Let's start with the most familiar * Java Collections Framework (JCF) *.
To introduce Lambda expressions, Java 8 adds Java util. Function package, which contains common function interfaces, which is the basis of Lambda expression. Java collection framework also adds some interfaces to connect with Lambda expression.
First, review the interface inheritance structure of the Java collection framework:
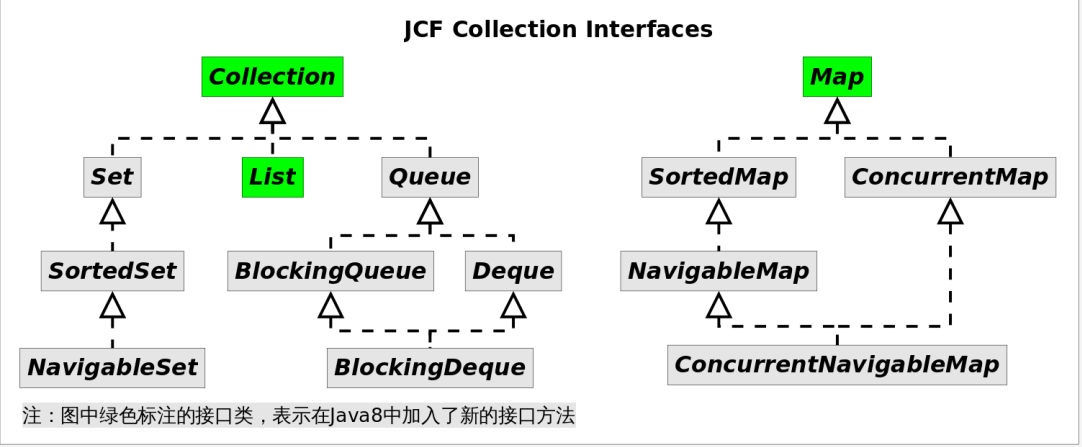
The interface class marked in green in the figure above indicates that new interface methods have been added to Java 8. Of course, due to the inheritance relationship, their corresponding subclasses will also inherit these new methods. The following table details these methods.
| Oral name | New methods added to Java 8 |
|---|---|
| Collection | removeIf() spliterator() stream() parallelStream() forEach() |
| List | replaceAll() sort() |
| Map | getOrDefault() forEach() replaceAll() putIfAbsent() remove() replace() computeIfAbsent() computeIfPresent() compute() merge() |
Most of these newly added methods use Java util. Function package, which means that most of these methods are related to Lambda expressions. We will learn these methods one by one.
New methods in Collection
As shown above, some new methods are added to the interfaces Collection and List. We take ArrayList, a subclass of List, as an example. Understanding the implementation principle of Java7ArrayList will help to understand the following.
forEach()
The signature of this method is void foreach (consumer <? Super E > action), which is used to perform the action specified by the action on each element in the container. Consumer is a function interface, in which there is only one method void accept (T) to be implemented (we will see later that the name of this method is not important at all, and you don't even need to remember its name).
Requirement: suppose there is a string list, you need to print out all strings with length greater than 3
In Java 7 and before, we can use the enhanced for loop to implement:
// Use Zeng Qiang for loop iteration
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(String str : list){
if(str.length()>3)
System.out.println(str);
}Now use the forEach() method in combination with the anonymous inner class to achieve the following:
// Use forEach() with anonymous inner class iteration
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach(new Consumer<String>(){
@Override
public void accept(String str){
if(str.length()>3)
System.out.println(str);
}
});The above code calls the forEach() method and uses the anonymous inner class to implement the consumer interface. So far, we haven't seen any benefits of this design, but don't forget the Lambda expression, which is implemented as follows:
// Use forEach() to iterate with Lambda expressions
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach( str -> {
if(str.length()>3)
System.out.println(str);
});The above code passes in a Lambda expression to the forEach() method. We don't need to know the accept() method or the Consumer interface. Type derivation helps us do everything.
removeIf()
The signature of this method is Boolean removeif (predict <? Super E > filter), which is used to delete all elements in the container that meet the conditions specified by the filter. Predict is a function interface, in which there is only one Boolean test (T) method to be implemented. Similarly, the name of this method is not important at all, because it does not need to be written when it is used.
