Scoring algorithm formula: calculate the relevance (score) between query words and documents. The higher the score, the higher the relevance
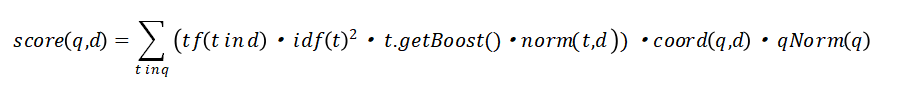
Explanation of variable meaning:
q: query words
d: A document, here refers to the article title + author + abstract
t: Query word, each word after word segmentation
Function meaning analysis:
tf function, word frequency
The idf function reverses the document frequency, the total number of documents / the number of documents containing this word, and reduces the impact of high-frequency words in all documents on the meaning of search words. For example, I, and such words appear in all documents, so it is necessary to reduce their weight in search query words
getBoost function to obtain the weight specified by the query for words (no special processing for the time being)
norm function, obtained by multiplying the first three functions
Document boost - Document weighting, using doc. Before indexing setBoost()
Field boost - field weighting, and also calling field. before indexing. setBoost()
lengthNorm(field) - this value is calculated by the number of tokens in the field. The shorter the field, The higher the score (Note: lucene similarity is implemented by default: when calculating the document length, the lengthNorm method is not called, but the document length is read through TFIDFSimilarity. In fact, it is added through DefaultSimilarity when creating the index. If you want to modify it, you need to rewrite this method. FieldInvertState.length calculation is used. If you want to know how this length is calculated DefaultIndexingChain. Convert method)
Storage:
public float lengthNorm(FieldInvertState state) {
final int numTerms;
if (discountOverlaps)
numTerms = state.getLength() - state.getNumOverlap();
else
numTerms = state.getLength();
return state.getBoost() * ((float) (1.0 / Math.sqrt(numTerms)));
}
Read:
public final SimScorer simScorer(SimWeight stats, LeafReaderContext context) throws IOException {
IDFStats idfstats = (IDFStats) stats;
return new TFIDFSimScorer(idfstats, context.reader().getNormValues(idfstats.field));
}coord(q,d), the scoring factor, is based on the number of query words in the document. The more query words in a document, the higher the matching program of some documents. The default is the percentage of query items. For example, 3 query words are segmented and N are hit (n < = 3), which is n/3
qNorm(q) function, query factor, standardized score, does not affect score sorting
Start the debug mode and observe the score of each
7.909076 = product of:
10.545435 = sum of:
3.661258 = weight(title:Journey to the West in 79475) [DefaultSimilarity], result of:
3.661258 = score(doc=79475,freq=1.0), product of:
0.5220341 = queryWeight, product of:
11.221514 = idf(docFreq=3, maxDocs=109953)
0.046520825 = queryNorm
7.013446 = fieldWeight in 79475, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
11.221514 = idf(docFreq=3, maxDocs=109953)
0.625 = fieldNorm(doc=79475)
3.661258 = weight(title:Journey to the West in 79475) [DefaultSimilarity], result of:
3.661258 = score(doc=79475,freq=1.0), product of:
0.5220341 = queryWeight, product of:
11.221514 = idf(docFreq=3, maxDocs=109953)
0.046520825 = queryNorm
7.013446 = fieldWeight in 79475, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
11.221514 = idf(docFreq=3, maxDocs=109953)
0.625 = fieldNorm(doc=79475)
3.2229195 = weight(title:travels in 79475) [DefaultSimilarity], result of:
3.2229195 = score(doc=79475,freq=1.0), product of:
0.48978832 = queryWeight, product of:
10.528367 = idf(docFreq=7, maxDocs=109953)
0.046520825 = queryNorm
6.5802293 = fieldWeight in 79475, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
10.528367 = idf(docFreq=7, maxDocs=109953)
0.625 = fieldNorm(doc=79475)
0.75 = coord(3/4)