https://blog.csdn.net/huangyu1985/article/details/103939462
1. Introduction
The bottom layer of ByteBuffer is through byte Array is used to store data. The so-called direct buffering means that byte arrays are stored outside the heap and do not exist on the jvm heap, which is not constrained by jvm garbage collection.
2. Creation methods of direct buffer and Heap Buffer
There are two ways to create a ByteBuffer: allocate and allocateDirect. Heapbytebuffer (Heap Buffer) is created through allocate, Source code As follows:
// Create Heap Buffer and return HeapByteBuffer
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
HeapByteBuffer inherits from ByteBuffer, in which byte array is stored data
public abstract class ByteBuffer extends Buffer
implements Comparable<ByteBuffer> {
// byte array for storing data
final byte[] hb; // Non-null only for heap buffers
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset) {
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
....
}
Directbytebuffer is created through allocateDirect. The source code is as follows:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
In the process of creating DirectByteBuffer, the space for storing data is allocated and initialized through the native method, and finally the DirectByteBuffer is associated with the array of storing data through a memory address. The source code is as follows:
DirectByteBuffer(int cap) {
....
base = unsafe.allocateMemory(size); // Allocate memory space
....
unsafe.setMemory(base, size, (byte) 0); // Memory space initialization
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1)); // Get memory space address
} else {
address = base;
}
....
}
3. Why direct buffering is needed
If heap buffering is used, the java heap belongs to user space. Take IO input as an example. First, the user space process requests a disk space data from the kernel, and then the kernel reads the disk data into the kernel space buffer Then, the user space process reads the data in the kernel space buffer into its own buffer, and then the process can access and use these data, as shown in the following figure: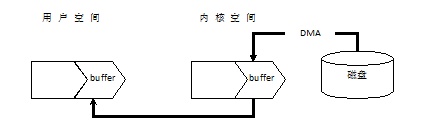
In the above process, with a data copy, there must be performance loss in high concurrency scenarios. Direct buffering solves this problem. In the current operating system, the distinction between user space and kernel space is generally realized by virtual memory, so both user space and memory space are in virtual memory. Using virtual memory is nothing more than because of its two advantages: first, it can make multiple virtual memory addresses point to the same physical memory; Second, the space of virtual memory can be larger than that of physical memory. For the first point, when performing IO operations, you can point the buffer area of user space and the buffer area of kernel space to the same physical memory. In this way, programs in user space do not need to go to kernel space to retrieve data, but can be accessed directly, avoiding data copying and improving performance.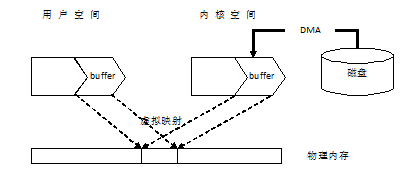
Another point of knowledge: when using HeapByteBuffer, why do you need to copy data from disk to buffer? Why can't you copy data directly from disk to buffer. This copy process is also reflected from the jdk source code, as follows:
/**
* var0: File descriptor, which represents the file handle of the data to be read
* var1: The ByteBuffer we created will write the data of the file into this buffer
*/
static int read(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {
// If the buffer is read-only, an error is reported directly
if (var1.isReadOnly()) {
throw new IllegalArgumentException("Read-only buffer");
} else if (var1 instanceof DirectBuffer) {
// If it is a DirectBuffer, write the file contents directly to the buffer
return readIntoNativeBuffer(var0, var1, var2, var4);
} else {
// If it is a HeapByteBuffer, create a DirectByteBuffer first
ByteBuffer var5 = Util.getTemporaryDirectBuffer(var1.remaining());
int var7;
try {
// Write the contents of the file to DirectByteBuffer first
int var6 = readIntoNativeBuffer(var0, var5, var2, var4);
var5.flip();
if (var6 > 0) {
// Then write the contents of DirectByteBUffer into the incoming HeapByteBuffer
var1.put(var5);
}
var7 = var6;
} finally {
Util.offerFirstTemporaryDirectBuffer(var5);
}
return var7;
}
}
From the source code, I did make a copy. In fact, I was accommodating some implementation details of the HotSpot VM in OpenJDK. HeapByteBuffer stores the byte array of the object on the Java heap, while the GC in HotSpot VM is called "compacting GC", which moves the object except CMS. If you want to pass the reference of a byte [] object in Java to the native code and let the native code directly access the contents of the array, you must ensure that the byte [] object cannot be moved when the native code accesses, that is, it must be pinned. Unfortunately, due to some trade-offs, HotSpot VM decided not to implement object pinning at the single object level. If you want to pin, you have to disable GC temporarily - that is, you have to pin the whole Java heap. This is how HotSpot VM implements the Critical API of JNI. It's not so easy to use. So Oracle/Sun JDK / OpenJDK uses a little detour. It assumes that copying the content in byte [] behind HeapByteBuffer once is an operation with acceptable time overhead, and that the real I/O may be a very slow operation. So it first copies the content of byte [] behind HeapByteBuffer to the native memory behind a DirectByteBuffer. This copy will involve sun misc. Unsafe. Behind the call of copymemory() is an implementation similar to memcpy(). In essence, this operation will not allow GC during the whole copy process, although the implementation method is different from JNI's Critical API. (specifically, Unsafe.copyMemory() is an intrinsic method of HotSpot VM. There is no safepoint in the middle, so GC cannot occur). Then, after the data is copied to the native memory, it's easy to do real I/O. pass the native memory address behind the DirectByteBuffer to the function that really does I/O. There is no need to access Java objects to read and write I/O data.
4. Advantages and disadvantages of direct buffering
4.1 advantages
As analyzed earlier, when performing IO operations, such as file reading and writing or socket reading and writing, the copy performance is improved.
Note that it is limited to scenarios with IO operations
4.2 disadvantages
In the scenario of non IO operation, for example, only doing data encoding and decoding without dealing with the machine hardware, the copy action will not occur even if the HeapByteBuffer is used. If the DirectByteBuffer is still used at this time, because the data storage part is stored outside the heap, the allocation and release of memory space is more complex than the heap memory, and the performance is slightly slower, In netty, it is solved through the buf pool scheme, which will be explained in detail in the subsequent netty blog.
Based on this, we can summarize the usage scenarios of HeapByteBuffer and DirectByteBuffer: for the codec operation of back-end services, HeapByteBuffer is used, and for IO communication, DirectByteBuffer is used.