Deep understanding of JVM (XI) -- class loading and bytecode Technology (V)
6. Operation period optimization
Layered compilation
The JVM divides the execution state into five levels:
- Layer 0: interpret and execute, and translate bytecode into machine code with interpreter
- Layer 1: compile and execute with C1 real-time compiler (without pro fi ling)
- Layer 2: compile and execute with C1 real-time compiler (with basic profiling)
- Layer 3: compile and execute with C1 real-time compiler (with full profiling)
- Layer 4: compile and execute with C2 real-time compiler
pro "ling" refers to the collection of data on the execution status of some programs during operation, such as [number of method calls], [number of edge loops], etc
The difference between just in time compiler (JIT) and interpreter
- interpreter
- Interpret bytecode as machine code. Even if the same bytecode is encountered next time, it will still perform repeated interpretation
- Bytecode is interpreted as machine code common to all platforms
- Just in time compiler
- Compile some bytecodes into machine code and store them in Code Cache. When encountering the same code next time, execute it directly without further compilation
- Generate platform specific machine code according to platform type
For most of the infrequently used code, we do not need to spend time compiling it into machine code, but run it in the way of interpretation and execution; On the other hand, for only a small part of the hot code, we can compile it into machine code to achieve the ideal running speed. In terms of execution efficiency, simply compare interpreter < C1 < C2. The overall goal is to find hotspot codes (the origin of hotspot names) and optimize these hotspot codes
escape analysis
Escape Analysis is simply a technology that the Java Hotspot virtual machine can analyze the usage range of newly created objects and decide whether to allocate memory on the Java heap
JVM parameters for escape analysis are as follows:
- Enable escape analysis: - XX:+DoEscapeAnalysis
- Close escape analysis: - XX:-DoEscapeAnalysis
- Display analysis results: - XX: + printescape analysis
Escape analysis technology is supported in Java SE 6u23 +, and is set to enabled by default. You don't need to add this parameter
Object escape state
Global escape
- That is, the scope of an object escapes from the current method or thread. There are several scenarios:
- Object is a static variable
- An object is an object that has escaped
- Object as the return value of the current method
Parameter escape (ArgEscape)
- That is, an object is passed or referenced as a method parameter, but there will be no global escape during the call. This state is determined by the bytecode of the called method
No escape
- That is, the object in the method does not escape
Escape analysis optimization
For the third point above, when an object does not escape, the following virtual machines can be optimized
Lock elimination
We know that thread synchronization lock is very performance sacrificing. When the compiler determines that the current object is only used by the current thread, it will remove the synchronization lock of the object
For example, both StringBuffer and Vector use synchronized to decorate thread safety, but in most cases, they are only used in the current thread, so the compiler will optimize the operation of removing these locks
The JVM parameters for lock elimination are as follows:
- Open lock elimination: - XX:+EliminateLocks
- Close lock elimination: - XX:-EliminateLocks
Lock elimination is enabled by default in JDK8, and lock elimination should be based on escape analysis
scalar replacement
First of all, we should understand scalars and aggregation quantities. References to basic types and objects can be understood as scalars, which cannot be further decomposed. The quantity that can be further decomposed is the aggregate quantity, such as object
An object is an aggregate quantity, which can be further decomposed into scalars and its member variables into dispersed variables, which is called scalar substitution.
In this way, if an object does not escape, there is no need to create it at all. Only the member scalar used by it will be created on the stack or register, which saves memory space and improves the performance of the application
The JVM parameters for scalar substitution are as follows:
- Enable scalar substitution: - XX:+EliminateAllocations
- Turn off scalar substitution: - XX:-EliminateAllocations
- Display scalar substitution details: - XX:+PrintEliminateAllocations
Scalar substitution is also enabled by default in JDK8, and should be based on escape analysis
On stack allocation
When the object does not escape, the object can be decomposed into member scalars through scalar replacement and allocated in the stack memory, which is consistent with the life cycle of the method. With the destruction of the stack frame when it comes out of the stack, the GC pressure is reduced and the application performance is improved
Method Inlining
Inline function
Inline function is that when the program is compiled, the compiler directly replaces the call expression of the inline function in the program with the function body of the inline function
JVM inline function
Whether C + + is an inline function is up to you, and Java is up to the compiler. Java does not support functions declared directly as inline functions. If you want them to be inline, you can only make a request to the compiler: the keyword final modifier is used to indicate that the function wants to be inline by the JVM, such as
public final void doSomething() {
// to do something
}
Generally speaking, general functions will not be treated as inline functions. Only after final is declared, the compiler will consider whether to turn your function into an inline function
There are many runtime optimizations built into the JVM. First, the short method is more conducive to JVM inference. The process is more obvious, the scope is shorter, and the side effects are more obvious. If it is a long method, the JVM may kneel directly.
