Detailed explanation of python crawler
1. Basic concepts
1.1 what is a reptile
Web crawler is a program or script that automatically grabs Internet information according to certain rules. Other infrequently used names include ants, automatic indexing, emulators, or worms. With the rapid development of the network, the world wide web has become the carrier of a large amount of information. How to effectively extract and use this information has become a great challenge. For example: AltaVista, Yahoo! And Google, as a tool to assist people in retrieving information, there are also some limitations. The goal of general search engine is to maximize the network coverage, and the returned results include a large number of web pages that users do not care about. In order to solve the above problems, crawlers that directionally grab relevant web resources came into being.
Due to the diversity of Internet data and the limitation of resources, capturing and analyzing web pages according to user needs has become the mainstream crawling strategy. As long as the data you can access through the browser can be obtained through the crawler. The essence of the crawler is to simulate the browser to open the web page and obtain the part of the data we want in the web page.
1.2 why Python is suitable for Crawlers
Because of the scripting characteristics of python, Python is easy to configure and flexible in character processing. In addition, python has rich network capture modules, so the two are often linked together.
Compared with other static programming languages, such as java, c#, C + +, python, the interface for capturing web documents is more concise; Compared with other dynamic scripting languages, such as perl, shell, Python's urlib2 package provides a more complete API for accessing web documents. In addition, crawling web pages sometimes needs to simulate the behavior of the browser, and many websites are blocked from crawling stiff crawlers. This is that we need to simulate the behavior of user agent to construct appropriate Requests, such as simulating user login and simulating the storage and setting of session/cookie. In Python, there are excellent third-party packages to help you, such as Requests and mechanism.
The captured web pages usually need to be processed, such as filtering html tags, extracting text, etc. python's beautiful soap provides a concise document processing function, which can complete the processing of most documents in very short code.
1.3. Python crawler components
Python crawler architecture is mainly composed of five parts: scheduler, URL manager, web page Downloader, web page parser and application (crawling valuable data).
Scheduler: it is equivalent to the CPU of a computer and is mainly responsible for scheduling the coordination among URL manager, downloader and parser.
URL Manager: includes the URL address to be crawled and the URL address that has been crawled to prevent repeated and circular crawling of URLs. The implementation of URL manager is mainly realized in three ways: memory, database and cache database.
Web page downloader: download a web page by passing in a URL address and convert the web page into a string. The web page downloader has urllib (Python official built-in standard library), including login, proxy, cookie s and requests (third-party package)
Web page parser: parsing a web page string can extract our useful information according to our requirements, or it can be parsed according to the parsing method of DOM tree. The web page parser has regular expressions (intuitively, convert the web page into a string to extract valuable information through fuzzy matching. When the document is complex, this method will be very difficult to extract data), HTML Parser (Python built-in), beatifulsoup (third-party plug-in, which can be parsed with html.parser or lxml, which is more powerful than others), lxml (third-party plug-in, which can parse xml and HTML), HTML Parser, beautiful soup and lxml are parsed in the form of DOM tree.
Application: it is an application composed of useful data extracted from web pages.
1.4 concept of URI and URL
Before we know about crawlers, we also need to know what is a URL?
1.4.1 web pages, websites, web servers, search engines
Web page: a web page document is a simple document given to the browser for display. This document is written by Hypertext Markup Language HTML. Web documents can insert a variety of different types of resources:
- Style information - controls the look and feel of the page
- Script - add interactivity to the page
- Multimedia - images, audio, and video
All available web pages on the network can be accessed through a unique address. To access a page, simply type the address of the page, the URL, in the address bar of your browser.
Website: a website is a collection of linked web pages that share a unique domain name. Each page of a given website provides a clear link - usually in the form of clickable text - allowing users to jump from one page to another. To access the website, enter the domain name in the browser address bar, and the browser will display the main page or home page of the website.
Web server: a web server is a computer that hosts one or more web sites. "Hosting" means that all web pages and their supporting files are available on that computer. The web server will send any web page from the hosted website to any user's browser according to the request of each user. Don't confuse the website with the web server. For example, when you hear someone say, "my website is not responding", this actually means that the web server is not responding, resulting in the unavailability of the website.
Search engine: a search engine is a specific type of website to help users find pages in other websites. For example: Yes Google, Bing, Yandex, DuckDuckGo wait. Browser is a software that receives and displays web pages, and search engine is a website that helps users find web pages from other websites.
1.4.2 what is a URL
As early as 1989, Internet inventor Tim Berners Lee proposed three pillars of the website:
1) URL, which tracks the address system of Web documents
2) HTTP, a transport protocol for finding documents when a URL is given
3) HTML, a document format that allows embedding hyperlinks
The original purpose of the Web is to provide a simple way to access, read and browse text documents. Since then, the network has developed to provide access to image, video and binary data, but these improvements have hardly changed the three pillars.
Before the web, it was difficult to access documents and jump from one document to another. WWW (World Wide Web) is abbreviated as 3W, which uses a unified resource locator (URL) to mark various documents on the WWW.
The complete workflow is as follows:
1) the Web user uses the browser (specify the URL) to establish a connection with the Web server and send a browsing request.
2) the Web server converts the URL into a file path and returns information to the Web browser.
3) after the communication is completed, close the connection.
Http: Hypertext Transfer Protocol (HTTP) is the protocol used to interact between client programs (such as browsers) and WWW server programs. HTTP uses a uniform resource identifier (URI) to transmit data and establish a connection. It uses a TCP connection for reliable transmission. The server listens on port 80 by default.
URL: represents the uniform resource locator. A URL is simply the address of a given unique resource on the Web. In theory, every valid URL points to a unique resource. Such resources can be HTML pages, CSS documents, images, etc.

