1. What is the bloom filter
2. Characteristics of Bloom filter
3. Usage scenario of Bloom filter
4. Principle of Bloom filter
5. Advantages and disadvantages of Bloom filter
6. Application of Bloom filter
7. Summary
1. What is the bloom filter
The bloom filter of redis is actually a bit like the hyperlog we learned before In depth understanding of redis -- a new type of bitmap / hyperlogo / Geo , it is also a set that does not save elements, and it does not save the specific contents of elements, but it can determine whether the element exists in the set (hyperloglog is the number of non repeating elements in the set).
1) It is composed of a bit array with zero initial value and multiple hash functions to quickly judge whether a data exists.
2) The essence is to judge whether specific data exists in a large set.
3) Bloom filter is a data structure similar to set, but the statistical results are not accurate
2. Characteristics of Bloom filter
1) If an element is judged as non-existent in the bloom filter, it must not exist
2) If an element is judged to exist in the bloom filter, it does not necessarily exist (the principle will be explained below)
3) Bloom filter can add elements, but cannot delete elements. Deleting elements will increase the misjudgment rate.
4) Misjudgment will only occur in elements that have not been added to the filter. Misjudgment will not occur for elements that have been added.
3. Usage scenario of Bloom filter
1) Solve the problem of cache penetration:
What is cache penetration:
In general, when querying data, if we use redis, we first check redis. If there is no redis in the cache, we then check the database. If there is no redis in the database, then cache penetration occurs.
When cache penetration occurs, a large number of queries may directly hit mysql, which will bring down the database to a certain extent.
Solution:
1.1) set an empty value for an empty key
However, when a large number of empty key s come out, it is equivalent to checking mysql many times, which may also bring down the database.
1.2) use bloom filter
Saving the existing key in the bloom filter is equivalent to a layer of Bloom filter protection in front of redis.
When a request occurs:
1.2.1) first check whether the bloom filter exists (if the bloom filter returns non-existent, it must not exist.)
1.2.2) if it exists, go to redis or even mysql query. If it does not exist, return it directly.
2) Black and white list questions:
The solution principle is the same as above. Put all the blacklists into the bloom filter and then filter them.
3) Bloom filter can be used to find out whether there are problems in massive data. (for example, there are 5 billion telephone numbers and 100000 telephone numbers, which can quickly and accurately determine whether the number exists.)
4. Principle of Bloom filter
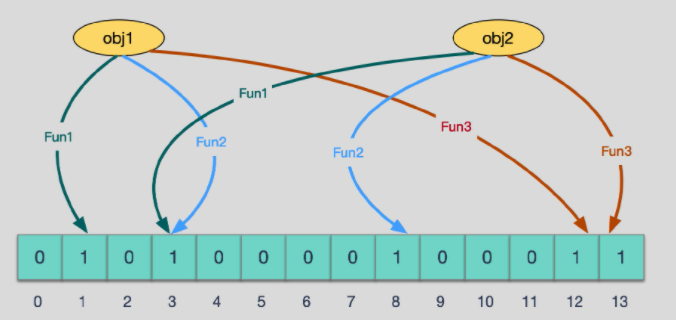
The bloom filter uses multiple Hash functions and a large array of bit s with initial values of 0.
add:
For example, we now have an object obj1, which first uses multiple hash functions to get multiple different values, then takes the array length to modulus these values to get multiple positions, and sets these positions to 1 to complete the add operation.
query:
When querying, as long as one of the subscripts calculated by multiple hash functions is 0, it means that the key does not exist. If they are all 1, it may exist, and then there may be hash conflict (that's why, bloom filter, none must be none, there may be).
Why the bloom filter cannot be deleted:
If the bloom filter deletes an element, that is, sets multiple subscripts of an object to 0, it will probably affect other elements, because it is likely that multiple elements share a subscript, so deleting an element will increase the misjudgment rate.
5. Advantages and disadvantages of Bloom filter
Advantages: insert and query efficiently and occupy less space
Disadvantages: elements cannot be deleted and misjudgment exists.
6. Application of Bloom filter
public class RedissonBloomFilterDemo {
public static final int _1W = 10000;
//How much data is expected to be inserted into the bloom filter
public static int size = 100 * _1W;
//The smaller the misjudgment rate, the fewer the number of misjudgments
public static double fpp = 0.03;
static RedissonClient redissonClient = null;
static RBloomFilter rBloomFilter = null;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.111.147:6379").setDatabase(0);
//Construct redisson
redissonClient = Redisson.create(config);
//Construct rBloomFilter through reisson
rBloomFilter = redissonClient.getBloomFilter("phoneListBloomFilter", new StringCodec());
//Initialize bloom filter
rBloomFilter.tryInit(size, fpp);
// 1 test whether the bloom filter has + redis yes
rBloomFilter.add("10086");
redissonClient.getBucket("10086", new StringCodec()).set("chinamobile10086");
// 2 test whether the bloom filter has + redis
//rBloomFilter.add("10087");
//No test, 3
}
public static void main(String[] args) {
String phoneListById = getPhoneListById("10087");
System.out.println("------Query results: " + phoneListById);
//Pause the thread for a few seconds
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
redissonClient.shutdown();
}
private static String getPhoneListById(String IDNumber) {
String result = null;
if (IDNumber == null) {
return null;
}
//1. Go to the bloom filter first
if (rBloomFilter.contains(IDNumber)) {
//2. There are in bloom filter, and then go to redis for query
RBucket rBucket = redissonClient.getBucket(IDNumber, new StringCodec());
result = rBucket.get();
if (result != null) {
return "i come from redis: " + result;
} else {
result = getPhoneListByMySQL(IDNumber);
if (result == null) {
return null;
}
// Update the data back to redis
redissonClient.getBucket(IDNumber, new StringCodec()).set(result);
}
return "i come from mysql: " + result;
}
return result;
}
private static String getPhoneListByMySQL(String IDNumber) {
return "chinamobile" + IDNumber;
}
}
7. Summary
Today, I learned and summarized bloom filter, which is a data type that does not save data, but can determine whether data exists in the set.