Distributed cluster architecture scenario optimization solution: distributed ID solution
Distributed ID solution
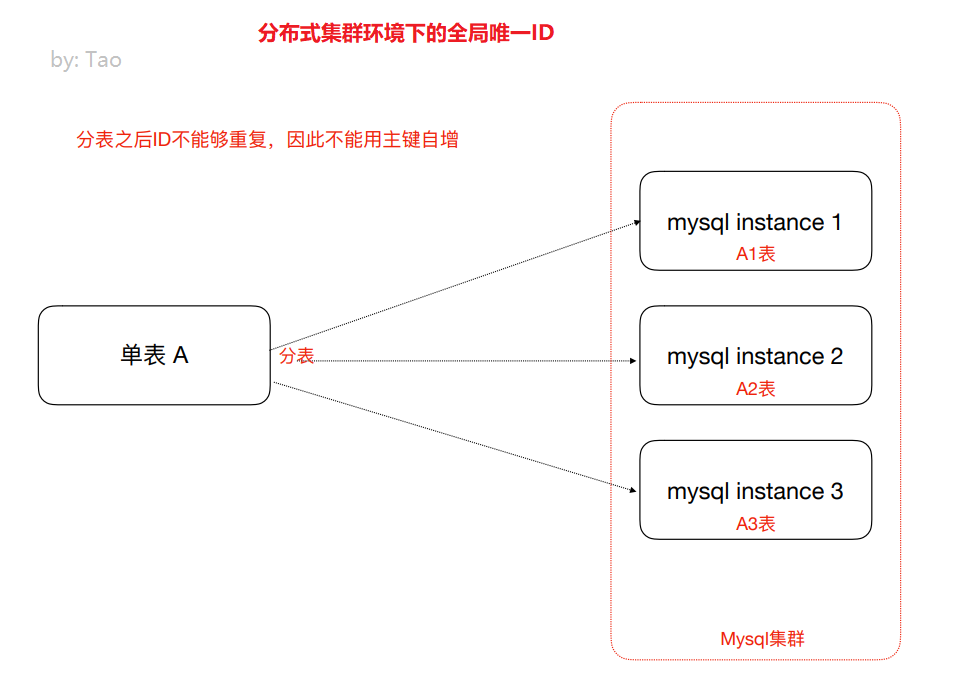
Why do I need a distributed ID (globally unique ID in a distributed cluster environment)
1. UUID (available)
UUID refers to universal unique identifier, which is a universal unique identifier when translated into Chinese
The occurrence of repeated UUID s and errors is very low, so it is unnecessary to consider this problem.
import java.util.UUID;
public class UuidTest {
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
}
}
2. Self increment ID of independent database
For example, table a is divided into table A1 and table A2, so the ID of table A1 and table A2 cannot be automatically increased. How to obtain the ID?
We can create a separate Mysql database and create a table in the database. The ID of the table is set to self increment. When a globally unique ID is required in other places, simulate inserting a record into the table in the Mysql database. At this time, the ID will self increment, and then we can use Mysql select last_insert_id() gets the ID generated by self increment in the table just now
For example, we created a database instance global_id_generator, in which a data table is created. The table structure is as follows:
-- ---------------------------- -- Table structure for DISTRIBUTE_ID -- ---------------------------- DROP TABLE IF EXISTS `DISTRIBUTE_ID`; CREATE TABLE `DISTRIBUTE_ID` ( `id` bigint(32) NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `createtime` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
When an application in the distributed cluster environment needs to obtain a globally unique distributed ID, it can use code to connect the database instance and execute the following sql statement.
insert into DISTRIBUTE_ID(createtime) values(NOW()); select LAST_INSERT_ID();
be careful:
1) The createtime field here has no practical significance. It is to insert a piece of data so that the id can be increased by itself.
2) Using an independent MySQL instance to generate a distributed id is feasible, but the performance and reliability are not good enough. Because you need code to connect to the database to obtain the id, the performance cannot be guaranteed. In addition, if the MySQL database instance hangs, you cannot obtain the fractional id.
