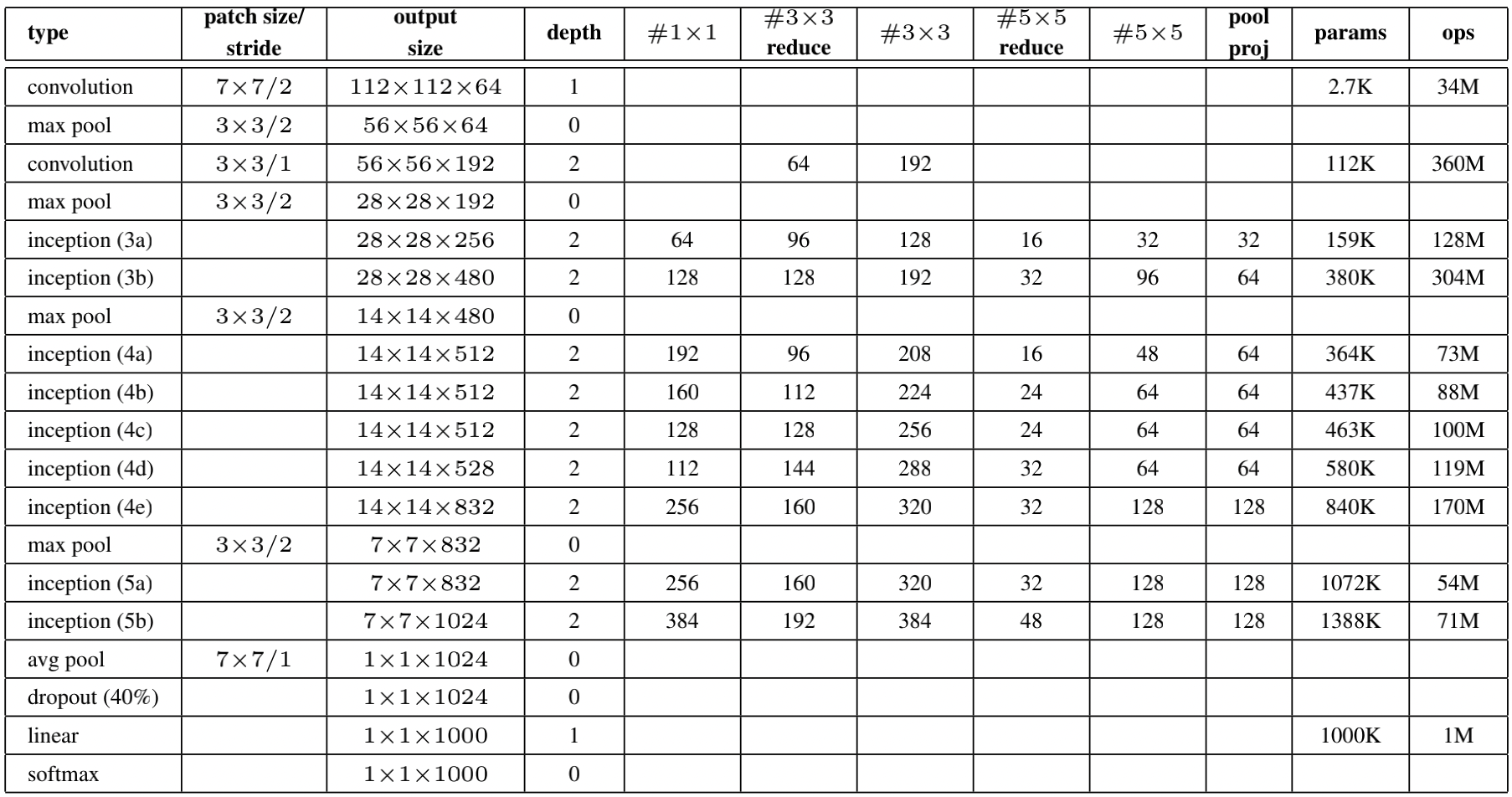
the network design of Google net is shown in the following table:
3 code implementation
3.1 B1 module
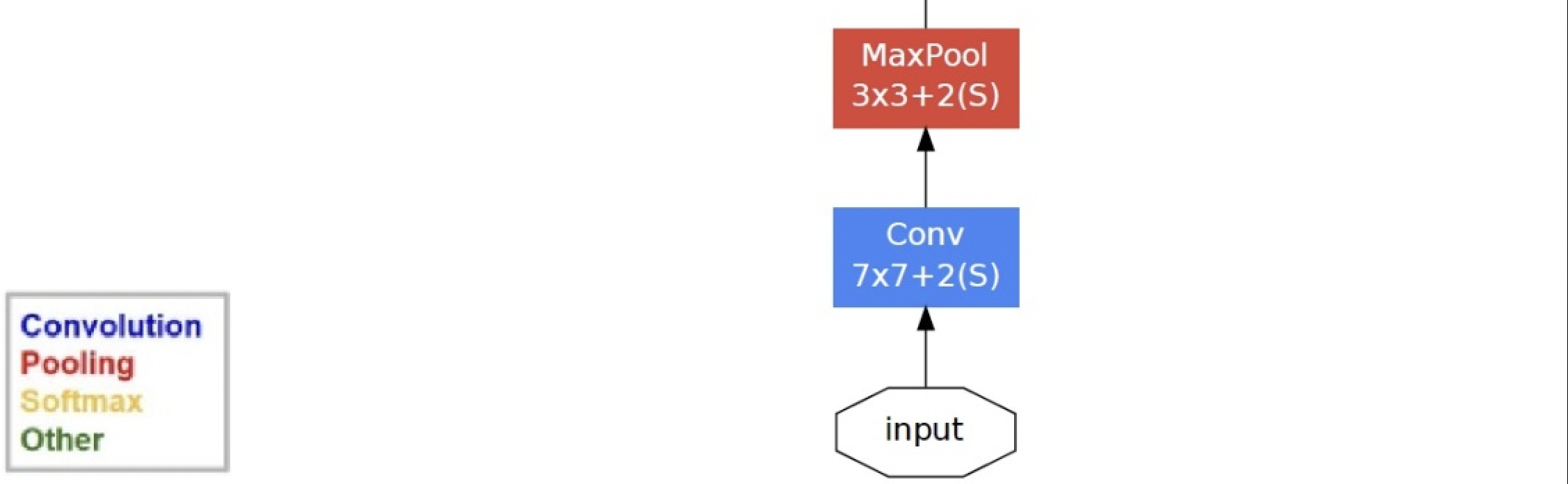
The first mock exam uses a 64 channel 7. × 7. Convolution.
inputs = tf.keras.Input(shape=(224,224,1),name="input") # Convolution: 7 * 7 64 x = tf.keras.layers.Conv2D(64,kernel_size=7,strides = 2,padding="same",activation="relu")(inputs) # Pool layer x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding="same")(x)
3.2 B2 module
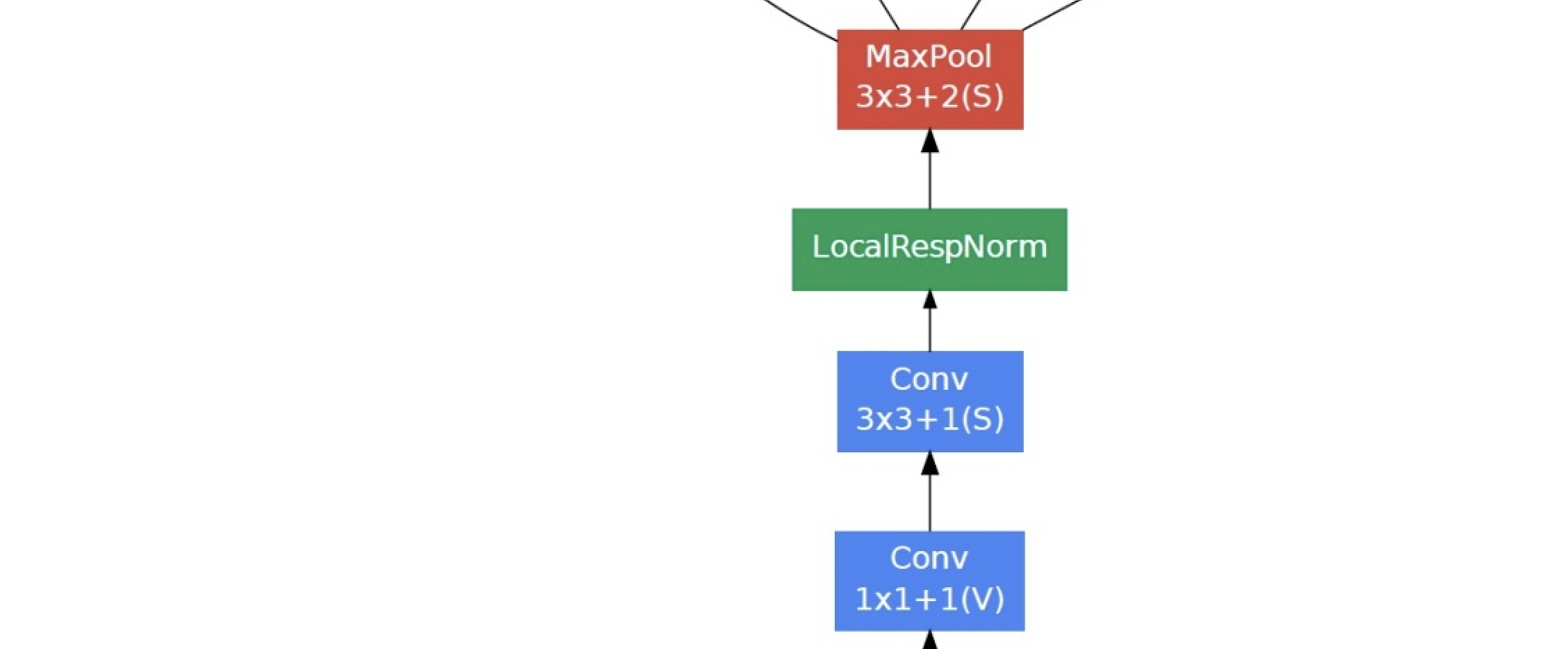
