Example creation mode (single type)
Hungry Han style
Hungry Chinese singleton has created a static object for the system to use at the same time of class creation, which will not be changed in the future. Therefore, it is thread safe and can be directly used for multithreading without problems.
The feature of this pattern is that once the class is loaded, a singleton is created to ensure that the singleton already exists before calling the getInstance method.
package com.zbz.Design mode;
public class Hungry {
/*
* Disadvantages: directly creating a static object may cause excessive content consumption
* */
private byte[] b1=new byte[1024*1024];
private byte[] b2=new byte[1024*1024];
private byte[] b3=new byte[1024*1024];
private byte[] b4=new byte[1024*1024];
//Private construction class to prevent the generation of instances
private Hungry(){
}
public static final Hungry hungry=new Hungry();
public static Hungry getInstance(){
return hungry;
}
}
Resolution:
Private constructor
The so-called private constructor is the so-called private constructor.
Its access permission is private. It can only be accessed by the class itself and cannot be called outside the class. Therefore, it can prevent the generation of objects.
Therefore, if a class has only one private constructor without any public constructor, it cannot generate any objects.
So what is the use of classes with private constructors that cannot generate objects?
Such classes are most commonly used as tool classes in practical applications, such as string verification and enumeration conversion. They are usually only made into static interfaces and called externally.
Static method is a method declared with static keyword, which can be called directly by class without specific objects instantiated from class. Therefore, such method is also called class method. Static methods can only access static fields and other static methods in the class, because non static members must be accessed through object references.
1. We need to know that static attributes are initialized at the first time in the initialization object (New hungary()):


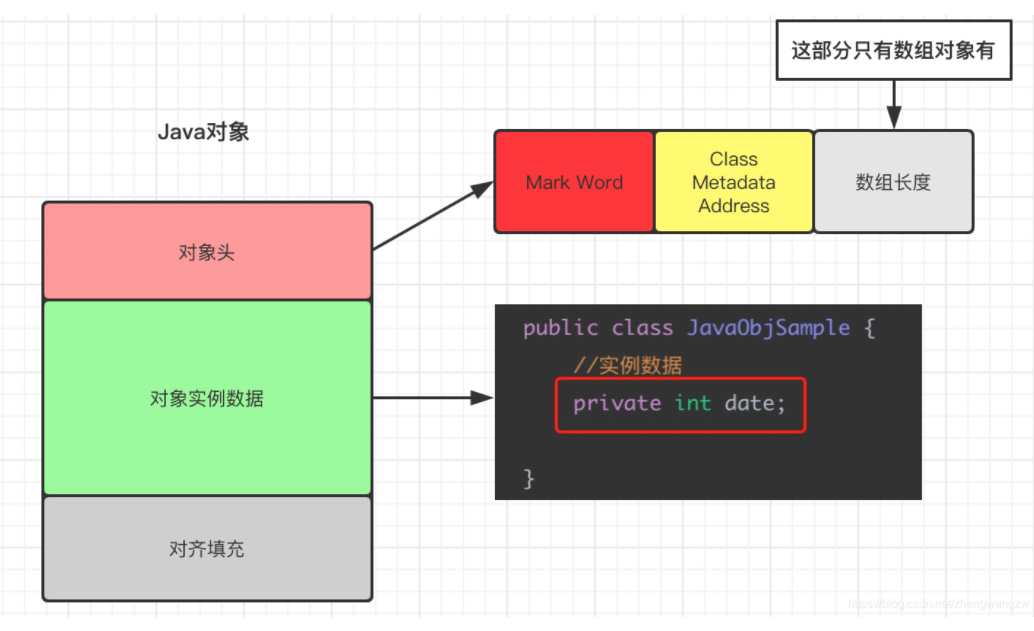
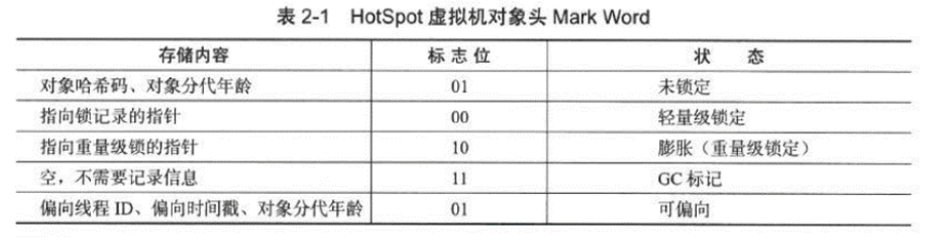
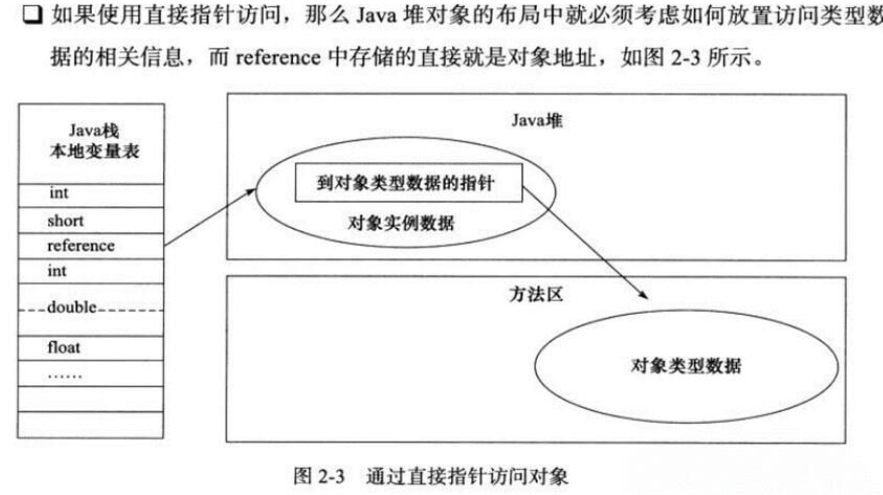
2. Object's memory layout
In the JVM, the layout of objects in memory is divided into three areas: object header, instance data and alignment fill data.

3. What the operating system does behind new hungary()
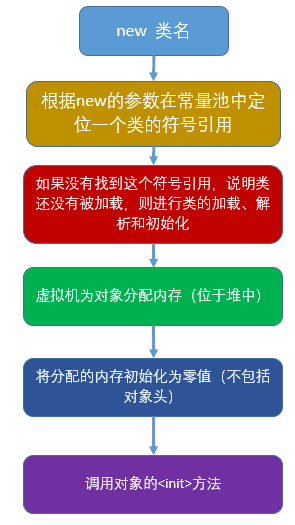
Instruction 1: allocate memory space
Instruction 2: execute the construction method and initialize the object
Instruction 3: point this object to this space
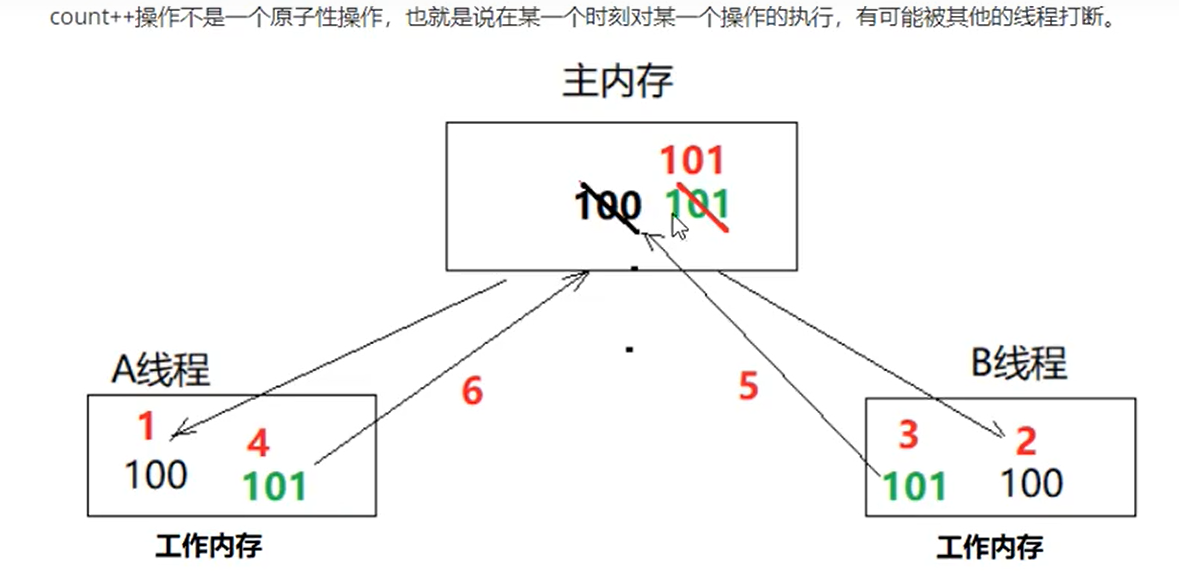
However, the cpu 132 allows such an execution order, so in the case of multithreading:

Thread A executes 132. When thread B comes, the object is initializing. At this time, the object is not empty, so it will be used.
