preface
Array, linked list, tree and other data structures will store the contents of elements. Once the amount of data is too large, the consumed memory will also increase linearly
Therefore, bloom filter is a data structure to solve the large amount of data
When talking about bloom filter, you need to know some preliminary knowledge points: such as hash function
1. Preparatory knowledge
1.1 hash function
A hash function is a function that maps the key value of an element in a hash table to the storage location of the element
In general linear tables and trees, the relative positions of records in the structure are random, that is, there is no definite relationship with the record keywords. Therefore, a series of comparisons with the keywords are required when looking up records in the structure. This kind of search method is based on "comparison", and the search efficiency depends on the number of comparisons in the search process. Ideally, the required records can be found directly. Therefore, a certain corresponding relationship f must be established between the storage location of the record and its keywords, so that each keyword corresponds to a unique storage location in the structure
The specific methods of its constructor are:
Direct addressing method, digital analysis method, square centering method, folding method, division and remainder method, etc
The methods to solve the conflict are:
Zipper method, Doha method, open address method, domain building method, etc
2. Bloom filter
2.1 concept
It is actually a long binary vector and a series of random mapping functions. (bit group and hash function)
Bloom filters can be used to retrieve whether an element is in a collection.
Its advantage is that space efficiency and query time are much better than general algorithms (more efficient and less storage space)
The disadvantage is that it has a certain false recognition rate and difficult to delete
2.2 implementation principle
The reason why bloom filter is used is that the implementation of HashMap also has disadvantages. For example, the proportion of storage capacity is high. Considering the existence of load factor, usually the space can not be used up, and it is impossible to use it once the data is large
For example, the value of storage code is calculated by three hash functions and stored in three positions (digit group)
Later, when determining the query code, Dr. Nong found that as long as one of the three values is not 1, it is not stored in the set, that is, it is not in the set
However, if there are many stored values, there may be a certain misjudgment rate when looking for them, resulting in the fact that they are not in the set, but the digit group is 1
How to select the length of the bit group and the number of hash functions mentioned above
If the Bronzer is too small, many positions will soon be 1, and the misjudgment rate will be very high. If the Bronzer is too long, the misjudgment rate will be smaller
If the number of hash functions is too small, the speed is slow and the misjudgment rate is high. If the number of hash functions is too large, the speed of bit 1 is accelerated, resulting in the lower efficiency of Bloom filter
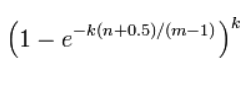
2.3 steps
-
The specific steps to add elements are
Give the added elements to k hash functions, calculate K positions on the corresponding bit array, and set these K positions to 1 -
The specific steps for querying elements are
Give k hash functions to the elements to be queried to calculate the K positions corresponding to the bit array. If one of the K positions is 0, it must not be in the collection. If all k positions are 1, they may be in the set
In the counting bloom filter, the premise of deletion is to ensure that the value must exist. Therefore, the value cannot be guaranteed to exist only through the bloom filter. If you delete the value after confirming its existence through other methods, you cannot guarantee that the value will return non-existent in subsequent bloom filter queries, because the corresponding position of the value is not necessarily zero. However, the efficiency of query can be optimized with a certain probability. Therefore, it cannot be said that the count bloom filter supports deletion. It should be said that the count bloom filter provides the possibility of deletion
2.4 realization
public class MyBloomFilter {
/**
* A bit with a length of 1 billion
*/
private static final int DEFAULT_SIZE = 256 << 22;
/**
* In order to reduce the error rate, the addition hash algorithm is used, so an 8-element prime array is defined
*/
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
/**
* It is equivalent to building 8 different hash algorithms
*/
private static HashFunction[] functions = new HashFunction[seeds.length];
/**
* Initialize bitmap of Bloom filter
*/
private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* Add data
*
* @param value Value to be added
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//Calculate the hash value and modify the corresponding position in the bitmap to true
bitset.set(f.hash(value), true);
}
}
}
/**
* Determine whether the corresponding element exists
* @param value Elements to be judged
* @return result
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//If a hash function returns false, it will jump out of the loop
if (!ret) {
break;
}
}
return ret;
}
/**
* Test...
*/
public static void main(String[] args) {
for (int i = 0; i < seeds.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
// Add 100 million data
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println(contains(id)); // true
System.out.println("" + contains("234567890")); //false
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
}