The second module uses 2 Volume layers: first, 64 channel 1. × 1 convolution, followed by a 3-fold increase in the channel × 3. Convolution.
# Convolution layer: 1 * 1 x = tf.keras.layers.Conv2D(64,kernel_size = 1,padding='same',activation="relu")(x) # Convolution: 3 * 3 x = tf.keras.layers.Conv2D(192,kernel_size=3,padding='same',activation='relu')(x) # Pool layer x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding="same")(x)
3.3 B3 module
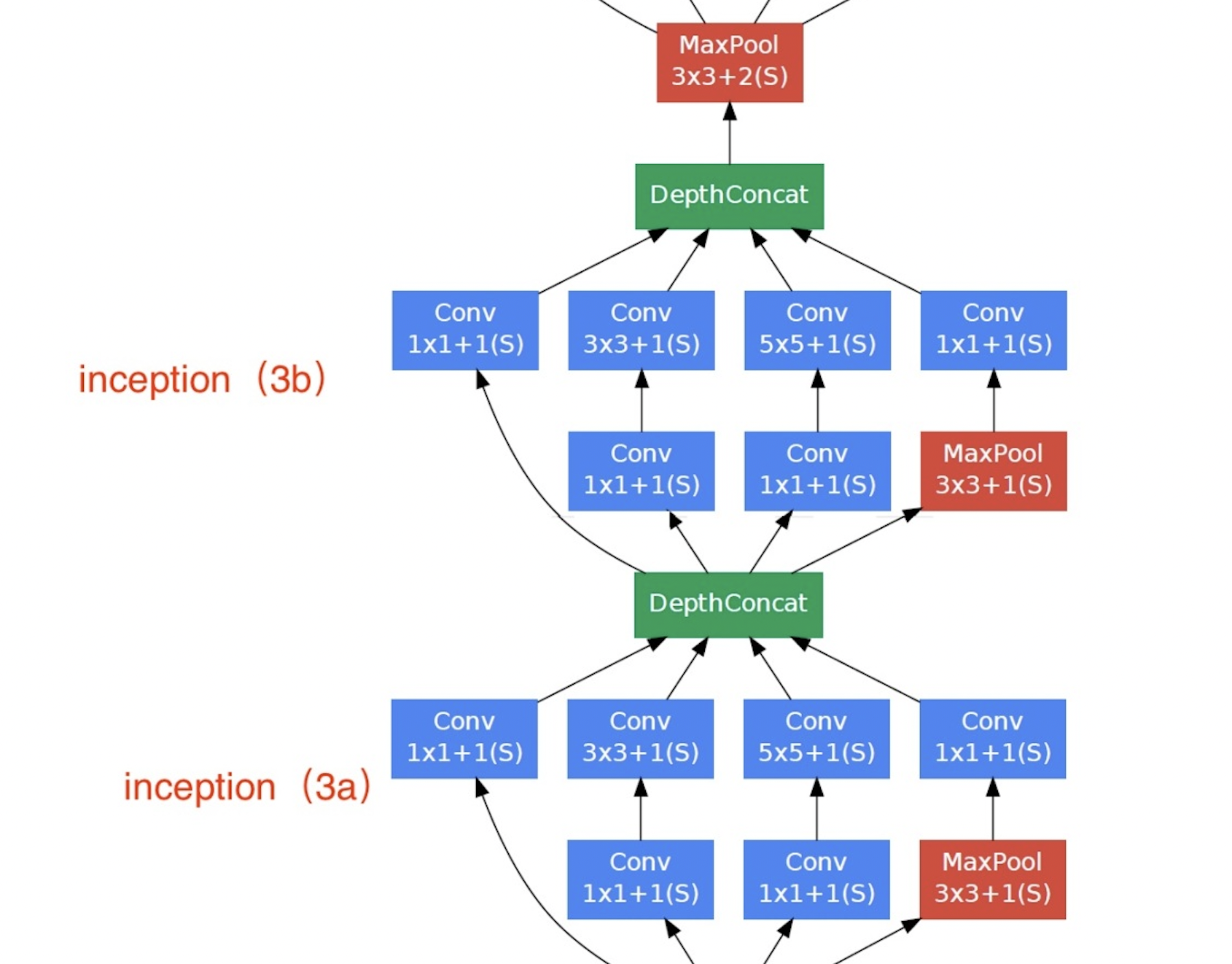
The third modules are connected in series with 2 complete Inception blocks. The number of output channels of the first inception block is 64 + 128 + 32 + 32=
