Test the WordCount function in Hadoop cluster
Goal: build a Hadoop development environment using Eclipse+Maven, and compile and run the official WordCount source code.
Create Hadoop project
establish
Maven
project
Creating
Maven
Please set it before the project
Maven
, at least
maven
Change the image to domestic source
stay
Eclipse
In,
Fil·e>New>Maven Project
:
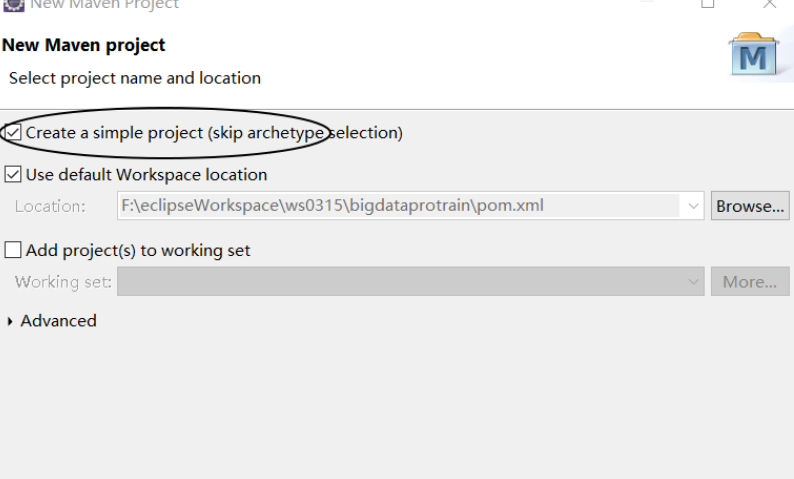
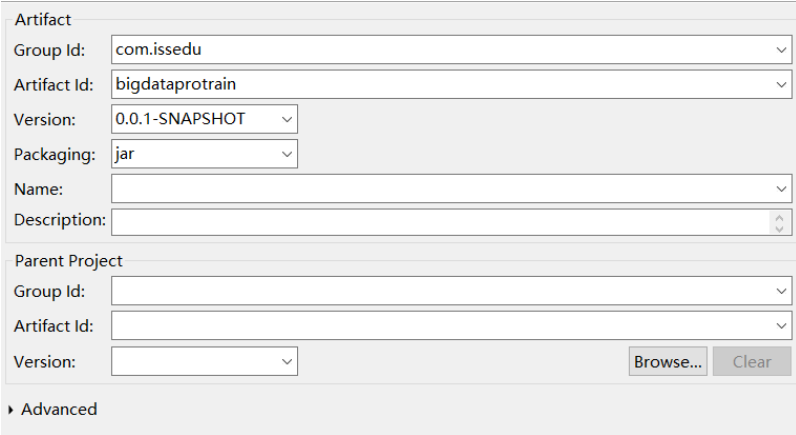
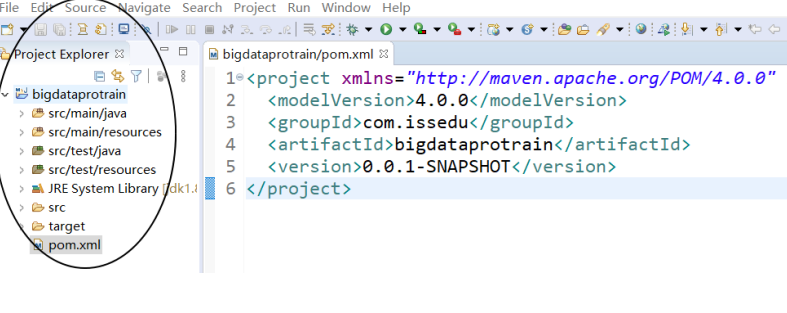
Add Hadoop dependency
At the beginning of the project
pom.xml
Document
project
Add the following content under the node (in < project > < / Project >):
<properties>
<hadoop.version>2.8.5</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>hadoop jar package has been added to the project
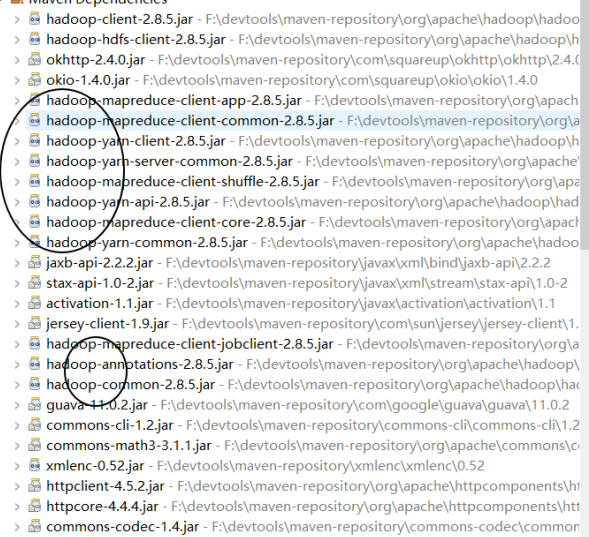
Implement WordCount function
You can start from
hadoop
Extract from the official installation package
WordCount
Source code, the path in the compressed package is:
hadoop-
2.8.5\share\hadoop\mapreduce\sources\hadoop-mapreduce-examples-2.8.5-
sources.jar
, use the decompression tool directly from the
jar
Extract from the package
WordCount.java
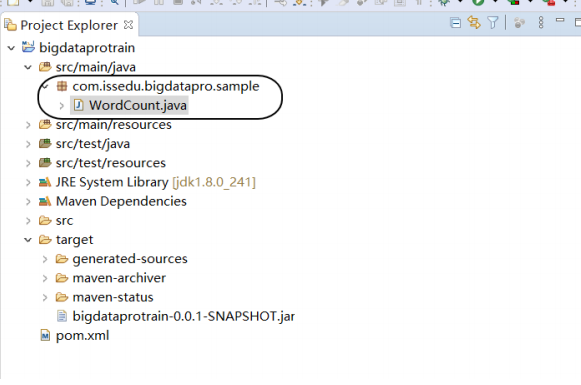
Some official source codes:

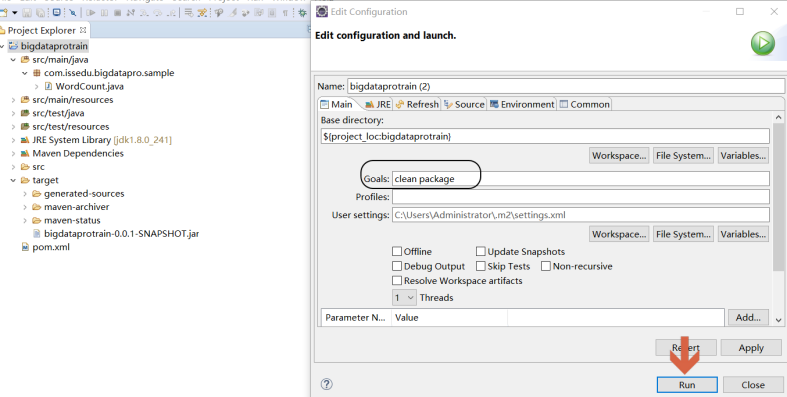
Build project
Right click the item and select[
run as
]
>
[
maven build...
], in
Goals
Medium input
clean package
:
Test the WordCount function in the cluster
Start cluster
start-all.sh
jps check and run, and the results must at least include:
[root@hadoopnode1 ~]# jps 136 NameNode 252 ResourceManager 862 Jps
Create a test file (myword.txt) in the virtual machine
[root@hadoopnode1 ~]# mkdir -p /home/demo [root@hadoopnode1 ~]# cd/home/demo [root@hadoopnode1 demo]# vi myword.txt
Write in the file (of course, this is only the test data, and the specific data is still based on your needs):
this is a wordcount test! hello! my name is jerry. who are you! where are you from! the end!