3) Some developers have designed the mysql database used to generate distributed IDS into a cluster architecture for the above situation. In fact, this method is basically not used now because it is too troublesome.
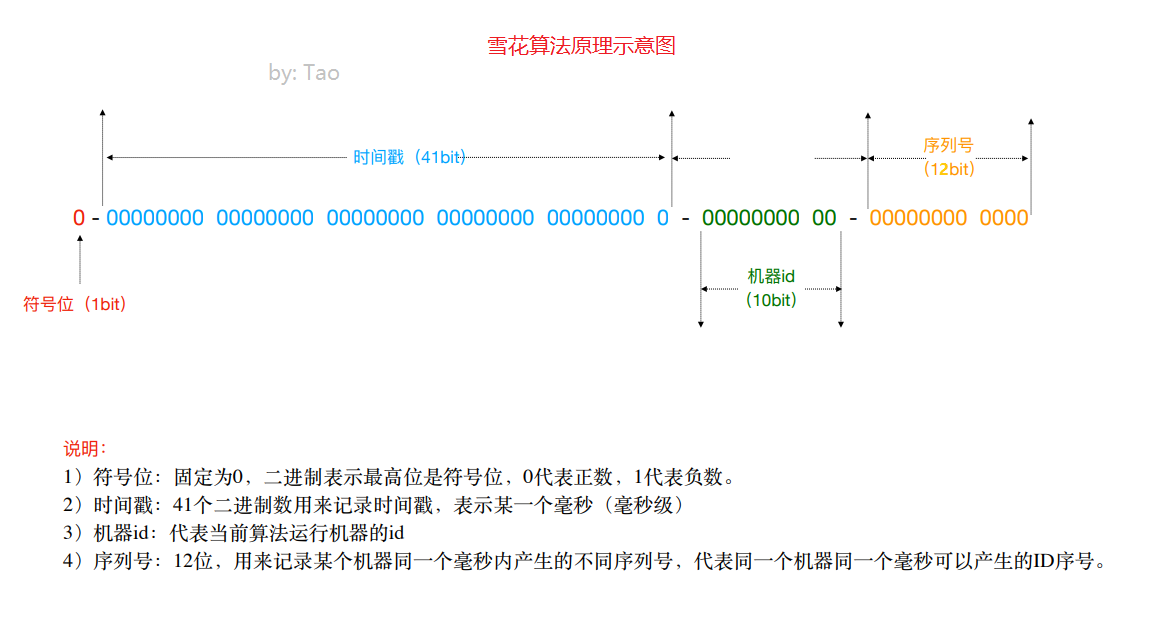
3. SnowFlake snowflake algorithm (available, recommended)
Snowflake algorithm is a strategy launched by Twitter to generate distributed ID S.
Snowflake algorithm is an algorithm. Based on this algorithm, ID can be generated. The generated ID is a long type. In Java, a long type is 8 bytes, which is 64bit. The following is the binary form of an ID generated by snowflake algorithm:
In addition, all Internet companies have also encapsulated some distributed ID generators based on the above scheme, such as Didi's tinyid (based on database implementation), Baidu's uidgenerator (based on SnowFlake) and meituan's leaf (based on database and SnowFlake).