Composition of URL:
1) protocol part (http:): it indicates the protocol that the browser must use to request resources (the protocol is a set of methods for exchanging or transmitting data in the computer network). Generally, for websites, the protocol is HTTPS or HTTP (its unsafe version). The HTTP protocol is used here, and the "/ /" after "HTTP" is the separator;
2) domain name (www.example.com): IP address can also be used directly in a URL;
3) port part (80): use ":" as separator between domain name and port. The port is not a required part of the URL. If the port part is omitted, the default port will be adopted (the default port can be omitted).
4) resource path: the resource path includes virtual directory and file name
Virtual directory part (/ path/to /): from the first "/" after the domain name to the last "/", it is the virtual directory part. The virtual directory is also not a required part of the URL.
File name part (myfile.html): from the last "/" after the domain name to "?" So far, it is the file name part. If there is no "?", It starts from the last "/" after the domain name to "#", which is the file part.
6) parameter part (key1 = value1 & key2 = Value2): from "?" The part from the beginning to "#" is the parameter part, also known as the search part and query part.
7) somewhere in the document: from "#" to the end, it is the anchor part. An anchor represents a "bookmark" within an asset, providing a direction for the browser to display the content located in the "bookmark" location. For example, in an HTML document, the browser will scroll to the location where the anchor point is defined; On a video or audio document, the browser attempts to go to the time represented by the anchor.
Uri is a uniform resource identifier, which is used to uniquely identify a resource. URL is a uniform resource locator. It is a specific URI, that is, URL can be used to identify a resource, and also indicates how to locate the resource.
1.5 introduction module
When crawling, we will use some modules. How to use these modules?
module: it is used to logically organize Python code (variables, functions and classes). In essence, it is a py file to provide code maintainability. Python uses import to import modules. If there is no foundation, you can read this article first: https://blog.csdn.net/xiaoxianer321/article/details/116723566.
Import module:
#Import built-in modules import sys #Import standard library import os #Import a third-party library (need to install: pip install bs4) import bs4 from bs4 import BeautifulSoup print(os.getcwd()) #Print current working directory #import bs4 imports the entire module print(bs4.BeautifulSoup.getText) #From BS4 import beautiful soup imports some properties of the specified module into the current workspace print(BeautifulSoup.getText)
Installation mode 1: use the command in the terminal
Installation method 2: pycharm is installed in settings
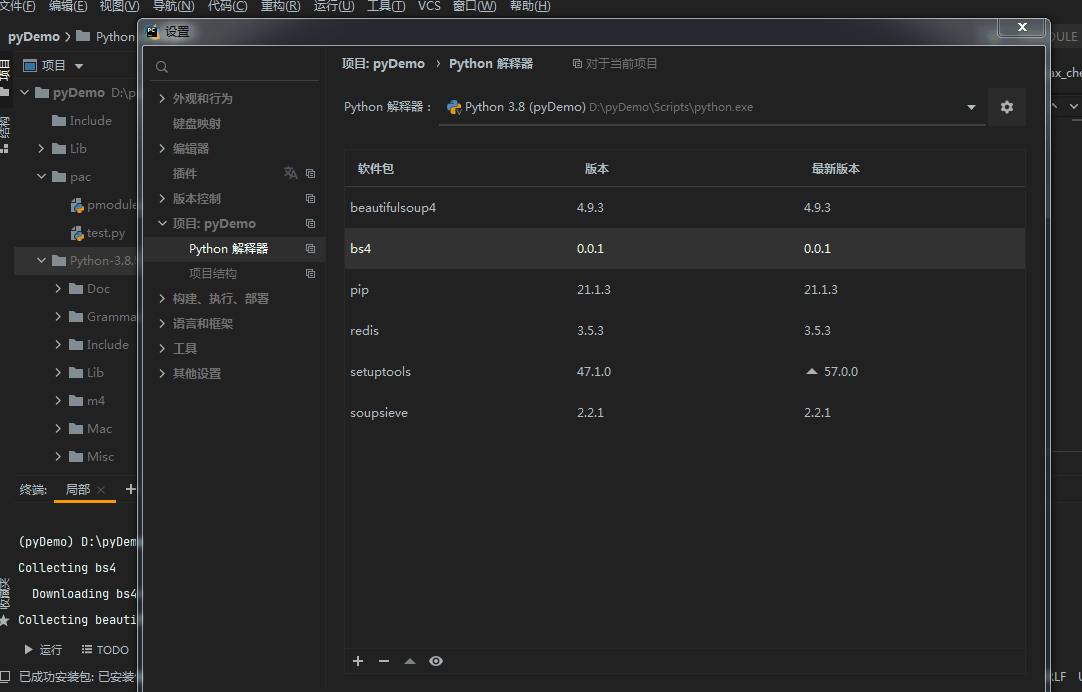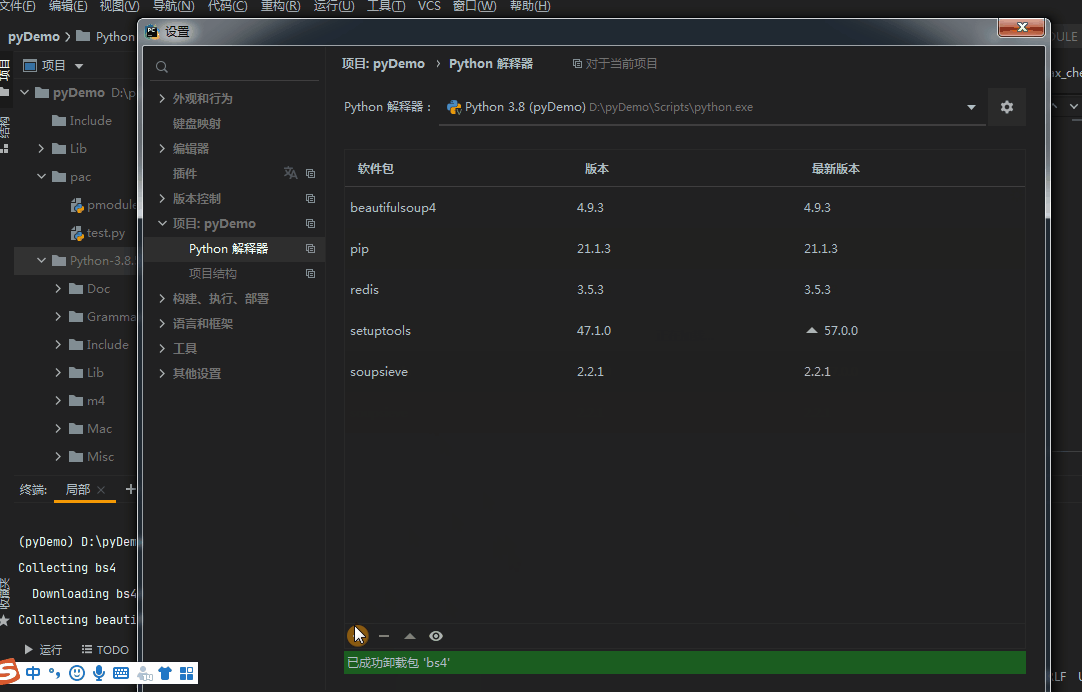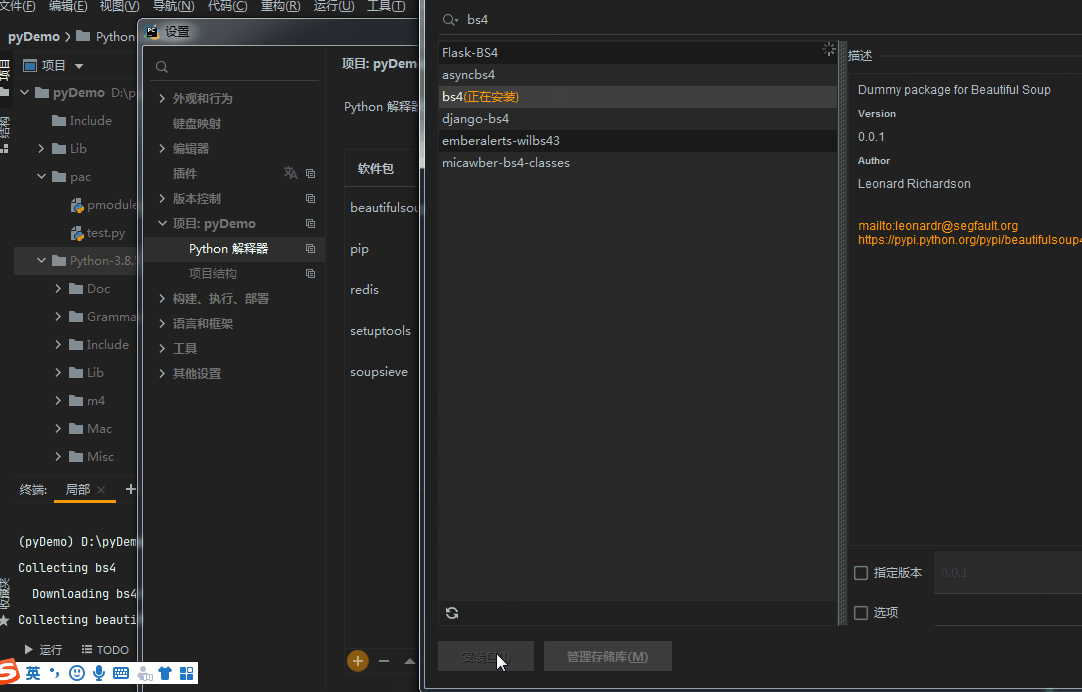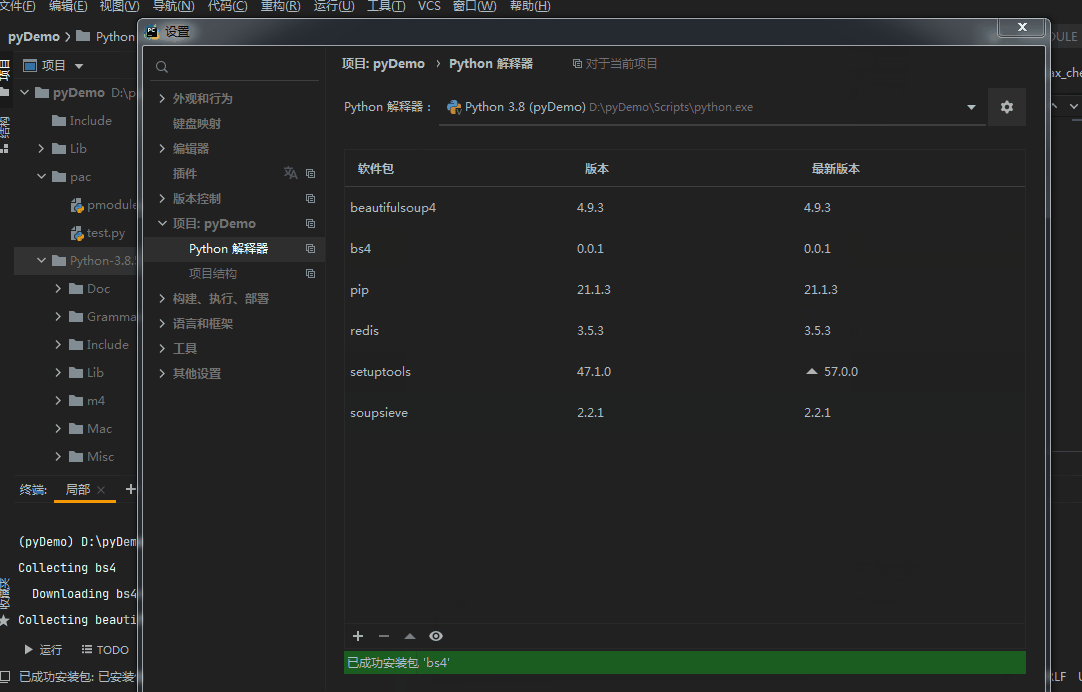
We will probably use the following modules:
import urllib.request,urllib.error #Customize URL to get web page data from bs4 import BeautifulSoup #Web page analysis and data acquisition import re #Regular expressions for file matching import xlwt #excel operation import sqlite3 #Perform SQLite database operations
2. Detailed explanation of urlib Library
Python 3 integrates the urllib and urllib 2 libraries in Python 2 into one urllib library, so we generally refer to the urllib Library in Python 3. It is a built-in standard library in Python 3 and does not need additional installation.
Four modules of urllib:
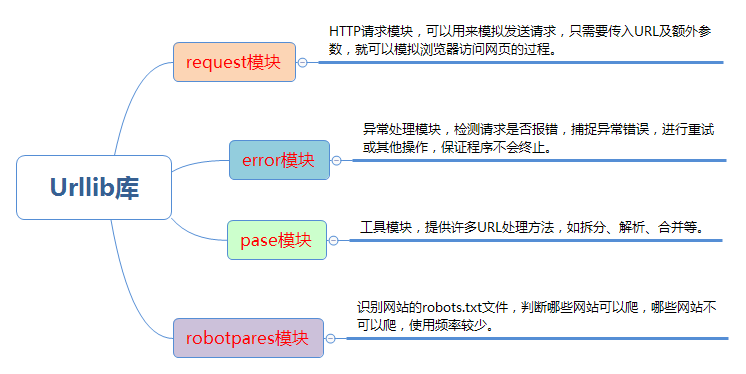
2.1. request module
The request module provides the most basic method for constructing HTTP requests. It can simulate a request initiation process of the browser. At the same time, it also handles authentication, redirections, cookies and other contents.
2.1.1,urllib.request.urlopen() function
Open a url method and return a file object HttpResponse. urlopen will send a get request by default. When the data parameter is passed in, a POST request will be initiated.
Syntax: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) Parameter Description: url: Requested url,It can also be request object data: Requested data,If this value is set, it will become post Request, if you want to pass a dictionary, you should use urllib.parse Modular urlencode()Function coding; timeout: Set the access timeout handle object of the website; cafile and capath: be used for HTTPS Request, set CA Certificate and its path; cadefault: ignore*cadefault*Parameters; context: If specified*context*,Then it must be a ssl.SSLContext example. urlopen() Return object HTTPResponse Provided methods and properties: 1)read(),readline(),readlines(),fileno(),close(): yes HTTPResponse Type data for operation; 2)info(): return HTTPMessage Object representing the header information returned by the remote server; 3)getcode(): return HTTP Status code geturl(): Return requested url; 4)getheaders(): Response header information; 5)status: Return status code; 6)reason: Return status details.
Case 1: grab Baidu with urlopen() function
import urllib.request
url = "http://www.baidu.com/"
res = urllib.request.urlopen(url) # get mode request
print(res) # Return the httpresponse object < http client. HTTPResponse object at 0x00000000026D3D00>
# Read response body
bys = res.read() # Calling the read() method yields a bytes object.
print(bys) # <!DOCTYPE html><!--STATUS OK-->\n\n\n <html><head><meta...
print(bys.decode("utf-8")) # To get the string content, you need to specify the decoding method. This part we put in the html file is Baidu's home page
# Get the HTTP protocol version number (10 is HTTP/1.0, 11 is HTTP/1.1)
print(res.version) # 11
# Get response code
print(res.getcode()) # 200
print(res.status) # 200
# Get response description string
print(res.reason) # OK
# Get the actual requested page URL (for preventing redirection)
print(res.geturl()) # http://www.baidu.com/
# Get the response header information and return the string
print(res.info()) # Bdpagetype: 1 Bdqid: 0x803fb2b9000fdebb...
# Get the response header information and return the binary tuple list
print(res.getheaders()) # [('Bdpagetype', '1'), ('Bdqid', '0x803fb2b9000fdebb'),...]
print(res.getheaders()[0]) # ('Bdpagetype', '1')
# Get specific response header information
print(res.getheader(name="Content-Type")) # text/html;charset=utf-8
After a brief understanding of using urllib request. The urlopen (URL) function will return an HTTPResponse object, which contains various information of the response after the request.
The most common way to request a url is to send a get request or a post request. In order to see the effect more conveniently, we can use this website http://httpbin.org/ To test our request.
Case 2: get request
We are http://httpbin.org/ Website, send a get test request:
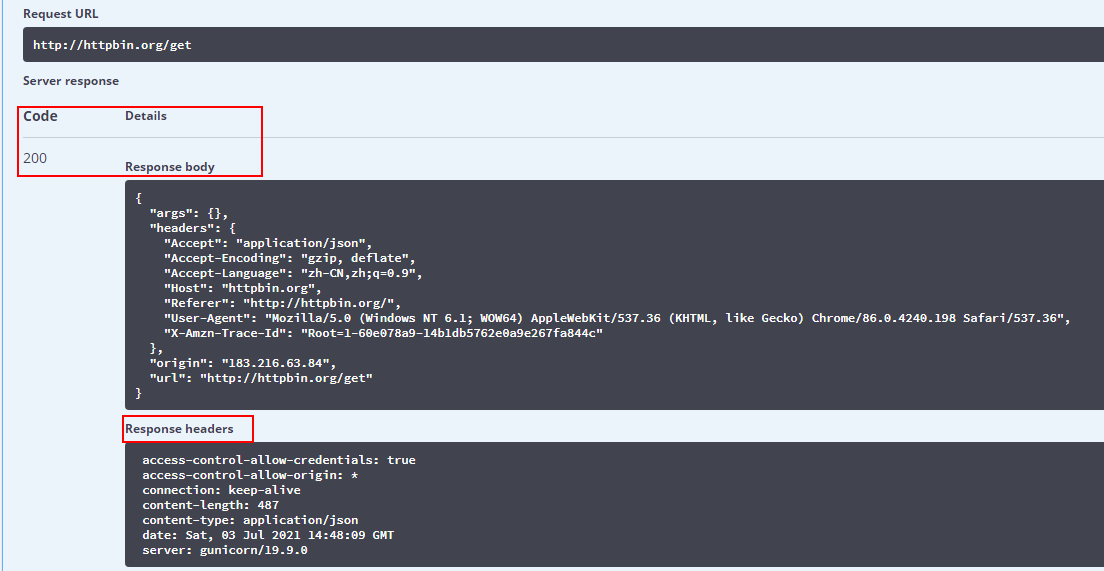
Then we are using python to simulate the browser to send a get request
import urllib.request
# Requested URL
url = "http://httpbin.org/get"
# Simulate a browser to open a web page (get request)
res = urllib.request.urlopen(url)
print(res.read().decode("utf-8"))The result of the request is as follows:
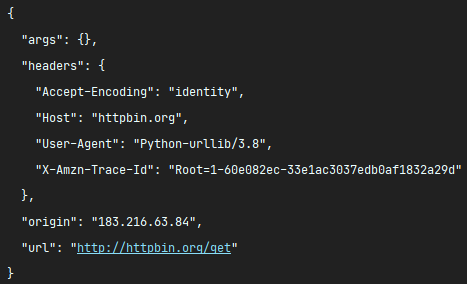
We will find that python emulates the request of the browser very much.
