Distributed storage ShardingSphere (read / write separation & Distributed Transaction)
We talked about the configuration and use of ShardingSphere earlier, but as a database middleware, it can do more than just divide databases and tables. This article wants to talk about
- It supports mysql read-write separation
- It supports distributed transactions. The default manager is [Atomikos]
- At the same time, a mysql server with one master and one slave will be built [because at least two servers are the premise of shardingshpher read-write separation]
- I will also talk about 2pc, base and cap theories related to distributed transactions.
mysql read / write separation
In the scenario of more reading and less writing, the advantages of separating reading and writing from the database are as follows:
- Reduce competition between shared locks and exclusive locks.
- Reduce the pressure on the server: when there are too many read requests, we can reduce the pressure on the database by expanding the read database horizontally.
- Configure different types of databases: in most cases, we configure innodb (operation supporting transactions). For query, we can configure MyISAM engine to improve efficiency
Configuration of mysql read / write separation [binlog]:
- When a database transaction occurs, it will write the operation into a log,
- Then, an io thread in the slave node sends a read operation regularly,
- The master will generate a binlog and return the binlog to the slave,
- slave will write the obtained binlog in its own relaylog, and then use a thread to execute it
Operation steps:
[overall process]
- The mater node needs to enable the binlog log
- The slave node needs to specify a binlog and start reading from that location
- slave needs to specify the ip, user name and password of the master node
[actual steps]
[set up two mysql servers] (I use mysql 8.0):
- 192.168.43.4[master]
- 192.168.43.3 [slave]
[enable binlog on the master node] add two lines of code to the mysql configuration file
- log-bin=/var/lib/mysql/mysql-bin
- server-id=1001
- Log bin refers to the location of your logbin file,
- Server ID refers to the unique identifier of your mysql server. slave needs to know this when reading
- Then restart mysql. After restarting, you will find that logbin has been generated in the log bin directory
-
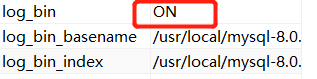
- Or use the sql query [show variables like 'log_bin%;] to find that log bin is already in on status, which also proves that it has been turned on

Create a user in the master node: it is equivalent to a white list. Only this user can copy data from the master
- --Create a user, where repl represents the user name and 192.168.43.3 represents the ip address of the slave library, that is, only this ip is allowed to access the master library through the repl user
- create user 'repl'@'192.168.43.3' identified with mysql_native_password by'123456';
- to grant authorization
- --replication slave means authorized replication -- *.* Represents all libraries and tables
- grant replication slave on *.* to 'repl'@'192.168.43.3';
- Refresh permission information
- flush privileges;

[ Connect master ] [change master to master_host='192.168.43.4',master_user='repl',master_password='123456',master_log_file='binlog.000002',master_log_pos=855;]

Query synchronization status: [show slave status\G] when you see that the following two attributes are yes, it proves that we have configured them

[possible problems]: because I directly copied the virtual machine, but the serverid of mysql is consistent, the above slave IO running: no situation may occur. We only need to modify the id in auto confi to be inconsistent.
[test]: when we create a new database on the master, the same database will be automatically created on the slave. Similarly, when we create a new table, the slave will be automatically created. So far, the master-slave configuration and construction are completed.
[what binlog is]: query all binlogs [show BINARY LOGS;] and query the binlog currently used [SHOW BINLOG EVENTS in 'here is the file queried by using show master status]. In fact, it just puts the sql in info every time and takes it to slave for parsing and execution, which achieves the same effect as the master

[what about the master-slave synchronization delay?]: when the master node communicates with the slave node, the network delay cannot be avoided, which may be
Data synchronization delay caused by large transactions or too many nodes. In this case, we can judge the delay amount of the primary database through these fields in [show slave status\G]. If the delay is too large, we can directly force the primary database.
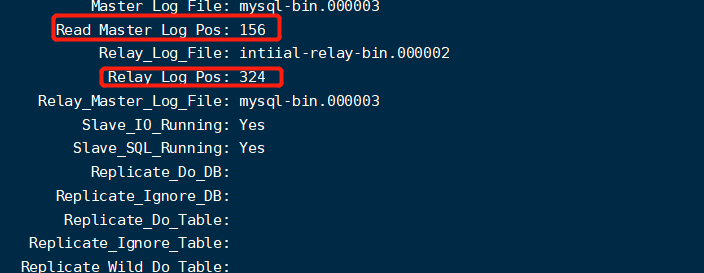
Either by controlling the number of slave nodes or cascading, the specific situation still needs to be determined according to the actual situation.
ShardingJDBC realizes read-write separation
A master-slave mysql server has been built above. However, when an sql server accesses our server, how can we judge which node it goes? At this time, shardingSphere has done this for us.
[configuration]
spring.shardingsphere.props.sql-show=true spring.shardingsphere.datasource.names="write-ds,read-ds" spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver #Write library configuration spring.shardingsphere.datasource.write-ds.jdbc-url=jdbc:mysql://192.168.43.4/readwritedb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.write-ds.username=root spring.shardingsphere.datasource.write-ds.password=123456 #Read library configuration spring.shardingsphere.datasource.read-ds.jdbc-url=jdbc:mysql://192.168.43.3/readwritedb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.read-ds.username=root spring.shardingsphere.datasource.read-ds.password=123456 # The name db0 is defined arbitrarily, which is the name of a logical library spring.shardingsphere.rules.replica-query.data-sources.db0.primary-data-source-name=write-ds spring.shardingsphere.rules.replica-query.data-sources.db0.replica-data-source-names=read-ds spring.shardingsphere.rules.replica-query.load-balancers.db0.type=ROUND_ROBIN #It doesn't make any sense spring.shardingsphere.rules.replica-query.load-balancers.db0.props.test=test
Test insert a piece of data

