Redis data types (5 common)
| type | Implementation principle |
|---|---|
| string | String |
| hash | HashMap |
| hash | LinkedList |
| set | HashSet |
| sorted_set | TreeSet |
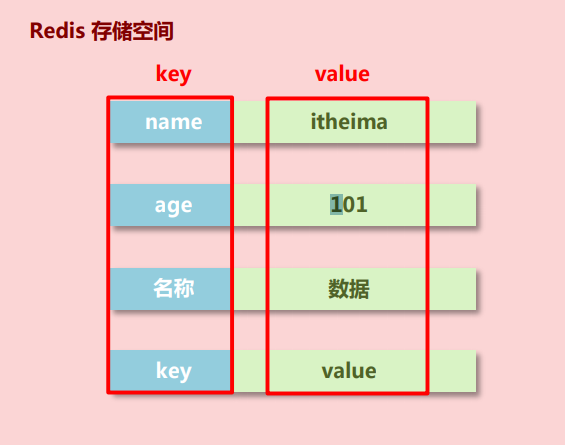
redis data storage format
- redis itself is a Map in which all data is stored in the form of key:value.
- Data type refers to the type of stored data, that is, the type of value part. The key part is always a string.
1.string type
-
Stored data: single data, the simplest data storage type and the most commonly used data storage type
-
Format of stored data: one storage space holds one data
-
Storage content: string is usually used. If the string is displayed in the form of integer, it can be used as digital operation
Code example
Basic operation of string type data
- Add / modify data set key value
set username zhangsan
- Get data get key
127.0.0.1:6379> get username "zhangsan"
- Delete data del key
127.0.0.1:6379> del username (integer) 1
- Add / modify multiple data mset key1 value1 key2 value2
mset name xiaoming sex nan address hn
- Get multiple data mget key1 key2
mget name sex address 1) "xiaoming" 2) "nan" 3) "hn"
- Get the number of data characters (string length) strlen key
127.0.0.1:6379> strlen name (integer) 8
- Append information to the back of the original information (append if the original information exists, otherwise create a new one) append key value
1
27.0.0.1:6379> append name dd (integer) 10 127.0.0.1:6379> get name "xiaomingdd"
Extension operation of string type data
Business scenario 1
In large enterprise applications, table splitting is the basic operation. Multiple tables are used to store the same type of data, but the corresponding primary key id must be unified and cannot be repeated. Oracle database has
sequence setting can solve this problem, but MySQL database does not have a similar mechanism, so how to solve it
Solution
- Set the numeric data to increase the value of the specified range
incr key incrby key increment incrbyfloat key increment
example
127.0.0.1:6379> incr seq_id1 (integer) 1 127.0.0.1:6379> incr seq_id1 (integer) 2 127.0.0.1:6379> incrby seq_id1 2 (integer) 4 127.0.0.1:6379> incr seq_id1 (integer) 5 127.0.0.1:6379> incrbyfloat seq_id1 0.5 "5.5"
- Set numeric data to reduce the value of the specified range
decr key decrby key increment
example
127.0.0.1:6379> decr seq_id2 (integer) -1 127.0.0.1:6379> decrby seq_id2 2 (integer) -3
string as numeric operation
- String is stored in redis. By default, it is a string. When increasing or decreasing operations incr and decr are encountered, it will be converted to numerical type for calculation.
- All redis operations are atomic. Single thread is used to process all businesses, and commands are executed one by one. Therefore, there is no need to consider the data impact caused by concurrency.
- Note: for data operated by value, if the original data cannot be converted into value or exceeds the upper limit of redis value, an error will be reported.
9223372036854775807 (maximum value of long type data in java, Long.MAX_VALUE)
Tips 1:
- redis is used to control the primary key id of the database table, provide the generation strategy for the primary key of the database table, and ensure the uniqueness of the primary key of the database table
- This scheme is applicable to all databases and supports database clusters
Business scenario 2
The "strongest girl" can only vote through wechat when starting the audition voting, and each wechat can only vote once every four hours.
E-commerce merchants open the recommendation of popular goods. Popular goods cannot be in the popular period all the time. The popular period of each kind of goods is maintained for 3 days, and the popular goods will be automatically cancelled after 3 days.