Concurrent programming volatile
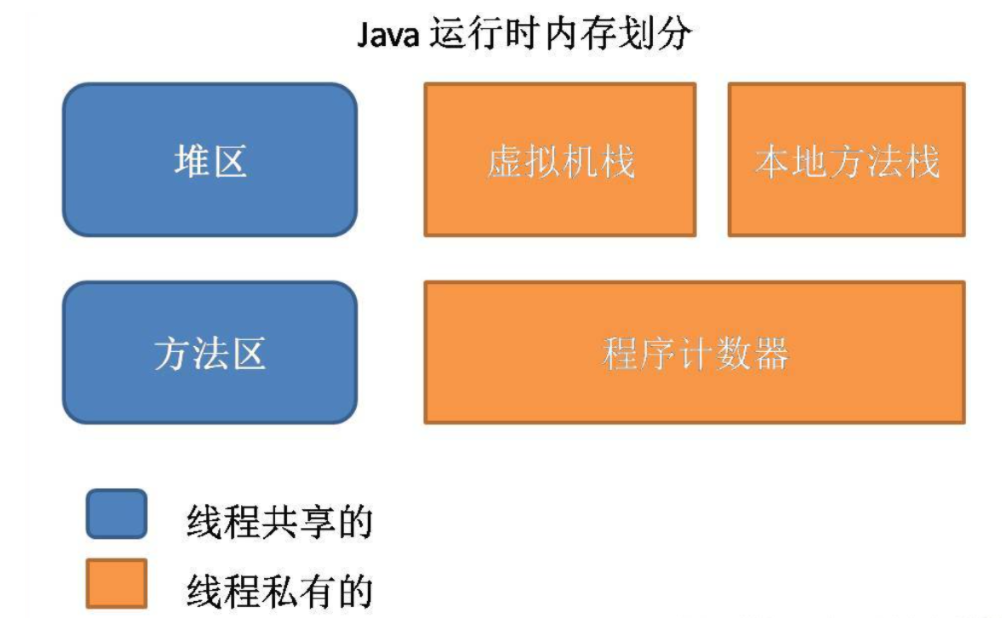
Java memory structure
The memory structure of Java is the division of memory area when learning java virtual machine.
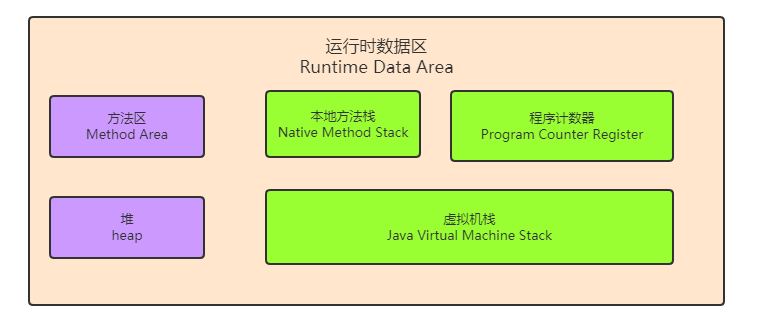
Green represents the memory area private to threads, and purple represents the memory area shared by all threads.
The Java memory structure is not expanded here. In the JVM, it is mentioned in detail to explain which areas are thread private, which are thread shared, and to distinguish them from JMM.
JMM
JMM is an underlying model mechanism of concurrent programming defined in the JVM.
JMM, the full name is Java Memory Model. Don't get confused with Java memory structure.
Java memory model is a set of specifications or rules, which should be followed by each thread. It is used to solve the communication problem in threads.
JMM is a specification and an abstract concept. It does not really exist. The memory structure is real.
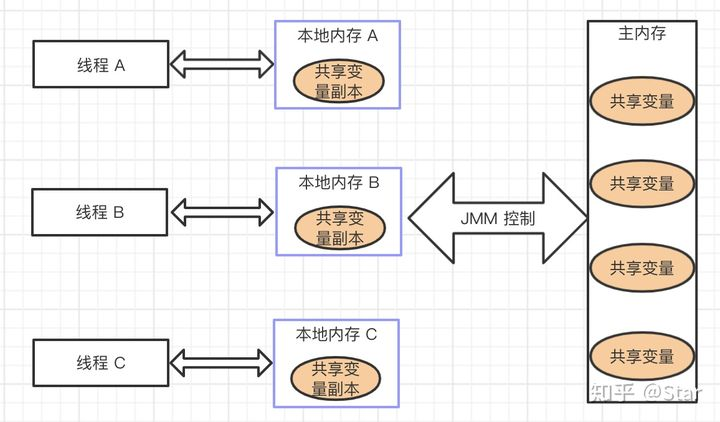
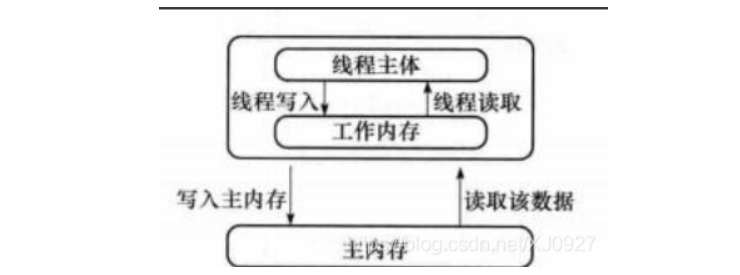
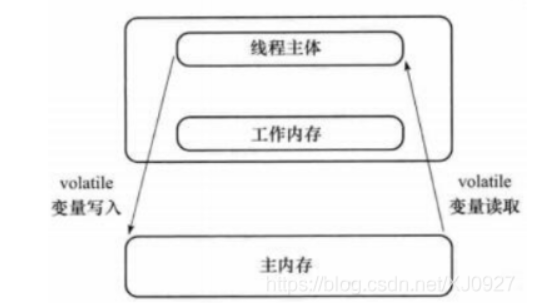
Before explaining JMM, we need to understand two concepts, main memory and working memory.
Main memory
The main memory is where the Java runtime stores data on the computer and is shared by all threads. If multiple threads modify the main memory at the same time, there will be many problems. This is the problem of concurrent operation, which needs to be solved.
Working memory
Each thread has a place to store data, which is used to store the data that the thread needs to operate. Why?
