Why is current limiting required?
1. When developing a highly concurrent system, we may encounter too frequent interface access. In order to ensure the high availability and stability of the system, we need to limit the traffic.
2. Some operator models take a long time to calculate and consume resources. If the traffic is too high, it can't be handled.
3. You can use Nginx to control the request, or you can use some popular class libraries to implement it. Current limiting is a big killer in high concurrency systems.
4. Now the general gateway will also limit the current.
What is current limiting?
Flow limiting is to protect services by limiting concurrent access requests or limiting requests within a time window. Once the limit rate is reached, measures need to be taken.
- Direct denial of service: direct to the error page or tell that the resource is gone
- Wait: it can be put into the queue or other operations
- Degradation processing: return the bottom data or default data
Generally speaking, various measures can be represented by the returned status code, and the requester can customize the operation according to the returned status code
For example:
- Direct reject: 5001 (the requester can retry)
- Wait: 5002 (the requester can wait for the server to return information without any operation)
- Demotion processing: 5003 (the server gives the returned data, and the specific processing measures can be discussed by both parties)
The main purpose of current limiting is to ensure that their services are not hung up. Secondly, it can also be measured as the service availability. For example, you can discuss with the business that the qps is 10, that is, 10 requests in one second, to ensure that these 10 requests can be processed normally, or allow some errors, and the availability is 100% or 99.999%.
Common algorithms for current limiting?
- Counter algorithm
- Sliding window algorithm
- Leaky bucket algorithm
- Token Bucket
1. Counter algorithm
The so-called counter algorithm is to count requests within a certain time interval. When the number of requests reaches the threshold, judge whether current restriction is required. When the critical point of time is reached, clear the counter and update the time
- Set a variable count. When a request comes, count + +, and record the request time at the same time
- When the next request comes, judge whether the value of count exceeds the set threshold. If it does not exceed the threshold, do not limit the current. If it exceeds the threshold, judge whether the difference between the time of the current request and the time of the first request is within the counting cycle
- If the time difference between the two is within the counting cycle, current limiting is required and the request is rejected
- If the time difference between the two is greater than or equal to the count cycle, you need to update the time and clear the value of count
The code is implemented as follows
package main
import (
"log"
"sync"
"time"
)
type Counter struct {
rate int //The maximum number of requests allowed in the count cycle
begin time.Time //Count start time
cycle time.Duration //Counting cycle
count int //Total requests in count cycle
lock sync.Mutex
}
// Judge whether the current is limited
func (l *Counter) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
if l.count == l.rate-1 {
now := time.Now()
if now.Sub(l.begin) >= l.cycle {
//Reset the counter within the allowable speed range
l.Reset(now)
return true
} else {
return false
}
} else {
//Rate limit not reached, count plus 1
l.count++
return true
}
}
// initialization
func (l *Counter) Set(r int, cycle time.Duration) {
l.rate = r
l.begin = time.Now()
l.cycle = cycle
l.count = 0
}
//Update time and empty count
func (l *Counter) Reset(t time.Time) {
l.begin = t
l.count = 0
}
func main() {
var wg sync.WaitGroup
var lr Counter
lr.Set(3, time.Second) // Up to 3 requests in 1s
for i := 0; i < 10; i++ {
wg.Add(1)
log.Println("Create request:", i)
go func(i int) {
if lr.Allow() {
log.Println("Response request:", i)
}
wg.Done()
}(i)
time.Sleep(200 * time.Millisecond)
}
wg.Wait()
}
The response results are as follows
2021/02/01 21:16:12 Create request: 0 2021/02/01 21:16:12 Response request: 0 2021/02/01 21:16:12 Create request: 1 2021/02/01 21:16:12 Response request: 1 2021/02/01 21:16:12 Create request: 2 2021/02/01 21:16:13 Create request: 3 2021/02/01 21:16:13 Create request: 4 2021/02/01 21:16:13 Create request: 5 2021/02/01 21:16:13 Response request: 5 2021/02/01 21:16:13 Create request: 6 2021/02/01 21:16:13 Response request: 6 2021/02/01 21:16:13 Create request: 7 2021/02/01 21:16:13 Response request: 7 2021/02/01 21:16:14 Create request: 8 2021/02/01 21:16:14 Create request: 9
It can be seen from the response results that the requests of 2, 3, 4, 8 and 9 are discarded, that is, the flow is limited
But there is a problem with the counter algorithm?
The qps of an API interface is 100. At this time, 100 requests are made when it is infinitely close to 1s, and the count will be cleared after 1s. However, the request continues, and the count will be + +, and then 100 requests will arrive immediately after the last 1s. At this time, there are infinitely close to 200 requests in this time period, which will be greater than twice the current limit. This is in line with our design logic, This is also the design defect of the counter method. The system may bear a large number of requests from malicious users and even break down the system. Therefore, it can not deal with this kind of sudden traffic, and there is no good boundary of unit time
2. Sliding window algorithm
Sliding window is aimed at the critical point defect of the counter. The so-called sliding window is a flow control technology, which appears in the TCP protocol. Sliding window divides fixed time slices and moves with the passage of time. A fixed number of movable grids count and judge the threshold.