Case 3: pos request
import urllib.request
import urllib.parse
url = "http://httpbin.org/post"
# Encapsulate the data in the format of POST request, request the content, and pass the data
data = bytes(urllib.parse.urlencode({"hello": "world"}), encoding="utf-8")
res = urllib.request.urlopen(url, data=data)
# Output response results
print(res.read().decode("utf-8"))Simulate the request sent by the browser (the submitted data will be sent in the form of form), and the response results are as follows:
{
"args": {},
"data": "",
"files": {},
"form": {
"hello": "world"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.8",
"X-Amzn-Trace-Id": "Root=1-60e0754e-7ea455cc757714f14db8f2d2"
},
"json": null,
"origin": "183.216.63.84",
"url": "http://httpbin.org/post"
}
Case 4: camouflage Headers
Through the above case, it is not difficult to find the difference between the requests sent by urlib: "user agent". There will be a default header: user agent: Python urlib / 3.8 when urlib is used. Therefore, when we encounter some websites that verify the user agent, we may directly reject the crawler. Therefore, we need to customize the Headers to disguise ourselves as a browser.
In fact, we can also see http requests using the packet capture tool. Using the packet capture tool, we can grab get requests without specified request headers as follows: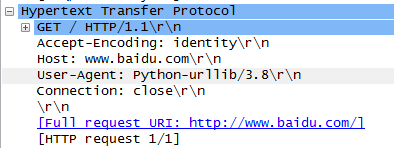
When I directly use Google browser, the user agent obtained by using the packet capture tool is as follows:

Of course, you can also view it directly in the browser:
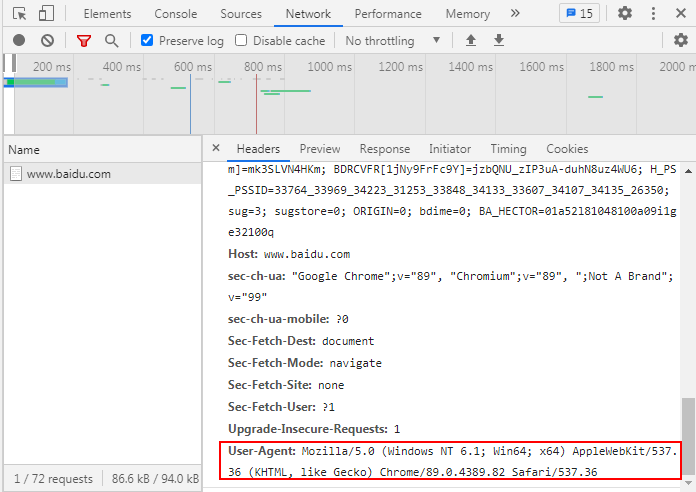
For example, when I climb the watercress net:
import urllib.request
url = "http://douban.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))
Return error: anti crawler
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 418:
HTTP 418 I'm a teapot The client error response code indicates that the server refused to make coffee because it was a teapot. This error is a reference to the hypertext coffee pot control protocol of the April Fool's Day joke in 1998.Custom Headers:
import urllib.request
url = "http://douban.com"
# Custom headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
# Urlopen (can also be a request object)
print(urllib.request.urlopen(req).read().decode('utf-8')) # To get the string content, you need to specify the decoding methodWhen I use the packet capture tool again to grab the get request with the specified request header, the results are as follows:

Case 5: setting request timeout
When we crawl web pages, we will inevitably encounter request timeout or unresponsive web addresses. In order to improve the robustness of the code, I can set the request timeout.
import urllib.request,urllib.error
url = "http://httpbin.org/get"
try:
resp = urllib.request.urlopen(url, timeout=0.01)
print(resp.read().decode('utf-8'))
except urllib.error.URLError as e:
print("time out")
Output: time out
2.1.2,urllib.request.urlretrieve() function
The urlretrieve() function is used to directly download remote data to the local
# Syntax: urlretrieve(url, filename=None, reporthook=None, data=None) # Parameter description url: Incoming URL filename: The save local path is specified (if the parameter is not specified, urllib A temporary file is generated to save the data) reporthook: Is a callback function that will be triggered when the server is connected and the corresponding data block is transmitted. We can use this callback function to display the current download progress data: finger post To the server, this method returns a two element(filename, headers)Tuples, filename Indicates the path to save to the local, header Represents the response header of the server
Use case:
import urllib.request
url = "http://www.hao6v.com/"
filename = "C:\\Users\\Administrator\\Desktop\\python_3.8.5\\film.html"
def callback(blocknum,blocksize,totalsize):
"""
@blocknum:The number of data blocks currently passed for this
@blocksize:The size of each data block, in byte,byte
@totalsize:Size of remote file
"""
if totalsize == 0:
percent = 0
else:
percent = blocknum * blocksize / totalsize
if percent > 1.0:
percent = 1.0
percent = percent * 100
print("download : %.2f%%" % (percent))
local_filename, headers= urllib.request.urlretrieve(url, filename, callback)
Case effect:
2.2. error module
urllib. The error module is urllib The exception thrown by request defines the exception class, and the basic exception class is URLError.
2.2.1 definition of HTTP protocol (RFC2616) status code
The first line of all HTTP responses is the status line, followed by the current HTTP version number, a 3-digit status code, and a phrase describing the status, separated by spaces.
The first number of the status code represents the type of current response:
1xx message - the request has been received by the server. Continue processing
2xx successful - the request has been successfully received, understood, and accepted by the server
3xx redirection - subsequent action is required to complete this request
4xx request error - the status code of 4xx class is used when it appears that the client has an error, the request contains a lexical error or cannot be executed
5xx server error - the response status code beginning with the number "5" indicates that the server is obviously in an error condition or unable to execute the request, or an error occurred when processing a correct request.
Some status codes are as follows:
| Status code | definition |
| 100 | continue. The client should continue its request. The intermittent response is used to remind the client server that the request has been received and accepted The beginning part. The client should continue to send the rest of the request, or ignore the response if the request has been sent. The server must send a final response after the request is completed. |
| 101 | Switching protocol. |
| 200 | OK. The request was successful. The information returned by the response depends on the method used in the request, for example: GET the entity corresponding to the requested resource will be sent in the response; HEAD the entity header corresponding to the requested resource will be sent in the response without a message body; POST an entity that describes or contains the results of a behavior; TRACE contains the entity of the request message received by the destination server. |
| 201 | establish. All requests were successful and a new resource was created. The original server must create the resource before returning the 201 status code. If the behavior cannot be implemented immediately, the server should respond with 202 (Accepted) instead. |
| 202 | The request has been accepted for processing, but the processing has not been completed. |
| 203 | The meta information returned in the entity header is not a valid deterministic set in the original server, but is copied locally or from a third party Collected. The current set may be a subset or superset of the original version. |
| 204 | The server has completed the request, but does not need to return entities, and may want to return updated meta information. Response package Include new or updated meta information in the form of entity header. If these headers exist, they should be associated with the requested variable Off. |
| 205 | Reset content. The server has completed the request and the user agent should reset the document view that caused the request to be sent. |
| 300 | Multiple options. The requested resource matches any one of the set of representations, each with its own special location. Agent driven collaboration The quotient information is provided to the user (or user agent) to select the preferred expression and redirect the request to its location. |
| 301 | The requested resource has been assigned to a new persistent URI and should be used by any future reference to the resource One of the URI s returned. |
| 302 | The requested resource temporarily exists at a different URI. |
| 303 | The response to the request can be found in different URI s, and you should use the GET method to the resource to GET it. |
| 307 | temporary redirect |
| 400 | The server cannot understand the request due to malformed syntax. |
| 403 | The server understands the request but refuses to complete it. Authentication is useless. The request should not be repeated. |
| 404 | Not found. The server cannot find anything that matches the request URI. |
| 408 | request timeout |
| 500 | Server error |
| 503 | Service Unavailable |
| 504 | gateway timeout |
| 505 | HTTP version is not supported |
2.2.2, urllib.error.URLError
import urllib.request,urllib.error
try:
url = "http://www.baidus.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))
# except urllib.error.HTTPError as e:
# print("please check whether the url is correct")
# URLError is urllib Superclass of request exception
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)Case effect:

URLError, urllib The basic exception class triggered by request, 403 printed here, is urllib error. Httperror and another ContentTooShortError. This exception will be thrown when the urlretrieve() function detects that the downloaded data amount is less than the expected data amount (given by the content length header).
2.3 parse module
urllib. The parse module provides many functions for parsing and building URL s. Only some are listed below
Function to parse url: urllib parse. urlparse,urllib.parse.urlsplit,urllib.parse.urldefrag
Function of component url: urllib parse. urlunparse,urllib.parse.urljoin
Construction and analysis of query parameters: urllib parse. urlencode,urllib.parse.parse_qs,
urllib.parse.parse_qsl
2.3.1,urllib.parse.urlparse
# grammar urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True) scheme:Set defaults allow_fragments:Allow fragment
Resolve the URL to a ParseResult object. The object contains six elements: that is, the composition of the URL we mentioned earlier, but the urlparse function parses it into six elements.
| attribute | Indexes | value | Value (if not present) |
|---|---|---|---|
| scheme | 0 | URL protocol | scheme parameter |
| netloc | 1 | Network location section (domain name) | Empty string |
| path | 2 | Hierarchical path | Empty string |
| params | 3 | Parameters of the last path element | Empty string |
| query | 4 | Query parameters | Empty string |
| fragment | 5 | Fragment recognition | Empty string |
Use case:
import urllib.parse
url = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2#SomewhereIntheDocument"
parsed_result = urllib.parse.urlparse(url)
print(parsed_result)
print('agreement-scheme :', parsed_result.scheme)
print('domain name-netloc :', parsed_result.netloc)
print('route-path :', parsed_result.path)
print('Path parameters-params :', parsed_result.params)
print('Query parameters-query :', parsed_result.query)
print('fragment-fragment:', parsed_result.fragment)
print('user name-username:', parsed_result.username)
print('password-password:', parsed_result.password)
print('host name-hostname:', parsed_result.hostname)
print('Port number-port :', parsed_result.port)
Output results:
ParseResult(scheme='http', netloc='www.example.com:80', path='/path/to/myfile.html', params='', query='key1=value&key2=value2', fragment='SomewhereIntheDocument')
agreement-scheme : http
domain name-netloc : www.example.com:80
route-path : /path/to/myfile.html
Path parameters-params :
Query parameters-query : key1=value&key2=value2
fragment-fragment: SomewhereIntheDocument
user name-username: None
password-password: None
host name-hostname: www.example.com
Port number-port : 802.3.2,urllib.parse.urlsplit
This is similar to urlparse, except that urlplit () does not separate the path parameters (params) from the path. This function returns 5 items named tuple: (protocol, domain name, path, query, fragment identifier)
Use case:
import urllib.parse
url = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2#SomewhereIntheDocument"
# The only difference between urlplit segmentation and params segmentation is that params will not be separated
parsed_result = urllib.parse.urlsplit(url)
print(parsed_result)
print('agreement-scheme :', parsed_result.scheme)
print('domain name-netloc :', parsed_result.netloc)
print('route-path :', parsed_result.path)
# parsed_result.params does not have this option
print('Query parameters-query :', parsed_result.query)
print('fragment-fragment:', parsed_result.fragment)
print('user name-username:', parsed_result.username)
print('password-password:', parsed_result.password)
print('host name-hostname:', parsed_result.hostname)
print('Port number-port :', parsed_result.port)2.3.3,urllib.parse.urlsplit
urllib.parse.urldefrag: if the url contains a fragment identifier, the modified url Version (excluding the fragment identifier) is returned, and the fragment identifier is returned as a separate string. If there is no fragment identifier in the url, the original url and empty string are returned.