Requirement: suppose there is a list of strings in which all strings with length greater than 3 need to be deleted.
We know that if the container needs to be deleted during the iteration process, the iterator must be used, otherwise the ConcurrentModificationException will be thrown. Therefore, the traditional writing method of the above task is:
// Deleting list elements using iterators
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Iterator<String> it = list.iterator();
while(it.hasNext()){
if(it.next().length()>3) // Delete elements with length greater than 3
it.remove();
}Now use the removeIf() method in combination with the anonymous inner class. We can implement it as follows:
// Use removeIf() in combination with anonymous name inner class implementation
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(new Predicate<String>(){ // Delete elements with length greater than 3
@Override
public boolean test(String str){
return str.length()>3;
}
});The above code uses the removeIf() method and implements the precise interface using an anonymous inner class. I believe you have figured out how to write with Lambda expression:
// Using removeIf() combined with Lambda expression
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(str -> str.length()>3); // Delete elements with length greater than 3You don't need to remember the predict interface name or the test() method name when using Lambda expression. You just need to know that a Lambda expression that returns boolean type is needed here.
replaceAll()
The signature of this method is void replaceall (UnaryOperator < E > operator), which is used to perform the operation specified by the operator on each element and replace the original element with the operation result. UnaryOperator is a function interface, in which there is only one function T apply(T t) to be implemented.
Requirement: suppose there is a string list in which all elements with length greater than 3 are converted to uppercase, and the other elements remain unchanged.
There seems to be no elegant way before Java 7:
// Using subscripts to implement element substitution
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(int i=0; i<list.size(); i++){
String str = list.get(i);
if(str.length()>3)
list.set(i, str.toUpperCase());
}The replaceAll() method combined with the anonymous inner class can be implemented as follows:
// Using anonymous inner class implementation
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(new UnaryOperator<String>(){
@Override
public String apply(String str){
if(str.length()>3)
return str.toUpperCase();
return str;
}
});The above code calls the replaceAll() method and implements the UnaryOperator interface using an anonymous inner class. We know that it can be implemented with a more concise Lambda expression:
// Implementation using Lambda expressions
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(str -> {
if(str.length()>3)
return str.toUpperCase();
return str;
});sort()
This method is defined in the List interface. The method signature is void sort (comparator <? Super E > c). This method sorts the container elements according to the comparison rules specified by c. Comparator interface is no stranger to us. One of the methods int compare(T o1, T o2) needs to be implemented. Obviously, this interface is a function interface.
Requirement: suppose there is a string list, which sorts the elements in ascending order according to the length of the string.
Since Java 7 and the previous sort() method are in the Collections tool class, the code should be written as follows:
// Collections.sort() method
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Collections.sort(list, new Comparator<String>(){
@Override
public int compare(String str1, String str2){
return str1.length()-str2.length();
}
});You can now use list directly Sort () method, combined with Lambda expression, can be written as follows:
// List.sort() method combined with Lambda expression
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.sort((str1, str2) -> str1.length()-str2.length());spliterator()
The method signature is splitter < E > splitter (), which returns the container's separable Iterator. From the name, this method is a bit like the iterator() method. We know that Iterator is used to iterate containers, and splitter has similar functions, but they are different as follows:
-
The splitter can iterate one by one or batch like the Iterator. Batch iteration can reduce the cost of iteration.
-
The splitter is separable. A splitter can try to split into two by calling the splitter < T > trysplit() method. One is this and the other is the newly returned one. The elements represented by the two iterators do not overlap.