256. The number of output channels of the second Inception block increases to 128 + 192 + 96 + 64 = 480.
# inception x = Inception(64,(96,128),(16,32),32)(x) # inception x = Inception(128,(128,192),(32,96),64)(x) # Pooling x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding="same")(x)
3.4 B4 module
the fourth module is more complex. It has five Inception blocks in series, and the number of output channels are 192 + 208 + 48 + 64 = 512, 160 + 224 + 64 + 64 = 512, 128 + 256 + 64 + 64 = 512, 112 + 288 + 64 + 64 = 528 and 256 + 320 + 128 + 128 = 832 respectively. In addition, an auxiliary classifier is added. According to the experiment, it is found that the middle layer of the network has strong recognition ability. In order to make use of the abstract characteristics of the middle layer, multi-layer classifiers are added to some middle layers, as shown in the figure below:
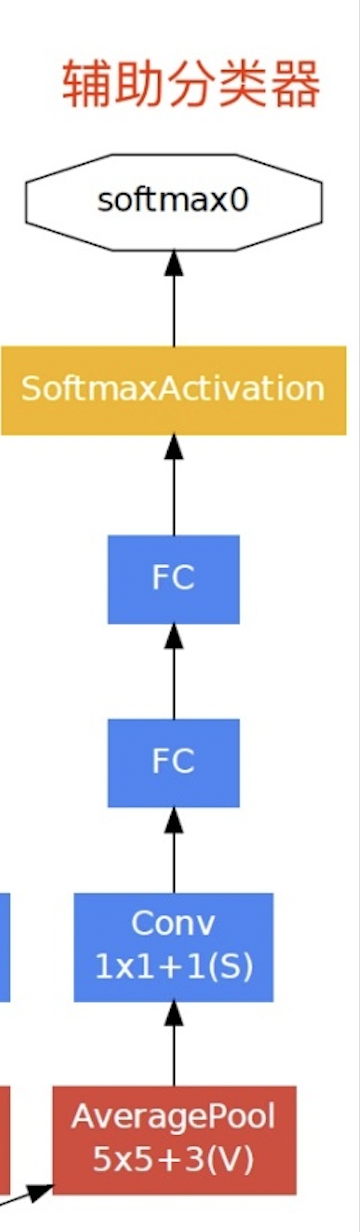
Classifier code implementation:
# Auxiliary classifier
def aux_classifier(x,filter_size):
# Pool layer
x = tf.keras.layers.AveragePooling2D(pool_size=5,strides = 3,padding='same')(x)
# Convolution layer
x = tf.keras.layers.Conv2D(filters = filter_size[0],kernel_size=1,strides=1,padding ="valid",activation="relu")(x)