Because the thread cannot directly modify the data in the main memory, it can only modify the data in the working memory of the thread. Therefore, when the thread modifies the data in the main memory, it will save the data in the main memory in its own working memory and then operate.
In this way, there will be a problem. Each thread will operate on its own working memory, so each thread cannot know what the data in the working memory of other threads is. This is a visibility problem.
Abstract structure of JMM
Provisions of JMM:
-All shared variables are stored in main memory. The variables mentioned here refer to instance variables and class variables, excluding local variables. Because local variables are private to threads, there is no competition problem.
- Each thread also has its own working memory. The working memory of the thread retains the working copy of the variables used by the thread.
- All operations (reading and fetching) of a thread on variables must be completed in the working memory, rather than directly reading and writing variables in the main memory.
- Different threads cannot directly access the variables in each other's working memory. The value of variables between threads needs to be transferred through main memory.
The following are the eight operations that JMM will perform when operating on main memory data. (in order)
-
1,lock
Identify the data variable in main memory as thread exclusive state, that is, lock the variable, and other threads cannot operate on it. -
2,read
Read the variables that need to be modified in the main memory, that is, the last variables that have been locked. -
3,load
Load the read data variable into the working memory of the thread.
-
4,use
Transfer the variable in the working memory to the execution engine, that is, operate on the variable.
-
5,assign
After the execution engine operates on the variable, put the value of the variable back into the working memory. -
6,store
Store the variables in the thread working memory. -
7,write
Write the above stored variables into the main memory to refresh the values in the main memory. -
8,unlock
Release the lock of this variable so that it can be operated by other threads.
Three features of JMM
Java memory model is a set of rules to solve the problems of visibility, atomicity and ordering in shared data.
That is, JMM exists to ensure these three features. Now let's take a look at these three features.
visibility
Visibility was also mentioned when we talked about working memory just now. This is actually very easy to understand. After the working memory in each thread is modified and written back to the main memory, other threads can see the value in the main memory change, so as to solve some cache inconsistencies.
Atomicity
Atomicity means that an operation cannot be interrupted during execution. It is a bit similar to the atomicity of a transaction. It is either completed successfully or failed directly.
Order
Orderliness means that JMM will ensure that operations are executed in an orderly manner. Some people may wonder, aren't all procedures executed in an orderly manner?
This is about the instruction rearrangement of the processor, which involves some assembly knowledge, so I don't expand it much. Let's have a general understanding.
In order to improve CPU utilization, the processor will rearrange and optimize instructions during program compilation and execution, which is generally divided into the following three.
- Compiler optimized rearrangement
- Instruction parallel rearrangement
- Rearrangement of memory system
Instruction rearrangement makes the statements not necessarily executed from top to bottom, but may be executed out of order. Some statements will maintain the sequence only if they have data dependency.
Why doesn't it feel like a single thread?
This is because instruction rearrangement will not interfere with the results of single thread execution, but there will be some problems in disordered execution in multithreading, resulting in different results.
Variable invisibility under multithreading
The provisions of JMM may cause the thread's modification of shared variables not to be updated to the main memory immediately, or the thread is not able to synchronize the latest value of shared variables to the working memory immediately, so that when the thread uses the value of shared variables, the value is not the latest.
Memory visibility
Memory visibility means that when A thread modifies the value of A variable, other threads can always know the change of the variable. That is, if thread A modifies the value of shared variable V, thread B can immediately read the latest value of V when using the value of V.
package com.zbz.Design mode;
public class visibility {
public static void main(String[] args) {
MyThread th=new MyThread();
th.start();
while (true){
if(th.isFlag()){//th. flag=true is set 1 s after the start sub thread is started
//The main thread is always in the while loop, but it cannot enter the if
System.out.println("get into while---");
}
}
}
}
class MyThread extends Thread{
private boolean flag=false;
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
@Override
public void run() {
//Simulate the time spent executing other code before flag=true
try {
Thread.sleep(1000);//1s
} catch (InterruptedException e) {
e.printStackTrace();
}
flag=true;
System.out.println("flag="+flag);
}
}
Solutions to visibility problems
How do we ensure the visibility of shared variables under multithreading? That is, when a thread modifies a value, it is visible to other threads.
There are two schemes: locking and using volatile keyword.
Locked synchronized:
package com.zbz.Design mode;
public class visibility {
public static void main(String[] args) {
MyThread th=new MyThread();
th.start();
while (true){
//**Here you should have a question: why is the memory visibility of variables guaranteed after locking**
synchronized(th) {//Lock
if (th.isFlag()) {//th. flag=true is set 1 s after the start sub thread is started
System.out.println("get into while---");
}
}
}
}
}
class MyThread extends Thread{
private boolean flag=false;
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
@Override
public void run() {
//Simulate the time spent executing other code before flag=true is executed
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag=true;
System.out.println("flag="+flag);
}
}
Here you should have a question: why is the memory visibility of variables guaranteed after locking?
Because when a thread enters the synchronized code block,
The thread acquires the lock,
Will clear the local memory,
Then copy the latest value of the shared variable from the main memory to the local memory as a copy,
Execute the code and refresh the modified copy value into main memory,
Finally, the thread releases the lock.
In addition to synchronized, other locks can also ensure the memory visibility of variables.
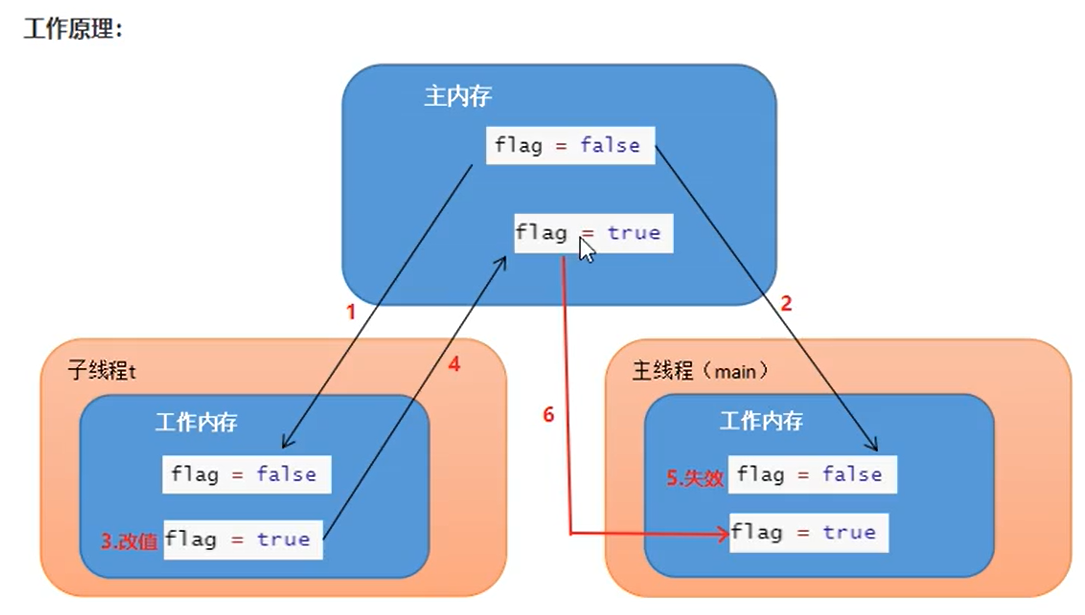
Use volatile keyword
After using volatile to modify shared variables, when each thread wants to operate variables
The variable will be copied from the main memory to the local memory as a copy. When the thread operates the variable copy and writes it back to the main memory, it will inform other threads through the CPU bus sniffing mechanism that the variable copy has expired and needs to be read from the main memory again.
Volatile ensures the visibility of different threads to shared variable operations, that is, when a thread modifies the variable modified by volatile, when the modified variable is written back to main memory, other threads can immediately see the latest value.