Algorithm code:
/**
* It is officially launched in Scala programming language
* Java Predecessors implemented the snowflake algorithm in Java language
*/
public class IdWorker{
//The following two 5 bits each add up to a 10 bit work machine id
private long workerId; //Job id
private long datacenterId; //Data id
//12 digit serial number
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence){
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
//Initial timestamp
private long twepoch = 1288834974657L;
//The length is 5 digits
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
//Maximum
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//Serial number id length
private long sequenceBits = 12L;
//Maximum serial number
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//Number of bits of work id to be shifted left, 12 bits
private long workerIdShift = sequenceBits;
//The data id needs to be shifted left by 12 + 5 = 17 bits
private long datacenterIdShift = sequenceBits + workerIdBits;
//The timestamp needs to be shifted left by 12 + 5 + 5 = 22 bits
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//Last timestamp, initial value is negative
private long lastTimestamp = -1L;
public long getWorkerId(){
return workerId;
}
public long getDatacenterId(){
return datacenterId;
}
public long getTimestamp(){
return System.currentTimeMillis();
}
//Next ID generation algorithm
public synchronized long nextId() {
long timestamp = timeGen();
//Get the current timestamp. If it is less than the last timestamp, it indicates that the timestamp acquisition is abnormal
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
//Gets the current timestamp if it is equal to the last timestamp
//Note: if it is still in the same millisecond, add 1 to the serial number; Otherwise, the serial number is assigned to 0, starting from 0.
if (lastTimestamp == timestamp) { // 0 - 4095
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
//Refresh last timestamp value
lastTimestamp = timestamp;
/**
* Return result:
* (timestamp - twepoch) << timestampLeftShift) Indicates that the initial timestamp is subtracted from the timestamp, and then the corresponding digit is shifted to the left
