preface
The last article introduced how to use ncnn to deploy yolox on nano. Because the ncnn related deployment code of yolox is open source, we only need to configure the environment according to the process, modify the relevant code and compile it. The author has open source the code of four deployment methods, but there is no libtorch. Libtorch, as the C + + version of pytorch, also has very efficient deployment efficiency, It is also relatively easy to use, so this article describes how to deploy yolox using libtorch.
1. Model transformation pytorch->torchscript
First of all, we should serialize the model of pytorch into a C + + callable model. Here, I imitate the code of torch to onnx in the original hub and create an export_libtorch.py file, put it in export_onnx.py directory, the conversion code is as follows:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
import argparse
import os
from loguru import logger
import torch
from torch import nn
from yolox.exp import get_exp
from yolox.models.network_blocks import SiLU
from yolox.utils import replace_module
def make_parser():
parser = argparse.ArgumentParser("YOLOX libtorch deploy")
parser.add_argument(
"--output-name", type=str, default="yolox.pt", help="output name of models"
)
parser.add_argument("--input", default="images", type=str, help="input name of onnx model")
parser.add_argument("--output", default="output", type=str, help="output name of onnx model")
parser.add_argument("-o", "--opset", default=11, type=int, help="onnx opset version")
parser.add_argument(
"-f",
"--exp_file",
default=None,
type=str,
help="expriment description file",
)
parser.add_argument("-expn", "--experiment-name", type=str, default=None)
parser.add_argument("-n", "--name", type=str, default=None, help="model name")
parser.add_argument("-c", "--ckpt", default=None, type=str, help="ckpt path")
parser.add_argument(
"opts",
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER,
)
return parser
@logger.catch
def main():
args = make_parser().parse_args()
logger.info("args value: {}".format(args))
exp = get_exp(args.exp_file, args.name)
exp.merge(args.opts)
if not args.experiment_name:
args.experiment_name = exp.exp_name
model = exp.get_model()
if args.ckpt is None:
file_name = os.path.join(exp.output_dir, args.experiment_name)
ckpt_file = os.path.join(file_name, "best_ckpt.pth.tar")
else:
ckpt_file = args.ckpt
ckpt = torch.load(ckpt_file, map_location="cpu")
# load the model state dict
model.eval()
if "model" in ckpt:
ckpt = ckpt["model"]
model.load_state_dict(ckpt)
model = replace_module(model, nn.SiLU, SiLU)
model.head.decode_in_inference = False
logger.info("loaded checkpoint done.")
dummy_input = torch.randn(1, 3, exp.test_size[0], exp.test_size[1])
traced_script_module = torch.jit.trace(model, dummy_input)
output1 = traced_script_module(torch.ones(1, 3, 640, 640))
output2 = model(torch.ones(1, 3, 640, 640))
print(output1) # Check whether the reasoning after conversion is consistent
print(output2)
traced_script_module.save(args.output_name)
logger.info("generate jit::torch named {}".format(args.output_name))
if __name__ == "__main__":
main()
Direct run command:
python tools/export_libtorch.py -n yolox-s -c weights/best_ckpt.pth.tar
Similarly, if it is the weight of your own training, you need to modify exps/default/yolox_s.py file, change the number of categories to 1:
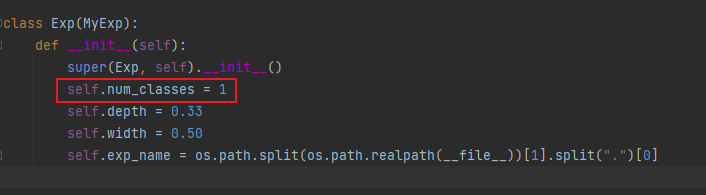
After running, you get yolox PT file (if GPU reasoning is required, cuda needs to be loaded during model transformation).
