Pre knowledge #
==The difference between and equals #
For basic type variables, you can only use = =, because basic type variables have no methods. Use = = value comparison
For variables of reference type, whether the addresses of the two reference objects compared by = = are equal. All classes inherit from the object class, and the object class uses the equals method to compare whether the addresses of the objects are equal. If the class does not override the equals method, using = = has the same effect as using the equals method
Why rewrite equals and HashCode #
HashCode method: the bottom layer is written in C language and converted to integer type according to the object address
If the hashcodes of two objects are equal, the contents of the objects are not necessarily equal; hash collision problem
If you use the equals method to compare two objects with the same content value, the hashcode value is also equal
Because equals by default, the Object class uses = = to compare objects. The comparison is whether the memory addresses are equal. As long as the data type is not a basic type, the comparison will never be equal.
The set set stores non duplicate objects, and the bottom layer is hashmap, which is judged according to equals and hashcode
Time complexity #
The time complexity is O(n) query from the beginning to the end and query multiple times
The time complexity is O(1) query once, such as according to the array subscript
Queries with time complexity of O(logn) square, such as red black trees,
Efficiency: O (1) > O (logn) > O (n)
(move right without symbol) > > > #
Unsigned right shift means that after the right shift, no matter whether the number is positive or negative, the left is supplemented by 0 after the right shift
The main difference between the unsigned right shift operator and the right shift operator is the calculation of negative numbers, because the unsigned right shift is the high complement of 0, and how many bits are shifted complement how many zeros
15> > > 2 = 0000 1111 shift right two bits = 0000 0011 = 3
^XOR operation #
The same is 0, the difference is 1
2^3= 0010^0011=0001=1
&(and operation) #
00 0 11 1 01 0
2&3=0010&0011=0010=2
Displacement operation: 1 < < 2 = 4, why does 1 shift left two bits equal to 4 #
1 here is decimal, and computer communication is binary, so 1 should be expressed in binary first.
Each symbol (English, number or symbol, etc.) will occupy 1Bytes of records, and each Chinese symbol will occupy 2Byte
A 1Bytes occupies 8 bits, that is, 8 binary bits
8-bit binary number: 28 different states 0000 ~ 1111 1111 = 0 ~ 255 = 28 = 256
The binary representation of 1 is 0000 0001, and then the displacement operation is performed.
The displacement operation shifts to the left, and 0 is added to the empty space behind. The more to the left, the larger. The 0000 0001 is shifted to the left by 2 bits, which becomes 0000 0100. The binary 0000 0100 is converted to decimal, so it is 4. It can also be said that every bit shifted to the left is multiplied by 2
8>>2?
0000 1000 shifts 2 bits to the right 0000 0010, which is converted to hexadecimal equal to 2
10>>2?
0000 1010 shifts 2 bits to the right 0000 0010, which is converted to hexadecimal equal to 2
1<<30?
0000 0001 shifts 30 bits to the left 01000000 000000 00000000 00000000 00000000, which is converted to hexadecimal, equal to 1073741824, that is, 230
HashMap collection features and source code analysis (JDK1.8) #
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
HashMap inherits the AbstractMap class and implements Cloneable cloning interface, Serializable serialization interface and Map interface
Features: array + linked list + red black tree

Five important points of HashMap #
1. Set initialization #
HashMap member variable #
//Default initialization hashmap capacity static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //The fourth power of 2 16 //hashmap maximum capacity 1073741824 static final int MAXIMUM_CAPACITY = 1 << 30;//The 30th power of 2 //Capacity expansion factor 16 * 0.75 = 12. Capacity expansion will be carried out when it reaches 12 static final float DEFAULT_LOAD_FACTOR = 0.75f; //When the number of elements stored in the linked list is > 8, it will be automatically converted to a red black tree static final int TREEIFY_THRESHOLD = 8; //When deleting elements, if the number of elements stored in a red black tree is less than 6, it will be automatically converted to a linked list static final int UNTREEIFY_THRESHOLD = 6; //Array capacity > 64 & linked list length > 8 is converted to red black tree static final int MIN_TREEIFY_CAPACITY = 64; //Threshold value, used to judge whether to expand capacity, threshold = capacity * expansion factor = 16 * 0.75 = 12 int threshold; //Actual size of expansion factor final float loadFactor; //The number of elements in the HashMap, transient, indicates that it cannot be serialized transient int size; //The number of collection modifications prevents multiple threads from tampering with data transient int modCount; //One way linked list of arrays storing elements transient Node<K,V>[] table;
HashMap internal data structure #
Linked list
//The one-way linked list implements the Entry interface, and the above array constitutes the structure of array plus linked list
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//Construct a node
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
//Basic method