You can call splitter. Com (multiple times) Trysplit () method to decompose the load for multithreading.
stream() and parallelStream()
stream() and parallelStream() return the stream view representation of the container respectively. The difference is that parallelStream() returns parallel streams. Stream is the core class of Java functional programming, which we will learn in later chapters.
New methods in Map
Compared with Collection, more methods are added to Map. Let's take HashMap as an example to explore one by one. Understanding the implementation principle of Java7HashMap will help to understand the following.
forEach()
The signature of this method is void foreach (BiConsumer <? Super K,? Super V > action), which is used to perform the operation specified by the action for each Map in the Map. BiConsumer is a function interface with a method void accept (T, t, u, U) to be implemented. Don't remember the names of the binconaccept () method and binconaccept () method.
Requirement: suppose there is a number to the Map corresponding to English words, please output all the mapping relationships in the Map
Java 7 and previous classic codes are as follows:
// Java 7 and previous iterations Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
System.out.println(entry.getKey() + "=" + entry.getValue());
}Use map Foreach() method, combined with anonymous inner class, the code is as follows:
// Iterate the Map using forEach() in combination with anonymous inner classes
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.forEach(new BiConsumer<Integer, String>(){
@Override
public void accept(Integer k, String v){
System.out.println(k + "=" + v);
}
});The above code calls the forEach() method and implements the BiConsumer interface using an anonymous inner class. Of course, no one uses anonymous inner class writing in the actual scene, because there are Lambda expressions:
// Use forEach() with Lambda expression to iterate Map HashMap<Integer, String> map = new HashMap<>(); map.put(1, "one"); map.put(2, "two"); map.put(3, "three"); map.forEach((k, v) -> System.out.println(k + "=" + v)); }
getOrDefault()
This method has nothing to do with Lambda expressions, but it is very useful. The method signature is V getOrDefault(Object key, V defaultValue). It is used to query the corresponding value in the Map according to the given key. If it is not found, it returns defaultValue. Using this method, programmers can save the trouble of querying whether the specified key value exists
Demand; Suppose there is a number to the Map corresponding to the English word, and output the English word corresponding to 4. If it does not exist, output NoValue
// Query the value specified in the Map, and use the default value if it does not exist
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
// Java 7 and previous practices
if(map.containsKey(4)){ // 1
System.out.println(map.get(4));
}else{
System.out.println("NoValue");
}
// Java 8 uses map getOrDefault()
System.out.println(map.getOrDefault(4, "NoValue")); // 2putIfAbsent()
This method has nothing to do with Lambda expressions, but it is very useful. The method signature is V putIfAbsent(K key, V value). The function is to put the value specified by value into the Map only when there is no mapping of key value or the mapping value is null, otherwise the Map will not be changed. This method combines condition judgment and assignment into one, which is more convenient to use
remove()
We all know that there is a remove(Object key) method in the Map to delete the mapping relationship in the Map according to the specified key value; Java 8 has added the remove(Object key, Object value) method. Only when * * key is mapped to value in the current Map, * * will delete the mapping, otherwise nothing will be done
replace()
In Java7 and before, to replace the mapping relationship in the Map, you can use the put(K key, V value) method, which always replaces the original value with the new value. In order to more accurately control the replacement behavior, Java8 added two replace() methods to the Map, as follows:
-
replace(K key, V value). Only when the mapping of * * key exists in the current Map * * will use value to replace the original value, otherwise nothing will be done
-
replace(K key, V oldValue, V newValue). Only when the mapping of * * key in the current Map exists and is equal to oldValue, * * will replace the original value with newValue, otherwise nothing will be done
replaceAll()
The signature of this method is replaceall (BiFunction <? Super K,? Super V,? Extends V > function). It is used to perform the operation specified by function on each Map in the Map and replace the original value with the execution result of function. BiFunction is a function interface with a method r apply (t, u, U) to be implemented. Don't be frightened by so many function interfaces, Because you don't need to know their names when using them