package com.zbz.Design mode;
public class visibility {
public static void main(String[] args) {
MyThread th=new MyThread();
th.start();
while (true){
if (th.isFlag()) {//th. flag=true is set 1 s after the start sub thread is started
//The main thread is always in the while loop, but it cannot enter the if
System.out.println("get into while---");
}
}
}
}
class MyThread extends Thread{
private volatile boolean flag=false; //volatile keyword
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
@Override
public void run() {
//Simulate the time spent executing other code before flag=true
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag=true;
System.out.println("flag="+flag);
}
}
Bus sniffing mechanism
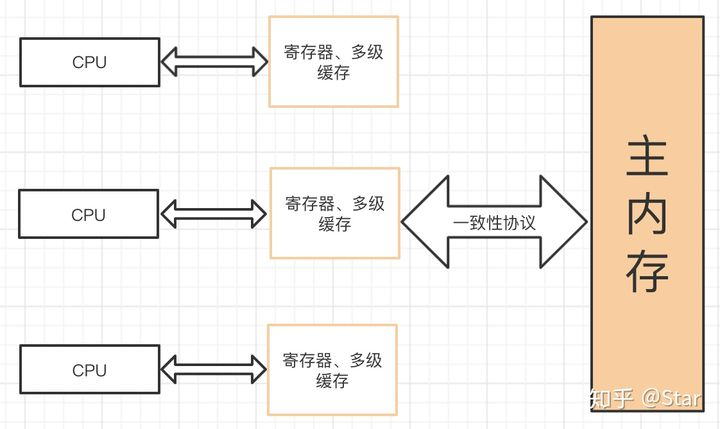
In order to improve the processing speed, the CPU does not directly communicate with the memory, but adds many registers and multi-level caches between the CPU and the memory, which are much higher than the access speed of the memory. In this way, the inconsistency between the CPU operation speed and the memory reading speed is solved.
Since the cache is added between the CPU and the memory, the data is copied from the memory to the cache before data operation. The CPU directly operates the data in the cache. However, in multiprocessors, it may lead to inconsistent cache data (which is also the origin of the visibility problem). In order to ensure that the cache of each processor is consistent, the cache consistency protocol will be implemented, and sniffing is a common mechanism to achieve cache consistency.
Processor memory model
Note that the cache consistency problem is not caused by multiprocessors, but by multiple caches.
Working principle of sniffing mechanism: each processor checks whether its cache value is expired by listening to the data transmitted on the bus. If the processor finds that the memory address corresponding to its cache line is modified, it will set the current processor's cache line to invalid state. When the processor modifies this data, The data will be re read from main memory to the processor cache.
Note: Based on the CPU cache consistency protocol, the JVM realizes the visibility of volatile. However, due to the bus sniffing mechanism, it will constantly monitor the bus. If volatile is widely used, it will cause a bus storm. Therefore, the use of volatile should be suitable for specific scenarios.
Summary of visibility issues
In the above example, we can see that using volatile and synchronized locks can ensure the visibility of shared variables. Compared with synchronized, volatile can be regarded as a lightweight lock, so the cost of using volatile is lower, because it will not cause thread context switching and scheduling. However, volatile cannot guarantee the atomicity of operation like synchronized.
volatile atomicity problem
The so-called atomicity means that in one operation or multiple operations, either all operations are executed and will not be interrupted by any factor, or all operations are not executed.
In multi-threaded environment, volatile keyword can ensure the visibility of shared data, but it can not guarantee the atomicity of data operation. In other words, in a multithreaded environment, variables decorated with volatile are thread unsafe.
To solve the problem of thread insecurity, we can use locking mechanism or atomic class (such as AtomicInteger).
Special note:
Reading / writing to any single variable modified with volatile is atomic, but similar to flag =! Flag this kind of compound operation is not atomic. In other words, simple operability is atomic.
package com.zbz.Design mode;
//Create 100 threads, and each thread will accumulate the shared data count for 10000 times. The final result should be 100000
public class Atomicity {
public static void main(String[] args) {
Runnable target=new MyThread0();
for (int i=1;i<=100;++i){
new Thread(target,"The first"+i+"Threads").start();
}
}
}
class MyThread0 implements Runnable{
private int count=0; //Shared variable
@Override
public void run() {
for(int i=1;i<=1000;i++){
++count;
System.out.println(Thread.currentThread().getName()+"--->count: "+count);
}
}
}
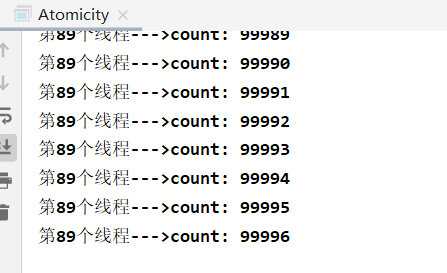
The result is that it cannot be added to 100000
Analysis: thread A and thread B both get the count. When A gets the count, the value is 100, and B also gets the count value is 100, and "modify" the count value to 101 at the same time, and overwrite it into the main memory at the same time

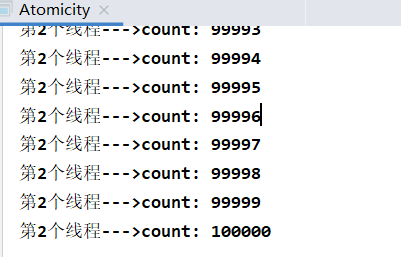
Plus volatile
The result is the same. Therefore, in a multithreaded environment, volatile keyword can ensure the visibility of shared data, but it can not guarantee the atomicity of data operations. In other words, in a multithreaded environment, variables decorated with volatile are thread unsafe.
terms of settlement
To solve the problem of thread insecurity, we can use locking mechanism or atomic class (such as AtomicInteger).
package com.zbz.Design mode;
//Create 100 threads, and each thread will accumulate the shared data count for 10000 times. The final result should be 1000000 times
public class Atomicity {
public static void main(String[] args) {
Runnable target=new MyThread0();
for (int i=1;i<=100;++i){
new Thread(target,"The first"+i+"Threads").start();
}
}
}
class MyThread0 implements Runnable{
private int count=0;
@Override
public void run() {
synchronized (MyThread0.class) { //Lock
for (int i = 1; i <= 1000; i++) {
++count;
System.out.println(Thread.currentThread().getName() + "--->count: " + count);
}
}
}
}
volatile prevents instruction reordering
Instruction reordering
In order to improve performance, the as if serial semantics must be observed (that is, no matter how reordering, the execution result of the program under single thread cannot be changed. The compiler, runtime and processor must comply with it.) In this case, compilers and processors often reorder instructions.
Generally, reordering can be divided into the following three types:
- Compiler optimized reordering. The compiler can rearrange the execution order of statements without changing the semantics of single threaded programs.
- Instruction level parallel reordering. Modern processors use instruction level parallelism technology to execute multiple instructions overlapped. If there is no data dependency, the processor can change the execution order of the machine instructions corresponding to the statements.
- Memory system reordering. Since the processor uses cache and read / write buffer, it makes the load and store operations appear to be performed out of order.
Data dependency: if two operations access the same variable and one of the two operations is a write operation, there is a data dependency between the two operations. The data dependency mentioned here only refers to the instruction sequence executed in a single processor and the operation executed in a single thread. The data dependency between different processors and between different threads is not considered by the compiler and processor.
From the Java source code to the instruction sequence finally executed, it will undergo the following three reordering:
 Reorder
Reorder
For a better understanding of reordering, please see the following part of the sample code:
int a = 0;
// Thread A
a = 1; // 1
flag = true; // 2
// Thread B
if (flag) { // 3
int i = a; // 4
}
Just look at the above program, it seems that there is no problem. The last value of i is 1.