2, libtorch environment configuration
In fact, there is no configuration, because the libtorch official has compiled it for us. You can download it directly and use it torch's official website Medium:

Directly copy and link to the browser or download from Xunlei. Here, it should be noted that it should correspond to the pytorch version and cuda version you use as far as possible, otherwise there may be problems, because I use torch 1 Version 8, so the link has been modified to 1.9 0 to 1.8 0. It can be downloaded normally. The file is a little large. Wait slowly; After downloading it, unzip it directly to get a 4G folder (too big...), with the following structure:
First record the file path, which will be used when compiling. You can simply write a program to test whether it can be used normally:
#include <iostream>
#include "torch/torch.h"
#include "torch/jit.h"
int main() {
std::cout << "Hello, World!" << std::endl;
auto a = torch::tensor({{1, 2}, {3, 4}});
std::cout << a << std::endl;
return 0;
}
CMakeLists.txt file is as follows:
find_package(PythonInterp REQUIRED)
cmake_minimum_required(VERSION 3.16)
project(Libtorch_test)
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_PREFIX_PATH /home/cai/github/libtorch) # Write the path of libtorch save just now
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_executable(Libtorch_test libtorch_test.cpp)
target_link_libraries(Libtorch_test ${TORCH_LIBRARIES})
If the following results are obtained after compilation, it can be used normally (if it is developed by ubuntu, it is recommended to use clion to write and compile c + + code. When creating a new C + + project, it will help you create the two files at the same time and directly copy them to run. However, the bad thing about clion is that it is not free... I think of a way to do it myself)
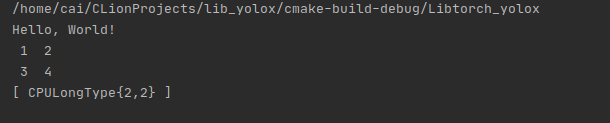
3, Using libtorch to call the torchscripts model
Because yolox is anchor free, its post-processing part is very friendly and not as complex as yolov5. For coco 80 class, the output is still 85 channels, which is the same as yolov5, The same is true (two center points (2) + width and height (2) + confidence (1) + classification (80) = 85). The difference is that without anchor, it is easier to calculate the offset back to the original drawing.
Give cmakelists first Txt file content, because opencv is used, opencv should also be compiled in advance:
find_package(PythonInterp REQUIRED)
cmake_minimum_required(VERSION 3.16)
project(Libtorch_yolox)
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_PREFIX_PATH /home/cai/github/libtorch) # Path modification
find_package(Torch REQUIRED)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_executable(Libtorch_yolox main.cpp)
target_link_libraries(Libtorch_yolox ${TORCH_LIBRARIES} ${OpenCV_LIBS})
Create a new main CPP files are directly coded. The main difference between CPP files and ncnn and tensorrt codes is that they are basically the same as the pre-processing and reasoning part of the image and the post-processing part after network output. However, due to the different types of data output by different frameworks, corresponding modifications should also be made:
#include <iostream>
#include "torch//jit.h"
#include "opencv2/opencv.hpp"
#include "torch/script.h"
#include "algorithm"
using namespace cv;
using namespace std;
static const int INPUT_W = 640;
static const int INPUT_H = 640;
#define NMS_THRESH 0.1
#define BBOX_CONF_THRESH 0.3
