The network depth of VGG series is improved compared with its previous networks. VGG16 and VGG19 are the representatives of VGG series. This time, VGG16 network is realized based on tensorflow 2.0.
1. Introduction to vgg16 network
VGG16 network model stood out in the 2014 ImageNet competition, ranking second in classification tasks and first in positioning tasks. Compared with the previous LexNet and LeNet networks, VGG16 network reached an unprecedented level in the number of network layers at that time.
2. Network structure
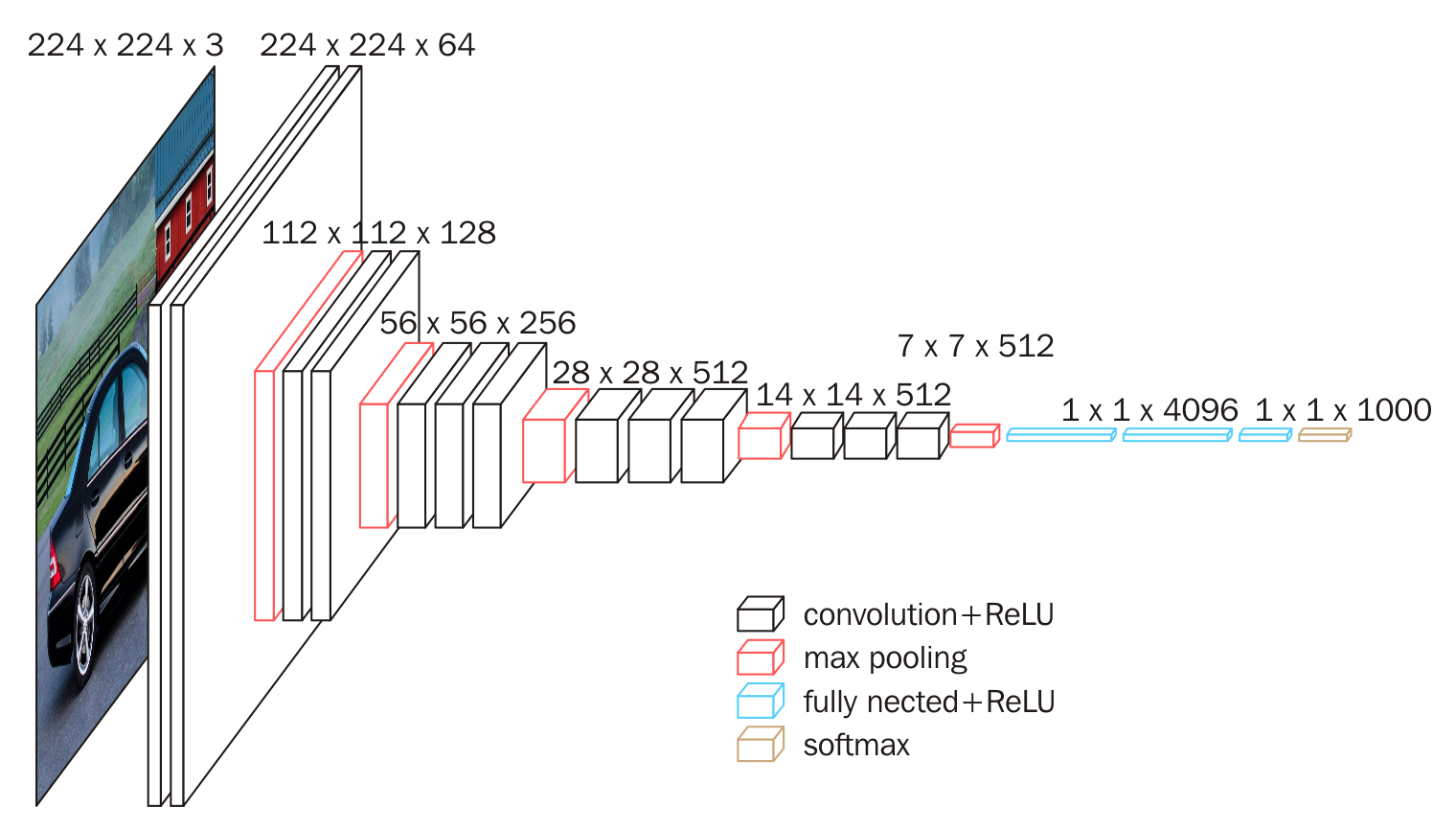
3. Innovation
① Use 3x3 convolution kernel instead of 7x7 convolution kernel.
3x3 convolution kernel is the smallest receptive field size that can feel the focus of up, down, left and right. Moreover, when two 3x3 convolution kernels are superimposed, their receptive fields are equivalent to one 5x5 convolution kernel. After three convolution kernels are superimposed, their receptive fields are equivalent to one 7x7 effect.
Because the receptive fields are the same, three 3x3 convolutions use three nonlinear activation functions, which increases the nonlinear expression ability and makes the segmentation plane more separable. At the same time, small convolution kernel is used to greatly reduce the amount of parameters.
The use of 3x3 convolution kernel stack not only increases the number of network layers, but also reduces the amount of parameters.
② By increasing the number of channels to reach a deeper network, 2x2 pooled core and Max pooling method are used.
Using 2x2 pooled cores, small pooled cores can bring more detailed information capture. At that time, there was also average pooling, but the effect of max pooling was better in the image task. max was easier to capture the changes in the image, resulting in greater local information difference and better description of edge texture.
4. Network implementation
def VGG16(nb_class,input_shape):
input_ten = Input(shape=input_shape)
#1
x = tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same')(input_ten)
x = tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)
#2
x = tf.keras.layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)
#3
x = tf.keras.layers.Conv2D(filters=256,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.Conv2D(filters=256,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.Conv2D(filters=256,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)
#4
x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)
#5
x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)
x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)
#FC
x = tf.keras.layers.Flatten()(x)
x = Dense(4096,activation='relu')(x)
x = Dense(4096,activation='relu')(x)
output_ten = Dense(nb_class,activation='softmax')(x)
model = Model(input_ten,output_ten)
return model
model_VGG16 = VGG16(24,(img_height,img_width,3))
model_VGG16.summary()
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv2d_1 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2d_3 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 56, 56, 128) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv2d_5 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv2d_6 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 28, 28, 256) 0 _________________________________________________________________ conv2d_7 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv2d_8 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv2d_9 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 14, 14, 512) 0 _________________________________________________________________ conv2d_10 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv2d_11 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv2d_12 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ dense (Dense) (None, 4096) 102764544 _________________________________________________________________ dense_1 (Dense) (None, 4096) 16781312 _________________________________________________________________ dense_2 (Dense) (None, 24) 98328 ================================================================= Total params: 134,358,872 Trainable params: 134,358,872 Non-trainable params: 0 _________________________________________________________________
It can be found that the training parameters of VGG16 have reached 134358872, many times more than that of AlexNet, but the network performance of VGG series is still relatively good.
Come on a