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//Compare whether two nodes are equal
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
Red black tree
//Overview of red black tree structure
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;//Left subtree
TreeNode<K,V> right;//Right subtree
TreeNode<K,V> prev; //
boolean red;//Is it red
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
//Returns the current node
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
}
HashMap construction method #
Specify initial capacity
Construct an empty HashMap with default initial capacity (16) and default load factor (0.75)
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; //Expansion factor 0.75
}
Specify fill ratio
Construct an empty HashMap with the specified initial capacity and default expansion factor (0.75)
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);//The initial capacity expansion factor is 0.75 by default
}
public HashMap(int initialCapacity, float loadFactor) {
//Illegal capacity judgment
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//Is it greater than the maximum capacity? It is not allowed to exceed the maximum capacity
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//Illegal judgment of expansion factor
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;//Load factor
this.threshold = tableSizeFor(initialCapacity);
}
//The power of the smallest 2 greater than cap is obtained, for example, the power of the smallest 2 of 10, 10 = 16
static final int tableSizeFor(int cap) {
int n = cap - 1;//n=9 0000 1001
n |= n >>> 1;//|=Represents that the XOR operation first shifts 1 bit to the right = 0000 01000000 1001 and 0000 0100. The XOR operation obtains 0000 1101
n |= n >>> 2;//... and so on
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
//N < 0 returns 1, otherwise n is greater than maximum_ If the capacity is less than the maximum value, n + 1 will be returned. In the case of all 1, + 1 must become 1 followed by a pile of 0. This determines the final value. When the size of the HashMap reaches the threshold, it will expand
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
Map used to initialize
Construct a new HashMap using the same mapping as the specified Map
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;//Default load factor 0.75
putMapEntries(m, false);
}
//put collection elements into HashMap
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
//Get element size
int s = m.size();
if (s > 0) {
//If the array of storage elements is empty, it indicates that this is a newly constructed HashMap, then you need to specify the maximum capacity for it
if (table == null) {
//The maximum capacity is calculated according to the threshold and Map size, and rounded up to get an integer
float ft = ((float)s / loadFactor) + 1.0F;
//Judge whether the capacity exceeds the maximum capacity, and assign a value directly if it does not exceed the maximum capacity
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//If the capacity is greater than the threshold
if (t > threshold)
//Recalculate threshold
threshold = tableSizeFor(t);
}
//The array has been initialized
else if (s > threshold)
resize(); //Capacity expansion first
// Cyclic put
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
//resize may be triggered
putVal(hash(key), key, value, false, evict);
}
}
}
2. Data addressing Get #
Get elements according to key
public V get(Object key) {
Node<K,V> e;
//hash value of key
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
Detailed method
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;
Node<K,V> first, e;
int n; K k;
//If table is not equal to null, the array is not equal to null, and the first = assignment calculates the array subscript position where the hash value of the current node is located
if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {
//If the current node is compared with the first node
if (first.hash == hash &&((k = first.key) == key || (key != null && key.equals(k))))
//Return to the first node
return first;
//If the next node of the first node is not null
if ((e = first.next) != null) {
//Judge whether it is a red black tree
if (first instanceof TreeNode)
//Process getTreeNode() method to search for key
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//It's a linked list
do {
//Traverse the comparison until the node is found or the node is null to exit the loop
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
3. Data storage Put #
Add elements to HashMap
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
Detailed method
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
//n indicates the length of the table array, and i indicates which array subscript the key is stored in
int n, i;
//Judge whether the global table=tab is empty or whether the tab length is 0, and expand the capacity of the table
if ((tab = table) == null || (n = tab.length) == 0)
//Expansion n=16
n = (tab = resize()).length;
//I = (n - 1) & hash calculate the index value corresponding to the key tab [i] whether the key exists in the array
if ((p = tab[i = (n - 1) & hash]) == null)
//If the index value of the key does not conflict
tab[i] = newNode(hash, key, value, null);
//The index of key conflicts
else {
Node<K,V> e; K k;
//If the hash and equals comparisons are the same, overwrite them directly
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//If it is a red black tree
