install
pip install lxml pip install beautifulsoup4
Verify installation
In [1]: from bs4 import BeautifulSoup In [2]: soup = BeautifulSoup('<p>Hello</p>', 'lxml') In [3]: print(soup.p.string) Hello
About Beautiful Soup
Parsers supported by Beautiful Soup
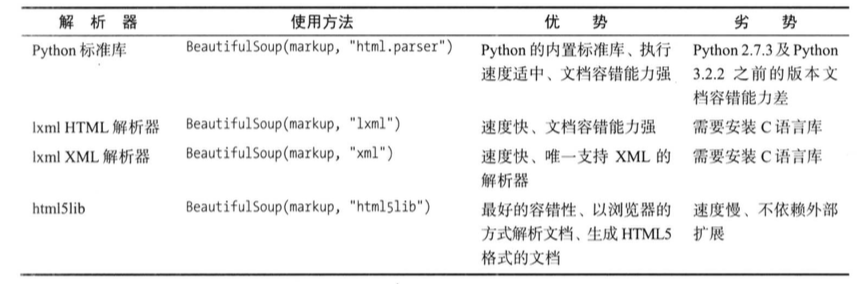
By comparison, lxml parser is a better choice
Just set the second parameter to lxml when initializing Beautiful Soup
from bs4 import BeautifulSoup html = ''' <html> <head><title>Beautiful Soup test</title></head> <body> <p class="first" name="first_p"><b>first content</b></p> <p class="second">second content <a href="http://example.com/first"></a> <a href="http://example.com/second"> ''' soup = BeautifulSoup(html, 'lxml') print(soup.prettify()) # Increase indent and beautify output print(soup.title.string) # Get the text content of the title node
Note: the html content in the above code is incomplete, and some tags are not closed
Operation result:
<html> <head> <title> Beautiful Soup test </title> </head> <body> <p class="first" name="first_p"> <b> first content </b> </p> <p class="second"> second content <a href="http://example.com/first"> </a> <a href="http://example.com/second"> </a> </p> </body> </html> Beautiful Soup test
Beautifulsop will automatically complete html tags
Node selector
from bs4 import BeautifulSoup html = ''' <html> <head><title>Beautiful Soup test</title></head> <body> <p class="first" name="first_p"><b>first content</b></p> <p class="second">second content <a href="http://example.com/first"></a> <a href="http://example.com/second"> ''' soup = BeautifulSoup(html, 'lxml') print(soup.title) # <title>Beautiful Soup test</title> print(type(soup.title)) # <class 'bs4.element.Tag'> print(soup.title.string) # Beautiful Soup test print(soup.head) # <head><title>Beautiful Soup test</title></head> print(soup.p) # <p class="first" name="first_p"><b>first content</b></p>
Node name
In [3]: print(soup.title.name) title
Node all attributes
In [4]: print(soup.p.attrs) {'class': ['first'], 'name': 'first_p'}
Node specified properties
In [5]: print(soup.p.attrs['name']) first_p
Node specified attribute shorthand
In [6]: print(soup.p['name']) first_p
Node text content
In [7]: print(soup.p.string) first content
Nested selection
In [8]: print(soup.head.title) <title>Beautiful Soup test</title> In [9]: print(type(soup.head.title)) <class 'bs4.element.Tag'> In [10]: print(soup.head.title.string) Beautiful Soup test
Association selection
In [11]: print(soup.body.children) <list_iterator object at 0x10825a6d8> In [12]: for i, child in enumerate(soup.body.children): ...: print(i, child) ...: 0 1 <p class="first" name="first_p"><b>first content</b></p> 2 3 <p class="second">second content <a href="http://example.com/first"></a> <a href="http://example.com/second"> </a></p>
- children all child nodes
- descendants all descendant nodes
- Parent direct parent
- parents ancestor node
- Next? Sibling
- Previous > previous sibling
- Next? Siblings
- Previous > siblings
Method selector
find_all
Data preparation
In [13]: from bs4 import BeautifulSoup ...: ...: html = ''' ...: <div class="panel"> ...: <div class="panel-heading"> ...: <h4>Hello</h4> ...: </div> ...: <div class="panel-body"> ...: <ul class="list" id="list-1"> ...: <li class="element">Foo</li> ...: <li class="element">Bar</li> ...: <li class="element">Jay</li> ...: </ul> ...: <ul class="list list-small" id="list-2"> ...: <li class="element">Foo</li> ...: <li class="element">Bar</li> ...: </ul> ...: </div> ...: </div> ...: ''' ...: ...: soup = BeautifulSoup(html, 'lxml') ...: ...:
All ul
In [16]: soup.find_all(name='ul') Out[16]: [<ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul>, <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul>]
Since the ul obtained is of Tag type, it can be iterated
In [17]: type(soup.find_all(name='ul')[0]) Out[17]: bs4.element.Tag In [18]: for ul in soup.find_all(name='ul'): ...: print(ul.find_all(name='li')) ...: [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>]
Then through traversing li, the text of li is obtained
In [19]: for ul in soup.find_all(name='ul'): ...: print(ul.find_all(name='li')) ...: for li in ul.find_all(name='li'): ...: print(li.string) ...: [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>] Foo Bar Jay [<li class="element">Foo</li>, <li class="element">Bar</li>] Foo Bar
attrs
Query by attribute
In [26]: soup.find_all(attrs={'id': 'list-1'}) Out[26]: [<ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul>]
text
Match the text content of the node
In [28]: import re # Returns a list of all matching regular node text In [29]: soup.find_all(text=re.compile('ar')) Out[29]: ['Bar', 'Bar']
find
Returns the first matching element
In [30]: soup.find(text=re.compile('ar')) Out[30]: 'Bar' In [31]: soup.find('li') Out[31]: <li class="element">Foo</li>
There are other uses for find:
find_parents() and find_parent()
Find? Next? Siblings() and find? Next? Siblings()
Find ABCD previous ABCD siblings() and find ABCD previous ABCD siblings()
Find'all'next() and find'next()
Fina? All? Previous() and find? Previous()
css selector
Just call the select() method and pass in the corresponding css selector
In [32]: soup.select('.panel .panel-heading') Out[32]: [<div class="panel-heading"> <h4>Hello</h4> </div>] In [33]: soup.select('ul li') Out[33]: [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>] In [34]: soup.select('#list-2 .element') Out[34]: [<li class="element">Foo</li>, <li class="element">Bar</li>] In [35]: soup.select('ul')[0] Out[35]: <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul>
Nested selection
In [36]: for ul in soup.select('ul'): ...: print(ul.select('li')) ...: [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>]
get attribute
In [37]: for ul in soup.select('ul'): ...: print(ul['id']) ...: print(ul.attrs['id']) ...: list-1 list-1 list-2 list-2
Get text
In [39]: for li in soup.select('li'): ...: print('Get Text:', li.get_text()) ...: print('String:', li.string) ...: ...: Get Text: Foo String: Foo Get Text: Bar String: Bar Get Text: Jay String: Jay Get Text: Foo String: Foo Get Text: Bar String: Bar