Article Directory
Distributed Lock
1. Distributed Lock Implementation
With the development of business, the original single-machine deployment system has been evolved into a distributed cluster system. Because the distributed system is multi-threaded, multi-process and distributed on different machines, this will invalidate the concurrent control lock policy in the original single-machine deployment. The Java API alone cannot provide the ability of distributed locks.To solve this problem, a cross-JVM mutex mechanism is needed to control the access of shared resources, which is the problem to be solved by distributed locks.
The main implementation scheme of distributed locks:
- Distributed Lock Based on Database
- Cache-based (Redis, etc.)
- Zookeeper-based
Each distributed lock solution has its own advantages and disadvantages: - Performance: redis highest
- Reliability: zookeeper highest
This article focuses on the implementation of distributed locks based on redis.
2. Distributed Lock Using redis
redis:Command
set sku:1:info "OK" NX PX 10000
EX second: Sets the key's expiration time to seconds.SET key value EX second effect is equivalent to SETEX key second value.
PX millisecond: Sets the key's expiration time to milliseconds.SET key value PX millisecond effect is equivalent to PSETEX key millisecond value.
NX: The key is set only if it does not exist.SET key value NX effect is equivalent to SETNX key value.
XX: The key is set only when it already exists.
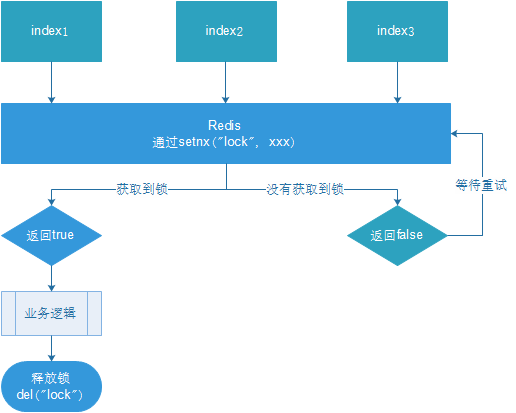
- Multiple clients acquire locks simultaneously (setnx)
- Achieve success, execute business logic, execute complete release lock (del)
- Other clients are waiting to retry
Learning optimization
- Problem: setnx just acquired the lock, business logic exception, lock could not be released
Solution: Set the lock expiration time to release the lock automatically. - Problem: Business operation time may be longer than lock expiration time, at which time this thread may delete locks of other threads
Solution: When setnx acquires a lock, set a specified unique value (for example, uuid); get this value before releasing to determine if it is its own lock - Problem: Operation lacks atomicity
Solution: LUA scripts guarantee deletion atomicity
summary
To ensure that distributed locks are available, we need to ensure that locks are implemented with at least four conditions:
- Mutual exclusion.Only one client can hold a lock at any time.
- No deadlock will occur.Even if one client crashes during the lock-holding period without actively unlocking, subsequent clients can be locked.
- The bell must also be ringer.Locking and unlocking must be the same client. Clients themselves cannot unlock locks that others have added.
- Locking and unlocking must be atomic.
Problems in the redis cluster state:
- Client A acquires locks from master
- Master dropped the lock before master synchronized it to slave.
- slave node promoted to master node
- Client B acquired another lock on the same resource that Client A already acquired.
Safety failure!
Solution:
Redlock implementation
The redlock algorithm proposed by antirez is probably the following:
In a distributed environment of Redis, we assume that there are N Redis masters.These nodes are completely independent of each other, and there is no master-slave replication or other cluster coordination mechanism.We ensure that locks are acquired and released on N instances in the same way as on Redis single instances.Now let's assume there are five Redis master nodes and we need to run these Redis instances on five servers at the same time so that they don't all go down at the same time.
In order to get the lock, the client should do the following:
Gets the current Unix time in milliseconds.
Trying to acquire locks from five instances in turn, using the same key and unique value (such as UUID).When requesting a lock from Redis, the client should set a network connection and response timeout that is less than the lock's expiration time.For example, if your lock automatically expires in 10 seconds, the time-out should be between 5 and 50 milliseconds.This prevents the client from waiting desperately for a response when the server-side Redis has been suspended.If the server does not respond within the specified time, the client should try to get a lock from another Redis instance as soon as possible.
The client uses the current time minus the time it started acquiring the lock (time recorded in step 1) to get the time it took to acquire the lock.Locks are successful only if and only if the locks are taken from most of the Edits nodes (N/2+1, here are three) and are used for less than the lock expiration time.
If a lock is retrieved, the real effective time of the key is equal to the effective time minus the time used to acquire the lock (the result of step 3).