Use case:
import urllib.parse url = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2#SomewhereIntheDocument" parsed_result = urllib.parse.urldefrag(url) print(parsed_result) # DefragResult(url='http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2', fragment='SomewhereIntheDocument') url1 = "http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2" parsed_result1 = urllib.parse.urldefrag(url1) print(parsed_result1) # Output results: # DefragResult(url='http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2', fragment='SomewhereIntheDocument') # DefragResult(url='http://www.example.com:80/path/to/myfile.html?key1=value&key2=value2', fragment='')
2.3.4,urllib.parse.urlunparse
urlunparse() receives the parameters of a list, and the length of the list is required. It must have more than six parameters, otherwise an exception is thrown.
import urllib.parse
url_compos = ('http', 'www.example.com:80', '/path/to/myfile.html', 'params2', 'query=key1=value&key2=value2', 'SomewhereIntheDocument')
print(urllib.parse.urlunparse(url_compos))
# Output results:
# http://www.example.com:80/path/to/myfile.html;params2?query=key1=value&key2=value2#SomewhereIntheDocument2.3.5,urllib.parse.urljoin
import urllib.parse
# Connect the URLs of the two parameters, and fill the missing part of the second parameter with the first parameter. If the second has a complete path, the second is the main one.
print(urllib.parse.urljoin('https://movie.douban.com/', 'index'))
print(urllib.parse.urljoin('https://movie.douban.com/', 'https://accounts.douban.com/login'))
# Output results:
# https://movie.douban.com/index
# https://accounts.douban.com/login
2.3.6,urllib.parse.urlencode
A dict can be converted into a valid query parameter.
import urllib.parse
query_args = {
'name': 'dark sun',
'country': 'China'
}
query_args = urllib.parse.urlencode(query_args)
print(query_args)
# Output results
# name=dark+sun&country=%E4%B8%AD%E5%9B%BD2.3.7,urllib.parse.parse_qs
Parse the query string provided as a string parameter, and return the data as a dictionary. The dictionary key is a unique query variable name, and the value is a list of values for each name.
import urllib.parse
query_args = {
'name': 'dark sun',
'country': 'China'
}
query_args = urllib.parse.urlencode(query_args)
print(query_args) # name=dark+sun&country=%E4%B8%AD%E5%9B%BD
print(urllib.parse.parse_qs(query_args)) # Return to dictionary
print(urllib.parse.parse_qsl(query_args)) # Return to list
# Output results
# {'name': ['dark sun'], 'country': ['China']}
# [('name ',' dark sun '), ('country', 'China')]2.4,robotparser modular
This module provides a separate class RobotFileParser , which can answer questions about whether a particular user agent can get published robots on the Web site Txt file URL problem. (/ robots.txt this file is a simple text-based access control system. The file provides the network robot with instructions about its website, which robots can access and which links cannot)
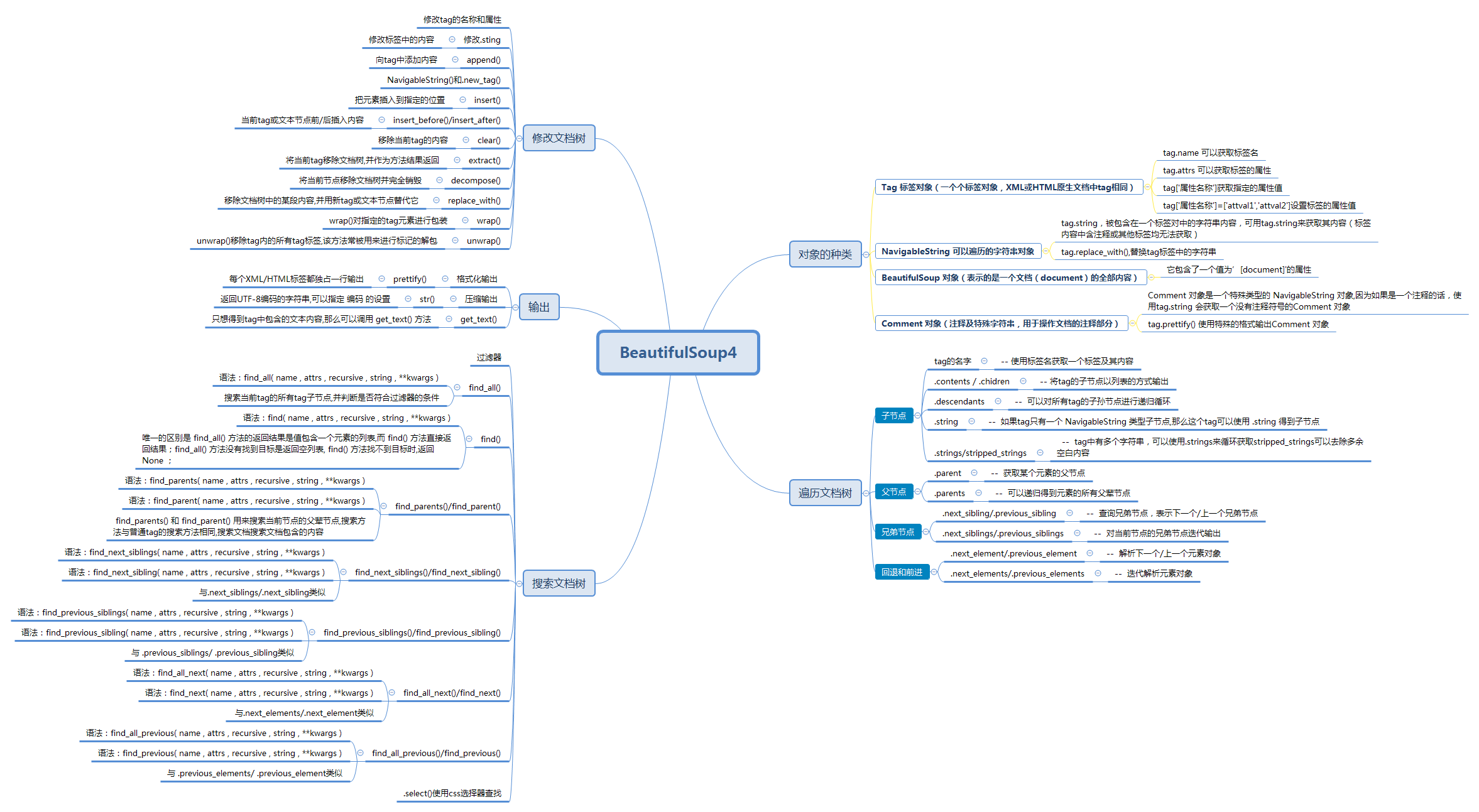
3,BeautifulSoup4
After learning the urlib standard library, we have been able to climb to some normal web source code (html documents), but this is still one step away from the result - how to filter the data we want. At this time, the beautiful soup library comes. At present, the latest version of beautiful soup is beautiful soup4.
3.1 introduction and use of beautiful soup 4
3.1.1 introduction to beautiful soup
The official definition of Beautiful Soup: it is a Python library that can extract data from HTML or XML files It can realize the usual way of document navigation, searching and modifying through your favorite converter Beautiful Soup will help you save hours or even days of working time. (official website document: https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/)
Beautiful soup itself supports HTML parsers in Python standard libraries, but if you want beautiful soup to use an html5lib/lxml parser, you can use the following method. (official recommendation: use lxml as parser because it is more efficient.)
pip install html5lib pip install lxml
3.1.2 use of beautiful soup 4
Beautiful soup (markup, features) accepts two parameters:
First parameter (markup): file object or string object
The second parameter (features): parser. If it is not specified, the python standard parser (html.parser) will be used, but a warning will be generated
from bs4 import BeautifulSoup # Import beautiful soup4 Library
# Use HTML without specifying Parser is a python standard parser. If beautulsoup (markup, "html.parser") is not specified, a warning will be generated. GuessedAtParserWarning: No parser was explicitly specified
# The first parameter of BeautifulSoup accepts: a file object or string object
soup1 = BeautifulSoup(open("C:\\Users\\Administrator\\Desktop\\python_3.8.5\\film.html"))
soup2 = BeautifulSoup("<html>hello python</html>") # Get the object of the document
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup1) # <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ....
print(soup2) # <html><head></head><body>hello python</body></html>
3.2 types of objects
Beautiful soup transforms complex HTML documents into a complex tree structure. Each node is a Python object. All objects can be summarized into four types: tag, navigablestring, beautiful soup and comment.
3.2.1 Tag object
Tag has many methods and properties in Traverse the document tree And Search document tree It is explained in detail in Now let's introduce the most important attributes in tag: name and attribute.
3.2.2 NavigableString object (traversable string)
The string content contained in a label pair can be used as tag String to get its content (if the tag content contains comments or other tags, they cannot be obtained)
3.2.3. Beautiful soup object
Represents the entire content of a document
3.2.4 Comment object (Comment and special string)
Comment object is a special type of NavigableString object. In fact, the output still does not include comment symbols, but if it is not handled properly, it may cause unexpected trouble to our text processing.