else if (p instanceof TreeNode)
//Append to red black tree
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//It is currently a linked list
else {
//Loop through linked list
for (int binCount = 0; ; ++binCount) {
//If the linked list is empty, it is directly appended after next
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//If the linked list length binCount is greater than 8, the array capacity is greater than 64
if (binCount >= TREEIFY_THRESHOLD - 1)
//Convert the linked list into a red black tree
treeifyBin(tab, hash);
break;
}
//Query whether the key exists in the linked list. If so, modify the value directly
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//Really assign a value to e and overwrite the new value with oldvalue
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//Only by adding a new one will the modCount + + modification not be affected. The fastclass mechanism will prevent the collection modification class during traversal
++modCount;
//If size > 12, the capacity will be expanded in advance
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
4. Node deletion #
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;
}
Detailed method
//Hash: hash value of key key: key value of key value pair to delete key value: value of key value pair to delete
//If matchValue is true, it will be deleted only when the value equals(value) of the key value pair corresponding to the key is true; Otherwise, you don't care about the value of value
//movable whether to move the node after deletion. If false, the node will not be moved
final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//The node array tab is not empty, the array length n is greater than 0, and the node object p located according to the hash
if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//If the key and key of the current node are equal, the current node is the node to be deleted and assigned to node
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//Gets the next node of the current node
else if ((e = p.next) != null) {
//If it is a red black tree, call the getTreeNode method to find the nodes that meet the conditions from the tree structure
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
//If it's a linked list
else {
//Node by node comparison from beginning to end
do {
//Whether the key of node e is equal to the key. Node e is the node to be deleted and assigned to the node variable
if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;//p points to e, so that p will always store the parent node of E in the next cycle
} while ((e = e.next) != null);
}
}
//Node is not empty. The deleted node is found. If the value value does not need to be compared or the value value needs to be compared, but the value value is also equal
if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {
//If it is a node on a red black tree
if (node instanceof TreeNode)
//delete
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//If it is a linked list, the node node is the first node
else if (node == p)
//Delete assigns the next value of the current node to the current table index
tab[index] = node.next;
//Not the first node, p is the parent node of node
else
// Deleting the next node of the parent node is the next node of the node
p.next = node.next;
++modCount;//The number of modifications of HashMap increases
--size;//Number of elements in HashMap
afterNodeRemoval(node);//The reserved override method has no effect
return node;//Return deletion result
}
}
return null;
}
5. Capacity expansion principle #
Resizing mechanism in JDK1.7 HashMap () #
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//If the old capacity has reached the maximum, set the threshold to the maximum value, the same as 1.8
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//Create a new hash table
Entry[] newTable = new Entry[newCapacity];
//Transfer the data from the old table to the new hash table
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//Update threshold
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//Traverse all linked lists in the original array
for (Entry<K,V> e : table) {
//Judge whether the linked list storage corresponding to each subscript is empty
while(null != e) {
//If you get e.next in both multithreaded environments, there may be an endless loop problem
Entry<K,V> next = e.next;
//Do you need to recalculate the hash value
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//Get the index in the new table
int i = indexFor(e.hash, newCapacity);
//Add the new node as the head node to the bucket
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
Analysis process of dead loop caused by capacity expansion in multithreaded environment
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
Because the header insertion method is used, the order of the whole linked list will be reversed. Traversing the table in a multithreaded environment is easy to lead to an endless loop because the same e object is manipulated

In the case of simultaneous capacity expansion of multiple threads, thread 1 obtains CPU resources first, while thread 2 is suspended. At this time, the data they get is e=a; next=c; As soon as the thread takes the lead in executing, it calculates the key and puts it into the newTable

At this time, thread 2 is awakened again. Because threads are not shared, the newTable is also empty and needs to be re assigned, but the e variable can be shared.