The code is as follows
package utils
import "time"
var LimitQueue map[string][]int64
var ok bool
//Single machine time sliding window current limiting method
func LimitFreqSingle(queueName string, count uint, timeWindow int64) bool {
currTime := time.Now().Unix()
if LimitQueue == nil {
LimitQueue = make(map[string][]int64)
}
if _, ok = LimitQueue[queueName]; !ok {
LimitQueue[queueName] = make([]int64, 0)
}
//The queue is not full
if uint(len(LimitQueue[queueName])) < count {
LimitQueue[queueName] = append(LimitQueue[queueName], currTime)
return true
}
//When the queue is full, get the earliest access time
earlyTime := LimitQueue[queueName][0]
//It indicates that the earliest time is still within the time window and has not expired, so it is not allowed to pass
if currTime-earlyTime <= timeWindow {
return false
} else {
//It indicates that the earliest access should be expired. Remove the earliest access
LimitQueue[queueName] = LimitQueue[queueName][1:]
LimitQueue[queueName] = append(LimitQueue[queueName], currTime)
}
return true
}
There will still be the concept of time slice, which can not fundamentally solve the critical point problem. The specific implementation algorithm can be referred to
Related algorithm implementation GitHub com/RussellLuo/slidingwindow
3. Leaky bucket algorithm
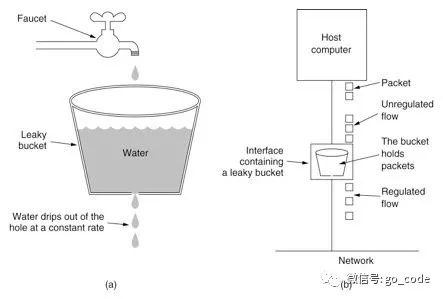
Leaky Bucket algorithm is based on the principle that a Leaky Bucket with a fixed capacity flows out water droplets at a fixed rate, that is, the rate of processing requests is fixed. Even if there is a burst flow, it will be discarded due to insufficient Leaky Bucket capacity.
The code is implemented as follows
type LeakyBucket struct {
rate float64 //Fixed effluent rate per second
capacity float64 //Barrel capacity
water float64 //Current water volume in bucket
lastLeakMs int64 //Bucket last leak timestamp ms
lock sync.Mutex
}
func (l *LeakyBucket) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
now := time.Now().UnixNano() / 1e6
eclipse := float64((now - l.lastLeakMs)) * l.rate / 1000 //Perform the water leakage test first
l.water = l.water - eclipse //Calculate the remaining water volume
l.water = math.Max(0, l.water) //The bucket is dry
l.lastLeakMs = now
if (l.water + 1) < l.capacity {
// Try adding water and the water is not full
l.water++
return true
} else {
// Refuse to add water when the water is full
return false
}
}
func (l *LeakyBucket) Set(r, c float64) {
l.rate = r
l.capacity = c
l.water = 0
l.lastLeakMs = time.Now().UnixNano() / 1e6
}
- The capacity of the bucket is fixed, and the flow rate is also fixed (the rate at which requests are processed)
- If the bucket is empty at this time, there is no need to process the request
- It can flow into the bucket at any water speed (flow can come at will, or sudden)
- When the bucket is full, it can not be filled with water and will overflow (the flow will be rejected after reaching the capacity)
Disadvantages: it can not handle burst traffic, but it can solve the problems caused by burst traffic
4. Token bucket algorithm
Token Bucket algorithm is the most commonly used algorithm in network Traffic Shaping and Rate Limiting. Typically, Token Bucket algorithm is used to control the number of data sent to the network and allow the sending of burst data.
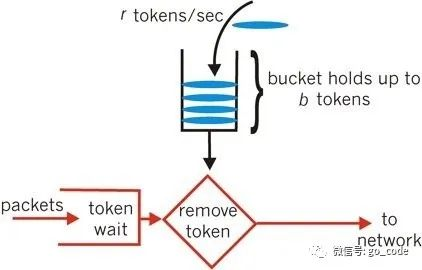
Token bucket algorithm: there is a fixed bucket in which tokens are stored. At first, the bucket is empty. The system will put fixed tokens into the bucket according to a fixed time. A request will fetch tokens from the bucket. If there is no token in the bucket, the request will be rejected
type TokenBucket struct {
rate int64 //Fixed token putting rate, r/s
capacity int64 //Barrel capacity
tokens int64 //Current number of token s in bucket
lastTokenSec int64 //Timestamp of last token put in bucket s
lock sync.Mutex
}
func (l *TokenBucket) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
now := time.Now().Unix()
l.tokens = l.tokens + (now-l.lastTokenSec)*l.rate // Add token first
if l.tokens > l.capacity {
l.tokens = l.capacity
}
l.lastTokenSec = now
if l.tokens > 0 {
// And a token. Get a token
l.tokens--
return true
} else {
// No token, reject
return false
}
}
func (l *TokenBucket) Set(r, c int64) {
l.rate = r
l.capacity = c
l.tokens = 0
l.lastTokenSec = time.Now().Unix()
}
- The token bucket puts a certain token in a certain time
- The capacity of the bucket is limited. If the bucket is full, the newly added token will be discarded
- If there is no token in the bucket, the request will be discarded by flow restriction
The token bucket algorithm actually limits the average inflow rate, so it can allow a certain burst traffic without other problems