Use case:
from bs4 import BeautifulSoup
# Import beautiful soup4 Library
# The python standard parser uses this beautiful soup (markup, "HTML. Parser") without specifying it
soup2 = BeautifulSoup("<html>"
"<p class='boldest'>I am p label<b>hello python</b></p>"
"<!--I am the content annotation outside the tag-->"
"<p class='boldest2'><!--I p Notes in labels-->I am independent p label</p>"
"<a><!--I a Notes in labels-->I'm a link</a>"
"<h1><!--This is a h1 Notes for labels--></h1>"
"</html>",
"html5lib") # Get the object of the document
# Tag tag object
print(type(soup2.p)) # Output tag object < class' BS4 element. Tag'>
print(soup2.p.name) # Output the name of the Tag object
print(soup2.p.attrs) # Output the attribute information of the first p tag: {class': ['boldest ']}
soup2.p['class'] = ['boldest', 'boldest1']
print(soup2.p.attrs) # {'class': ['boldest', 'boldest1']}
# NavigableString is a string object that can be traversed
print(type(soup2.b.string)) # <class 'bs4.element.NavigableString'>
print(soup2.b.string) # hello python
print(soup2.a.string) # None comments or other label contents cannot be obtained
print(soup2.b.string.replace_with("hello world")) # replace_ The with() method replaces the contents of the label
print(soup2.b.string) # hello world
# BeautifulSoup object
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup2) # <html>< head > < / head > < body > < p class = "boldest" > I'm P tag < b > Hello Python < / b > < / P > <-- I am the content comment outside the tag -- > < p > <-- Comments in my p tag -- > I am a separate P tag</p></body></html>
print(soup2.name) # [document]
# Comment comment and special string (a special type of NavigableString object)
print(type(soup2.h1.string)) # <class 'bs4.element.Comment'>
print(soup2.h1.string) # This is an annotation of h1 tag (using. string to output its content, the annotation is removed, which is not what we want)
print(soup2.h1.prettify()) # It will be output in a special format: < H1 > <-- This is a comment for the H1 tag -- ></h1>
3.3. Object properties - traversing documents
3.3.1 child nodes
| Properties (beautifulsup object) | describe |
| . tag tag tag name | Use the tag name to get a tag and its contents |
| .contents / .chidren | Output the child nodes of tag as a list |
| .descendants | You can recursively loop through the descendants of all tag s |
| .string | If a tag has only one child node of NavigableString type, this tag can be used string to get child nodes |
| .strings/stripped_strings | There are multiple strings in tag, which can be used Strings to get stripped in a loop_ Strings can remove redundant white space |
Use case:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I'm the title</title>
</head>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>
<b>I am a paragraph...</b>
I'm the first paragraph
I'm the second paragraph
<b>I'm another paragraph</b>
I'm the first paragraph
</p>
<a>I am a link</a>
</div>
<div>
<p>picture</p>
<img src="example.png"/>
</div>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup object
print(soup.head.name) # soup.head can get the tag and get the tag name - output: head
print(soup.head.contents) # Output the child nodes of tag in a list -- output: ['\ n', < meta charset = "UTF-8" / >, '\ n', < title > I'm the title < / Title >, '\ n']
print(soup.head.contents[1]) # <meta charset="utf-8"/>
print(soup.head.children) # list_iterator object
for child in soup.head.children:
print(child) # <meta charset="utf-8"/> <title>I'm the title</title>
# In fact, the content in the tag is also a node. Using contents and children cannot directly obtain the content in the indirect node, but The descendants attribute can
for child in soup.head.descendants:
print(child) # <meta charset="utf-8"/> <title>I'm the title</title> I'm the title
print(soup.head.title.string) # Output: I'm the title Note: other nodes or comments in the title cannot be obtained
print(soup.body.div.div.p.strings) # use. String none is used strings get generator object
for string in soup.body.div.div.p.stripped_strings: # stripped_strings can remove redundant white space
print(repr(string)) # 'I'm a paragraph...'
# 'I'm the first paragraph \ Ni'm the seco n d paragraph'
# 'I'm another paragraph'
# 'I'm the first paragraph'3.3.2. Parent node
| attribute | describe |
| .parent | Gets the parent node of an element |
| .parents | All parent nodes of the element can be obtained recursively |
Use case:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I'm the title</title>
</head>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>
<b>I am a paragraph...</b>
I'm the first paragraph
I'm the second paragraph
<b>I'm another paragraph</b>
I'm the first paragraph
</p>
<a>I am a link</a>
</div>
<div>
<p>picture</p>
<img src="example.png"/>
</div>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup object
title = soup.head.title
print(title.parent) # Output parent node
# <head>
# <meta charset="utf-8"/>
# <title>I'm the title</title>
# </head>
print(title.parents) # generator object PageElement.parents
for parent in title.parents:
print(parent) # Output head parent node and html parent node3.3.3 brother nodes
| attribute | describe |
| .next_sibling | Query the sibling node to represent the next sibling node |
| .previous_sibling | Query sibling node, indicating the previous sibling node |
| .next_siblings | Iterative output of sibling nodes of the current node (Part 2) |
| .previous_siblings | Iterative output of sibling nodes of the current node (Part 1) |
Use case:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I'm the title</title>
</head>
<body>
<div>
<p>
<b id="b1">I'm the first paragraph</b><b id="b2">I'm the second paragraph</b><b id="b3">I'm the third paragraph</b><b id="b4">I'm the fourth paragraph</b>
</p>
<a>I am a link</a>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup object
p = soup.body.div.p.b
print(p) # < B id = "" b1 "" > I'm the first paragraph</b>
print(p.next_sibling) # < B id = "" b2 "" > I'm the second paragraph</b>
print(p.next_sibling.previous_sibling) # < B id = "" b1 "" > I'm the first paragraph</b>
print(p.next_siblings) # generator object PageElement.next_siblings
for nsl in p.next_siblings:
print(nsl) # < B id = "" b2 "" > I'm the second paragraph</b>
# < B id = "" b3 "" > I'm the third paragraph</b>
# < B id = "" b4 "" > I'm the fourth paragraph</b>3.3.4. Fallback and forward
| attribute | describe |
| .next_element | Resolve next element object |
| .previous_element | Resolve previous element object |
| .next_elements | Iteratively resolve element objects |
| .previous_elements | Iteratively resolve element objects |
Use case:
from bs4 import BeautifulSoup
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>I'm the title</title>
</head>
<body>
<div>
<p>
<b id="b1">I'm the first paragraph</b><b id="b2">I'm the second paragraph</b><b id="b3">I'm the third paragraph</b><b id="b4">I'm the fourth paragraph</b>
</p>
<a>I am a link<h3>h3</h3></a>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup object
p = soup.body.div.p.b
print(p) # < B id = "" b1 "" > I'm the first paragraph</b>
print(p.next_element) # I'm the first paragraph
print(p.next_element.next_element) # < B id = "" b2 "" > I'm the second paragraph</b>
print(p.next_element.next_element.next_element) # I'm the second paragraph
for element in soup.body.div.a.next_element: # Right: I am a link string traversal
print(element)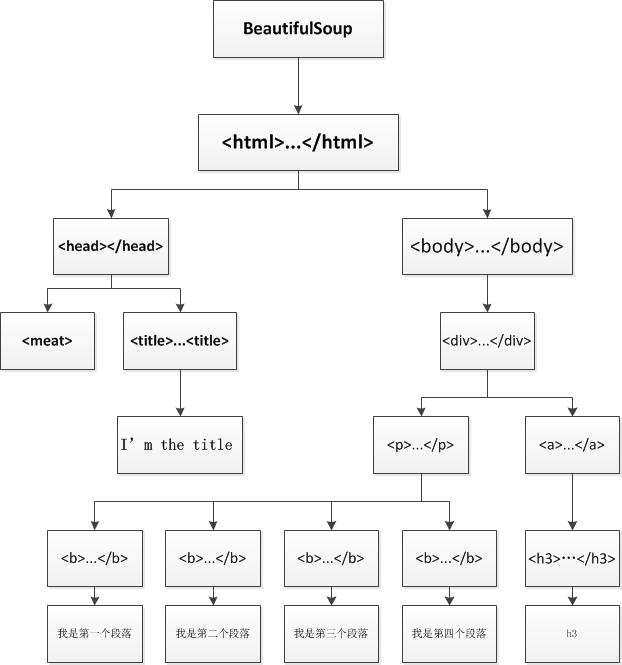
Note: next_element, the content in the tag will also be regarded as a node. For example, take the next of node a in the case_ Element is a string (I am a link)
3.4. Object properties and methods - search document tree
The search document here is actually to search and filter documents according to certain conditions. The filtering rules often use the Search API, or we can customize the regular / filter to search documents.
3.4.1,find_all()
The simplest filter is a string Pass in a string parameter in the search method, and the Beautiful Soup will find the content that completely matches the string.
Syntax: find_all( name , attrs , recursive , string , **kwargs ) return to list
find_all( name , attrs , recursive , string , **kwargs ) Parameter Description: name: Find all names name of tag(name (it can be a string or a list) attrs: The retrieval string of label attribute value can be used for label attribute retrieval recursive: Retrieve all descendants by default True string: <>...</>Search string in string area
Use case:
from bs4 import BeautifulSoup
import re
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title id="myTitle">I'm the title</title>
</head>
<body>
<div>
<p>
<b id="b1" class="bcl1">I'm the first paragraph</b><b>I'm the second paragraph</b><b id="b3">I'm the third paragraph</b><b id="b4">I'm the fourth paragraph</b>
</p>
<a href="www.temp.com">I am a link<h3>h3</h3></a>
<div id="dv1">str</div>
</div>
</body>
</html>'''
# Syntax: find_all( name , attrs , recursive , string , **kwargs )
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup object
# The first parameter name can be a tag name or a list
print(soup.findAll('b')) # Return to the list containing B tags [< B id = "" b1 "" > I'm the first paragraph < / b >, < B id = "" b2 "" > I'm the second paragraph < / b >, < B id = "" b3 "" > I'm the third paragraph < / b >, < B id = "" b4 "> I'm the fourth paragraph < / b >]
print(soup.findAll(['a', 'h3'])) # Match multiple [< a href = "www.temp. Com" > I am a link < H3 > H3 < / H3 > < / a >, < H3 > H3 < / H3 >]
# The second parameter, attrs, can specify the parameter name or not
print(soup.findAll('b', 'bcl1')) # Match the B tag of class='bcl1 '[< B class = "BCL1" id = "" b1 "> I'm the first paragraph < / b >]
print(soup.findAll(id="myTitle")) # Specify ID [< Title id = "mytitle" > I'm the title < / Title >]
print(soup.find_all("b", attrs={"class": "bcl1"})) # [< B class = "BCL1" id = "b1" > I'm the first paragraph < / b >]
print(soup.findAll(id=True)) # Match all tags with id attribute
# The third parameter recursive is True by default. If you want to search only the direct child nodes of tag, you can use the parameter recursive=False
print(soup.html.find_all("title", recursive=False)) # [] recursive=False. The direct child node of html is head, so the title cannot be found
# Fourth parameter string
print(soup.findAll('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("I'm the second"))) # Search me is the second paragraph
# Other parameters limit parameter
print(soup.findAll('b', limit=2)) # When the number of search results reaches the limit, stop the search and return results, [< B class = "BCL1" id = "b1" > I am the first paragraph < / b >, < b > I am the second paragraph < / b >]
3.4.2,find()
Find() and find_ The difference between all() and find()_ The return result of the all () method is a list of values containing an element, while the find () method directly returns the result (that is, if it is found, it will not be found, and only the first matching one will be returned)_ The all() method returns an empty list if the target is not found. When the find() method cannot find the target, it returns {None.
Syntax: find( name , attrs , recursive , string , **kwargs )
Use case:
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup object
# The first parameter name can be a tag name or a list
print(soup.find('b')) # Return < B class = "BCL1" id = "b1" "> I am the first paragraph < / b >, as long as I find one, I will return
# The second parameter, attrs, can specify the parameter name or not
print(soup.find('b', 'bcl1')) # < B class = "BCL1" id = "b1" > I'm the first paragraph</b>
print(soup.find(id="myTitle")) # <title id="myTitle">I'm the title</title>
print(soup.find("b", attrs={"class": "bcl1"})) # < B class = "BCL1" id = "b1" > I'm the first paragraph</b>
print(soup.find(id=True)) # Match to the first < Title id = "mytitle" > I'm the title < / Title >
# The third parameter recursive is True by default. If you want to search only the direct child nodes of tag, you can use the parameter recursive=False
print(soup.html.find("title", recursive=False)) # None recursive=False. The direct child node of html is head, so the title cannot be found
# Fourth parameter string
print(soup.find('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("I'm the second"))) # I'm the second paragraph3.4.3,find_parents() and find_parent()
find_parents() and} find_parent() is used to search the parent node of the current node.
