preface
Hello, I'm 👉 [year of fighting]
This issue introduces you how to use python to crawl vipshop product information, involving Chinese urlencode coding, multi-layer url search, excel table operation and so on. I hope it will be helpful to you.
Statement: This article is for learning reference only
1. Web page analysis
1.1 official website analysis
Official website address: https://www.vip.com/?wxsdk=1&wq=1&wxsdk=1
Take men's t-shirts and short sleeves as an example:
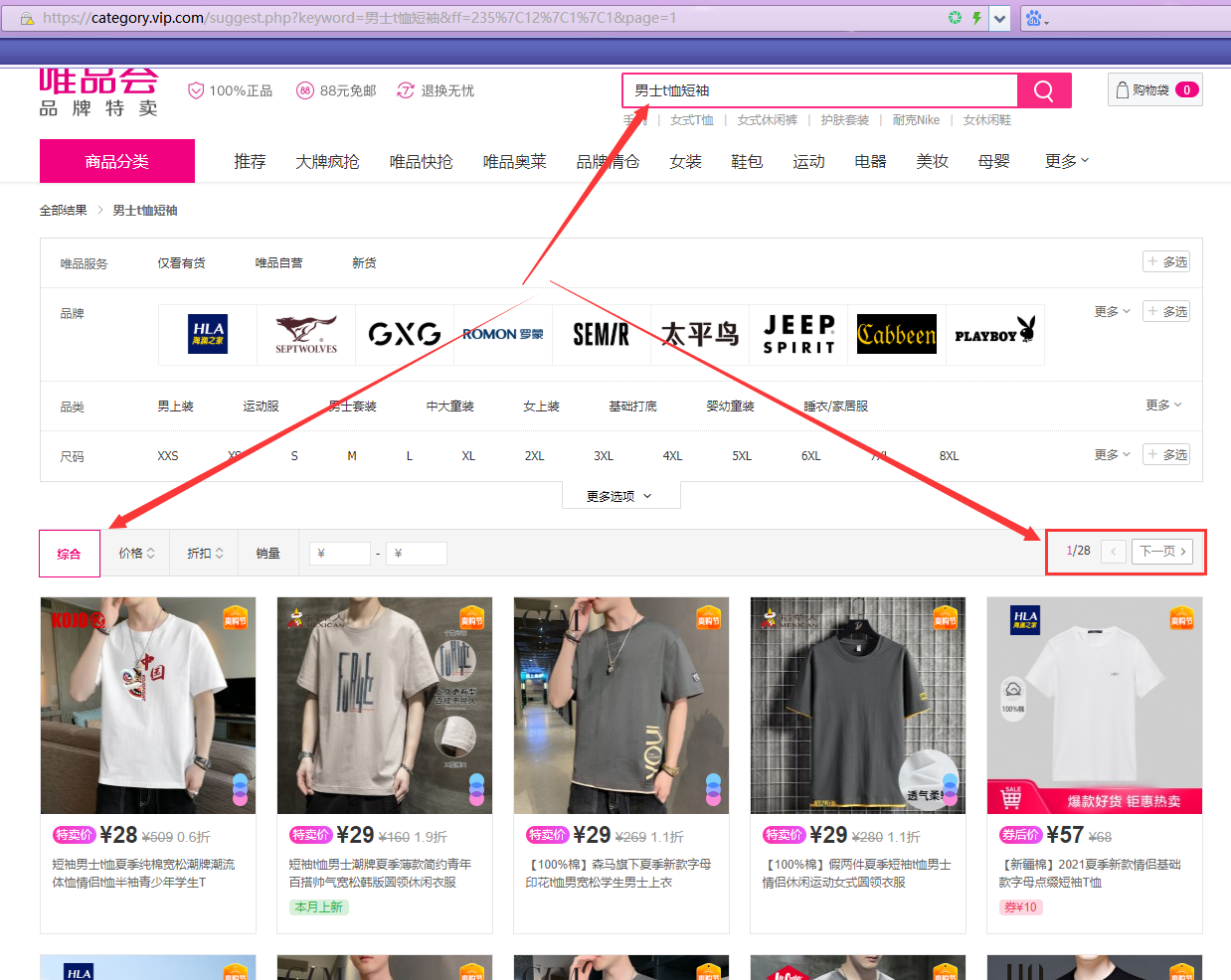
Pay attention to the three information in the figure: name, sort and page number. The men's t-shirt short sleeves are sorted by default, with a total of 28 pages.