struct Object
{
cv::Rect_<float> rect;
int label;
float prob;
};
struct GridAndStride
{
int grid0;
int grid1;
int stride;
};
Mat narrow_640_pad(Mat& img,float &scale) {
int nw = int(img.cols * scale);
int nh = int(img.rows * scale);
resize(img, img, cv::Size(nw, nh), INTER_CUBIC);
int top = 0;
int bottom = INPUT_H - nh - top;
int left = 0;
int right = INPUT_W - nw - left;
Mat resize_img;
copyMakeBorder(img, resize_img, top, bottom, left, right, BORDER_CONSTANT, Scalar(114, 114, 114));
return resize_img;
}
static void generate_yolox_proposals(std::vector<GridAndStride> grid_strides, const torch::Tensor &feat_ptr, float prob_threshold, std::vector<Object>& objects)
{
const int num_class = feat_ptr.sizes()[1] - 5;
const int num_anchors = grid_strides.size();
// const float* feat_ptr = (float *)feat_blob.data;
for (int anchor_idx = 0; anchor_idx < num_anchors; anchor_idx++)
{
const int grid0 = grid_strides[anchor_idx].grid0;
const int grid1 = grid_strides[anchor_idx].grid1;
const int stride = grid_strides[anchor_idx].stride;
// yolox/models/yolo_head.py decode logic
// outputs[..., :2] = (outputs[..., :2] + grids) * strides
// outputs[..., 2:4] = torch.exp(outputs[..., 2:4]) * strides
torch::Tensor x_center = (feat_ptr[anchor_idx][0] + grid0) * stride;
torch::Tensor y_center = (feat_ptr[anchor_idx][1] + grid1) * stride;
torch::Tensor w = exp(feat_ptr[anchor_idx][2]) * stride;
torch::Tensor h = exp(feat_ptr[anchor_idx][3]) * stride;
torch::Tensor x0 = x_center - w * 0.5f;
torch::Tensor y0 = y_center - h * 0.5f;
torch::Tensor box_objectness = feat_ptr[anchor_idx][4];
for (int class_idx = 0; class_idx < num_class; class_idx++)
{
torch::Tensor box_cls_score = feat_ptr[anchor_idx][5 + class_idx];
torch::Tensor box_prob = box_objectness * box_cls_score;
if (box_prob.item().toFloat() > prob_threshold)
{
Object obj;
obj.rect.x = x0.item().toFloat();
obj.rect.y = y0.item().toFloat();
obj.rect.width = w.item().toFloat();
obj.rect.height = h.item().toFloat();
obj.label = class_idx;
obj.prob = box_prob.item().toFloat();
objects.push_back(obj);
}
}
} // point anchor loop
}
static int generate_grids_and_stride(const int target_size, std::vector<int>& strides, std::vector<GridAndStride>& grid_strides)
{
for (auto stride : strides)
{
int num_grid = target_size / stride;
for (int g1 = 0; g1 < num_grid; g1++)
{
for (int g0 = 0; g0 < num_grid; g0++)
{
grid_strides.push_back((GridAndStride){g0, g1, stride});
}
}
}
}
static void qsort_descent_inplace(std::vector<Object>& faceobjects, int left, int right) {
int i = left;
int j = right;
float p = faceobjects[(left + right) / 2].prob;
while (i <= j) {
while (faceobjects[i].prob > p)
i++;
while (faceobjects[j].prob < p)
j--;
if (i <= j) {
// swap
std::swap(faceobjects[i], faceobjects[j]);
i++;
j--;
}
}
}
static void qsort_descent_inplace(std::vector<Object>& objects)
{
if (objects.empty())
return;
qsort_descent_inplace(objects, 0, objects.size() - 1);
}
static inline float intersection_area(const Object& a, const Object& b)
{
cv::Rect_<float> inter = a.rect & b.rect;
return inter.area();
}
static void nms_sorted_bboxes(const std::vector<Object>& faceobjects, std::vector<int>& picked, float nms_threshold)
{
picked.clear();
const int n = faceobjects.size();
std::vector<float> areas(n);
for (int i = 0; i < n; i++)
{
areas[i] = faceobjects[i].rect.area();
}
for (int i = 0; i < n; i++)
{
const Object& a = faceobjects[i];
int keep = 1;
for (int j = 0; j < (int)picked.size(); j++)
{