Syntax:
find_parents( name , attrs , recursive , string , **kwargs )
find_parent( name , attrs , recursive , string , **kwargs )
3.4.4,find_next_siblings() and find_next_sibling()
find_ next_ The siblings () method returns all the subsequent sibling nodes that meet the conditions, find_next_sibling() returns only the first tag node that meets the conditions;
Syntax:
find_next_siblings( name , attrs , recursive , string , **kwargs )
find_next_sibling( name , attrs , recursive , string , **kwargs )
3.4.5,find_previous_siblings() and find_previous_sibling()
Pass .previous_siblings Property to the previous resolution of the current tag. find_ previous_ The siblings () method returns all the previous sibling nodes that meet the conditions, find_ previous_ The sibling () method returns the first qualified sibling node;
Syntax:
find_previous_siblings( name , attrs , recursive , string , **kwargs )
find_previous_sibling( name , attrs , recursive , string , **kwargs )
3.4.6,find_all_next() and find_next()
find_ all_ The next () method returns all qualified nodes, find_ The next () method returns the first qualified node.
Syntax:
find_all_next( name , attrs , recursive , string , **kwargs )
find_next( name , attrs , recursive , string , **kwargs )
3.4.7,find_all_previous() and find_previous()
find_ all_ The previous () method returns all qualified node elements, find_ The previous () method returns the first qualified node element.
Syntax:
find_all_previous( name , attrs , recursive , string , **kwargs )
find_previous( name , attrs , recursive , string , **kwargs )
These are actually similar to the previous attribute usage, but more than attributes, such as find_ The same parameter as all(). I won't introduce it in detail here. You can see the API on the official website.
3.4.8. CSS selector search
Beautiful Soup supports most CSS selectors, such as tag or Beautiful Soup objects By passing in the string parameter in the select() method, you can find the tag using the syntax of the CSS selector.
Use case:
from bs4 import BeautifulSoup
import re
markup = '''<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title id="myTitle">I'm the title</title>
</head>
<body>
<div>
<p>
<b id="b1" class="bcl1">I'm the first paragraph</b><b>I'm the second paragraph</b><b id="b3">I'm the third paragraph</b><b id="b4">I'm the fourth paragraph</b>
</p>
<a href="www.temp.com">I am a link<h3>h3</h3></a>
<div id="dv1">str</div>
</div>
</body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup object
print(soup.select("html head title")) # [<title id="myTitle">I'm the title</title>]
print(soup.select("body a")) # [< a href = "www.temp. Com" > I'm a link < H3 > H3 < / H3 > < / a >]
print(soup.select("#dv1")) # [<div id="dv1">str</div>]
3.5. Object properties and methods - modify document tree
3.5.1. Modify the name and attribute of tag
Use case:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.name = "blockquote"
print(tag) # <blockquote class="boldest">Extremely bold</blockquote>
tag['class'] = 'veryBold'
tag['id'] = 1
print(tag) # <blockquote class="veryBold" id="1">Extremely bold</blockquote>
del tag['id'] # Delete attribute3.5.2 modification string
Tag Assigning a value to the string attribute is equivalent to using the content in the current tag
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.string = "replace"
print(tag) # <b class="boldest">replace</b>3.5.3,append()
Add content to tag
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.append(" append")
print(tag) # <b class="boldest">Extremely bold append</b>3.5.4 NavigableString() and new_tag()
from bs4 import BeautifulSoup, NavigableString, Comment
soup = BeautifulSoup('<div><b class="boldest">Extremely bold</b></div>', "html5lib")
tag = soup.div
new_string = NavigableString('NavigableString')
tag.append(new_string)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString</div>
new_comment = soup.new_string("Nice to see you.", Comment)
tag.append(new_comment)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--></div>
# To add labels, the factory method new is recommended_ tag
new_tag = soup.new_tag("a", href="http://www.example.com")
tag.append(new_tag)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--><a href="http://www.example.com"></a></div>
3.5.5,insert()
Inserts the element into the specified location
from bs4 import BeautifulSoup markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup,"html5lib") tag = soup.a tag.insert(1, "but did not endorse ") # The difference between and append is Inconsistent contents property acquisition print(tag) # <a href="http://example.com/">I linked to but did not endorse <i>example.com</i></a> print(tag.contents) # ['I linked to ', 'but did not endorse ', <i>example.com</i>]
3.5.6,insert_before() and insert_after()
Insert content before / after the current tag or text node
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to</a>'
soup = BeautifulSoup(markup, "html5lib")
tag = soup.new_tag("i")
tag.string = "Don't"
soup.a.string.insert_before(tag)
print(soup.a) # <a href="http://example.com/"><i>Don't</i>I linked to</a>
soup.a.i.insert_after(soup.new_string(" ever "))
print(soup.a) # <a href="http://example.com/"><i>Don't</i> ever I linked to</a>
3.5.7,clear()
Remove the contents of the current tag
from bs4 import BeautifulSoup markup = '<a href="http://example.com/">I linked to</a>' soup = BeautifulSoup(markup, "html5lib") tag = soup.a tag.clear() print(tag) # <a href="http://example.com/"></a>
3.5.8,extract()
Removes the current tag from the document tree and returns it as a result of the method
from bs4 import BeautifulSoup markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, "html5lib") a_tag = soup.a i_tag = soup.i.extract() print(a_tag) # <a href="http://example.com/">I linked to </a> print(i_tag) # <i>example. Com < / I > what we removed
3.5.9,decompose()
Remove the current node from the document tree and destroy it completely
from bs4 import BeautifulSoup markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>' soup = BeautifulSoup(markup, "html5lib") a_tag = soup.a soup.i.decompose() print(a_tag) # <a href="http://example.com/">I linked to </a>
3.5.10,replace_with()
Remove a section from the document tree and replace it with a new tag or text node
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
new_tag = soup.new_tag("b")
new_tag.string = "example.net"
soup.a.i.replace_with(new_tag)
print(soup.a) # <a href="http://example.com/">I linked to <b>example.net</b></a>
3.5.11. wrap() and unwrap()
wrap() wraps the specified tag element and unwrap() removes all tag tags in the tag. This method is often used to unpack tags
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
a_tag = soup.a
a_tag.i.unwrap()
print(a_tag) # <a href="http://example.com/">I linked to example.com</a>
soup2 = BeautifulSoup("<p>I wish I was bold.</p>", "html5lib")
soup2.p.string.wrap(soup2.new_tag("b"))
print(soup2.p) # <p><b>I wish I was bold.</b></p>3.6 output
3.6.1 format output
The prettify() method formats the document tree of Beautiful Soup and outputs it in Unicode encoding. Each XML/HTML tag has an exclusive line.
from bs4 import BeautifulSoup
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>
print(soup.prettify()) #<html>
# <head>
# </head>
# <body>
# <a href="http://example.com/">
# I linked to
# <i>
# example.com
# </i>
# </a>
# </body>
# </html>3.6.2 compressed output
If you only want to get the result string and don't pay attention to the format, you can use Python's str() method for a BeautifulSoup or Tag object.
3.6.3,get_text() outputs only the text content in the tag
If you only want to get the text content contained in the tag, you can call get_text() method.
from bs4 import BeautifulSoup markup = '<a href="http://example. COM / "> I linked to < I > example. Com < / I > Click me < / a > ' soup = BeautifulSoup(markup, "html5lib") print(soup) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html> print(str(soup)) # <html><head></head><body><a href=" http://example.com/ "> I linked to < I > example. Com < / I > Click me</a></body></html> print(soup.get_text()) # I linked to example.com
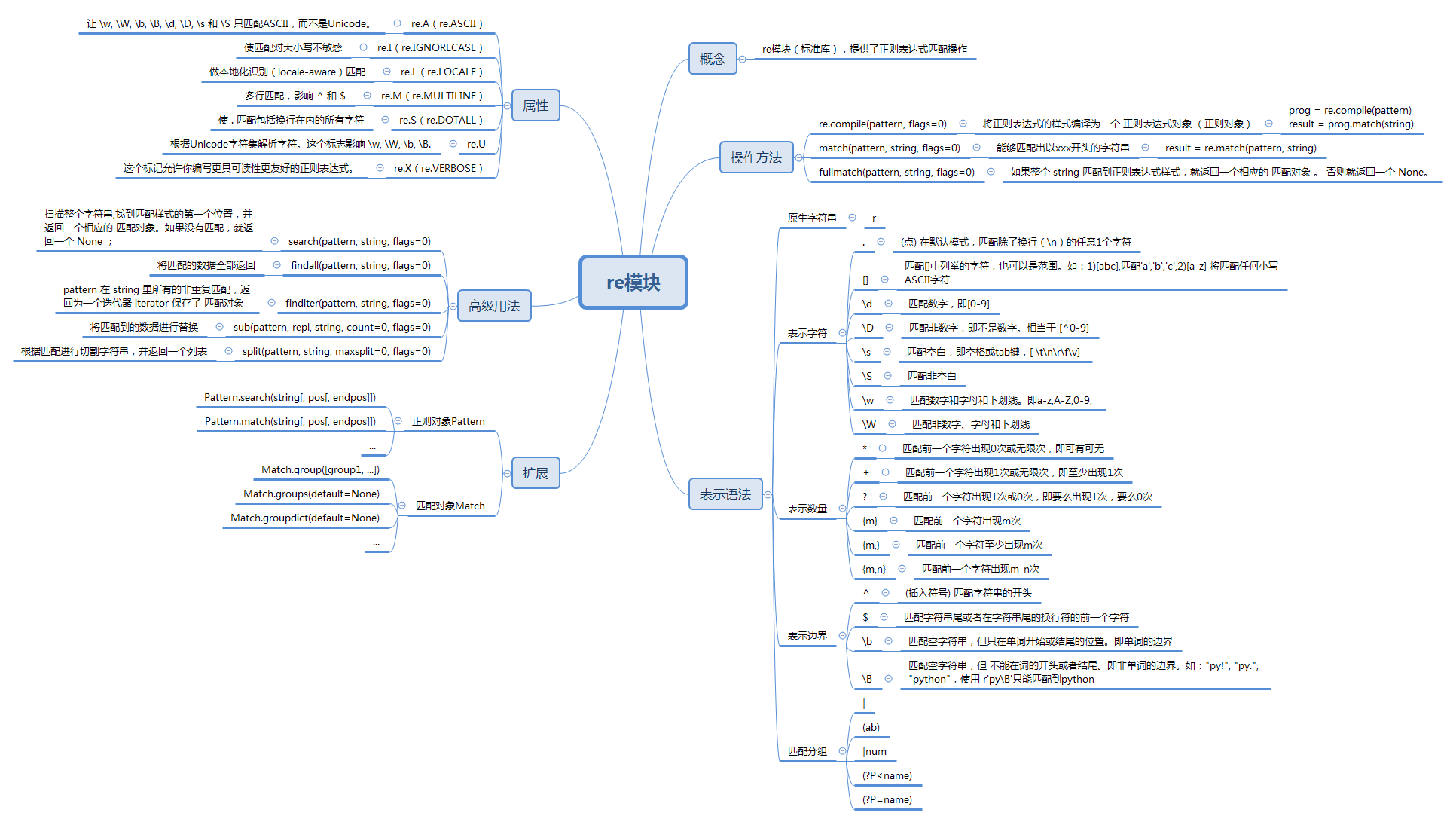
4. re standard library (module)
The beautiful soup library filters the data we want from html documents, but there may be many more detailed contents of these data, such as whether we get the links we want, whether we need to extract mailbox data, etc. in order to extract data more carefully and accurately, regular rules come.