When we pull down the scroll bar on the right to the bottom, we will find that the goods on the page are increasing, indicating that there is ajax interaction on the web page, that is, the web address in the browser search box is not the actual goods information web address, so we need F12 to find the actual goods information web address.
Press F12 or right-click to review the element and search the first product information (fuzzy search):
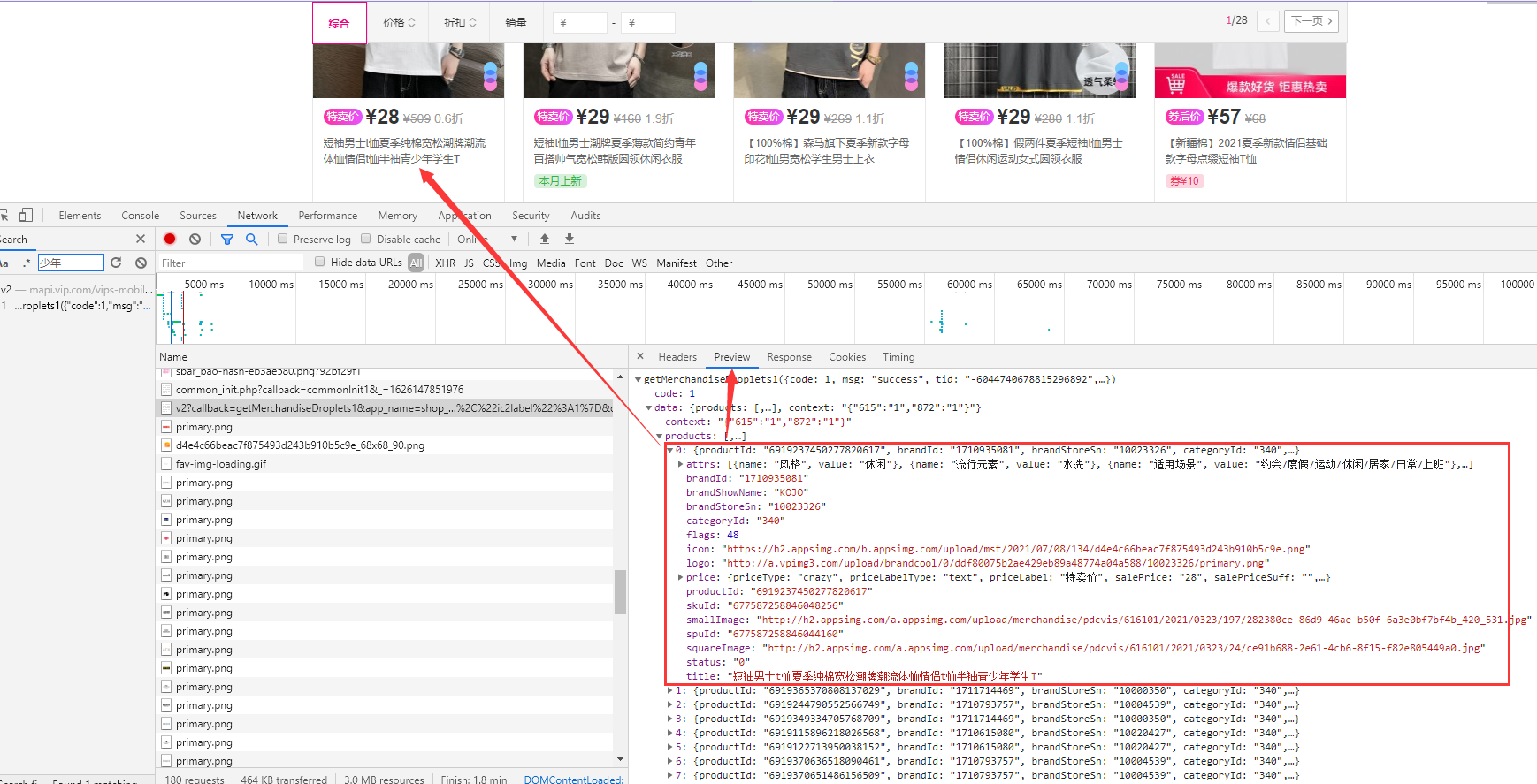
It can be found that the product information is returned in json format, numbered 0-49, with a total of 50 items.