Requirement: suppose there is a number to the Map corresponding to English words, please convert the words in the original mapping relationship into uppercase
Java 7 and previous classic codes are as follows:
// Replace all mapping relationships in all maps in Java 7 and before
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
entry.setValue(entry.getValue().toUpperCase());
}Using replaceAll() method and anonymous inner class, the implementation is as follows:
// Using replaceAll() combined with anonymous inner class implementation
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.replaceAll(new BiFunction<Integer, String, String>(){
@Override
public String apply(Integer k, String v){
return v.toUpperCase();
}
});The above code calls the replaceAll() method and implements the BiFunction interface using an anonymous inner class. Further, the Lambda expression is used to realize the following:
// Using replaceAll() combined with Lambda expression HashMap<Integer, String> map = new HashMap<>(); map.put(1, "one"); map.put(2, "two"); map.put(3, "three"); map.replaceAll((k, v) -> v.toUpperCase());
merge()
The signature of this method is merge (k key, V value, bifunction <? Super V,? Super V,? Extends V > remoppingfunction), which is used to:
-
If the mapping corresponding to the key in the Map does not exist or is null, associate value (cannot be null) to the key;
-
Otherwise, execute remappingFunction. If the execution result is not null, the result will be associated with the key. Otherwise, delete the mapping of the key in the Map
The BiFunction function interface in the parameter has been introduced earlier. There is a method r apply (T, u, U) to be implemented
Although the semantics of the merge() method is somewhat complex, the method is used in a clear way. A common scenario is to splice new error information into the original information, such as:
map.merge(key, newMsg, (v1, v2) -> v1+v2);
compute()
The signature of this method is compute (k key, bifunction <? Super K,? Super V,? Extensions V > remappingFunction), which is used to associate the calculation result of remappingFunction with the key. If the calculation result is null, the mapping of the key will be deleted in the Map
To realize the example of error message splicing in the above merge() method, use the compute() code as follows:
map.compute(key, (k,v) -> v==null ? newMsg : v.concat(newMsg));
computeIfAbsent()
The signature of this method is v computeifabsent (k key, function <? Super K,? Extends V > mappingFunction). Its purpose is to call mappingFunction only when there is no mapping of key value in the current Map or the mapping value is null, and associate the result with key when the execution result of mappingFunction is not null
Function is a function interface with a method r apply (T) to be implemented
computeIfAbsent() is often used to establish an initialization mapping for a key value of a Map. For example, if we want to implement a multi value mapping, the definition of Map may be Map < K, set < V > >. To put a new value into the Map, we can implement it through the following code:
Map<Integer, Set<String>> map = new HashMap<>();
// Java 7 and previous implementations
if(map.containsKey(1)){
map.get(1).add("one");
}else{
Set<String> valueSet = new HashSet<String>();
valueSet.add("one");
map.put(1, valueSet);
}
// Implementation of Java 8
map.computeIfAbsent(1, v -> new HashSet<String>()).add("yi");computeIfAbsent() is used to combine conditional judgment and addition operation, which makes the code more concise
computeIfPresent()
The signature of this method is v computeifpresent (k key, bifunction <? Super K,? Super V,? Extensions V > remoppingfunction), which is opposite to computeIfAbsent(), that is, remoppingfunction is called only when there is a mapping of key value in the current Map and it is not null. If the execution result of remoppingfunction is null, the mapping of key is deleted, Otherwise, use this result to replace the original key mapping
The function of this function is equivalent to the following code:
// Java 7 and previous code equivalent to computeIfPresent()
if (map.get(key) != null) {
V oldValue = map.get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null)
map.put(key, newValue);
else
map.remove(key);
return newValue;
}
return null;-
Java 8 adds some useful methods to the container. Some of these methods are to improve the original functions, and some are to introduce functional programming. Learning and using these methods will help us write more concise and effective code
-
Although there are many function interfaces, we don't need to know their names at all most. Type inference helps us do everything when writing Lambda expressions