If for some reason the acquisition of a lock fails (at least N/2+1 Redis instances have not acquired the lock or the acquisition time has exceeded the valid time), the client should unlock all Redis instances (even if some Redis instances have not successfully locked at all, preventing some nodes from acquiring the lock but the client has not responded and causing a period of time to elapseCan be re-acquired).
Extracted from ( Redlock implementation)
Solving distributed locks using redisson
Redisson is a Java In-Memory Data Grid based on Redis.It not only provides a series of distributed Java common objects, but also provides many distributed services.These include (BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson which provides the easiest and easiest way to use Redis.The purpose of Redisson is to promote a separation of Redis concerns so that users can focus more on their business logic.
Official Document Address:https://github.com/redisson/redisson/wiki
Connect document:https://github.com/redisson/redisson
1. Import dependent service-util
<!-- redisson --> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.11.2</version> </dependency>
2. Configure redisson
@Data @Configuration @ConfigurationProperties("spring.redis") public class RedissonConfig { private String host; private String password; private String port; private int timeout = 3000; private static String ADDRESS_PREFIX = "redis://"; /** * automatic assembly */ @Bean RedissonClient redissonSingle() { Config config = new Config(); if(StringUtils.isEmpty(host)){ throw new RuntimeException("host is empty"); } SingleServerConfig serverConfig = config.useSingleServer() .setAddress(ADDRESS_PREFIX + this.host + ":"+ port) .setTimeout(this.timeout); if(!StringUtils.isEmpty(this.password)) { serverConfig.setPassword(this.password); } return Redisson.create(config); } }
Reentrant Lock
Redis-based Reedisson Distributed Re-entrainable Lock Java Object ImplementationJava.util.concurrent.Locks.LockInterface.
It is well known that if the Edsson node responsible for storing this distributed lock is down and the lock is in a locked state, the lock will be locked.To avoid this, Redisson provides a watchdog inside that monitors locks, which continuously prolongs the duration of the locks until the Redisson instance is closed.By default, the time-out for a watchdog's check lock is 30 seconds or can be modified Config.lockWatchdogTimeout To specify otherwise.
Redisson also provides the leaseTime parameter to specify the lock time by locking.After this time the lock is automatically unlocked.
@Autowired private RedissonClient redisson; ... RLock lock = redisson.getLock("anyLock"); // Most often used lock.lock(); // Automatic unlock 10 seconds after lock // No need to call unlock method to unlock manually lock.lock(10, TimeUnit.SECONDS); // Attempt to lock, wait up to 100 seconds, unlock automatically 10 seconds after lock boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS); if (res) { try { ... } finally { lock.unlock(); } } ...
- Test Code
public String testLockRedisson(){ RLock lock = redissonClient.getLock("lock"); try { //Three locks, one lock.lock();// permanent lock.lock(10, TimeUnit.SECONDS);// Expires in 10 seconds try { boolean b = lock.tryLock(100, 10, TimeUnit.SECONDS); if (b) { // setnx success equivalent to redis } } catch (InterruptedException e) { e.printStackTrace(); } }finally { lock.unlock();// Unlock } return null; }
Test Code
@Autowired RedisTemplate redisTemplate; /*** * Before caching annotations with aop * @param skuId * @return */ // @Override public SkuInfo getSkuInfoBak(Long skuId) { //key to store data String skuRedisKey = prefix+skuId+Suffix; //lock for Distributed Locks String skuRedisLock = prefix+skuId+Suffix; SkuInfo skuInfo = null; //Query Cache String skuInfoStr = (String) redisTemplate.opsForValue().get(skuRedisKey); //Determines whether it is empty, does not set the return data to be taken from the cache if (StringUtils.isNotBlank(skuInfoStr)){ skuInfo = JSON.parseObject(skuInfoStr,SkuInfo.class); }else {//skuInfo is empty //UUID used to determine the distributed lock to be deleted by this thread String uuid = UUID.randomUUID().toString(); //The key of a distributed lock,sku:skuId:lock Boolean OK = redisTemplate.opsForValue().setIfAbsent(skuRedisLock, uuid, RedisConst.SKULOCK_EXPIRE_PX1, TimeUnit.SECONDS); //Acquire locks if (OK){ //Perform query db operation skuInfo = getSkuInfoDB(skuId); //When querying data that does not exist, to prevent redis cache penetration, place null values in redis and set an expiration time if (skuInfo==null){ skuInfo = new SkuInfo(); redisTemplate.opsForValue().set(skuRedisKey, JSON.toJSONString(skuInfo),60*60,TimeUnit.SECONDS); return skuInfo; } //Query the data and put in redis redisTemplate.opsForValue().set(skuRedisKey, JSON.toJSONString(skuInfo));//Item details key in cache //Use the Lua script to delete the distributed lock// lua, after get to the key, delete the key according to the value of the key DefaultRedisScript<Long> luaScript = new DefaultRedisScript<>(); //Setting the return value type luaScript.setResultType(Long.class); luaScript.setScriptText("if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"); redisTemplate.execute(luaScript, Arrays.asList(skuRedisLock), uuid); return skuInfo; }else { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return getSkuInfo(skuId); } } return skuInfo; }
Distributed Lock + AOP Implementation Cache
With the addition of caching and distributed locks in the business, business code becomes more complex. In addition to business logic itself, caching and distributed locks are also considered, which increases the workload and development difficulty.Cached routines are particularly similar to transactions, and declarative transactions are implemented using the idea of aop.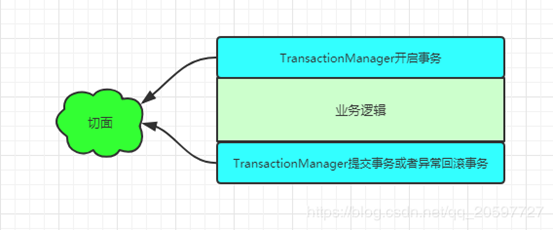
- Use the @Transactional annotation as the cut point for the implant point so that you know that the @Transactional annotation method needs to be proxied.