In order to improve performance, compilers and processors often reorder instructions without changing data dependencies.
Suppose that thread A is reordered during execution: execute code 2 first, and then execute code 1;
Thread B: after thread A executes code 2, it reads the flag variable.
Since the condition is true, thread B will read variable a. At this time, the variable a has not been written by thread a at all, so the last value of i is 0, resulting in incorrect execution results.
**So how to execute the program correctly** The volatile keyword can still be used here.
In this example, using volatile not only ensures the memory visibility of variables, but also prohibits the reordering of instructions, that is, it ensures that the compiled order of variables modified by volatile is the same as the execution order of the program. Then, after modifying the flag variable with volatile, in thread A, it is ensured that the execution order of code 1 must be before code 2.
How does volatile prohibit instruction reordering?
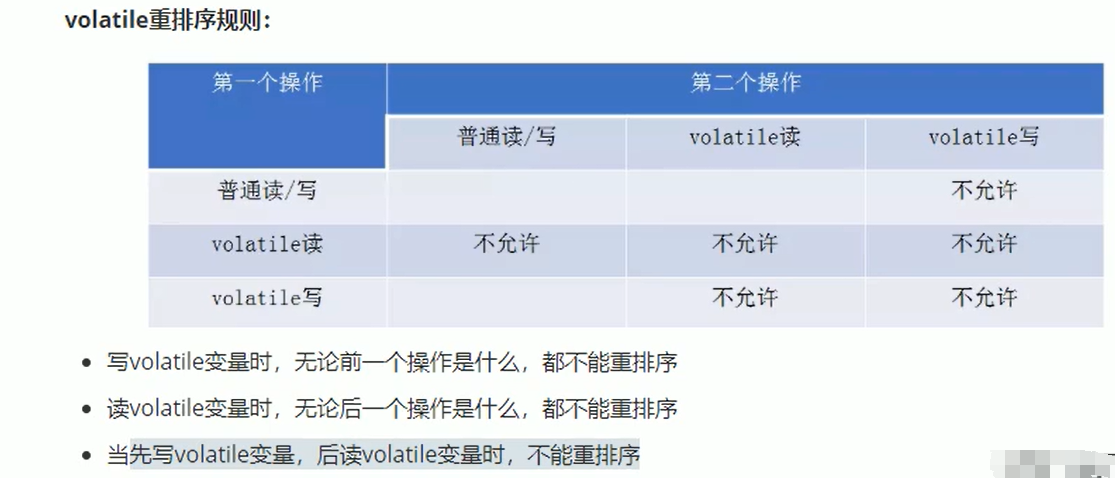
Memory barrier instruction
The compiler will not reorder volatile reads and any memory operations after volatile reads; The compiler does not reorder volatile writes and any memory operations preceding volatile writes.
Memory barrier is a set of processor instructions. Its function is to prohibit instruction reordering and solve the problem of memory visibility.
JMM divides memory barrier instructions into the following four categories:

StoreLoad barrier is an all-round barrier, which has the effect of the other three barriers at the same time. Therefore, the overhead of executing this barrier will be great, because it makes the processor flush all the data in the cache into memory.
Let's take a look at how volatile inserts the memory barrier during read / write, as shown in the following figure:

From the above figure, we can know the volatile read / write insert memory barrier rule:
- Insert the LoadLoad barrier and LoadStore barrier after each volatile read operation.
- Insert a StoreStore barrier and a StoreLoad barrier before and after each volatile write operation.
happens-before
What is happens before
Happens before does not affect instruction rearrangement. It ensures visibility on the premise of good order


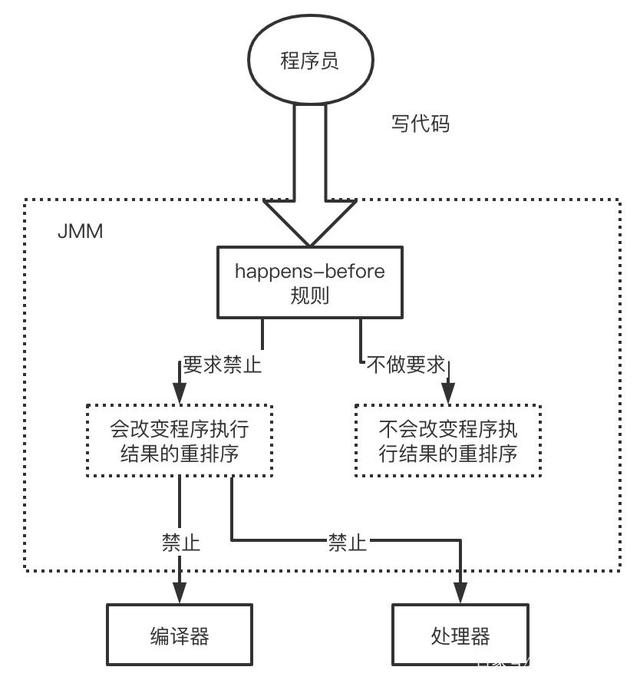
Happens before rule
**Program order rule: * * the execution result of a piece of code in a thread is orderly. It will also rearrange instructions, but whatever it is, the result will be generated in the order of our code and will not change.
**Pipe locking rules: * * for the same lock, whether in a single threaded environment or a multi-threaded environment, after one thread unlocks the lock, another thread obtains the lock, and you can see the operation results of the previous thread! (pipe pass is a general synchronization primitive, and synchronized is the implementation of pipe pass)
**The thread reads this variable first, and then writes it to the variable of this variable.

**Thread startup rules: * * if the child thread B is started during the execution of main thread A, the modification results of shared variables made by thread A before starting child thread B will be visible to thread B. (Note: however, the modification results of shared variables after thread A are not necessarily visible to thread b)
**Thread termination rules: * * when sub thread B terminates during the execution of main thread A, the modification results of shared variables made by thread B before termination are visible in thread A. Also known as thread join() rule.
Thread interrupt rule: the call to the thread interrupt() method occurs first when the interrupt event is detected by the interrupted thread code. You can use thread Interrupted() detected whether an interrupt occurred.
**Transitivity rule: * * this simple is that the happens before principle is transitive, that is, hb(A, B), hb(B, C), then hb(A, C).
**Object termination rule: * * this is also simple, that is, the completion of the initialization of an object, that is, the end of the constructor execution must happen before its finalize() method.
volatile write read build happens before
Question:
package com.zbz.Design mode;
public class HappensBefore {
private int a=1;
private int b=2;
public void write(){
a=3;
b=a;
}
public void read(){
System.out.println("b="+b+",a="+a);
}
public static void main(String[] args) {
HappensBefore hb=new HappensBefore();
new Thread(new Runnable() {//Thread 1
@Override
public void run() {
hb.write();//write
}
}).start();
new Thread(new Runnable() {//Thread 2
@Override
public void run() {
hb.read();//read
}
}).start();
}
}


package com.zbz.Design mode;
public class HappensBefore {
private int a=1;
private volatile int b=2; //Add volatile keyword
public void write(){
a=3;
b=a;
}
public void read(){
System.out.println("b="+b+",a="+a);
}
public static void main(String[] args) {
HappensBefore hb=new HappensBefore();
while(true){
new Thread(new Runnable() {
@Override
public void run() {
hb.write();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
hb.read();
}
}).start();
}
}
}
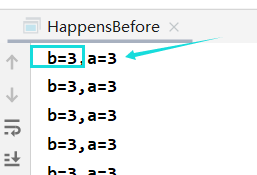
b is written to a=3, and all operations before b are visible: a=3 is visible.
