Original website:
brief introduction
This paper introduces the snowflake algorithm in distributed. Including: usage and principle.
The snowflake algorithm is used to generate a globally unique ID.
Principle of snowflake algorithm
Snowflake, snowflake algorithm, is a distributed ID generation algorithm open source by Twitter. Project website: https://github.com/twitter/snowflake.
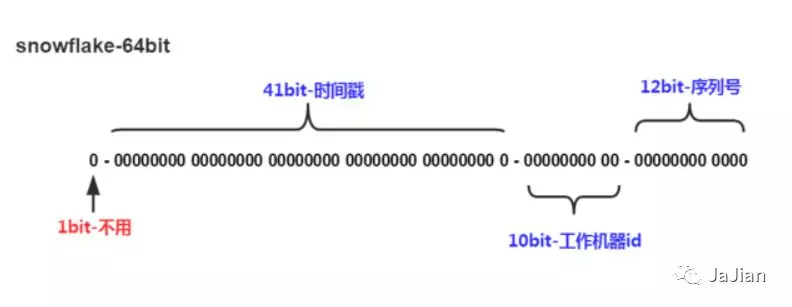
SnowFlake algorithm divides 64 bit into several parts by dividing namespace, and each part represents different meanings. The 64bit integer in Java is of long type, so the ID generated by SnowFlake algorithm in Java is stored in long.
- The first bit occupies 1 bit, and its value is always 0.
- It can be seen that the sign bit is not used.
- The 41 bits starting with bit 2 are time stamps
- 41bit can represent 2 ^ 41 numbers, and each number represents milliseconds. Then the available time period of snowflake algorithm is (1L < < 41) / (1000l36024 * 365) = 69 years.
- The middle 10 bit indicates the number of machines
- That is, 2 ^ 10 = 1024 machines, but generally we will not deploy such machines.
- If we have a demand for IDC (Internet Data Center), we can divide 10 bit into 5-bit to IDC and 5-bit into working machines. In this way, 32 IDCs can be represented, and there can be 32 machines under each IDC. The specific division can be defined according to their own needs.
- The last bit = 4096-12 bits of the sequence.
After such division, 4096 ordered and non duplicate IDS can be generated on a machine in a data center in one millisecond. However, there must be more than one IDC and machine, so the number of ordered IDs that can be generated in milliseconds is doubled.
code implementation
The official version of Snowflake's Twitter is written in scala. Students who have studied the Scala language can read it. The following is the writing method of the Java version.
The following is just a simple Demo. In actual use, it is best to use the singleton mode to ensure that there is only one SnowflakeIdWorker.
package com.example.a;
/**
* Twitter_Snowflake<br>
* SnowFlake The structure of the is as follows (each part is separated by): < br >
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1 Bit identification: because the basic type of long is signed in Java, the highest bit is the sign bit, the positive number is 0 and the negative number is 1, so the id is generally a positive number and the highest bit is 0 < br >
* 41 Bit time cut (in milliseconds). Note that the 41 bit time cut is not the time cut that stores the current time, but the difference of the stored time cut (current time cut - start time cut)
* The start time cut here is generally the time when our id generator starts to use, which is specified by our program (the startTime attribute of IdWorker class in the following program). The 41 bit time cut can be used for 69 years. Year t = (1L < < 41) / (1000L * 60 * 60 * 24 * 365) = 69 < br >
* 10 Bit data machine can be deployed in 1024 nodes, including 5-bit datacenter ID and 5-bit workerid < br >
* 12 Bit sequence, counting within milliseconds, and 12 bit counting sequence number. Each node can generate 4096 ID sequence numbers per millisecond (the same machine, the same time cut) < br >
* Add up to just 64 bits, which is a Long type< br>
* SnowFlake The advantage is that, on the whole, it is sorted by time, and there is no ID collision in the whole distributed system (distinguished by data center ID and machine ID), and the efficiency is high. After testing, SnowFlake can generate about 260000 IDS per second.
*/
public class SnowflakeIdWorker {
// ==============================Fields===========================================
/** Start time (January 1, 2015). Generally, the latest time of the system is taken (once it is determined, it cannot be changed) */
private final long twepoch = 1420041600000L;
/** Number of digits occupied by machine id */
private final long workerIdBits = 5L;
/** Number of bits occupied by data id */
private final long datacenterIdBits = 5L;
/** The maximum machine id supported is 31 (this shift algorithm can quickly calculate the maximum decimal number represented by several binary numbers) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** The maximum data id supported is 31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** The number of bits the sequence occupies in the id */
private final long sequenceBits = 12L;
/** The machine ID shifts 12 bits to the left */
private final long workerIdShift = sequenceBits;
/** Data id shifts 17 bits to the left (12 + 5) */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** Shift the time cut to the left by 22 bits (5 + 5 + 12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** The mask of the generated sequence is 4095 (0b111111 = 0xfff = 4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** Working machine ID(0~31) */
private long workerId;
/** Data center ID(0~31) */
private long datacenterId;
/** Sequence in milliseconds (0 ~ 4095) */
private long sequence = 0L;
/** Last generated ID */
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* Constructor
* @param workerId Job ID (0~31)
* @param datacenterId Data center ID (0~31)
*/
private SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// Singleton mode
private static class SnowflakeIdWorkerHolder {
private static final SnowflakeIdWorker INSTANCE = new SnowflakeIdWorker(0, 0);
}
private static SnowflakeIdWorker getInstance() {
return SnowflakeIdWorkerHolder.INSTANCE;
}
public long generateId() {
return SnowflakeIdWorker.getInstance().nextId();
}
// ==============================Methods==========================================
/**
* Get the next ID (this method is thread safe)
* @return SnowflakeId
*/
private synchronized long nextId() {
long timestamp = timeGen();
//If the current time is less than the timestamp generated by the last ID, it indicates that the system clock has fallback, and an exception should be thrown at this time
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//If it is generated at the same time, the sequence within milliseconds is performed
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//Sequence overflow in milliseconds
if (sequence == 0) {
//Block to the next millisecond and get a new timestamp
timestamp = tilNextMillis(lastTimestamp);
}
}
//The timestamp changes and the sequence resets in milliseconds
else {
sequence = 0L;
}
//Last generated ID
lastTimestamp = timestamp;
//Shift and put together by or operation to form a 64 bit ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* Block to the next millisecond until a new timestamp is obtained
* @param lastTimestamp Last generated ID
* @return Current timestamp
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* Returns the current time in milliseconds
* @return Current time (MS)
*/
private long timeGen() {
return System.currentTimeMillis();
}
//==============================Test=============================================
/** test */
public static void main(String[] args) {
// SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
// for (int i = 0; i < 1000; i++) {
// long id = idWorker.nextId();
// System.out.println(Long.toBinaryString(id));
// System.out.println(id);
// }
long id = SnowflakeIdWorker.getInstance().generateId();
System.out.println(id);
}
}advantage
- Independent of third parties
- High performance.
- Because it is incremental, it is conducive to database sorting
- Simple implementation
- High flexibility
- Applicable sub database and sub table
shortcoming
- After time fallback, the ID may be repeated
- Snowflake algorithm strongly depends on the machine clock. If the clock on the machine is dialed back, it will lead to repeated signal issuance or the service will be unavailable. If it happens that some IDs have been generated before fallback, and after time fallback, the generated IDs may be repeated. The official did not give a solution for this, but simply threw the wrong processing, which would make the service unavailable before the time was recovered.
- Now there are many implementations based on snowflake algorithm to solve the problem of clock fallback. For example: Baidu's UidGenerator and meituan Leaf's snowflake model.