Turn:
Detailed explanation of linked list of data structure (implemented in c language)
Linked list (C language)
- introduction
- Implementation of single linked list
-
- Definition of single linked list
- Initialization of single linked list
- Insertion and deletion of single linked list
- Deletion of single linked list
- Search of single linked list
- Modification of single linked list
- Establishment of single linked list
- Bidirectional linked list
- Circular linked list
- The difference between linked list and sequential list
- summary
introduction
Linear table is a common and important linear structure in data structure. In short, a linear table is a finite sequence of n data elements. There are two common implementations of linear lists, of which the most common is the linked list.
When the linked list implements the sequential list, the biggest difference from the sequential list is that the physical addresses of the two elements logically located together in the linked list are not continuous, because each of the linked list will have a pointer to the next item, and the value corresponding to the address referred to by the pointer is the value logically adjacent to the element. In this article, we will start from the single linked list and take you step by step to understand the double linked list and circular linked list.
,
Implementation of single linked list
As we mentioned above, the most typical one in the linked list is the single linked list. What is a single linked list? As the name suggests, it means that there is only one pointer to correspond to other elements in the list.
Definition of single linked list
We can clearly see that each item will have a pointer to point to the next item, but we can also find that our last item seems to have no pointer. In fact, the last pointer points to NULL, that is, our NULL.
Combined with the above figure, we can clearly see that for a linked list, it requires two types of variables: a data item and a pointer to the next item.
Here are some inline snippets.
// Define a single linked List, rename struct list to List with typedef, and name List * as ListNode
typedef struct list{
int data;
struct list *next;
}List,*ListNode;
Initialization of single linked list
For any data structure, our operations are nothing more than the basic operations of creating, destroying, adding, deleting, modifying and checking. Only by mastering these basic operations can we expand more functions
In fact, a single linked list can be divided into two types: one with a head node and the other without a head node. What is the difference between the two?
This example is a non leading node
The following is the leading node
We can clearly feel that the biggest difference between the two is that the linked list of the leading node is more in line with people's counting method. For us, it is better to maintain and operate, and we can see that the head node of the single linked list of the leading node has no data value, because we don't need it to help us access the value, just for the convenience of counting, So his data is the default type. Next, let's try to initialize a single linked list. All the methods I'm talking about here are based on the leading node. Interested friends can try how to define the non leading node by themselves
// Initialize a single linked list. Because there is a header node, the next item of the header node is the real data item 1
//Therefore, we have to give the value indicated by the pointer of the head node to represent the real first term
void init(ListNode &L)
{
//The reason for using & is that we need to return the processed value to our main function instead of copying a new value and only processing it in the function stack
//We pass in a pointer to a List element
L=(List *)malloc(sizeof(List));//Apply for a space in memory to store the header node
L->next=NULL;
//The initialization of a linked list without any elements ends
}
Insertion and deletion of single linked list
For a single linked list, if we want to delete an element at a certain position, it is obvious that the first step is to find the previous position first, and then point the next pointer of the previous element at this position to the part we want to insert, and the next pointer of the part we want to insert points to the element originally at this position
For example, we insert the P node in the third position
Then we find the second position b first. After finding it, we point a - > next to p and p - > next to b