Hot news will appear in news websites. The biggest feature of hot news is timeliness. How to automatically control the timeliness of hot news
Solution
- The setup data has a specified lifecycle
Seconds and milliseconds
setex key seconds value psetex key milliseconds value
example
127.0.0.1:6379> setex name 5 xiaohong OK 127.0.0.1:6379> get name "xiaohong" 127.0.0.1:6379> get name (nil) 127.0.0.1:6379> psetex sex 5000 nan OK 127.0.0.1:6379> get sex "nan" 127.0.0.1:6379> get sex (nil)
Tips 2:
- redis controls the life cycle of data and controls business behavior through whether the data is invalid. It is applicable to all operations with time limited control
- Difference between feedback of unsuccessful data operation and normal data operation
① Indicates whether the running result is successful
(integer) 0 → false failed
(integer) 1 → true successful
② Indicates the running result value
(integer) 3 → 3
(integer) 1 → 1 - Data not obtained
(nil) is equivalent to null - Maximum data storage
512MB - Maximum range of numerical calculation (maximum value of long in java)
9223372036854775807
Business scenario 3
Display control of high-frequency access information on the home page, such as the number of fans and the number of microblogs displayed on the big V home page of sina Weibo
Solution
Business scenario solution point
2.hash type
Storage confusion
If the storage of object class data has frequent update requirements, the operation will be cumbersome
- New storage requirements: organize a series of stored data to facilitate management, and store object information in typical applications
- Required storage structure: one storage space holds multiple key value pair data
- Hash type: the bottom layer uses hash table structure to realize data storage
hash storage structure optimization
- If the number of field s is small, the storage structure is optimized to class array structure
- If there are a large number of field s, the storage structure uses the HashMap structure
Basic operations of hash type data
- Modify / delete data
hset key field value
127.0.0.1:6379> hset student id 1 (integer) 1 127.0.0.1:6379> hset student name zhangsan (integer) 1
- get data
hget key field hgetall key
127.0.0.1:6379> hget student id "1" 127.0.0.1:6379> hgetall student 1) "id" 2) "1" 3) "name" 4) "zhangsan"
- Delete data
hdel key field1 [field2]
127.0.0.1:6379> hdel student id name (integer) 2
- Add / modify multiple data
hmset key field1 value1 field2 value2 ...
127.0.0.1:6379> hmset student id 1 name lisi address beijing OK
- Get multiple data
hmget key field1 field2 ...
127.0.0.1:6379> hmget student id name address
- "1"
- "lisi"
- "beijing"
- Gets the number of fields in the hash table
hlen key
127.0.0.1:6379> hlen student (integer) 3
- Gets whether the specified field exists in the hash table
hexists key field
127.0.0.1:6379> hexists student id (integer) 1 127.0.0.1:6379> hexists student sex (integer) 0
hash type data extension operation
- Gets all field names or field values in the hash table
hkeys key hvals key
127.0.0.1:6379> hkeys student 1) "id" 2) "name" 3) "address" 127.0.0.1:6379> hvals student 1) "1" 2) "lisi" 3) "beijing"
- Set the numeric data of the specified field and increase the value of the specified range
hincrby key field increment hincrbyfloat key field increment
127.0.0.1:6379> hincrby student id 2 (integer) 3 127.0.0.1:6379> hget student id "3" 127.0.0.1:6379> hincrbyfloat student id 0.5 "3.5" 127.0.0.1:6379> hget student id "3.5"
Precautions for hash type data operation
- value under hash type can only store strings, and other data types are not allowed to be stored. There is no nesting. If the data is not obtained,
The corresponding value is (nil) - Each hash can store 2
32 - 1 key value pair - The hash type is very close to the data storage form of the object, and the object attributes can be added and deleted flexibly. But hash is not designed for storage
It is designed to store a large number of objects. Remember not to abuse it, let alone use hash as an object list - hgetall operation can obtain all attributes. If there are too many internal field s, the efficiency of traversing the overall data will be very low, which may become data access
bottleneck
hash type application scenario
hash type application field
3.list type
- Data storage requirements: store multiple data and distinguish the order in which the data enters the storage space
- Required storage structure: one storage space holds multiple data, and the entry order can be reflected through the data
- List type: save multiple data, and the bottom layer is realized by using the storage structure of two-way linked list
Basic operation of list type data
- Add / modify data
lpush key value1 [value2] ...... rpush key value1 [value2] ......