Requested URL:
https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2?callback=getMerchandiseDroplets1&app_name=shop_pc&app_version=4.0&warehouse=VIP_BJ&fdc_area_id=101102101&client=pc&mobile_platform=1&province_id=101102&api_key=70f71280d5d547b2a7bb370a529aeea1&user_id=&mars_cid=1626140565769_ab62db3562bea66ece4d3be6cf1e103b&wap_consumer=a&productIds=6919237450277820617%2C6919122713899473032%2C6919244790552566749%2C6919365370808137029%2C6919349334705768709%2C6919115896218026568%2C6919370636518090461%2C6919276419446043264%2C6919122713950038152%2C6919370651486156509%2C6919329002893560922%2C6919237439834453401%2C6919350735782819229%2C6919371081433470225%2C6919122713916360840%2C6919229945477842824%2C6919327140812408075%2C6919283957337024212%2C6919335984255330371%2C6919299866232381888%2C6919338906091451537%2C6919259535495841540%2C6919236171781461080%2C6919357601690551060%2C6919236172000633944%2C6919204353510574422%2C6919194074239392213%2C6919286603892718595%2C6919309792697436509%2C6919279626107011266%2C6919345925870185309%2C6919289690701309596%2C6919246471294097610%2C6919193978543121053%2C6919357586575472842%2C6919376731742848261%2C6919315821509577802%2C6919286827270069127%2C6919311453429778187%2C6919308539448316757%2C6919204120777410772%2C6919376731742840069%2C6919217246785372804%2C6919386645522057307%2C6918657640750100544%2C6919115896234848840%2C6919350306559218006%2C6918750453251013140%2C6919372204827383045%2C6919365370824983877%2C&scene=search&standby_id=nature&extParams=%7B%22stdSizeVids%22%3A%22%22%2C%22preheatTipsVer%22%3A%223%22%2C%22couponVer%22%3A%22v2%22%2C%22exclusivePrice%22%3A%221%22%2C%22iconSpec%22%3A%222x%22%2C%22ic2label%22%3A1%7D&context=&_=1626154739375
Pull down the right scroll bar to the bottom. There are 3 requests in total:
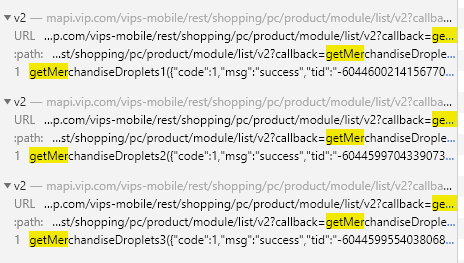
The number of goods requested in the three requests is 50, 50 and 20 respectively, that is, there are 120 goods information in total, which is consistent with the web page.