Regular Expression (English: Regular Expression, often abbreviated as regex, regexp or RE in code), is a concept of computer science. Regular expressions use a single string to describe and match a series of strings that match a syntactic rule. In other languages, we often come into contact with regular expressions.
Use case:
import re
# Create regular object
pat = re.compile('\d{2}') #A number that appears twice
# search searches for the first occurrence of a match for a given regular expression pattern anywhere
s = pat.search("12abc")
print(s.group()) # 12
# match matches the pattern from the beginning of the string
m = pat.match('1224abc')
print(m.group()) # 12
# The difference between search and match is that the matching position is different
s1 = re.search('foo', 'bfoo').group()
print(s1) # foo
try:
m1 = re.match('foo','bfoo').group() # AttributeError
except:
print('Matching failed') # Matching failed
# Native string (\ B does not end with py)
allList = ["py!", "py.", "python"]
for li in allList:
# re. Match (regular expression, string to match)
if re.match(r'py\B', li):
print(li) # python
# findall()
s = "apple Apple APPLE"
print(re.findall(r'apple', s)) # ['apple']
print(re.findall(r'apple', s, re.I)) # ['apple', 'Apple', 'APPLE']
# sub() find and replace
print(re.sub('a', 'A', 'abcdacdl')) # AbcdAcdl
5. Practical cases
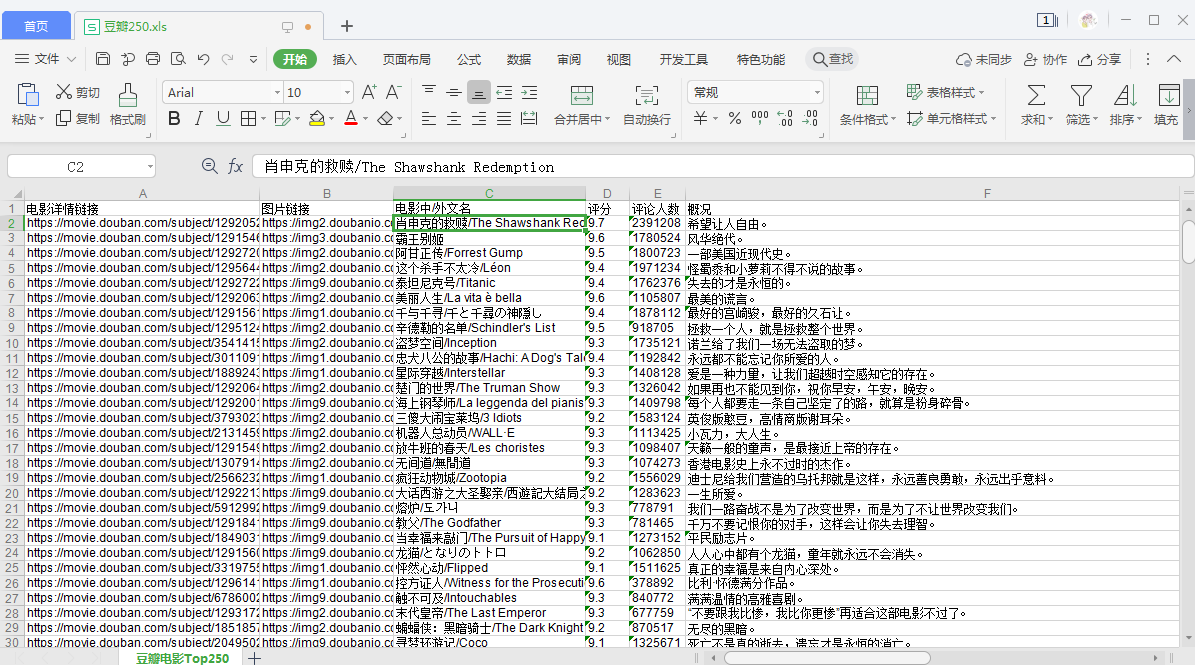
We use watercress https://movie.douban.com/top250 Take the website as an example to crawl for movie information.
5.1. The first step is to use urllib library to obtain web pages
First of all, let's analyze the structure of this web page. It is a fairly regular web page, with 25 articles per page, a total of 10 pages.
We click on the first page: url = https://movie.douban.com/top250?start=0&filter=
We click on the second page: url = https://movie.douban.com/top250?start=25&filter=
We click on page 3: url = https://movie.douban.com/top250?start=50&filter=
import urllib.request, urllib.error
# Define the basic url and find the rule. The last number after start = changes on each page
baseurl = "https://movie.douban.com/top250?start="
# Define a function getHtmlByURL to get the content of the web page with the specified url
def geturl(url):
# Custom headers (camouflage, tell Douban server what type of machine we are, so as not to be anti crawled)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# Use the Request class to construct a Request with a custom header
req = urllib.request.Request(url, headers=headers)
# Define a receive variable for receiving
html = ""
try:
# Parameters of the urlopen() method, send to the server and receive the response
resp = urllib.request.urlopen(req)
# urlopen() gets the page content. The returned data format is bytes, which needs to be decoded by decode() and converted into str
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def main():
print(geturl(baseurl + "0"))
if __name__ == "__main__":
main()Step 1: we have successfully obtained the specified web content;
5.2. The second step is to parse the data using the beautiful soup and re libraries
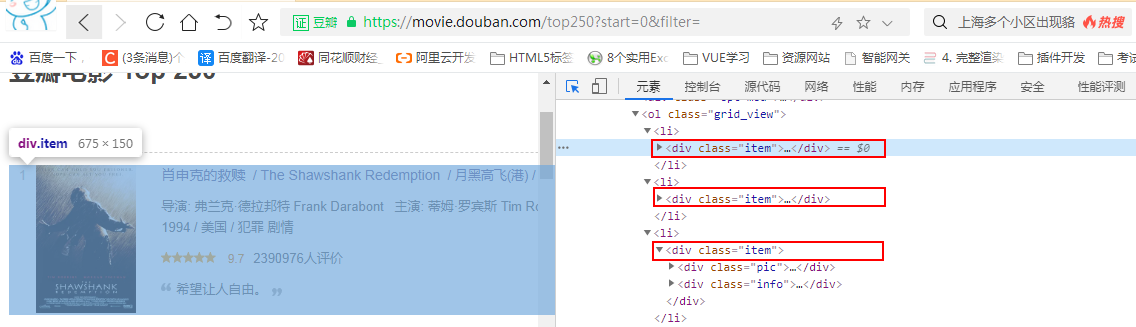
5.2.1 positioning data block
We found that all the data we need are in the < li > < / Li > tag, which is called < div class = "item" > < / div >
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import re
# Define the basic url and find the rule. The last number after start = changes on each page
baseurl = "https://movie.douban.com/top250?start="
# Define a function getHtmlByURL to get the content of the web page with the specified url
def geturl(url):
# Custom headers (camouflage, tell Douban server what type of machine we are, so as not to be anti crawled)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# Use the Request class to construct a Request with a custom header
req = urllib.request.Request(url, headers=headers)
# Define a receive variable for receiving
html = ""
try:
# Parameters of the urlopen() method, send to the server and receive the response
resp = urllib.request.urlopen(req)
# urlopen() gets the page content. The returned data format is bytes, which needs to be decoded by decode() and converted into str
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# Define a function and parse the web page
def analysisData(url):
# Get the specified web page
html = geturl(url)
# Specify the parser to parse html and get the beautifulsup object
soup = BeautifulSoup(html, "html5lib")
# Locate where our data block is
for item in soup.findAll('div', class_="item"):
print(item)
return ""
def main():
print(analysisData(baseurl + "0"))
if __name__ == "__main__":
main()First block of output:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="The Shawshank Redemption" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">The Shawshank Redemption</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / The moon is black and flies high(harbor) / Stimulus 1995(platform)</span>
</a>
<span class="playable">[Playable]</span>
</div>
<div class="bd">
<p class="">
director: Frank·Delabond Frank Darabont to star: Tim·Robbins Tim Robbins /...<br/>
1994 / U.S.A / Crime plot
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2390982 Human evaluation</span>
</div>
<p class="quote">
<span class="inq">Want to set people free.</span>
</p>
</div>
</div>
</div>
<div class="item">5.2.2 parsing data blocks using regular
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import re
# Define the basic url and find the rule. The last number after start = changes on each page
baseurl = "https://movie.douban.com/top250?start="
# Define a function getHtmlByURL to get the content of the web page with the specified url
def geturl(url):
# Custom headers (camouflage, tell Douban server what type of machine we are, so as not to be anti crawled)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# Use the Request class to construct a Request with a custom header
req = urllib.request.Request(url, headers=headers)
# Define a receive variable for receiving
html = ""
try:
# Parameters of the urlopen() method, send to the server and receive the response
resp = urllib.request.urlopen(req)
# urlopen() gets the page content. The returned data format is bytes, which needs to be decoded by decode() and converted into str
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# Defines a regular object to get the specified content
# Extract links (all links start with < a href = "1")
findLink = re.compile(r'<a href="(.*?)">')
# Extract picture
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S let '.' Special characters match any character, including line breaks;
# Extract movie name
findTitle = re.compile(r'<span class="title">(.*)</span>')
# Extract movie score
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# Number of people extracted for evaluation
findJudge = re.compile(r'<span>(\d*)Human evaluation</span>')
# Introduction to extraction
inq = re.compile(r'<span class="inq">(.*)</span>')
# Extract relevant content
findBd = re.compile(r'<p class="">(.*)</p>(.*)<div', re.S)
# Define a function and parse the web page
def analysisData(baseurl):
# Get the specified web page
html = geturl(baseurl)
# Specify the parser to parse html and get the beautifulsup object
soup = BeautifulSoup(html, "html5lib")
dataList = []
# Locate where our data block is
for item in soup.find_all('div', class_="item"):
# item is BS4 element. Tag object, which is converted into a string here
item = str(item)
# Define a list to store the content parsed by each movie
data = []
# findall returns a list where links are extracted
link = re.findall(findLink, item)[0]
data.append(link) # Add link
img = re.findall(findImgSrc, item)[0]
data.append(img) # Add picture link
title = re.findall(findTitle, item)
# There is usually a Chinese name and a foreign name
if len(title) == 2:
# ['Shawshank Redemption', '\ xa0/\xa0The Shawshank Redemption']
titlename = title[0] + title[1].replace(u'\xa0', '')
else:
titlename = title[0] + ""
data.append(titlename) # Add title
pf = re.findall(findRating, item)[0]
data.append(pf)
pjrs = re.findall(findJudge, item)[0]
data.append(pjrs)
# Some may not
inqInfo = re.findall(inq, item)
if len(inqInfo) == 0:
data.append(" ")
else:
data.append(inqInfo[0])
bd = re.findall(findBd, item)[0]
# [('\ ndirector: Frank Darabont\xa0\xa0\xa0 Starring: Tim Robbins /... < br / > \ n 1994 \ xa0/\xa0 America \ xa0/\xa0 crime plot \ n', '\ n \ n \ n')]
bd[0].replace(u'\xa0', '').replace('<br/>', '')
bd = re.sub('<\\s*b\\s*r\\s*/\\s*>', "", bd[0])
bd = re.sub('(\\s+)?', '', bd)
data.append(bd)
dataList.append(data)
return dataList
def main():
print(analysisData(baseurl + "0"))
if __name__ == "__main__":
main()
Page 1 analysis results: analysisData needs to be slightly modified later to process the 10 pages of Douban Top250
[['https://movie.douban.com/subject/1292052/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg ',' The Shawshank Redemption ',' 9.7 ',' 2391074 ',' hope to set people free. ',' Director: Frank Darabont, starring Tim Robbins / 1994 / USA / crime scenario '], ['https://movie.douban.com/subject/1291546/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg ',' Farewell My Concubine ',' 9.6 ',' 1780355 ',' gorgeous. ',' Director: Chen Kaige KaigeChen Starring: Leslie Cheung / Zhang Fengyi fengyizha 1993/ Chinese mainland China Hongkong / plot love same-sex] ['https://movie.douban.com/subject/1292720/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2372307693.jpg ',' Forrest Gump ',' 9.5 ',' 1800723 ',' a modern American history ',' Director: Robert Zemeckis starring Tom Hanks / 1994 / USA / plot love '], ['https://movie.douban.com/subject/1295644/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p511118051.jpg ',' this killer is not too cold / L é on ',' 9.4 ',' 1971155 ',' blame the story that millet and little Laurie have to tell. ',' Director: Luc Besson Starring: Jean Reno / Natalie Portman 1994 / France USA / plot action crime '], ['https://movie.douban.com/subject/1292722/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p457760035.jpg ',' Titanic / Titanic ',' 9.4 ',' 1762280 ',' what is lost is eternal. ',' Director: James Cameron Starring: Leonardo DiCaprio Leonardo 1997 / USA Mexico Australia Canada / plot love disaster '], ['https://movie.douban.com/subject/1292063/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2578474613.jpg ',' beautiful life / La vita è Bella ',' 9.6 ',' 1105760 ',' the most beautiful lie ',' Director: Roberto Benigni Starring: Roberto Benigni 1997 / Italy / drama comedy love war '], ['https://movie.douban.com/subject/1291561/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2557573348.jpg ',' Chihiro / Chihiro Chihiro ',' 9.4 ',' 1877996 ',' the best Hayao Miyazaki, the best Kushiro. ',' Director: Hayao Miyazaki Starring: Rumi h î ragi / freedom Miyazaki 2001 / Japan / plot animation Fantasy '], ['https://movie.douban.com/subject/1295124/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p492406163.jpg 'schindler's list ',' 9.5 ',' 918645 ',' saving one person is saving the whole world. ',' Director: Steven Spielberg Starring: Liam Neeson 1993 / USA / plot history war '], ['https://movie.douban.com/subject/3541415/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2616355133.jpg ',' inception ',' 9.3 ',' 1734973 ',' Nolan gave us a dream that we can't steal. ',' Director: Christopher Nolan Starring: Leonardo DiCaprio le 2010 / USA, UK / plot science fiction suspense adventure '], ['https://movie.douban.com/subject/3011091/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p524964039.jpg 'Hachi: a dog's Tale', '9.4', '1192778', 'never forget the people you love.', ' Director: lesse Hallstr ö m Starring: Richard Kiel, Richard ger 2009 / USA / UK / plot '], ['https://movie.douban.com/subject/1889243/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2614988097.jpg ',' interstellar crossing / interstellar ',' 9.3 ',' 1408128 ',' love is a power that allows us to perceive its existence beyond time and space. ',' Director: Christopher Nolan Starring: Matthew McConaughey 2014 / USA, UK, Canada / plot sci-fi adventure '], ['https://movie.douban.com/subject/1292064/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p479682972.jpg ',' Truman show ',' 9.3 ',' 1325913 ',' if I can't see you again, I wish you good morning, good afternoon and good night. ',' Director: Peter Weir Starring: Jim Carrey / Laura lini Lau 1998 / USA / science fiction '], ['https://movie.douban.com/subject/1292001/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2574551676.jpg ', "La Legenda del pianista sull'oceano",' 9.3 ',' 1409712 ',' everyone should take a firm road, even if it is broken to pieces', ' Director: Giuseppe Tornatore starring Tim Roth / 1998 / Italy / plot music '], ['https://movie.douban.com/subject/3793023/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p579729551.jpg ',' three fools make trouble in Bollywood / 3 Idiots', '9.2', '1583056', 'handsome version of bean, high EQ version of Sheldon', ' Director: rakuma Hirani Rajkumar Hirani Starring: Amir Khan / ka 2009 / India / drama comedy love song and dance '], ['https://movie.douban.com/subject/2131459/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p1461851991.jpg ',' robot story / WALL · e ',' 9.3 ',' 1113357 ',' little Wally, big life ',' Director: Andrew Stanton Starring: Ben Bert, Ben Burtt / Ellie 2008 / USA / sci fi animation adventure '], ['https://movie.douban.com/subject/1291549/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p1910824951.jpg ',' the spring of the cattle herding class / Les choristes', '9.3', '1098339', 'the childlike sound of nature is the closest existence to God.', ' Director: Christophe Barratier Starring: Gerard Junio G é 2004 / France, Switzerland, Germany / drama comedy music '], ['https://movie.douban.com/subject/1307914/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2564556863.jpg ',' Infernal Affairs / Infernal Affairs', '9.3', '1074152', 'timeless masterpieces in Hong Kong film history', ' Director: Liu Weiqiang / Mai Zhaohui Starring: Andy Lau / Tony Leung / Huang Qiusheng 2002 / Hong Kong, China / plot crime thriller '], ['https://movie.douban.com/subject/25662329/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2614500649.jpg 'crazy animal city / Zootopia', '9.2', '1555912', 'the Utopia created by Disney is like this, always kind and brave, always unexpected.' " Director: Byron Howard / rich Moore Starring: Jennifer 2016 / US / comic animation adventure '], ['https://movie.douban.com/subject/1292213/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2455050536.jpg ',' Dahua journey to the West's great sage's wedding / journey to the West's grand finale of fairy shoes', '9.2', '1283551', 'love of life', ' Director: Liu Zhenwei Jeffrey Lau Starring: Stephen Chow / Wu Mengda mantatng 1995/ Chinese mainland China / comedy love fantasy Hongkong costume] ['https://movie.douban.com/subject/5912992/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p1363250216.jpg ',' melting pot ',' 9.3 ',' 778782 ',' we fight all the way not to change the world, but to prevent the world from changing us. ',' Director: Huang Donghe Dong hyukhwang Starring: Kong YooGong / Zheng Youmei Yu mijung / 2011 / Korea / plot '], ['https://movie.douban.com/subject/1291841/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p616779645.jpg ',' Godfather / The Godfather ',' 9.3 ',' 781422 ',' don't hate your opponent, it will make you lose your mind. ',' Director: Francis Ford Coppola Starring: Marlon Brando m 1972 / USA / plot crime '], ['https://movie.douban.com/subject/1849031/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2614359276.jpg ',' the pursuit of happiness', '9.1', '1273152', 'civilian inspirational films',' Director: Gabriele Muccino starring Will Smith 2006 / USA / plot biography family '], ['https://movie.douban.com/subject/1291560/', 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2540924496.jpg ',' chinchilla / となりのトトロ ',' 9.2 ',' 1062785 ',' everyone has a chinchilla in his heart, and childhood will never disappear. ',' Director: Hayao Miyazaki Starring: Noriko Hidaka / Sakamoto Chixia Ch 1988 / Japan / animated fantasy adventure '], ['https://movie.douban.com/subject/3319755/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p501177648.jpg ',' flipped ',' 9.1 ',' 1511459 ',' true happiness comes from the bottom of your heart. ',' Director: Rob Reiner Starring: Madeline Carroll / card 2010 / USA / drama comedy love '], ['https://movie.douban.com/subject/1296141/', 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p1505392928.jpg ',' witness for the prosecution ',' 9.6 ',' 378892 ',' Billy Wilder's works with full marks', ' Director: Billy Wilder, starring Billy Wilder: Tyrone Power / Marlene 1957 / USA / plot crime suspense ']]
5.3 export data to excel
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import re
import xlwt
# Define the basic url and find the rule. The last number after start = changes on each page
baseurl = "https://movie.douban.com/top250?start="
# Define a function getHtmlByURL to get the content of the web page with the specified url
def geturl(url):
# Custom headers (camouflage, tell Douban server what type of machine we are, so as not to be anti crawled)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# Use the Request class to construct a Request with a custom header
req = urllib.request.Request(url, headers=headers)
# Define a receive variable for receiving
html = ""
try:
# Parameters of the urlopen() method, send to the server and receive the response
resp = urllib.request.urlopen(req)
# urlopen() gets the page content. The returned data format is bytes, which needs to be decoded by decode() and converted into str
html = resp.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# Defines a regular object to get the specified content
# Extract links (all links start with < a href = "1")
findLink = re.compile(r'<a href="(.*?)">')
# Extract picture
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S let '.' Special characters match any character, including line breaks;
# Extract movie name
findTitle = re.compile(r'<span class="title">(.*)</span>')
# Extract movie score
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# Number of people extracted for evaluation
findJudge = re.compile(r'<span>(\d*)Human evaluation</span>')
# Introduction to extraction
inq = re.compile(r'<span class="inq">(.*)</span>')
# Extract relevant content
findBd = re.compile(r'<p class="">(.*)</p>(.*)<div', re.S)
# Define a list of 10 pages to receive
dataList = []
# Define a function and parse the web page
def analysisData(baseurl):
# Get the specified web page
for i in range(0, 10): # Get the function of web page options, 10 times
url = baseurl + str(i * 25)
html = geturl(url)
# Specify the parser to parse html and get the beautifulsup object
soup = BeautifulSoup(html, "html5lib")
# Locate where our data block is
for item in soup.find_all('div', class_="item"):
# item is BS4 element. Tag object, which is converted into a string here
item = str(item)
# Define a list to store the content parsed by each movie
data = []
# findall returns a list where links are extracted
link = re.findall(findLink, item)[0]
data.append(link) # Add link
img = re.findall(findImgSrc, item)[0]
data.append(img) # Add picture link
title = re.findall(findTitle, item)
# There is usually a Chinese name and a foreign name
if len(title) == 2:
# ['Shawshank Redemption', '\ xa0/\xa0The Shawshank Redemption']
titlename = title[0] + title[1].replace(u'\xa0', '')
else:
titlename = title[0] + ""
data.append(titlename) # Add title
pf = re.findall(findRating, item)[0]
data.append(pf)
pjrs = re.findall(findJudge, item)[0]
data.append(pjrs)
inqInfo = re.findall(inq, item)
if len(inqInfo) == 0:
data.append(" ")
else:
data.append(inqInfo[0])
bd = re.findall(findBd, item)[0]
# [('\ ndirector: Frank Darabont\xa0\xa0\xa0 Starring: Tim Robbins /... < br / > \ n 1994 \ xa0/\xa0 America \ xa0/\xa0 crime plot \ n', '\ n \ n \ n')]
bd[0].replace(u'\xa0', '').replace('<br/>', '')
bd = re.sub('<\\s*b\\s*r\\s*/\\s*>', "", bd[0])
bd = re.sub('(\\s+)?', '', bd)
data.append(bd)
dataList.append(data)
return dataList
def main():
analysisData(baseurl)
savepath = "C:\\Users\\Administrator\\Desktop\\python_3.8.5\\Watercress 250.xls"
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # Create Workbook object
sheet = book.add_sheet("Douban film Top250", cell_overwrite_ok=True) # Create worksheet
col = ("Movie details link", "pictures linking", "In the movie/Foreign name", "score", "Number of comments", "survey", "Relevant information")
print(len(dataList))
for i in range(0, 7):
sheet.write(0, i, col[i])
for i in range(0, 250):
print('Saving page'+str((i+1))+'strip')
data = dataList[i]
for j in range(len(data)):
sheet.write(i + 1, j, data[j])
book.save(savepath)
if __name__ == "__main__":
main()
Final effect: