1, Redis Sentinel
1. Introduction
Redis sentinel is a high availability solution officially recommended by redis. When redis is used as the high availability of the master slave, if the master itself goes down, redis itself or the client does not realize the function of master-slave switching.
Redis sentinel is an independent process, which is used to monitor multiple master slave clusters, automatically find master downtime and automatically switch slave > master.
sentinel's main functions are as follows:
1. Monitor whether redis is running well from time to time. If the node is unreachable, it will be offline identified. 2. If the identified primary node is, sentinel will "negotiate" with other sentinel nodes. If other nodes also think that the primary node is unreachable, they will elect a sentinel node to complete automatic failover. 3. After the master slave is switched, the master will_ redis.conf,slave_ The contents of redis.conf and sentinel.conf will change, that is, master_ There will be one more line of slaveof configuration in redis.conf, and the monitoring targets of sentinel.conf will be changed accordingly
2. Working principle
Each Sentinel sends a PING command to its known Master, Slave and other Sentinel instances once a second
If the time of an instance from the last valid reply to the PING command exceeds the value specified by the down after milliseconds option, the instance will be marked as offline by Sentinel.
If a Master is marked as subjective offline, all sentinels monitoring the Master should confirm that the Master has indeed entered the subjective offline state once per second.
When a sufficient number of sentinels (greater than or equal to the value specified in the configuration file) confirm that the Master has indeed entered the subjective offline state within the specified time range, the Master will be marked as objective offline
In general, each Sentinel will send INFO commands to all known masters and Slave every 10 seconds
When the Master is marked as objectively offline by Sentinel, the frequency of Sentinel sending INFO commands to all Slave of the offline Master will be changed from once in 10 seconds to once per second
If not enough Sentinel agree that the Master has been offline, the objective offline status of the Master will be removed.
If the Master returns a valid reply to Sentinel's PING command again, the Master's subjective offline status will be removed.
Subjective offline and objective offline
Subjective offline: Subjectively Down, SDOWN for short, refers to the offline judgment made by the current Sentinel instance on a redis server. Objective logoff: Objectively Down, referred to as ODOWN for short, refers to the Master Server logoff judgment obtained by multiple Sentinel instances after making SDOWN judgment on the Master Server and communicating with each other through the Sentinel is master down by addr command, and then start failover
SDOWN is suitable for Master and Slave. As long as a Sentinel finds that the Master has entered ODOWN, the Sentinel may be selected by other sentinels and perform automatic fault migration for the offline Master server.
ODOWN is only applicable to the Master. For the Redis instances of Slave, Sentinel does not need to negotiate before judging them as offline, so Slave Sentinel will never reach ODOWN.
3. master downtime handling
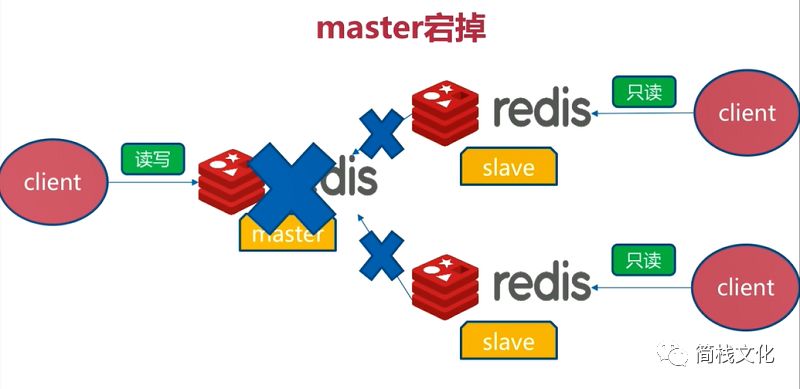
img
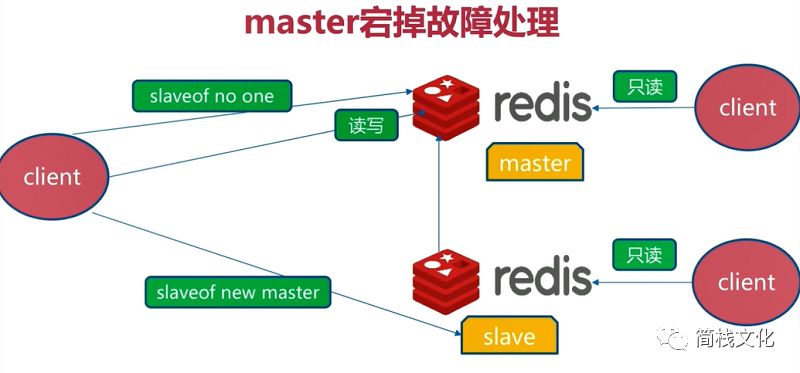
img
If the Master goes down, we should first select a slave and make it a new master. Other redis are modified to the slave of the new master, but neither redis nor the client can realize the master-slave switching function. Of course, it is also possible to manually modify the configuration file to realize the functions shown in the figure above, but if it is late at night, everyone goes to bed, Who will modify the configuration information? At this time, you can use the Sentinel function of redis. When the master is found to be down, it will automatically help us modify other redis configuration files and elect a new master.
4. Sentinel function realization diagram

img

img

img
5. redis some viewing commands
redis-cli info # View redis database information redis-cli info replication # View the replication authorization information of redis (master-slave replication) redis-cli info sentinel # View the sentinel information of redis
6. Redis master-slave configuration
1.Prepare three redis Instance, one master and two slaves # redis-6379.conf configuration port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/redis/data/" # redis-6380.conf configuration port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 # redis-6381.conf configuration port 6381 daemonize yes logfile "6381.log" dbfilename "dump-6381.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 2. Prepare three database instances and start three database instances # Remember to create a folder for redis data storage before startup mkdir -p /var/redis/data/ # Start instance redis-server redis-6379.conf redis-server redis-6380.conf redis-server redis-6381.conf # Check whether the redis service has been started ps -ef | grep redis 3. Determine the master-slave relationship redis-cli -p 6379 info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=336,lag=0 slave1:ip=127.0.0.1,port=6381,state=online,offset=336,lag=1 redis-cli -p 6380 info replication # Replication role:slave master_host:127.0.0.1 master_port:6379
7. Redis Sentinel installation configuration
1. Sentinel Configuration resolution
port 26379 // Sentinel port
dir /var/redis/data/ // Sentinel log file storage location
logfile "26379.log" // Sentinel log file name
// The Sentinel node currently monitors the primary node 127.0.0.1:6379
// 2 means that it is failed to judge the primary node. At least 2 Sentinel nodes are required to agree
// mymaster is the alias of the master node
sentinel monitor mymaster 127.0.0.1 6379 2
// Each Sentinel node should regularly PING the command to judge whether the Redis data node and other Sentinel nodes can reach
// If it exceeds 30000 milliseconds for 30s and there is no reply, it is determined that it is unreachable
sentinel down-after-milliseconds mymaster 30000
// When the Sentinel node set reaches an agreement on the fault determination of the primary node, the Sentinel leader node will perform a failover operation and select a new primary node,
// The original slave node will initiate replication operations to the new master node. The number of slave nodes initiating replication operations to the new master node is limited to 1
sentinel parallel-syncs mymaster 1
//The failover timeout is 180000 milliseconds
sentinel failover-timeout mymaster 180000
// Background execution
daemonize yes
2. Prepare three sentinels and start monitoring the master-slave architecture
# Sentry configuration file redis-26379.conf
port 26379
dir /var/redis/data/
logfile "26379.log"
sentinel monitor zbjmaster 127.0.0.1 6379 2
sentinel down-after-milliseconds zbjmaster 30000
sentinel parallel-syncs zbjmaster 1
sentinel failover-timeout zbjmaster 180000
daemonize yes
# Sentry configuration file redis-26380.conf
port 26380
dir /var/redis/data/
logfile "26380.log"
sentinel monitor zbjmaster 127.0.0.1 6379 2
sentinel down-after-milliseconds zbjmaster 30000
sentinel parallel-syncs zbjmaster 1
sentinel failover-timeout zbjmaster 180000
daemonize yes
# Sentry configuration file redis-26381.conf
port 26381
dir /var/redis/data/
logfile "26381.log"
sentinel monitor zbjmaster 127.0.0.1 6379 2
sentinel down-after-milliseconds zbjmaster 30000
sentinel parallel-syncs zbjmaster 1
sentinel failover-timeout zbjmaster 180000
daemonize yes
3. Start three sentinel instances
redis-sentinel redis-26379.conf
redis-sentinel redis-26380.conf
redis-sentinel redis-26381.conf
be careful!! If the experiment is not successful, delete all sentry configuration files and start over
be careful!! If the experiment is not successful, delete all sentry configuration files and start over
be careful!! If the experiment is not successful, delete all sentry configuration files and start over
# Check whether the sentinel status is normal
# Only the following information is found, it is normal
redis-cli -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
# The most important sentence
master0:name=zbjmaster,status=ok,address=127.0.0.1:6380,slaves=2,sentinels=3