Get the links of the first three pages in sequence according to the above methods as follows:
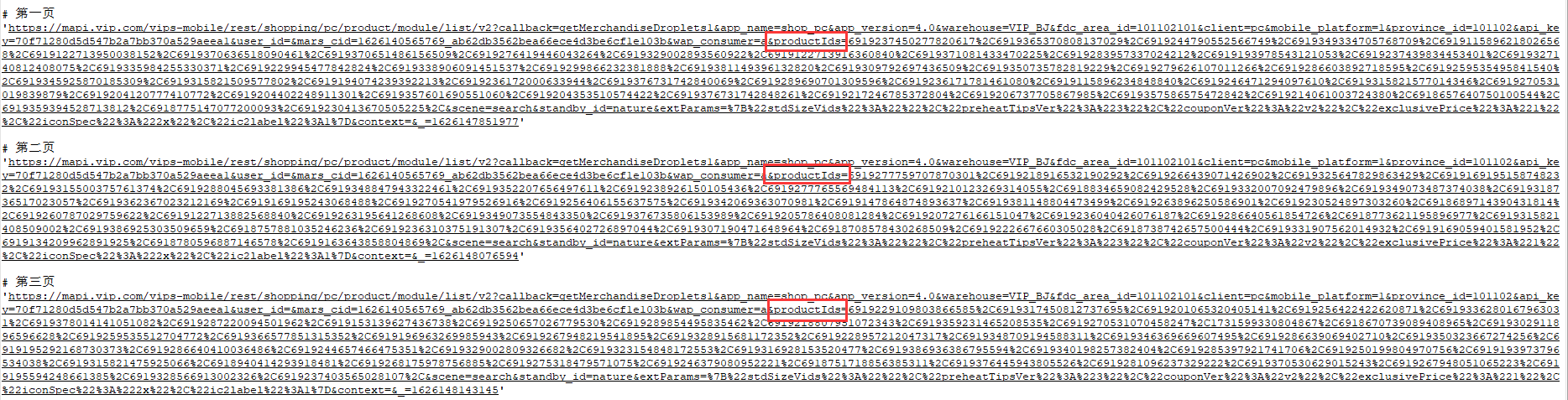
The main difference lies in the different productIds parameters. Finally_ The (underlined) parameter is also different, but this parameter has no effect on the result, so the main problem is to solve the productIds parameter.
After careful observation, you will find that the value of the productIds parameter is actually the id of all commodities requested