Lazy style
package com.zbz.Design mode;
//Lazy single case design mode
public class LazyMan {
//private prevents classes from being instantiated externally
private LazyMan(){
}
private static LazyMan lazyMan;
private static LazyMan getInstance(){
if(lazyMan==null){
lazyMan=new LazyMan();
}
return lazyMan;
}
public static void main(String[] args) {
LazyMan instance =LazyMan.getInstance();
LazyMan instance0=LazyMan.getInstance();
System.out.println(instance);
System.out.println(instance0);
}
}
result:
com.zbz.Design mode.LazyMan@10f87f48 com.zbz.Design mode.LazyMan@10f87f48
Reflection destruction single example
Terminator of singleton mode:
declaredConstructor.setAccessible(true);//Set not to perform permission checking when using the constructor
package com.zbz.Design mode;
import java.lang.reflect.Constructor;
//Lazy single case design mode
public class LazyMan {
//private prevents classes from being instantiated externally
private LazyMan(){
}
//Lazy singleton. A singleton object will be instantiated only when getInstance is called
//But ah, but the reflection is very strong!!!
private static volatile LazyMan lazyMan;
private static LazyMan getInstance(){
if(lazyMan==null){
lazyMan=new LazyMan();
}
return lazyMan;
}
public static void main(String[] args) throws Exception {
LazyMan instance =LazyMan.getInstance();
//LazyMan instance0=LazyMan.getInstance();
Constructor<LazyMan> declaredConstructor=LazyMan.class.getDeclaredConstructor(null);//Nonparametric structure
declaredConstructor.setAccessible(true);//Set not to perform permission checking when using the constructor
LazyMan instance1=declaredConstructor.newInstance();//Create an object instance with a parameterless construct
//Since there is no permission check, you can also create objects outside the Lazyman class and then execute methods
//Observe the console, the private constructor is called again, the singleton mode is captured, and the execution method is successful
System.out.println(instance);
System.out.println(instance1);
}
}
The results are:
com.zbz.Design mode.LazyMan@10f87f48 com.zbz.Design mode.LazyMan@b4c966a
The hash values are different, which proves to be two different instances, so the singleton mode is destroyed
Reason for adding volatile keyword to attribute lazyman:
lazyMan=new LazyMan(); Instead of atomic operation, the JVM will be broken down into the following commands:
1 allocate space to objects
2 initialization object
3 associate the initialization object with the memory address
There is no problem to execute in the above decomposition order (1 - > 2 - > 3), but due to the existence of JVM compilation optimization, steps 2 and 3 may be reversed, that is, execute in the order of 1 - > 3 - > 2 (this is instruction reordering). Execute in the order of 1 - > 3 - > 2. When executing getInstance in a multithreaded environment, it is possible that lazyMan has been associated with the initial object memory, but the object has not been initialized, that is, lazyMan when executing if (lazyMan == null)= Null directly returns the lazyMan that has not been initialized, resulting in an error when using the lazyMan instance again.
volatile keyword is a way to solve the problem of instruction reordering
You can also use the lock synchronized:
volatile can be understood as a lightweight lock
public static LazyMan getInstance(){
if(lazyMan==null){
synchronized (LazyMan.class){
if(lazyMan==null){
lazyMan = new LazyMan();
}
}
}
return lazyMan;
}
Review Java constructor
Constructor properties:
1. If there is no constructor defined in our class, the system will provide us with a parameterless constructor by default.
2. If a constructor is defined in our class, the system will no longer provide us with a default parameterless constructor.
==Function: = = build and create an object. At the same time, we can do an initialization operation for our properties.
Here are the differences between constructors and methods:
1. Different functions and functions
Constructor is to create an instance of a class. It is used to create an object and initialize properties at the same time. This process can also be used when creating an object: Platypus p1 = new Platypus();
On the contrary, the function of the method is only a function function, in order to execute java code.
2. Modifier, return value and naming are different
Constructors and methods have three convenient differences: modifiers, return values, and naming. Like methods, constructors can have any access modifier: public, protected, private Or not decorated (usually by package and friendly Call). Unlike methods, constructors cannot have the following non access modifications: abstract, final, native, static, perhaps synchronized.
3. Return type
Method must have a return value and can return any type of value or no return value( void),The constructor has no return value and does not require void.
4. Naming
Constructors use the same name as classes, but methods are different. By convention, methods usually start with lowercase letters, while constructors usually start with uppercase letters. Constructor is usually a noun because it is the same as the class name; A method is usually closer to a verb because it describes an operation.
5. Call:
Construction method: it will only be called when the object is created, and it will only be called once. General method: it can only be called after the object is created, and it can be called multiple times.
6. Usage of "this"
Constructors and methods use keywords this There is a big difference. Method reference this Points to an instance of the class that is executing the method. Static methods cannot be used this Keyword, because the static method does not belong to the instance of the class, so this There is nothing to point to. Constructor this Point to another constructor of different parameter lists in the same class
Single case mode is broken. Solution 1:
package com.zbz.Design mode;
import java.lang.reflect.Constructor;
//Lazy single case design mode
public class LazyMan {
private static int count=0; //Controlled by static count variable
//private prevents classes from being instantiated externally
private LazyMan(){
System.out.println("The constructor was called"+(++count)+"second");
if(count>1){
throw new RuntimeException("Singleton constructors cannot be reused");
}
}
private static volatile LazyMan lazyMan;
private static LazyMan getInstance(){
if(lazyMan==null){
lazyMan=new LazyMan();
}
return lazyMan;
}
public static void main(String[] args) throws Exception {
LazyMan instance =LazyMan.getInstance();
//LazyMan instance0=LazyMan.getInstance();