* (datacenterId << datacenterIdShift) Indicates that the data id is shifted to the left by the corresponding digit
* (workerId << workerIdShift) Indicates that the work id is shifted to the left by the corresponding digit
* | It is a bitwise OR operator, such as x | y. The result is 0 only when x and y are 0, and the result is 1 in other cases.
* Because only the value in the corresponding bit is meaningful in one part and 0 in other bits, the final spliced id can be obtained by | operation on the value of each part
*/
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
//Get the timestamp and compare it with the last timestamp
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//Get system timestamp
private long timeGen(){
return System.currentTimeMillis();
}
public static void main(String[] args) {
IdWorker worker = new IdWorker(21,10,0);
for (int i = 0; i < 100; i++) {
System.out.println(worker.nextId());
}
}
}
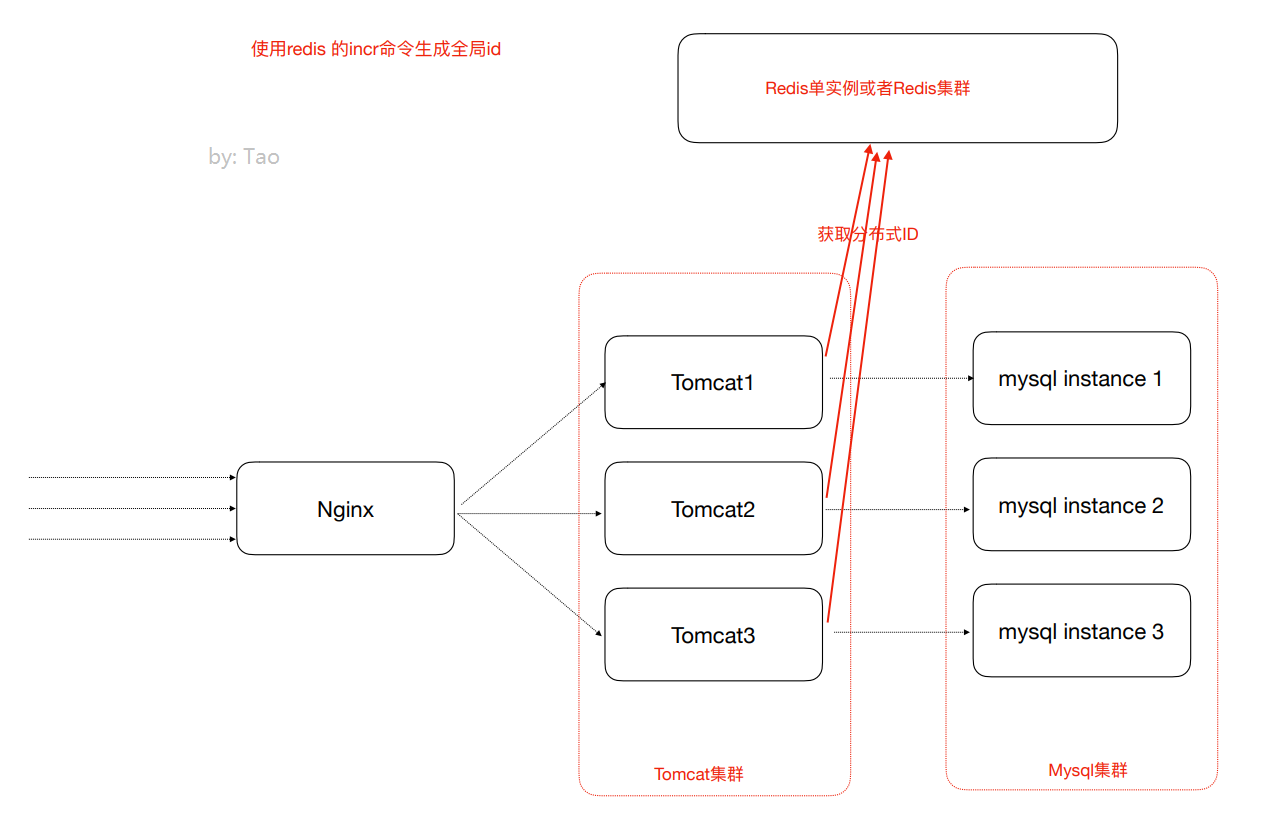
4. Obtain the globally unique ID with the Incr command of Redis (recommended)
The Redis Incr command increments the numeric value stored in the key by one. If the key does not exist, the value of the key will be initialized to 0 before performing the INCR operation.
<key,value>
<id,>
.incr(id) 1 2 3 4
Redis installation:
-
Download redis-3.2.10 from the official website tar. gz
-
Upload to the linux server and unzip tar -zxvf redis-3.2.10 tar. gz
-
cd decompress the file directory and compile the decompressed redis
make
-
Then cd enters the src directory and executes make install
-
Modify the redis. Config file in the extracted directory Conf, turn off protection mode
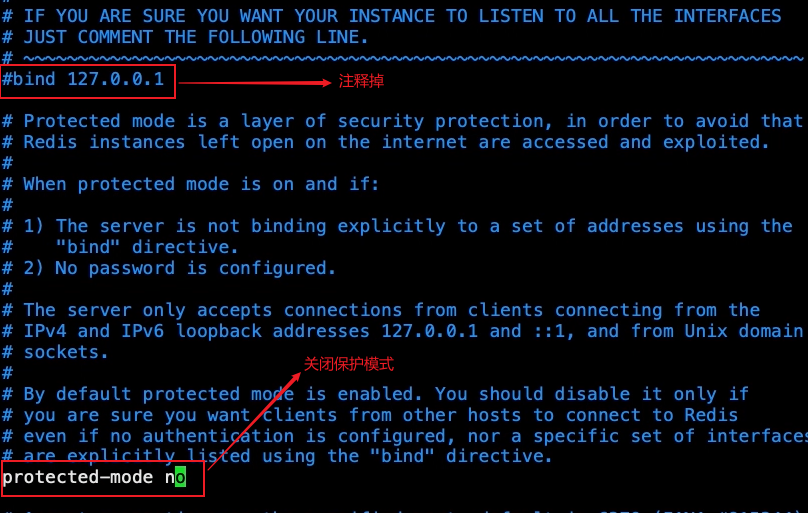
- Execute in src directory/ redis-server …/redis.conf start redis service
In the Java code, use the Jedis client to call the incr command of IDS to obtain a global id
- Introducing jedis client jar
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency>
- Java code (here we connect to a single node and do not use connection pool)
import redis.clients.jedis.Jedis;
public class RedisGenerator {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.2.3",6379);
Long id = jedis.incr("id");//<id,0>
System.out.println(id);
}
}