this time. You can confirm from the number or click a commodity details page to confirm. It will not be repeated here.
So the question turns to how to get the productIds of goods?
1.2 productlds analysis
search the productId of any product:
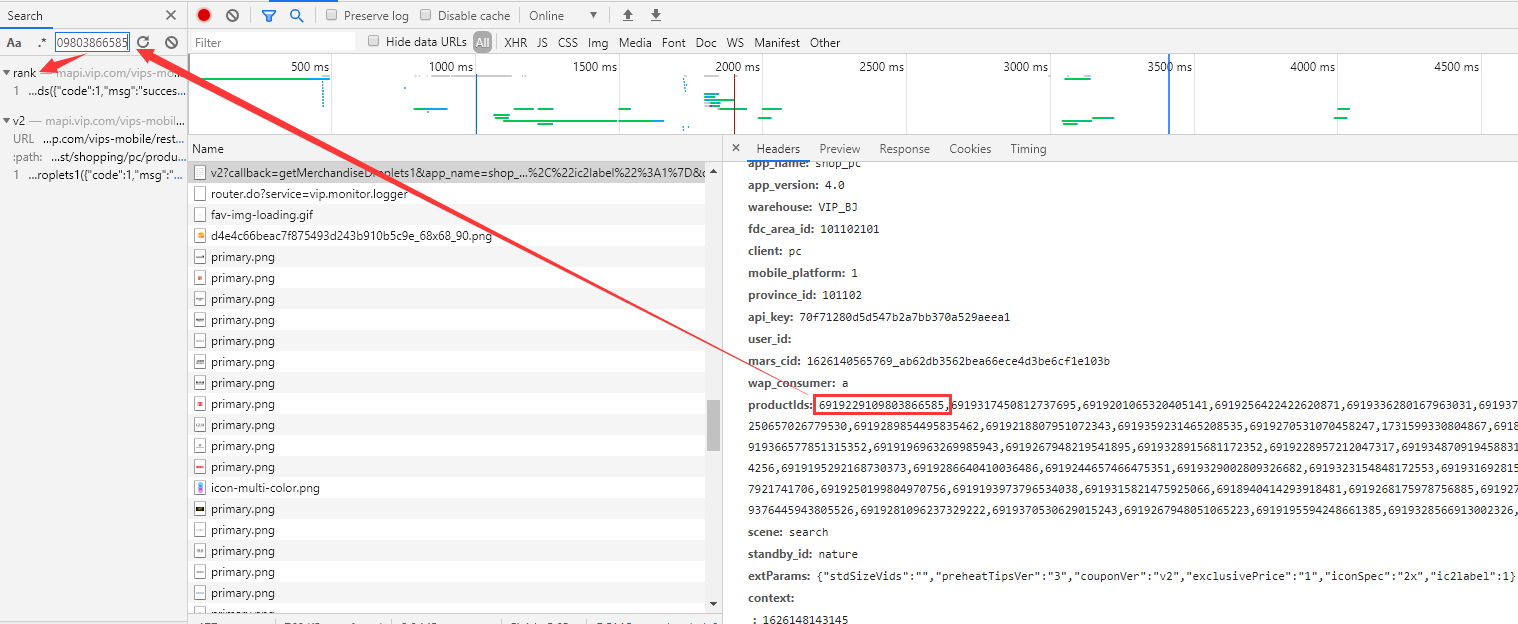
You can see a request link of rank. See the details:
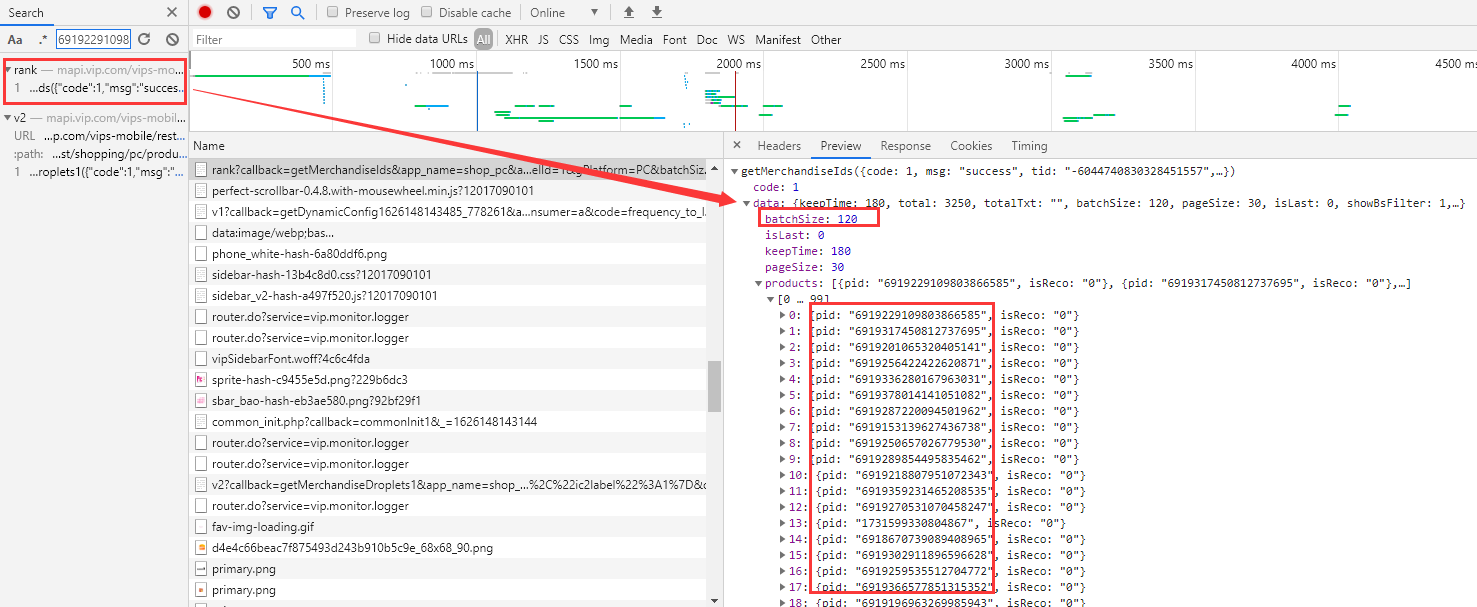
What a coincidence! There are 120 pieces of pid information here, which correspond to the 120 items on this page.