When implemented in code, we encapsulate it into an insert function. Here we should see that we should have three parameters: list * & L, a linked list, int n, the nth position, and the element to be inserted in int e
// Be sure to judge whether the insertion position is correct
bool insert(List * &L,int n,int e)
{
if(n<1)//Check whether the location is legal
return false;
List *p=L;
int j=0
while(p!=NULL&&j<n-1)//Find the position before inserting the element
{
p=p->next;
j++;
}
if(p==NULL)
return false;//Confirm whether the insertion is beyond the range of the linked list
List *s=(List *)malloc(sizeof(List));//data to store new elements
s->data=e;
s->next=p->next;
p->next=s;
return true;
}
Deletion of single linked list
In fact, the principle of deletion and addition are also very important. The first step is to find the previous P of the position to be deleted, and then let P directly point to p - > next - > next, and then clean up the P in the memory
For example, delete the third c
bool remove(List * &L,int n)
{
if(n<1)//Check whether the location is legal
return false;
List *p=L;
int j=0
while(p!=NULL&&j<n-1)//Find the location before deleting the element
{
p=p->next;
j++;
}
if(p==NULL)
return false;//Confirm whether the insertion is beyond the range of the linked list
List *q=p->next;
p->next=q->next;
free(q);
return true;
}
Search of single linked list
After writing here, it is estimated that many careful friends have found that our previous string of search for the n-1 position and insertion operation have basically not changed, but only the later logical operation. Therefore, we can use a method to package the previous block for our maintenance
List * getNode(List * &L,int n)
{
if(n<1)//Check whether the location is legal
return NULL;
List *p=L;
int j=0
while(p!=NULL&&j<n)//Find the location of the element
{
p=p->next;
j++;
}
return p;//If p is NULL, it will also return NULL
]
Modification of single linked list
In fact, as long as it can be written for search, modification is just to modify the data item on the basis of search
void changeNode(List * &L,int n,int e)
{
List *p=getNode(List * &L,int n);//Directly call the lookup function we have written
if(p!=NULL)
p->data=e;
]
Establishment of single linked list
The establishment of single linked list is divided into two modes, one is head interpolation and the other is tail interpolation
Head insertion
For example, if we want to add a new element p to the linked list, the method of header insertion is to add it to the back of the header node every time
Tail interpolation
For example, if we want to add a new element p to the linked list, the tail interpolation method is to add it to the back of the last node every time
For head insertion
List * createbyhead(List * &L)//An initialized new table
{
List *p=L;
int n;
do{
scanf("%d",&n);
List *s=(List *)malloc(sizeof(List));
s->next=p->next;//The next node of the new node refers to the next node of the head node
p->next=s;//Insert the new node into the top of the table
s->data=n;
}while(getchar()='n')//Enter indicates that the input is complete
return p;
}
For tail interpolation
List * createbytail(List * &L)//An initialized new table
{
List *tail=L;//Create a tail pointer tail
int n;
do{
scanf("%d",&n);
List *p=(List *)malloc(sizeof(List));
p->data=n;//The p pointer is every time we want to insert a new item
tail->next=p;///Insert new item at the end of the table
tail=p;//The tail pointer moves backward again
}while(getchar()='n')//Enter indicates that the input is complete
tail->next=NULL;//Ensure that the tail pointer points to NULL every time
return p;
}
Bidirectional linked list
A two-way list can also be referred to as a double linked list for short. What is a double linked list? Compared with a single linked list, a double linked list is a linked list with two pointers, one pointing to the successor node and the other pointing to the predecessor node. Combined with the single linked list introduced above, we will not find that a double linked list is nothing more than multiple pointers. The definition is as follows:
typedef struct Doublelist{
int data;
struct Doublelist *next;
struct Doublelist *prior;
}Dlist;
Therefore, when we add, delete, check and change the two-way linked list, we only need to take into account its precursor pointer every time