Constructor<LazyMan> declaredConstructor=LazyMan.class.getDeclaredConstructor(null);
declaredConstructor.setAccessible(true);
LazyMan instance1=declaredConstructor.newInstance();
System.out.println(instance);
System.out.println(instance1);
}
}

But it can still be broken by reflection:
package com.zbz.Design mode;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
//Lazy single case design mode
public class LazyMan {
private static int count=0;
//private prevents classes from being instantiated externally
private LazyMan(){
System.out.println("The constructor was called"+(++count)+"second");
if(count>1){
throw new RuntimeException("Singleton constructors cannot be reused");
}
}
private static volatile LazyMan lazyMan;
private static LazyMan getInstance(){
if(lazyMan==null){
lazyMan=new LazyMan();
}
return lazyMan;
}
public static void main(String[] args) throws Exception {
//LazyMan instance =LazyMan.getInstance();
//LazyMan instance0=LazyMan.getInstance();
Constructor<LazyMan> declaredConstructor=LazyMan.class.getDeclaredConstructor(null);
declaredConstructor.setAccessible(true);
//Reflection: constructor instantiation instance2
LazyMan instance2=declaredConstructor.newInstance();
//Get field
Field count=LazyMan.class.getDeclaredField("count");
//Destroy the private attribute of the variable count
count.setAccessible(true);
//After instance2 is instantiated, the static count of instance2 is copied back to 0
count.set(instance2,0);
//Instantiate the object through the reflection constructor. At this time, the count has been reset to 1
LazyMan instance1=declaredConstructor.newInstance();
System.out.println(instance2);
System.out.println(instance1);
}
}
In java, when a class is just loaded, all class information is placed in the method area, including static
Differences between static attributes and non static attributes:
1. The storage location is different in memory. All attributes or methods with static modifier are stored in the method area in memory, rather than static attributes in the heap area in memory
2. The occurrence time is different. The static property or method already exists before the object is created, while the non static property only exists after the object is created
3. Static properties are shared by all objects in a class
4. For different lifecycles, static attributes are destroyed after the class disappears, while amorphous attributes are destroyed after the object is destroyed
5. Usage:
a. Static properties can be accessed directly through the class name. Non static properties cannot be accessed directly through the class, but only through the object
b. The same thing between the two is that they can be used after creating objects. The following static attribute is that all objects in a class are shared. The final result is 20
Static inner class implementation
code
1. Static members are not allowed to be defined in non static internal classes
Non static class members can not be used directly
3. Static internal classes cannot access instance members of external classes, but only class members of external classes
package com.zbz.Design mode;
//Static inner classes implement singleton mode
public class Holder {
//Singleton mode: constructor private
private Holder(){
}
//Static members of external classes cannot directly use non static internal classes
public static Holder getInstance(){
return InnerClass.HOLDER;
}
//Static inner class
public static class InnerClass{
private static final Holder HOLDER=new Holder();
}
}
But it can still be destroyed by reflection
Enumeration implementation
package com.zbz.Design mode;
//Enumeration implementation singleton mode can not be destroyed by reflection
//Enumeration is essentially a class
public enum EnumSingle {
INSTANCE;//example
public static EnumSingle getInstance(){
return INSTANCE;
}
public static void main(String[] args) {
EnumSingle ins1=EnumSingle.INSTANCE;
EnumSingle ins2=EnumSingle.getInstance();
System.out.println(ins1);
System.out.println(ins2);
}
}
Output:
1. We tried to destroy by reflection:
package com.zbz.Design mode;
import java.lang.reflect.Constructor;
//Enumeration implementation singleton mode can not be destroyed by reflection
//Enumerations are essentially classes
public enum EnumSingle {
INSTANCE;//example
public static EnumSingle getInstance(){
return INSTANCE;
}
public static void main(String[] args) throws Exception {
EnumSingle ins1=EnumSingle.INSTANCE;
//Instantiate objects by reflection
Constructor<EnumSingle> declaredConstructor = EnumSingle.class.getDeclaredConstructor();//Nonparametric structure
declaredConstructor.setAccessible(true);
EnumSingle ins2 = declaredConstructor.newInstance();
System.out.println(ins1);
System.out.println(ins2);
}
}
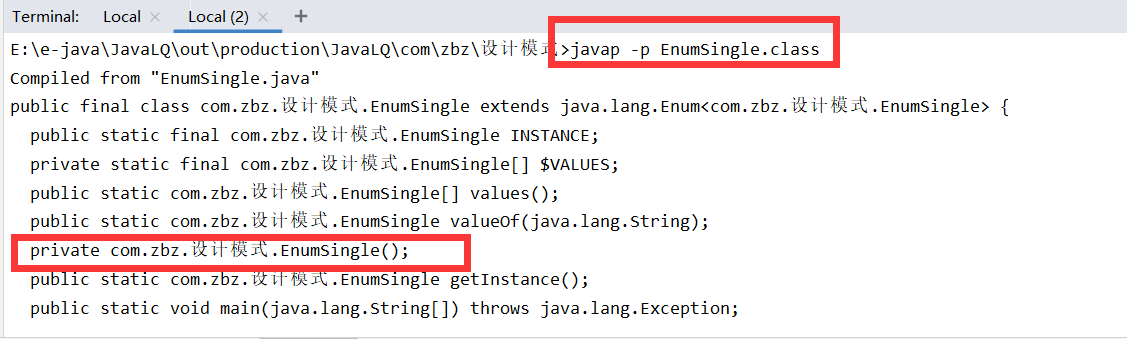
2. Through the decompilation of jdk, we found that there is a parameterless structure:


3. So we have a question? Can't you instantiate an object through nonparametric construction?
So we use a professional decompile tool JAD exe:
We're going to take JAD Exe file in class file under the same level directory
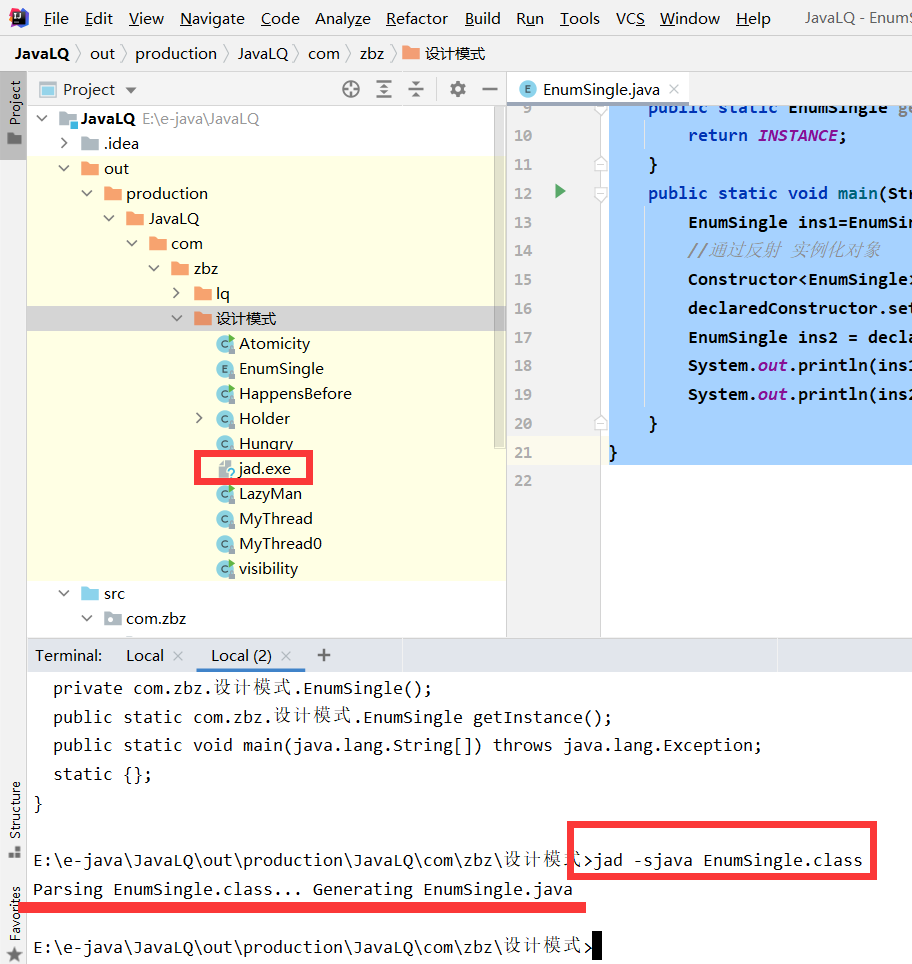
4. So we found that there are only parameter structures in the source code:
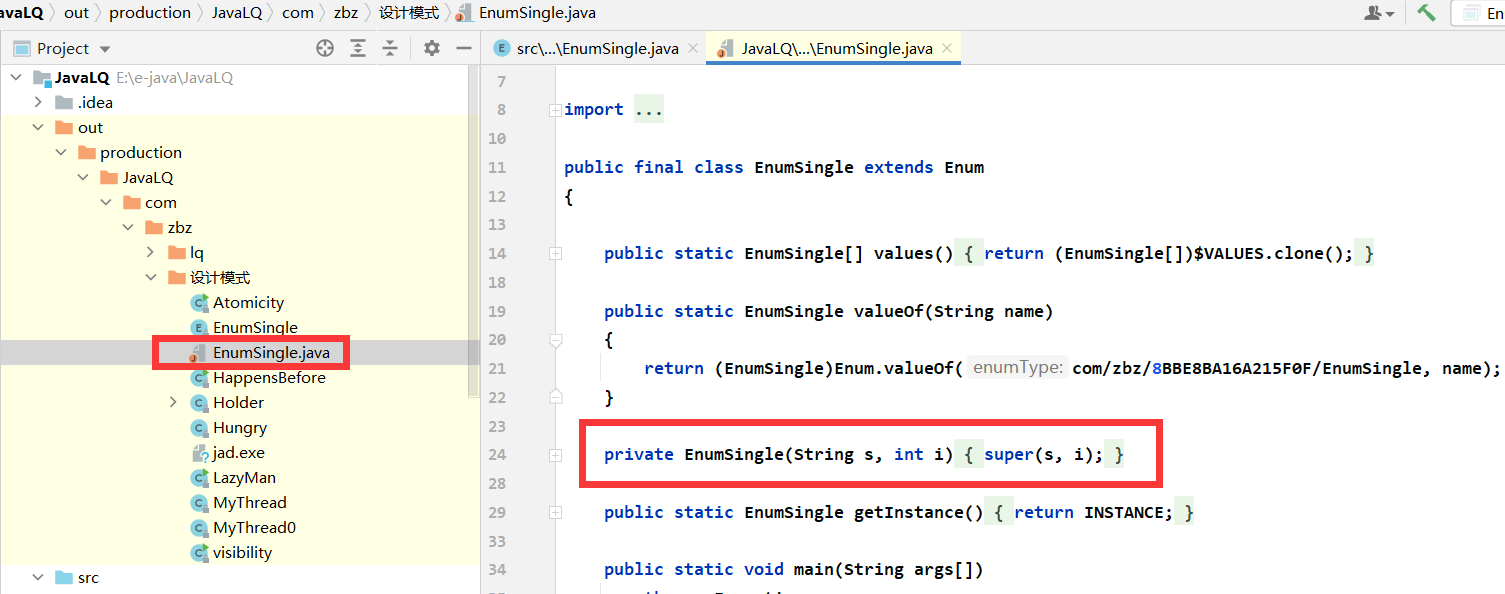
So we use reflection to destroy again:
package com.zbz.Design mode;
import java.lang.reflect.Constructor;
//Enumeration implementation singleton mode can not be destroyed by reflection
//Enumerations are essentially classes
public enum EnumSingle {
INSTANCE;//example
public static EnumSingle getInstance(){
return INSTANCE;
}
public static void main(String[] args) throws Exception {
EnumSingle ins1=EnumSingle.INSTANCE;
//Instantiate objects by reflection
Constructor<EnumSingle> declaredConstructor = EnumSingle.class.getDeclaredConstructor(String.class,int.class);//Parametric structure
declaredConstructor.setAccessible(true);
EnumSingle ins2 = declaredConstructor.newInstance();
System.out.println(ins1);
System.out.println(ins2);
}
}

5. Prove that reflection cannot destroy enumeration implementation singleton mode
Finally: summary and application scenarios
realization Singleton mode The idea is
A class can return an object, a reference (always the same) and a method to obtain the instance (it must be a static method, usually using the name getInstance); When we call this method, if the reference held by the class is not empty, we will return this reference. If the reference held by the class is empty, we will create an instance of the class and give the instance reference to the reference held by the class; At the same time, we also define the constructor of this class as a private method, so that the code in other places cannot instantiate the object of this class by calling the constructor of this class, and only the static method provided by this class can get the unique instance of this class.