Next, let's look at the rank link on the first three pages:

The main difference is that the pageOffset parameter is different. Finally_ The (underlined) parameter is also different. This parameter can be ignored, and pageOffset increases with a tolerance of 120.
When crawling, the parameter is pageOffset = 120 * (page-1)
1.3 summary
Crawl logic:
- Get current page productIds
- Get three product information requests per page
- Save product information
2. Crawl commodity information
2.1 obtaining productids
code:
# Get product ids
def get_product_ids(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
datas = re.findall('{.*}', r.text)[0]
pid_datas = json.loads(datas)
ids = pid_datas['data']['products']
product_ids = []
for id in ids:
product_ids.append(id['pid'])
return product_ids
url: rank request link
headers: request header (requires its own cookies)
2.2 specific information of crawling goods
Guess: since we have obtained all productIds of the current page number, can we request 120 pieces of information at one time without three times?
Try it!
def get_info_test(product_ids):
product_ids_str = '%2C'.join(product_ids)
url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2?callback=getMerchandiseDroplets3&app_name=shop_pc&app_version=4.0&warehouse=VIP_HZ&fdc_area_id=104101115&client=pc&mobile_platform=1&province_id=104101&api_key=70f71280d5d547b2a7bb370a529aeea1&user_id=&mars_cid=1600153235012_7a06e53de69c79c1bad28061c13e9375&wap_consumer=a&productIds={}%2C&scene=search&standby_id=nature&extParams=%7B%22stdSizeVids%22%3A%22%22%2C%22preheatTipsVer%22%3A%223%22%2C%22couponVer%22%3A%22v2%22%2C%22exclusivePrice%22%3A%221%22%2C%22iconSpec%22%3A%222x%22%7D&context=&_=1600164018137'.format(product_ids_str)
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
result:

Tip: limit size: 50. The maximum number of requests is 50, so you still need to make three requests.
Note the Chinese code of the url when requesting:

You can use parse. In urllib Transcoding with the quote() function:

Product information resolution code:
# Get product specific information
def get_product_infos(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
product_infos = re.findall('{.*}', r.text)[0]
infos = json.loads(product_infos)
infolsts = infos['data']['products']
allinfo = []
for lst in infolsts:
try:
# Commodity id
id = lst['productId']
# title
title = lst['title']
# brand
brand = lst['brandShowName']
# market value
price0 = lst['price']['marketPrice']
# price
price1 = lst['price']['salePrice']
# link
brandId = lst['brandId']
href = 'https://detail.vip.com/detail-{}-{}.html'.format(brandId,id)
oneinfo = [id,title,brand,price0,price1,href]