# Exhibition evaluation
x = tf.keras.layers.Flatten()(x)
# Full connection
x = tf.keras.layers.Dense(units = filter_size[1],activation="relu")(x)
# Output layer:
x = tf.keras.layers.Dense(units=10,activation="softmax")(x)
return x
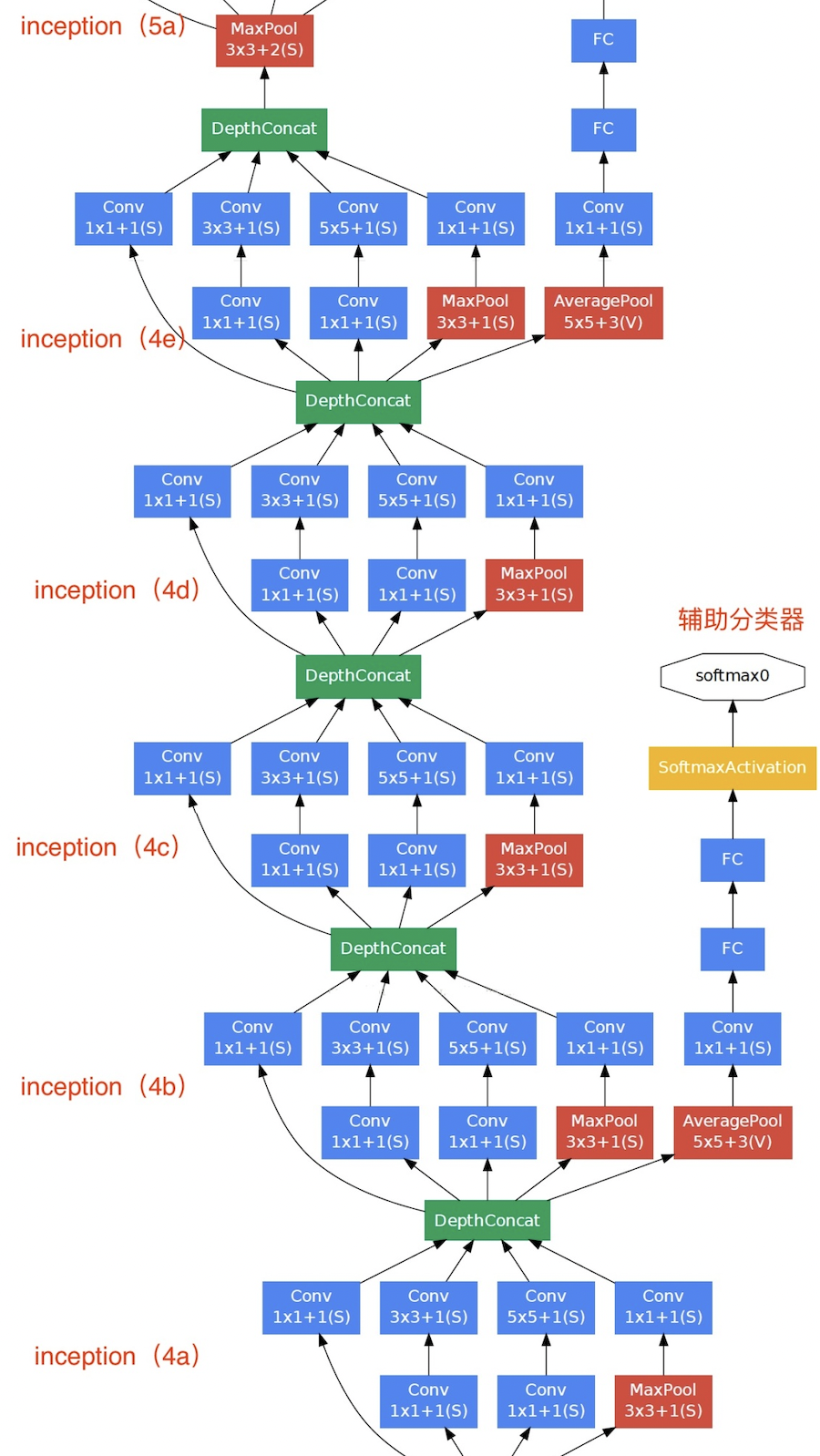
B4 module code implementation:
# Inception x = Inception(192,(96,208),(16,48),64)(x) # Auxiliary classifier 1 aux_output1 = aux_classifier(x,[128,1024]) # Inception x = Inception(160,(112,224),(24,64),64)(x) # Inception x = Inception(128,(128,256),(24,64),64)(x) # Inception x = Inception(112,(144,288),(32,64),64)(x) # Auxiliary classifier 1 aux_output2 = aux_classifier(x,[128,1024]) # Inception x =Inception(256,(160,320),(32,128),128)(x) # Maximum pooling x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding='same')(x)
3.5 B5 module
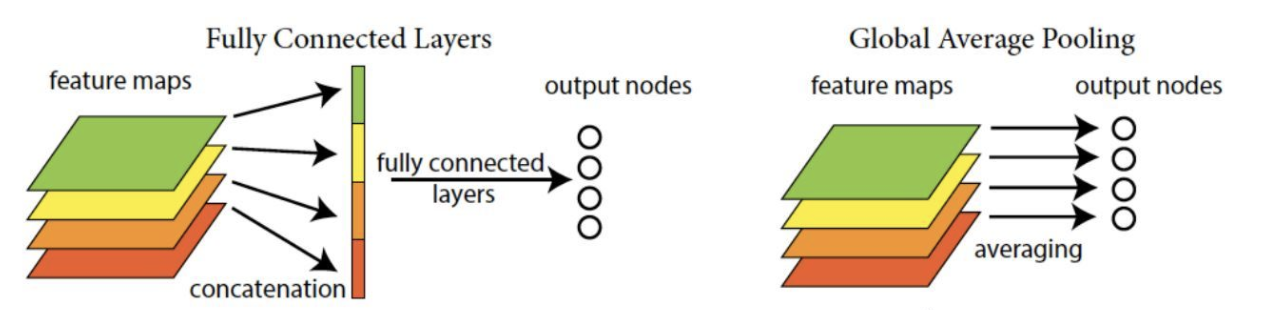
the fifth module has two Inception blocks with output channels of 256 + 320 + 128 + 128 = 832 and 384 + 384 + 128 + 128 = 1024. Followed by the output layer, the module uses the global average pooling layer (GAP) to change the height and width of each channel to 1. Finally, the output becomes a two-dimensional array, followed by the full connection layer whose output number is the number of label categories.
Global average pooling layer (GAP)
It is used to replace the Flatten in front of the full connection layer. After adding all pixel values in each channel of the characteristic map and averaging, the result is the result of GAP, which is sent to the subsequent network for calculation
# inception x = Inception(256,(160,320),(32,128),128)(x) x = Inception(384,(192,384),(48,128),128)(x) # GAP x = tf.keras.layers.GlobalAvgPool2D()(x) # Output layer output = tf.keras.layers.Dense(10,activation="softmax")(x)
All codes are as follows:
# inception module
class Inception(tf.keras.layers.Layer):
# Composition of setting module
def __init__(self,c1,c2,c3,c4):
super().__init__()
# Line 1:1*1 RELU same c1
self.p1_1 = tf.keras.layers.Conv2D(c1,kernel_size=1,activation="relu",padding ="same")
# Line 2:1*1 RELU same c2[0]
self.p2_1 = tf.keras.layers.Conv2D(c2[0],kernel_size=1,activation="relu",padding="same")
# Line 2:3*3 RELU same c2[1]
self.p2_2 = tf.keras.layers.Conv2D(c2[1],kernel_size=3,activation="relu",padding='same')
# Line 3:1*1 RELU same c3[0]
self.p3_1 = tf.keras.layers.Conv2D(c3[0],kernel_size=1,activation="relu",padding="same")
# Line 3:5*5 RELU same c3[1]
self.p3_2 = tf.keras.layers.Conv2D(c3[1],kernel_size=5,activation="relu",padding='same')
# Line 4: max pool
self.p4_1 = tf.keras.layers.MaxPool2D(pool_size=3,padding="same",strides=1)
# Line 4:1 * 1
self.p4_2 = tf.keras.layers.Conv2D(c4,kernel_size=1,activation="relu",padding="same")
# Forward propagation process
def call(self,x):
# Line 1
p1 = self.p1_1(x)
# Line 2
p2 = self.p2_2(self.p2_1(x))
# Line 3
p3 = self.p3_2(self.p3_1(x))
# Line 4
p4 = self.p4_2(self.p4_1(x))
# concat
outputs = tf.concat([p1,p2,p3,p4],axis=-1)
return outputs
# B1 module
inputs = tf.keras.Input(shape=(224,224,1),name="input")
# Convolution: 7 * 7 64
x = tf.keras.layers.Conv2D(64,kernel_size=7,strides = 2,padding="same",activation="relu")(inputs)
# Pool layer
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding="same")(x)
# B2 module
# Convolution layer: 1 * 1
x = tf.keras.layers.Conv2D(64,kernel_size = 1,padding='same',activation="relu")(x)
# Convolution: 3 * 3
x = tf.keras.layers.Conv2D(192,kernel_size=3,padding='same',activation='relu')(x)
# Pool layer
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding="same")(x)
# B3 module
# inception
x = Inception(64,(96,128),(16,32),32)(x)
# inception
x = Inception(128,(128,192),(32,96),64)(x)
# Pooling
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding="same")(x)
# B4 module
# Auxiliary classifier
def aux_classifier(x,filter_size):
# Pool layer
x = tf.keras.layers.AveragePooling2D(pool_size=5,strides = 3,padding='same')(x)
# Convolution layer
x = tf.keras.layers.Conv2D(filters = filter_size[0],kernel_size=1,strides=1,padding ="valid",activation="relu")(x)
# Exhibition evaluation
x = tf.keras.layers.Flatten()(x)
# Full connection
x = tf.keras.layers.Dense(units = filter_size[1],activation="relu")(x)
# Output layer:
x = tf.keras.layers.Dense(units=10,activation="softmax")(x)
return x
# Inception
x = Inception(192,(96,208),(16,48),64)(x)
# Auxiliary output
aux_output1 = aux_classifier(x,[128,1024])
# Inception
x = Inception(160,(112,224),(24,64),64)(x)
# Inception
x = Inception(128,(128,256),(24,64),64)(x)
# Inception
x = Inception(112,(144,288),(32,64),64)(x)
# Auxiliary output 2
aux_output2 = aux_classifier(x,[128,1024])
# Inception
x =Inception(256,(160,320),(32,128),128)(x)
# Maximum pooling
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding='same')(x)
# B5 module
# inception
x = Inception(256,(160,320),(32,128),128)(x)
x = Inception(384,(192,384),(48,128),128)(x)
# GAP
x = tf.keras.layers.GlobalAvgPool2D()(x)
# Output layer
output = tf.keras.layers.Dense(10,activation="softmax")(x)
# model building
model = tf.keras.Model(inputs=inputs,outputs=[output,aux_output1,aux_output2])
# View model structure
model.summary()
Output results:
Model: "model" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input (InputLayer) [(None, 224, 224, 1) 0 __________________________________________________________________________________________________ conv2d_6 (Conv2D) (None, 112, 112, 64) 3200 input[0][0] __________________________________________________________________________________________________ max_pooling2d_1 (MaxPooling2D) (None, 56, 56, 64) 0 conv2d_6[0][0] __________________________________________________________________________________________________ conv2d_7 (Conv2D) (None, 56, 56, 64) 4160 max_pooling2d_1[0][0] __________________________________________________________________________________________________ conv2d_8 (Conv2D) (None, 56, 56, 192) 110784 conv2d_7[0][0] __________________________________________________________________________________________________ max_pooling2d_2 (MaxPooling2D) (None, 28, 28, 192) 0 conv2d_8[0][0] __________________________________________________________________________________________________ inception_1 (Inception) (None, 28, 28, 256) 163696 max_pooling2d_2[0][0] __________________________________________________________________________________________________ inception_2 (Inception) (None, 28, 28, 480) 388736 inception_1[0][0] __________________________________________________________________________________________________ max_pooling2d_5 (MaxPooling2D) (None, 14, 14, 480) 0 inception_2[0][0] __________________________________________________________________________________________________ inception_3 (Inception) (None, 14, 14, 512) 376176 max_pooling2d_5[0][0] __________________________________________________________________________________________________ inception_4 (Inception) (None, 14, 14, 512) 449160 inception_3[0][0] __________________________________________________________________________________________________ inception_5 (Inception) (None, 14, 14, 512) 510104 inception_4[0][0] __________________________________________________________________________________________________ inception_6 (Inception) (None, 14, 14, 528) 605376 inception_5[0][0] __________________________________________________________________________________________________ inception_7 (Inception) (None, 14, 14, 832) 868352 inception_6[0][0] __________________________________________________________________________________________________ max_pooling2d_11 (MaxPooling2D) (None, 7, 7, 832) 0 inception_7[0][0] __________________________________________________________________________________________________ average_pooling2d (AveragePooli (None, 5, 5, 512) 0 inception_3[0][0] __________________________________________________________________________________________________ average_pooling2d_1 (AveragePoo (None, 5, 5, 528) 0 inception_6[0][0] __________________________________________________________________________________________________ inception_8 (Inception) (None, 7, 7, 832) 1043456 max_pooling2d_11[0][0] __________________________________________________________________________________________________ conv2d_27 (Conv2D) (None, 5, 5, 128) 65664 average_pooling2d[0][0] __________________________________________________________________________________________________ conv2d_46 (Conv2D) (None, 5, 5, 128) 67712 average_pooling2d_1[0][0] __________________________________________________________________________________________________ inception_9 (Inception) (None, 7, 7, 1024) 1444080 inception_8[0][0] __________________________________________________________________________________________________ flatten (Flatten) (None, 3200) 0 conv2d_27[0][0] __________________________________________________________________________________________________ flatten_1 (Flatten) (None, 3200) 0 conv2d_46[0][0] __________________________________________________________________________________________________ global_average_pooling2d (Globa (None, 1024) 0 inception_9[0][0] __________________________________________________________________________________________________ dense (Dense) (None, 1024) 3277824 flatten[0][0] __________________________________________________________________________________________________ dense_2 (Dense) (None, 1024) 3277824 flatten_1[0][0] __________________________________________________________________________________________________ dense_4 (Dense) (None, 10) 10250 global_average_pooling2d[0][0] __________________________________________________________________________________________________ dense_1 (Dense) (None, 10) 10250 dense[0][0] __________________________________________________________________________________________________ dense_3 (Dense) (None, 10) 10250 dense_2[0][0] ================================================================================================== Total params: 12,687,054 Trainable params: 12,687,054 Non-trainable params: 0 __________________________________________________________________________________________________