- The tangent logic of the @Transactional annotation is similar to @Around
Simulate transactions, caching can do this:
- Custom Cache Annotation @GmallCache (similar to Transaction@Transactional)
- Write facet classes that use wrapping notifications for logical encapsulation of caches
1. Define a note
import java.lang.annotation.*; @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface GmallCache { /** * Cache key prefix * @return */ String prefix() default "cache"; }
2. Define a tangent class with comments
@Component//Add Cutting Class to IOC Container @Aspect//Make it a tangent class public class GmallCacheAspect { @Autowired private RedissonClient redissonClient; @Autowired private RedisTemplate redisTemplate; //Defines the tangent expression that needs to be matched, using the method of annotating GmallCache as the starting point @Around("@annotation(com.atguigu.gmall.common.cache.GmallCache)") public Object AopCache(ProceedingJoinPoint point){ //Declare an object object as a result of return Object result = null; //Obtaining connection point parameters Object[] args = point.getArgs(); //Obtaining raw method information through reflection MethodSignature signature = (MethodSignature) point.getSignature(); //return type Class returnType = signature.getReturnType(); //annotation GmallCache gmallCache = signature.getMethod().getAnnotation(GmallCache.class); //Get annotation information as prefix String prefix = gmallCache.prefix(); //Splicing cache key s based on annotation information String key = prefix+ Arrays.asList(args); String keyInfo = key+Suffix; //Cache code execution result = cacheHit(returnType,keyInfo); //Indicates that the cache is not empty and returns the result directly if (result!=null){ return result; } //Cache empty, query from database //Use redisson to obtain distributed locks RLock lock = redissonClient.getLock(key + Random Suffix); //Execute connection point method, query db try { // Attempt to lock, wait up to 100 seconds, unlock automatically 10 seconds after lock boolean b = lock.tryLock(100, 10, TimeUnit.SECONDS); //Acquire locks if (b){ //Execute connection point method, query db result = point.proceed(args); //If the query database cannot query the data, place empty objects in the cache to prevent cache penetration if (result==null){ redisTemplate.opsForValue().setIfAbsent(keyInfo, JSON.toJSONString(new Object()), 60*60, TimeUnit.SECONDS); return result; }else { //Query the database to get data that is not empty, sync to the redis cache, and return the results redisTemplate.opsForValue().set(keyInfo, JSON.toJSONString(result)); //Return results return result; } }else { // If you do not get a distributed lock, someone has already checked the database, and the currently executing thread just fetches the data that other threads have stored in the cache. Thread.sleep(1000); //Looking at some data seems like a spin lock cacheHit(returnType,keyInfo); } } catch (Throwable throwable) { throwable.printStackTrace(); }finally { lock.unlock(); } return result;//Returns the result required by the original method } /*** * Query key in cache * @param returnType * @param key * @return */ private Object cacheHit(Class returnType, String key) { Object resulet = null; String cache = (String) redisTemplate.opsForValue().get(key); if (StringUtils.isNotBlank(cache)){ resulet = JSON.parseObject(cache,returnType); } return resulet; } }
3. Cache method will need to be used with cache annotations
When redis is not cached,
@GmallCache()//You can prefix the set method with your own public SkuInfo getSkuInfo(Long skuId) { //Query Database Method return getSkuInfoDB(skuId); }