print(oneinfo)
allinfo.append(oneinfo)
except:
continue
return allinfo
result:

2.3 saving data
We use openpyxl to save data to excel file:
# Save data
def insert2excel(filepath,allinfo):
try:
if not os.path.exists(filepath):
tableTitle = ['commodity id','title','brand','market value','price','Product link']
wb = Workbook()
ws = wb.active
ws.title = 'sheet1'
ws.append(tableTitle)
wb.save(filepath)
time.sleep(3)
wb = load_workbook(filepath)
ws = wb.active
ws.title = 'sheet1'
for info in allinfo:
ws.append(info)
wb.save(filepath)
return True
except:
return False
result:
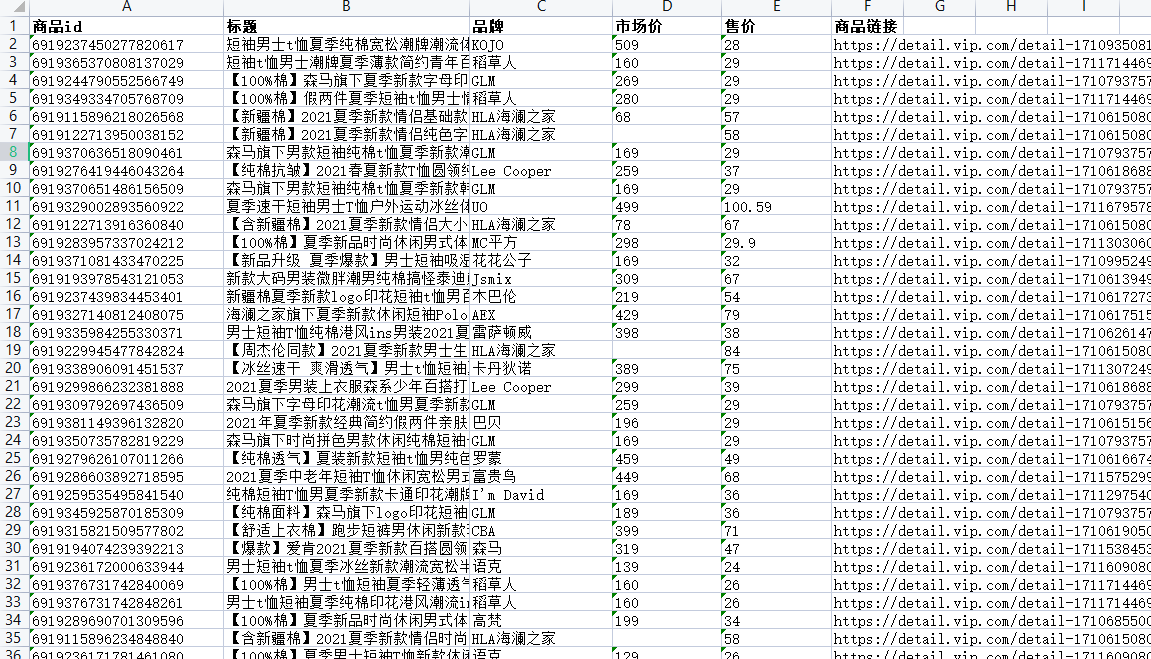
Here we only take the previous three pages of goods as an example.
2.4 main function
3. Summary
This issue mainly introduces you how to analyze the logic of web page data acquisition step by step. You should pay attention to the following points:
-
Check whether the web page data is loaded asynchronously
-
How to find the actual request url and whether transcoding is required
-
Data saving
The above is all the content sorted out for you in this issue. Practice quickly. It's not easy to be original. Friends who like can praise, collect and share it for more people to know.
- The article provides the code of several core functions. If you need full-text code, you can reply to "vipshop" in the background to obtain it.
Recommended reading
Pandas+Pyecharts | second hand housing data analysis + visualization on a platform in Beijing
Pandas+Pyecharts | 2021 comprehensive ranking analysis of Chinese universities + visualization
Visual | Python drawing geographic track map of high color typhoon
Visualization | analyze nearly 5000 tourist attractions in Python and tell you where to go during the holiday
Visual | Python exquisite map dynamic display of GDP of provinces and cities in China in recent 20 years
Visualization | Python accompany you 520: by your side, by your side
Reptile Python gives you a full set of skin on the official website of King glory
Crawlers use python to build their own IP proxy pool. They don't worry about insufficient IP anymore!
Tips | 20 most practical and efficient shortcut keys of pychar (dynamic display)
Tips | 5000 words super full parsing Python three formatting output modes [% / format / f-string]
Tips | python sends mail regularly (automatically adds attachments)
Reptile Python gives you a full set of skin on the official website of King glory
Crawlers use python to build their own IP proxy pool. They don't worry about insufficient IP anymore!
The article starts with WeChat official account "Python when the year of the fight", every day there are python programming skills push, hope you can love it.