const Object& b = faceobjects[picked[j]];
// intersection over union
float inter_area = intersection_area(a, b);
float union_area = areas[i] + areas[picked[j]] - inter_area;
// float IoU = inter_area / union_area
if (inter_area / union_area > nms_threshold)
keep = 0;
}
if (keep)
picked.push_back(i);
}
}
static void decode_outputs(torch::Tensor &prob, std::vector<Object>& objects, float &scale, const int img_w, const int img_h) {
std::vector<Object> proposals;
std::vector<int> strides = {8, 16, 32};
std::vector<GridAndStride> grid_strides;
generate_grids_and_stride(INPUT_W, strides, grid_strides);
generate_yolox_proposals(grid_strides, prob, BBOX_CONF_THRESH, proposals);
std::cout << "num of boxes before nms: " << proposals.size() << std::endl;
qsort_descent_inplace(proposals);
std::vector<int> picked;
nms_sorted_bboxes(proposals, picked, NMS_THRESH);
int count = picked.size();
std::cout << "num of boxes: " << count << std::endl;
objects.resize(count);
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x) / scale;
float y0 = (objects[i].rect.y) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height) / scale;
// clip
x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
}
}
const float color_list[80][3] =
{
{0.850, 0.325, 0.098},
{0.000, 0.447, 0.741},
{0.929, 0.694, 0.125},
{0.494, 0.184, 0.556},
{0.466, 0.674, 0.188},
{0.301, 0.745, 0.933},
{0.635, 0.078, 0.184},
{0.300, 0.300, 0.300},
{0.600, 0.600, 0.600},
{1.000, 0.000, 0.000},
{1.000, 0.500, 0.000},
{0.749, 0.749, 0.000},
{0.000, 1.000, 0.000},
{0.000, 0.000, 1.000},
{0.667, 0.000, 1.000},
{0.333, 0.333, 0.000},
{0.333, 0.667, 0.000},
{0.333, 1.000, 0.000},
{0.667, 0.333, 0.000},
{0.667, 0.667, 0.000},
{0.667, 1.000, 0.000},
{1.000, 0.333, 0.000},
{1.000, 0.667, 0.000},
{1.000, 1.000, 0.000},
{0.000, 0.333, 0.500},
{0.000, 0.667, 0.500},
{0.000, 1.000, 0.500},
{0.333, 0.000, 0.500},
{0.333, 0.333, 0.500},
{0.333, 0.667, 0.500},
{0.333, 1.000, 0.500},
{0.667, 0.000, 0.500},
{0.667, 0.333, 0.500},
{0.667, 0.667, 0.500},
{0.667, 1.000, 0.500},
{1.000, 0.000, 0.500},
{1.000, 0.333, 0.500},
{1.000, 0.667, 0.500},
{1.000, 1.000, 0.500},
{0.000, 0.333, 1.000},
{0.000, 0.667, 1.000},
{0.000, 1.000, 1.000},
{0.333, 0.000, 1.000},
{0.333, 0.333, 1.000},
{0.333, 0.667, 1.000},
{0.333, 1.000, 1.000},
{0.667, 0.000, 1.000},
{0.667, 0.333, 1.000},
{0.667, 0.667, 1.000},
{0.667, 1.000, 1.000},
{1.000, 0.000, 1.000},
{1.000, 0.333, 1.000},
{1.000, 0.667, 1.000},
{0.333, 0.000, 0.000},
{0.500, 0.000, 0.000},
{0.667, 0.000, 0.000},
{0.833, 0.000, 0.000},
{1.000, 0.000, 0.000},
{0.000, 0.167, 0.000},
{0.000, 0.333, 0.000},
{0.000, 0.500, 0.000},
{0.000, 0.667, 0.000},
{0.000, 0.833, 0.000},
{0.000, 1.000, 0.000},
{0.000, 0.000, 0.167},
{0.000, 0.000, 0.333},
{0.000, 0.000, 0.500},
{0.000, 0.000, 0.667},
{0.000, 0.000, 0.833},
{0.000, 0.000, 1.000},
{0.000, 0.000, 0.000},
{0.143, 0.143, 0.143},
{0.286, 0.286, 0.286},
{0.429, 0.429, 0.429},
{0.571, 0.571, 0.571},
{0.714, 0.714, 0.714},
{0.857, 0.857, 0.857},
{0.000, 0.447, 0.741},
{0.314, 0.717, 0.741},
{0.50, 0.5, 0}
};
static void draw_objects(const cv::Mat& bgr, const std::vector<Object>& objects)
{
// static const char* class_names[] = {
// "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
// "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
// "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
// "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
// "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