127.0.0.1:6379> lpush mylist1 apple banana orange bear (integer) 4 127.0.0.1:6379> rpush mylist2 aa bb cc dd ee (integer) 5
- get data
lrange key start stop lindex key index llen key
127.0.0.1:6379> lrange mylist1 0 10 1) "bear" 2) "orange" 3) "banana" 4) "apple" 127.0.0.1:6379> lrange mylist2 0 10 1) "aa" 2) "bb" 3) "cc" 4) "dd" 5) "ee" 127.0.0.1:6379> lindex mylist1 1 "orange" 127.0.0.1:6379> lindex mylist2 1 "bb" 127.0.0.1:6379> llen mylist1 (integer) 4 127.0.0.1:6379> llen mylist2 (integer) 5
- Get and remove data
lpop key rpop key
127.0.0.1:6379> lpop mylist1 "bear" 127.0.0.1:6379> rpop mylist1 "apple" 127.0.0.1:6379> lpop mylist2 "aa" 127.0.0.1:6379> rpop mylist2 "ee"
list type data extension operation
- Obtain and remove data within a specified time
blpop key1 [key2] timeout brpop key1 [key2] timeout brpoplpush source destination timeout
127.0.0.1:6379> blpop mylist1 2 1) "mylist1" 2) "orange" 127.0.0.1:6379> lrange mylist1 (error) ERR wrong number of arguments for 'lrange' command 127.0.0.1:6379> lrange mylist1 0 10 1) "banana" 127.0.0.1:6379> brpop mylist2 2 1) "mylist2" 2) "dd" 127.0.0.1:6379> brpoplpush mylist1 0 2 "banana" 127.0.0.1:6379> lrange mylist1 0 10 (empty list or set)
- Remove specified data
lrem key count value
127.0.0.1:6379> lpush mylist3 aa bb aa cc dd ee dd (integer) 7 127.0.0.1:6379> lrem mylist3 1 aa (integer) 1 127.0.0.1:6379> lrange mylist3 0 10 1) "dd" 2) "ee" 3) "dd" 4) "cc" 5) "bb" 6) "aa" 127.0.0.1:6379> lrem mylist3 2 dd (integer) 2 127.0.0.1:6379> lrange mylist3 0 10 1) "ee" 2) "cc" 3) "bb" 4) "aa"
Tips 6:
- redis is applied to data control with operation sequence
Precautions for list type data operation
- The data stored in the list is of string type, and the total data capacity is limited, up to 2
32 - 1 element (4294967295). - list has the concept of index, but when operating data, it is usually in the form of queue, or in the form of stack
- Get all data operation end index set to - 1
- List can page data. Usually, the information on the first page comes from the list, and the information on the second page and more is loaded in the form of database
list application scenario
Business scenario click here
4.set type
set type
- New storage requirements: store a large amount of data and provide higher efficiency in query
- Required storage structure: it can save a large amount of data, and has an efficient internal storage mechanism to facilitate query
- set type: exactly the same as the hash storage structure. Only keys are stored, and values (nil) are not stored, and duplicate values are not allowed
Basic operations of set type data
- Add data
sadd key member1 [member2]
127.0.0.1:6379> sadd myset1 aa bb cc dd ee dd ff (integer) 6
- Get all data
smembers key
127.0.0.1:6379> smembers myset1 1) "dd" 2) "bb" 3) "cc" 4) "aa" 5) "ee" 6) "ff"
- Delete data
srem key member1 [member2]
srem myset1 dd (integer) 1 127.0.0.1:6379> smembers myset1 1) "bb" 2) "cc" 3) "aa" 4) "ee" 5) "ff"
- Get the total amount of collection data
scard key
127.0.0.1:6379> scard myset1 (integer) 5
- Judge whether the set contains the specified data
sismember key member
127.0.0.1:6379> sismember myset1 aa (integer) 1 127.0.0.1:6379> sismember myset1 dd (integer) 0
Extension operation of set type data
Solution
- Gets a specified amount of data in a collection at random
srandmember key [count]
127.0.0.1:6379> srandmember myset1 2 1) "bb" 2) "cc" 127.0.0.1:6379> srandmember myset1 "ee"
- Randomly obtain a data in the set and move the data out of the set
spop key [count]
127.0.0.1:6379> spop myset1 1 1) "ff" 127.0.0.1:6379> spop myset1 2 1) "aa" 2) "cc"
- Find the intersection, union and difference sets of two sets
sinter key1 [key2] sunion key1 [key2] sdiff key1 [key2]
127.0.0.1:6379> sadd myset2 aa bb cc dd (integer) 4 127.0.0.1:6379> sadd myset3 dd ee ff gg (integer) 4 127.0.0.1:6379> sinter myset2 myset3 1) "dd" 127.0.0.1:6379> sunion myset2 myset3 1) "cc" 2) "bb" 3) "aa" 4) "dd" 5) "gg" 6) "ee" 7) "ff" 127.0.0.1:6379> sdiff myset2 myset3 1) "bb" 2) "cc" 3) "aa"
- Find the intersection, union and difference sets of two sets and store them in the specified set