1. The first cycle of thread 2 or the data obtained before e=a; next=c, and the newTable is still empty
// e=a e.next=c Entry<K,V> next = e.next; //1 int i = indexFor(e.hash, newCapacity); //e.next=null e.next = newTable[i]; //The first element at the position of array 1 is assigned a newTable[i] = e; //e=c e = next;
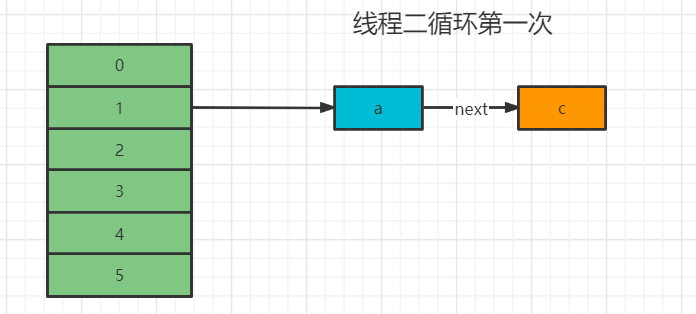
2. Thread second loop
In the second cycle, the data of e is obtained, because the data of e has been modified by thread 1 and changed to D - > C - >
// e=c e.next=a Entry<K,V> next = e.next; //1 int i = indexFor(e.hash, newCapacity); //e.next=null e.next = newTable[i]; //The position of array 1 is assigned c newTable[i] = e; //e=a e = next;

Because e has been modified by thread 1 to become D - > C - > A, c.next is equal to the value in thread 1, c.next=a
3. Thread second third loop
//e=a; e.next=a.next=null Entry<K,V> next = e.next; //1 int i = indexFor(e.hash, newCapacity); //At this time, newtable [i] = a - > C e.next = A.Next A.Next = C - > a dead cycle occurs e.next = newTable[i]; //The position of array 1 is assigned a newTable[i] = e; //e=null e = next;

At this point, the ring reference is entered, causing the CPU utilization to soar in the infinite loop
terms of settlement
There will be no problem if there is no single thread. ConCurrentHashMap is used in multi thread
Resizing mechanism in JDK1.8 HashMap () #
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//If the original table=null, it is the initialization of HashMap, and an empty table can be generated and returned
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//Threshold of hashmap's next expansion
int oldThr = threshold;
//Record the new capacity and the new next expansion size
int newCap, newThr = 0;
//Greater than 0 indicates that the array of previous HashMap is not empty
if (oldCap > 0) {
// Then check the array. If it is greater than the 30th power of the maximum capacity 2, it will be returned directly
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//If not, expand the capacity twice as much as before. Based on the right shift, the newCap is twice the length of the oldCap
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//Quantity of next advance expansion
newThr = oldThr << 1;
}
//A threshold greater than 0 indicates that the collection already exists and is assigned to newCap
else if (oldThr > 0)
newCap = oldThr;
//If it is equal to 0, it means that newcap = 0.75 has just been initialized, newthr = threshold of new capacity expansion = 0.75 * default capacity size
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//If the next advance expansion quantity = = 0
if (newThr == 0) {
//New threshold = new capacity * load factor
float ft = (float)newCap * loadFactor;
//The new array is less than the maximum capacity and the threshold is less than the maximum capacity
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//Threshold of next capacity expansion
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//New capacity expansion in HashMap
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//If the original table is not empty, move the data in the original table to the new table
if (oldTab != null) {
//Traverse the original list
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//Judge whether there is a linked list in each array. If so, save it with a linked list e
if ((e = oldTab[j]) != null) {
//Then assign the original linked list to null to avoid dead loop
oldTab[j] = null;
//The next node is empty, indicating that it contains only one element
if (e.next == null)
//Calculate the position of e in the new table and put it in it
newTab[e.hash & (newCap - 1)] = e;
//Judge whether the current node is a red black tree
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//Linked list
else {
//hashmap expansion will split the original linked list into two linked lists
//Head and tail of low linked list
Node<K,V> loHead = null, loTail = null;
//Head and tail of high-order linked list
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//Loop splits the linked list into two linked lists
do {
next = e.next;
//oldCap=16 when the hash subscript remains unchanged
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//Hash subscript change
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//Both methods put the linked list in a new position
//Put in the original position of the new table
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//Place in new table j+oldCap position
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap 1.8 unpacks the linked list into two linked lists through operation and stores them in a new table
HashMap interview questions #
When will HashMap be converted to red black tree #
When the array capacity is greater than 64 and the linked list length is greater than 8
Why should HashMap introduce red and black trees? What are the problems to be solved? #
The time complexity of linked list query is O(n), and the query efficiency is too low. The query efficiency of referencing red black tree can be changed to O(logN)
Why must the length of HashMap be a power of 2? #
In this way, the length must be even. When calculating the index subscript (n-1) & hash, so (n-1) will be odd, and the odd & hash value will reduce the conflict. The integer power of n to 2 is to reduce the probability of collision between different hash values, so that the elements can be evenly hashed in the hash table
How to avoid HashMap memory overflow #
Because hashcode and equals and methods are not rewritten, the bottom layer uses = = to compare memory addresses by default, which will lead to multiple objects in new. After rewriting, each comparison will be the same object and will be overwritten.