4. Test automatic master-slave switching of sentry
1,Kill 6379 redis database
kill -9 6379 of PID
2,Check the identity information of 6380 and 6381 and check whether the master-slave switch is performed automatically
We set it at 30 s after master Without response, the sentry automatically switches between master and slave, so 30 s View master-slave information after
redis-cli -p 6380 info replication
redis-cli -p 6381 info replication
3,Manually start the 6379 suspended database to check whether it will be added to the master-slave cluster of information by sentinels
redis-server redis-6379.conf
redis-cli -p 6379 info replication2, redis partition and cluster
1. What are partitions and clusters
- Partition is the process of dividing data into multiple Redis instances, so each instance only saves a subset of key s. Partitioning allows Redis to manage more memory, and Redis will be able to use the memory of all machines. Without partitions, you can only use the memory of one machine at most. Partitioning enables Redis's computing power to be doubled by simply adding computers, and Redis's network bandwidth will increase exponentially with the increase of computers and network cards.
- Cluster redis cluster is an implementation of partition
2. Why partition
- Concurrency: the official claims that redis can execute 100000 commands per second, but what if the business needs to execute 1 million commands per second (such as the cheating of sina Weibo star and official publicity)
- Data volume when the data volume is too large, the normal memory of a server is 16~256G. What if your business needs 500G memory?
- Solution
- Scheme 1: configure a super awesome server with super memory and super cpu, but the cost is very high. Moreover, if the machine goes down, your services will not be all hung up.
- Scheme 2: consider distributed, add machines, distribute the data to different locations, share the centralized pressure, and a pile of machines do one thing.
3. Partitioned data distribution theory
Redis is a non relational database. Its storage is in the form of key value. The main idea of redis instance cluster is to hash the keys of redis data, and the specific keys will be mapped to the specified redis node through the hash function
Distributed database mainly solves the problem of mapping the whole data set to multiple nodes according to partition rules, that is, dividing the data set to multiple nodes, and each node is responsible for a subset of the whole data.
Common partition rules include hash partition and sequential partition.
4. Sequential partition
Suppose I have three nodes and 100 redis data. According to the average value (almost average), the sequential partition rule is: put 1-33 data on node1, 34-66 data on node2 and 67-100 data on node3
5. Hash partition
- Node remainder retrieval, for example, according to the node remainder retrieval method, the data of three nodes 1 ~ 100 are used to extract the remainder of 3, which can be divided into three types: the remainder is 0, the remainder is 1, and the remainder is 2. Save the data with the remainder of 0 to the same node, the data with the remainder of 1 to the same node, and the data with the remainder of 2 to the same node
Then the same four nodes are hash(key)%4. The same remainder is stored in the same node. The advantage of node remainder retrieval is simple. The client partition is hash + remainder retrieval directly
- The consistency hash client performs fragmentation, hash + clockwise remainder
- Virtual slot partition this paper studies the virtual slot partition of hash partition, so let's talk about it separately
3, Virtual slot partition of hash partition
1. Introduction
Redis Cluster uses virtual slot partition
The virtual slot partition skillfully uses the hash space and uses the hash function with good dispersion to map all data to a set of integers in a fixed range, which are defined as slots.
Redis Cluster slots range from 0 to 16383, i.e. 16384 slots in total.
Slot is the basic unit of data management and migration in the cluster. The main purpose of adopting a wide range of slots is to facilitate data splitting and cluster expansion,
Each node (redis instance) is responsible for a certain number of slots.