Create an input folder on hdfs(
-p is to create the parent directory along the path
-p
Is to create a parent directory along the path
):
[root@hadoopnode1 demo]# hdfs dfs -mkdir -p /wordcount/input
Upload test files to hdfs:
[root@hadoopnode1 demo]# hdfs dfs -put myword.txt /wordcount/input
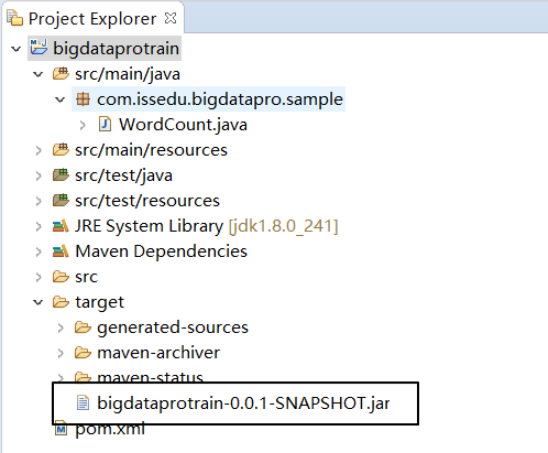
Upload the jar package and run:
Packed
/bigdataprotrain/target/bigdataprotrain-0.0.1-SNAPSHOT.jar
utilize
ftp
Tool upload
To cluster
namenode
node
/home/demo
Directory:
Command interpretation: hadoop jar Jar package name Package name. Class name Enter file address Output file address
- /wordcount/input / is the directory where the input file is located, which needs to be established in advance
- /wordcount/output is the directory where the output file is located. The output directory is automatically created and cannot be saved in advance
- Otherwise, an error will occur. If it exists, please delete it in advance.
- com.issedu.bigdatapro.sample.WordCount is the package name plus the class name of the main method
[root@hadoopnode1 demo]# hadoop jar bigdataprotrain-0.0.1- SNAPSHOT.jar com.issedu.bigdatapro.sample.WordCount /wordcount/input/ /wordcount/output
View output results:
[root@hadoopnode1 demo]# hdfs dfs -ls /wordcount/output
Results at this time:
be careful:
_SUCCESS
The number of file bytes is
0
, there is no content, but the output is marked as successful. The actual content is displayed in the
part-r-
00000
In, there may be multiple files with different serial numbers
Found 2 items
-rw-r--r-- 3 root supergroup 0 2020-03-18 09:42
/wordcount/output/_SUCCESS
-rw-r--r-- 3 root supergroup 120 2020-03-18 09:42
/wordcount/output/part-r-00000
Download to local view
[root@hadoopnode1 demo]# hdfs dfs -get /wordcount/output/part* [root@hadoopnode1 demo]# cat part-r-00000
The results are as follows:
a 1
are 2
end! 1
from! 1
hello! 1
is 2
jerry. 1
my 1
name 1
test! 1
the 1
this 1
where 1
who 1
wordcount 1
you 1
you! 1