The second reason is more important: method inlining
If the JVM detects that some small methods are executed frequently, it will replace the method call with the method body itself, such as:
private int add4(int x1, int x2, int x3, int x4) {
//add2 method is called here
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
After the method call is replaced
private int add4(int x1, int x2, int x3, int x4) {
//Replaced by the method itself
return x1 + x2 + x3 + x4;
}
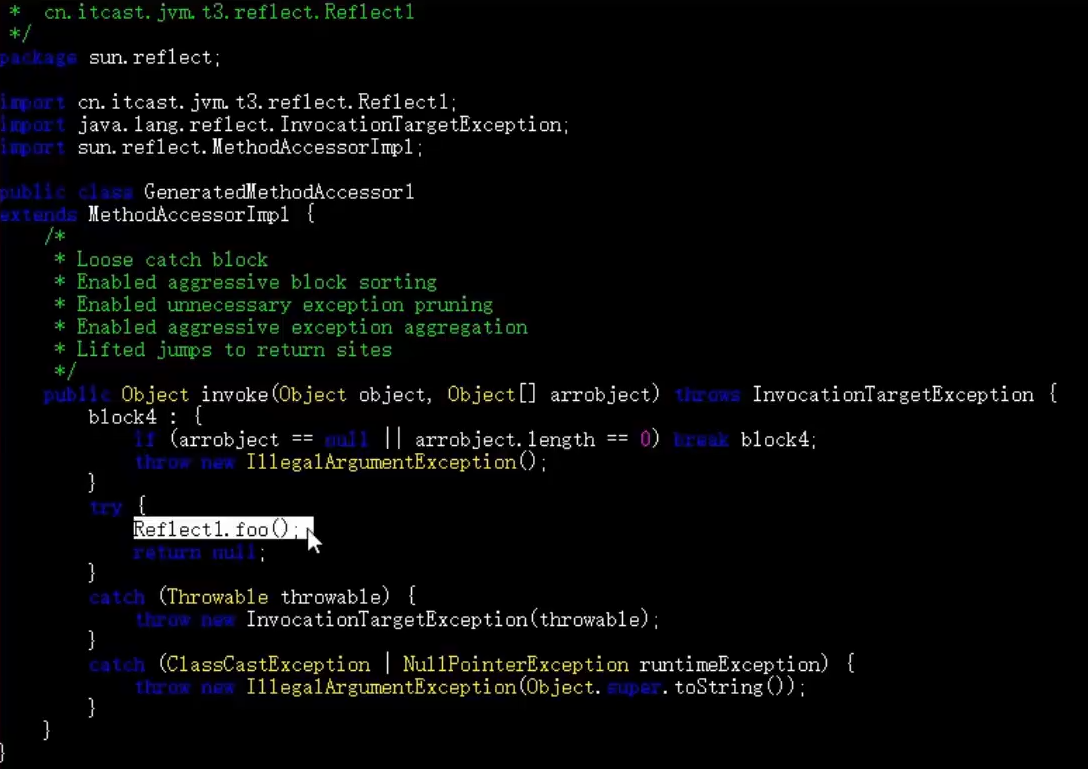
Reflection optimization
public class Reflect1 {
public static void foo() {
System.out.println("foo...");
}
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
Method foo = Demo3.class.getMethod("foo");
for(int i = 0; i<=16; i++) {
foo.invoke(null);
}
}
}
foo. The first 0 ~ 15 calls to invoke use the NativeMethodAccessorImpl implementation of MethodAccessor
invoke method source code
@CallerSensitive
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
//MethodAccessor is an interface with three implementation classes, one of which is an abstract class
MethodAccessor ma = methodAccessor; // read volatile
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
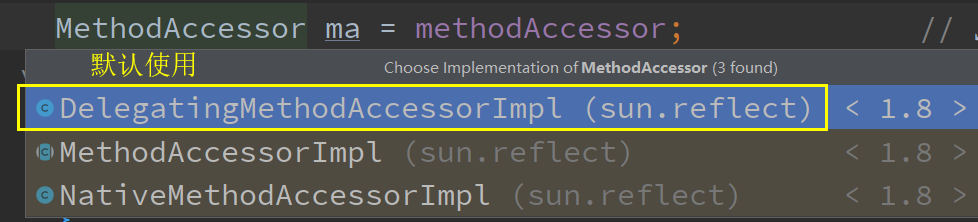
The delegatingmethodaccessorimpl will call NativeMethodAccessorImpl
NativeMethodAccessorImpl source code
class NativeMethodAccessorImpl extends MethodAccessorImpl {
private final Method method;
private DelegatingMethodAccessorImpl parent;
private int numInvocations;
NativeMethodAccessorImpl(Method var1) {
this.method = var1;
}
//Each reflection call will make numInvocation and reflectionfactory Compare the value of inflationthreshold (15) and add one to the value of numInvocation
//If numinvocation > reflectionfactory Inflationthreshold, the local method invoke0 method will be called
public Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException {
if (++this.numInvocations > ReflectionFactory.inflationThreshold() && !ReflectUtil.isVMAnonymousClass(this.method.getDeclaringClass())) {
MethodAccessorImpl var3 = (MethodAccessorImpl)(new MethodAccessorGenerator()).generateMethod(this.method.getDeclaringClass(), this.method.getName(), this.method.getParameterTypes(), this.method.getReturnType(), this.method.getExceptionTypes(), this.method.getModifiers());
this.parent.setDelegate(var3);
}
return invoke0(this.method, var1, var2);
}
void setParent(DelegatingMethodAccessorImpl var1) {
this.parent = var1;
}
private static native Object invoke0(Method var0, Object var1, Object[] var2);
}
//ReflectionFactory. Return value of the inflationthreshold() method
private static int inflationThreshold = 15;
- At first, if the condition is not satisfied, the local method invoke0 will be called
- As numInvocation increases, when it is larger than reflectionfactory When the value of inflationthreshold is 16, the local method accessor will be replaced by a dynamically generated accessor at runtime to improve efficiency
- At this time, it will change from reflection call to normal call, that is, call reflect1 directly foo()