Points needing attention:
Singleton mode must be used with caution in multithreaded applications. If two threads call the creation method at the same time when the unique instance has not been created, they do not detect the existence of the unique instance at the same time, so they create an instance at the same time. In this way, two instances are constructed, which violates the principle of unique instance in singleton mode. The solution to this problem is to provide a mutex for variables indicating whether the class has been instantiated (although this will reduce efficiency).
advantage:
1. In the singleton mode, there is only one instance of an active singleton, and all instantiations of the singleton class get the same instance. This prevents other objects from instantiating themselves and ensures that all objects access one instance
2. The singleton mode has certain scalability. The class controls the instantiation process by itself, and the class has corresponding scalability in changing the instantiation process.
3. Provides controlled access to a unique instance.
4. Because there is only one object in the system memory, it can save system resources. When objects need to be created and destroyed frequently, the singleton mode can undoubtedly improve the performance of the system.
5. Allow variable instances.
6. Avoid multiple occupation of shared resources.
Disadvantages:
1. It is not applicable to changing objects. If objects of the same type always change in different use case scenarios, a single instance will cause data errors and cannot save each other's states.
2. Since there is no abstraction layer in the simple interest mode, it is very difficult to expand the singleton class.
3. The responsibility of single instance is too heavy, which violates the "principle of single responsibility" to a certain extent.
4. Abusing singleton will bring some negative problems. For example, in order to save resources, designing database connection pool objects as singleton classes may lead to too many programs sharing connection pool objects and connection pool overflow;
If the instantiated object is not used for a long time, the system will consider it as garbage and be recycled, which will lead to the loss of object state.
Precautions for use
1. When using, you cannot create a singleton with reflection mode, otherwise a new object will be instantiated
2. Pay attention to thread safety when using lazy singleton mode
3. Both hungry singleton mode and lazy singleton mode construction methods are private, so they cannot be inherited. Some singleton modes can be inherited (such as registration mode)
Applicable scenario
Singleton mode allows only one object to be created, which saves memory and speeds up object access. Therefore, objects need to be suitable for public occasions, such as multiple modules using the same data source to connect objects, etc. For example:
1. Objects that need to be instantiated frequently and then destroyed.
2. Objects that take too much time or resources to create but are often used.
3. Stateful tool class objects.
4. Objects that frequently access databases or files.
The following are classic usage scenarios of singleton mode:
1. In the case of resource sharing, avoid performance or loss caused by resource operation. As the log file in the above, apply the configuration.
2. In the case of controlling resources, facilitate the communication between resources. Such as thread pool.
Examples of application scenarios:
1. External resources: each computer has several printers, but only one PrinterSpooler to avoid two print jobs being output to the printer at the same time. Internal resources: most software has one (or more) property files to store the system configuration. Such a system should have an object to manage these property files
2. Windows of Task Manager(Task manager) is a typical singleton mode (this is familiar). Think about it. Can you open two windows task manager Are you? If you don't believe it, try it yourself~ 3. windows of Recycle Bin(Recycle bin) is also a typical single case application. During the operation of the whole system, the recycle bin has maintained only one instance.
- The counter of the website is generally implemented in the single instance mode, otherwise it is difficult to synchronize.
- The log application of the application is generally implemented in the single instance mode. This is generally because the shared log file is always open, because there can only be one instance to operate, otherwise the content is not easy to add.
- The singleton mode is generally applied to the reading of configuration objects of Web applications because the configuration file is a shared resource.
- The design of database connection pool generally adopts single instance mode, because database connection is a kind of database resource. The use of database connection pool in database software system is mainly to save the efficiency loss caused by opening or closing database connection. This efficiency loss is still very expensive, because it can be greatly reduced by using singleton mode for maintenance.
- The design of multithreaded thread pool generally adopts single instance mode, because the thread pool should facilitate the control of threads in the pool.
- The file system of the operating system is also a specific example of the implementation of large singleton mode. An operating system can only have one file system.
- HttpApplication is also a typical application of unit example. Familiar with ASP Net (IIS) throughout the request life cycle, people should know that HttpApplication is also a singleton mode, and all HttpApplication modules share an HttpApplication instance
Principle and process of realizing simple profit mode:
1. Singleton mode: ensure that a class has only one instance, instantiate it by itself and provide this instance to the system
2. Singleton pattern classification: hungry singleton pattern (instantiating an object to give its own reference when the class is loaded), lazy singleton pattern (instantiating the object only when calling the method to obtain the instance, such as getInstance) (the performance of hungry singleton pattern in java is better than that of lazy singleton pattern, and lazy singleton pattern is generally used in c + +)
3. Elements of single case mode:
a. Private construction method
b. Private static references point to their own instances
c. Public static method with its own instance as return value