It was found that it went through the write library

Query a piece of data

It was found that it was reading the library

ShardingJDBC distributed transaction
Splitting databases and tables solves the pressure of databases, but this brings a new problem, distributed transactions. When users click a button, it may involve the operation of multiple tables. However, after splitting databases and tables, these tables are not in the same database. How to ensure the consistency of transactions? This leads to global transactions. The process is as follows: Below:
- In an application, operate the data of two databases at the same time [when mysql receives the data that needs to operate a database, it cannot operate directly because it becomes a single transaction]
- At this time, a third-party global transaction is introduced, which determines whether the two operations succeed or fail at the same time.
- When the operations of the two databases are completed [they will not directly commit the transaction], they will send a message to the global transaction to tell the global transaction whether their operation is successful or failed.
- Once there is an execution error of a node, the global transaction will let them roll back the transaction, otherwise they will be told to commit the transaction, so as to ensure the consistency of the transaction
[question]: we certainly can't use traditional transactions here, because global transactions will be submitted automatically. There is an XA protocol here
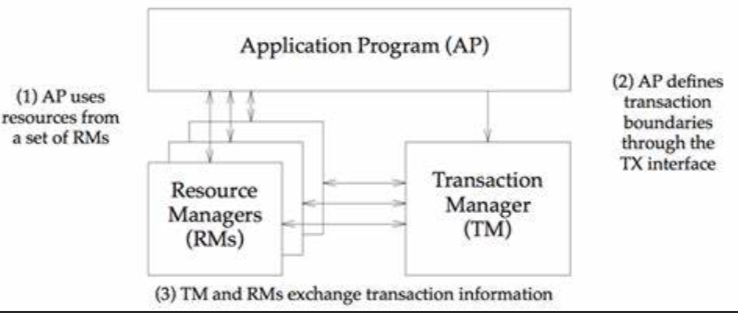
[XA protocol]: it is a protocol in a set of distributed transaction standards defined by the X/Open organization. In fact, the organization provides three roles and two protocols, which can be used to build a distributed transaction solution.
The three roles are as follows:

Specific methods:
to configure
spring.shardingsphere.props.sql-show=true spring.shardingsphere.datasource.names="ds-0,ds-1" spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver #Configure two data sources spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://192.168.43.3/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.ds-0.username=root spring.shardingsphere.datasource.ds-0.password=123456 spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://192.168.43.4/shard02?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.ds-1.username=root spring.shardingsphere.datasource.ds-1.password=123456 #Use user_id as partition key spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_id spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2} #Primary key generation rules spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_id spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=snowflake spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
Just add an annotation to the code. Let's test the error in the code to see if the transaction will be rolled back
@Override @Transactional(rollbackFor = Exception.class) @ShardingTransactionType(TransactionType.XA) public TOrder addOrder() { for (int i = 0; i <10 ; i++) { TOrder tOrder=new TOrder(); tOrder.setAddressId(1); tOrder.setStatus("GLOBAL_TRANSACTION"); tOrder.setUserId(random.nextInt(1000)); //Here let i When it is equal to 4, an error is reported to see if it will be rolled back if(i==4){ int ex=1/0; } orderMapper.insert(tOrder); } return new TOrder(); }
We see that an error has been reported and the data has not entered the database

ShardingSphere default The XA transaction manager is Atomikos. How does it implement transaction management with multiple data sources?
In fact, it is mainly 2pc based submission (a consistency protocol):
- It means that the transaction manager sends execution commands to each database, each database starts to execute their operations, and sends the execution results to the transaction manager
- If one of the sending results of the resource manager [database] is wrong, the resource manager transaction manager sends a request for transaction rollback to the database. Otherwise, it sends a request for them to execute.
Problems involved in distributed transactions
- C: Consistency consistency whether multiple copies of the same data are the same in real time.
- A: Availability availability: if the system returns a clear result within a certain period of time, it is called the system availability.
- P: Partition tolerance partition fault tolerance distributes the same service in multiple systems, so as to ensure that when one system goes down, other systems still provide the same service
- Basically available: Our data is allowed to be out of sync for a certain period of time. For example, the data in my master is 5 and the data in the slave node is 2
- Soft State: allows the system to have data delay in data copies of multiple different nodes.
- Eventually Consistent: the final consistency of data is achieved at a final point