sinterstore destination key1 [key2] sunionstore destination key1 [key2] sdiffstore destination key1 [key2]
127.0.0.1:6379> sinterstore myset4 myset2 myset3 (integer) 1 127.0.0.1:6379> smembers myset4 1) "dd" 127.0.0.1:6379> sunionstore myset5 myset2 myset3 (integer) 7 127.0.0.1:6379> smembers myset5 1) "cc" 2) "bb" 3) "aa" 4) "dd" 5) "gg" 6) "ee" 7) "ff" 127.0.0.1:6379> sdiffstore myset6 myset2 myset3 (integer) 3 127.0.0.1:6379> smembers myset6 1) "bb" 2) "cc" 3) "aa"
- Moves the specified data from the original set to the target set
smove source destination member
set application scenario
set application scenario click here
5.sorted_set type
- New storage requirements: data sorting is conducive to the effective display of data. It needs to provide a way to sort according to its own characteristics
- Required storage structure: a new storage model can save sortable data
- sorted_set type: add sortable fields based on the storage structure of set
sorted_ Basic operations of set type data
- Add data
zadd key score1 member1 [score2 member2]
127.0.0.1:6379> zadd sal 1 3600 (integer) 1 127.0.0.1:6379> zadd sal 2 4000 (integer) 1 127.0.0.1:6379> zadd sal 3 10000 (integer) 1 127.0.0.1:6379> zadd sal 4 8000 (integer) 1
- Get all data
zrange key start stop [WITHSCORES] zrevrange key start stop [WITHSCORES]
127.0.0.1:6379> zrange sal 0 10 withscores 1) "3600" 2) "1" 3) "4000" 4) "2" 5) "10000" 6) "3" 7) "8000" 8) "4" 127.0.0.1:6379> zrevrange sal 0 10 withscores 1) "8000" 2) "4" 3) "10000" 4) "3" 5) "4000" 6) "2" 7) "3600" 8) "1"
- Delete data
zrem key member [member ...]
127.0.0.1:6379> zrem sal 4000 (integer) 1 127.0.0.1:6379> zrem sal 16000 (integer) 0 127.0.0.1:6379> zrange sal 0 10 withscores 1) "3600" 2) "1" 3) "10000" 4) "3" 5) "8000" 6) "4"
- Get data by conditions
zrangebyscore key min max [WITHSCORES] [LIMIT] zrevrangebyscore key max min [WITHSCORES]
127.0.0.1:6379> zrangebyscore sal 2 4 withscores 1) "10000" 2) "3" 3) "8000" 4) "4" 127.0.0.1:6379> zrevrangebyscore sal 2 4 withscores (empty list or set)
- Delete data by criteria
zremrangebyrank key start stop zremrangebyscore key min max
127.0.0.1:6379> zremrangebyrank sal 0 3 (integer) 3 127.0.0.1:6379> zremrangebyscore sal 1000 10000 (integer) 0
be careful:
- min and max are used to limit the search query criteria
- Start and stop are used to limit the query range, act on the index, and indicate the start and end of the index
- offset and count are used to limit the query range, act on the query results, and represent the starting position and total amount of data
- Get the total amount of collection data
zcard key zcount key min max
127.0.0.1:6379> zadd score 1 80 (integer) 1 127.0.0.1:6379> zadd score 2 90 (integer) 1 127.0.0.1:6379> zadd score 3 60 (integer) 1 127.0.0.1:6379> zadd score 4 70 (integer) 1 127.0.0.1:6379> zadd score 6 85 (integer) 1 127.0.0.1:6379> zcard score (integer) 5 127.0.0.1:6379> zcount score 2 5 (integer) 3
- Set intersection and parallel operation
zinterstore destination numkeys key [key ...] zunionstore destination numkeys key [key ...]
sorted_ Extension operation of set type data
Get the index (ranking) corresponding to the data
zrank key member zrevrank key member
127.0.0.1:6379> zrank score 60 (integer) 2 127.0.0.1:6379> zrevrank score 60 (integer) 2
score value acquisition and modification
zscore key member zincrby key increment member
127.0.0.1:6379> zscore score 60 "3" 127.0.0.1:6379> zincrby score 2 60 "5"
sorted_ Precautions for set type data operation
- The data storage space saved by score is 64 bits. If it is an integer, the range is - 9007199254740992 ~ 9007199254740992
- The data saved by score can also be a double value of double precision. Based on the characteristics of double precision floating-point numbers, the precision may be lost. When used
Be careful - sorted_ The underlying storage of set is based on the set structure, so the data cannot be repeated. If the same data is added repeatedly, the score value will be reversed
Overwrite and keep the result of the last modification
sorted_set type application scenario
sorted_set type application scenario