Time complexity of HashMap query based on key #
If the key has no conflict and the time complexity is O(1), it can be found at one time
If the key conflicts, the linked list is stored as O(n), and the red black tree is stored as O(logn)
Where is the HashMapKey stored when it is null #
Position 0
int index = k == null ? 0 : k.hashCode() % objects.length;
Is the HashMap bottom layer a single linked list or a double linked list #
Unidirectional linked list
Is the underlying HashMap stored in order #
One way linked list stores unordered hash, which will traverse all linked lists and red black trees, which is very inefficient
How do LinkedHashMap and TreeMap bottom layers achieve ordered #
Principle: associating the linked list in each index is less efficient than HashMap
Underlying implementation principle of cache elimination algorithm LinkedHashMap
How to clean up Redis when its cache is full?
LUR algorithm: clean up recently used key s
Scheme 1: record the usage times of each key, then sort and delete it, which is very inefficient
Scheme 2: when accessing the key based on the LinkedHashMap ordered set, the key will be saved to the last position in the linked list

Insertion order: the first added is in front, and the last added is in the back. The modification operation does not affect the order
After the get/put operation, the corresponding key value pair will move to the end of the linked list, so the last is the most recently accessed, and the first is the longest not accessed. This is the access order.
The parameter accessOrder is used to specify whether to access in order. If it is true, it is the access order.
Why does HashMap not use modulo operations #
k. Hashcode()% entries.length modulus will lead to very high probability of key conflict
It will become linked list O(n) or red black tree O(logn). It is necessary to reduce the Hash conflict probability and place it evenly at each subscript of the array
Find the subscript i = (n-1) & hash, why (n-1) becomes an odd number #
By default, capacity expansion is an even number to the nth power of 2. If it is an even & (and operation) hash, the index conflict probability is very high, which will lead to uneven data distribution

So it needs to be odd
How can HashMap reduce Hash conflicts #
The hash function calculates I = (n-1) & hash. The probability of hash value conflict can be reduced by odd residual hash values
Why is the loading factor 0.75 instead of 1 #
If the loading factor is larger (1), the space utilization is relatively high, and all 16 locations are filled, so the index conflict probability is relatively high
If the loading factor is smaller (0.1) and the capacity is expanded when it reaches 0.1, the smaller the space utilization is and the more locations can be stored. In this way, the smaller the collision probability is
Balance point in space and time: 0.75
Statistical probability: Poisson distribution is a common discrete probability distribution in statistics and probability
How does Hashap store 1W pieces of data? It is the most efficient #
hashmap capacity = (number of elements to be stored / expansion factor) + 1 = (10000 / 0.75) + 1 = 13334
The purpose is to reduce the number of underlying capacity expansion. If the initial capacity is not set, hashmap needs to be expanded seven times, which seriously affects the performance
Differences between Hashmap1.7 and Hashmap1.8 #
Hashmap1.7 implements header insertion based on array + linked list. The writing method is simple, but there is a multi-threaded dead loop problem
Hashmap1.8 implements tail interpolation based on array + linked list + red black tree to solve the problem of multi-threaded dead loop
It can reduce the conflict probability of the index corresponding to the key and improve the query rate
The original linked list use and operation hash & the length of the original table, split into two linked lists and put them into a new array, which can shorten the length of the linked list and improve the query efficiency