2. Virtual slot diagram
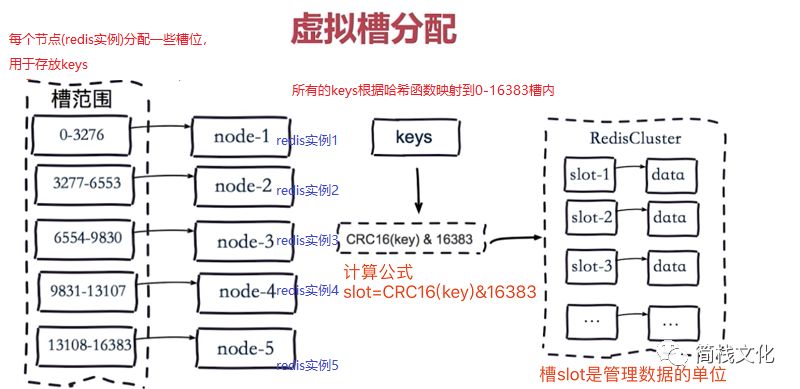
img
3. Set up redis cluster
redis supports the function of multiple instances. We need six instances to build a single demonstration cluster. Three are master nodes and three are slave nodes. The number of six nodes can ensure a highly available cluster.
1.Six nodes are prepared to store data and allocate slots. The configuration of each node is as follows, which is only the difference between ports
# redis-7000.conf configuration
port 7000
daemonize yes
dir "/opt/redis/data"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
The remaining 5 configurations as like as two peas, are just the difference between ports.
# redis-7001.conf configuration
# redis-7002.conf configuration
# redis-7003.conf configuration
# redis-7004.conf configuration
# redis-7005.conf configuration
Note: to create a folder for logs mkdir -p /opt/redis/data
2.Start 6 database instances
redis-server redis-7000.conf
redis-server redis-7001.conf
redis-server redis-7002.conf
redis-server redis-7003.conf
redis-server redis-7004.conf
redis-server redis-7005.conf
3.Start allocation redis Cluster status and slot allocation
Redis Cluster Itself provides automatic data distribution to Redis Cluster Capabilities of different nodes,
But slot allocation is more troublesome. Of course, if you are a great God, you can customize slot allocation,
Some great gods have written slot allocation tools or scripts, such as the open source of Douban company codis Tools, and ruby The author of the language, written redsi.rb,
So we can use some tools to help us redis cluster Construction of
4.adopt ruby Script, one click creation redis-cluster,Slot allocation
5.prepare ruby Programming environment
1,download ruby Source package for
wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
2,decompression ruby Is it far?
tar -zxvf ruby-2.3.1.tar.gz
3,Start compilation and installation ruby
get into ruby Source package
./configure --prefix=/opt/ruby/
4,Start compilation and install
make && make install
5,to configure ruby Environment variables for
vim /etc/profile
Write the following configuration
PATH=Your original PATH:/opt/ruby/bin
source /etc/profile
6.install ruby operation redis Module of
1,download ruby operation redis Module of
wget http://rubygems.org/downloads/redis-3.3.0.gem
2,install
gem install -l redis-3.3.0.gem
3,Search creation redis Cluster commands
find /opt -name redis-trib.rb
/opt/redis-4.0.10/src/redis-trib.rb
7.One click creation redis colony
/opt/redis-4.0.10/src/redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
--replicas Identity authorization
The following 1 represents each master node and only one slave node
7000 7001 70002 is set as the main library by default
Set 7003 7004 7005 as slave Library
8.Check cluster status
redis-cli -p 7000 cluster info
9.Test the cluster node to see if it can write data normally
redis-cli -c -p 7000
-p Specify database port
-c Specifies that cluster mode is enabled
set age 18 # Setting a key will automatically allocate the slot. Redirecting to the node where the slot is located represents success
At any node get age,Automatically redirects to age The node on which the is located.
10.redis-cluster The default will be different key,conduct CRC16 Algorithm to allocate to different slots
11.The data is redirected normally, i.e redis colony okReference address
- https://www.cnblogs.com/Zzbj/p/10280363.html
- https://www.cnblogs.com/rjzheng/p/10360619.html
If you like my article, you can pay attention to your personal subscription number. Welcome to leave messages and communicate at any time. If you want to join the wechat group for discussion, please add the administrator Jian stack culture - little assistant (lastpass4u), who will pull you into the group.