// "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
// "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
// "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
// "hair drier", "toothbrush"
// }; // If it is a coco 80 class, you can release the comment. And comment out the following
static const char* class_names[] = {
"label" // Modify according to the number of categories
};
cv::Mat image = bgr.clone();
for (size_t i = 0; i < objects.size(); i++)
{
const Object& obj = objects[i];
fprintf(stderr, "%d = %.5f at %.2f %.2f %.2f x %.2f\n", obj.label, obj.prob,
obj.rect.x, obj.rect.y, obj.rect.width, obj.rect.height);
cv::Scalar color = cv::Scalar(color_list[obj.label][0], color_list[obj.label][1], color_list[obj.label][2]);
float c_mean = cv::mean(color)[0];
cv::Scalar txt_color;
if (c_mean > 0.5){
txt_color = cv::Scalar(0, 0, 0);
}else{
txt_color = cv::Scalar(255, 255, 255);
}
cv::rectangle(image, obj.rect, color * 255, 2);
char text[256];
sprintf(text, "%s %.1f%%", class_names[obj.label], obj.prob * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.4, 1, &baseLine);
cv::Scalar txt_bk_color = color * 0.7 * 255;
int x = obj.rect.x;
int y = obj.rect.y + 1;
//int y = obj.rect.y - label_size.height - baseLine;
if (y > image.rows)
y = image.rows;
//if (x + label_size.width > image.cols)
//x = image.cols - label_size.width;
cv::rectangle(image, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
txt_bk_color, -1);
cv::putText(image, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.4, txt_color, 1);
}
cv::imwrite("det_res.jpg", image);
fprintf(stderr, "save vis file\n");
/* cv::imshow("image", image); */
/* cv::waitKey(0); */
}
int main() {
const char*imagepath = "../1.jpg";
torch::jit::script::Module model;
try{
model = torch::jit::load("../yolox_best.pt");
// model.to(at::kCUDA);
} catch (const c10::Error&e) {
cerr << "error loading the model\n";
return -1;
}
Mat image = imread(imagepath);
Mat image_copy = image.clone();
if (image.empty()){
cout << "Eroor: Could not load image" << endl;
return -1;
}
double time0 = static_cast<double >(getTickCount());
float scale = std::min(INPUT_W / (image.cols*1.0), INPUT_H / (image.rows*1.0));
image = narrow_640_pad(image,scale);
torch::Tensor tensor_image = torch::from_blob(image.data,{1,image.rows,image.cols,3},torch::kByte);
tensor_image = tensor_image.permute({0,3,1,2});
tensor_image = tensor_image.toType(torch::kFloat);
// tensor_image = tensor_image.to(at::kCUDA);
tensor_image = tensor_image.div(255)-0.5;
tensor_image = tensor_image.div(0.5);
torch::Tensor result = model.forward({tensor_image}).toTensor();
result = result.squeeze(0);
std::vector<Object> objects;
decode_outputs(result,objects,scale,image_copy.cols,image_copy.rows);
draw_objects(image_copy, objects);
//[5] Calculate run time and output
time0 = ((double)getTickCount() - time0) / getTickFrequency(); //End time - start time, converted to seconds
cout << "\t This method runs on: " << time0 << "second" << endl; //Output run time
return 0;
}
Run the executable directly after compilation/ Libtorch_yolox gets the following results:
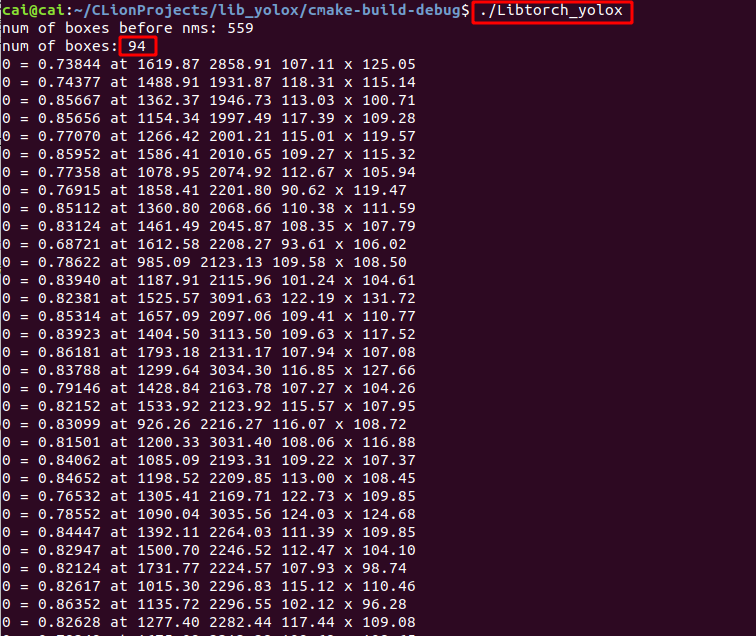
559 is the number of detected frames, 94 is the number of target frames after NMS, and the following information is the specific information of each target frame. Still use the picture tested before. The test effect is as follows, and the effect is basically the same as before. If you have time, find a camera or video to try the effect.