Although the double linked list is a little more difficult than the single linked list, in fact, if we understand it, adding and deleting is just an operation on these three nodes, such as initializing init()
void init(Dlist * &L)
{
L=(Dlist *)malloc(sizeof(Dlist));
L->next=NULL;
L->prior=NULL;
}
For the double linked list, the insertion is a little more difficult than the single linked list, because for the single linked list, each insertion is limited to only one item in front of the insertion position and two pointers of the newly inserted item, while the double linked list needs to consider three pointers (the next pointer of the previous item, the prior pointer of the newly inserted item and the next pointer), but it is not very difficult to understand
bool insertDlist(Dlist * &L,int n,int e)
{
if(n<1)
return false;
Dlist *p=L;
int i =0;
while(p!=NULL&&i<n-1)//First find the node before the insertion position
{
p=p->next;
i++;
}
if(p==NULL)
return false;
Dlist *q=p-next;
Dlist *s=(Dlist *)malloc(Dlist);
s->data=e;
q->prior=s;
s->next=q;
s->prior=p;//Don't forget to point to the front pointer
p->next=s;
return true
}
In addition to adding operations, there are also search, delete operations and so on. I won't show you the code here. I hope you can realize it in private
Circular linked list
The circular list is different from the circular list
I think after the above detailed introduction to the single linked list, you should be able to skillfully understand the working principle of the linked list here, so I'll only give you a rough introduction to the next circular linked list, and I won't say more about the specific details
Definition of circular linked list
typedef struct Clist{
int data;
struct Clist *next;
};
void init(struct Clist * &L)//No item in the circular linked list will point to NULL, and each item has something to refer to
{
L=(struct Clist *)malloc(sizeof(struct Clist));
L->next=L;
}
As for the following interfaces, such as insert(),remove(), I won't repeat them here, because it's relatively easy to write code as long as you master the basic principles
The difference between linked list and sequential list
To store data in a sequence table, you need to apply for a large enough storage space in advance, and then store the data one by one in order. The advantage is that the storage density is high, because it does not need to store pointers like a linked list, but because its length is limited, it is not conducive to dynamic adjustment. However, because the sequence table is directly addressed based on array subscripts, the search speed is faster than the linked list, When deleting and adding at the same time, it is not as simple as the linked list. It is only necessary to operate the two items in the current position
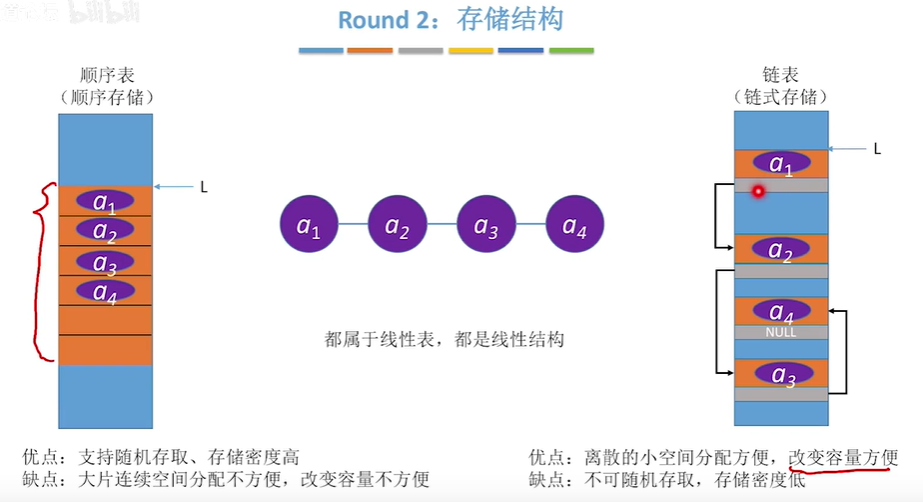
How to select linked list and sequential list?
Storage based considerations:
The storage space of the sequence table is allocated and unchanged. The size of its storage space must be clearly specified before the program is executed, that is, the "maxsize" must be set appropriately in advance, which will cause waste if it is too large and overflow if it is too small. When it is difficult to estimate the length or storage scale of linear table, sequential table should not be used; The linked list does not need to estimate the storage scale in advance.
2. Based on the consideration of operation:
If the frequent operation is to access data elements by serial number, it is obvious that the sequential list is better than the linked list; When inserting and deleting in the sequence table, half of the elements in the table will be moved on average. When the amount of information of data elements is large and the table is long, this should not be ignored; Insert and delete in the linked list. Although the insertion position should also be found, the operation is mainly a comparison operation. From this point of view, it is obvious that the linked list is better than the sequential list.
3. Based on environmental considerations:
The sequential list is easy to implement. There are array types in any high-level language. The operation of the linked list is based on pointers. Relatively speaking, the former is simpler
summary
For learning data structure, linear table is only the most basic. I hope I can make persistent efforts and understand its principle. Finally, I hope you can praise, pay attention and support. Thank you~~~~
Turn:
Detailed explanation of linked list of data structure (implemented in c language)
--Posted from Rpc