catalogue
1. Database self growth sequence or field
5. Twitter's snowflake algorithm
6. Generate unique ID with zookeeper
The system unique ID is a problem we often encounter when designing a system, and we often struggle with this problem. There are many methods to generate IDS, which can adapt to different scenarios, requirements and performance requirements. Therefore, some complex systems have multiple ID generation strategies. Here are some common ID generation strategies.
1. Database self growth sequence or field
The most common way. Using the database, the whole database is unique.
advantage:
1) Simple, convenient code, acceptable performance.
2) Digital ID natural sorting is very helpful for paging or sorting results.
Disadvantages:
1) The syntax and implementation of different databases are different. It needs to be handled during database migration or multi database version support.
2) In the case of single database, read-write separation or one master and multiple slaves, only one master database can be generated. Risk of single point of failure.
3) When the performance fails to meet the requirements, it is difficult to scale. (not applicable to massive high concurrency)
4) If multiple systems need to be merged or involve data migration, it will be quite painful.
5) There will be trouble when dividing tables and databases.
6) It is not necessarily continuous. Similar to MySQL, when the transaction generating a new ID is rolled back, the subsequent transactions will not use this ID. This is a tradeoff between performance and continuity. If in order to ensure continuity, the ID must be generated after the end of the transaction, there will be a performance problem.
7) In distributed database, if self increasing primary key is adopted, it may bring tail hot spots. Distributed databases often use the partition mode of range. When a large number of new records are added, IO will be concentrated on one partition, resulting in hot data.
Optimization scheme:
1) For a single point of the Master library, if there are multiple Master libraries, the starting number and step size of each Master library are different, which can be the number of masters. For example, Master1 generates 1, 4, 7 and 10, Master2 generates 2, 5, 8 and 11, and Master3 generates 3, 6, 9 and 12. In this way, the unique ID in the cluster can be generated effectively, and the load of ID generation database operation can be greatly reduced.
2. UUID
Common ways. It can be generated by database or program. Generally speaking, it is unique in the world. UUIDs are composed of 32 hexadecimal digits, so the length of each UUID is 128 bits (16 ^ 32 = 2 ^ 128). As a widely used standard, UUID has multiple implementation versions. The factors affecting it include time, network card MAC address, user-defined Namesapce and so on.
advantage:
1) Simple and convenient code.
2) The performance of ID generation is very good, and there are basically no performance problems.
3) It is unique in the world. It can take it easy in case of data migration, system data consolidation, or database change.
Disadvantages:
1) Without sorting, the trend cannot be guaranteed to increase.
2) UUID s are often stored in strings, and the efficiency of query is relatively low.
3) The storage space is relatively large. If it is a massive database, the storage capacity needs to be considered.
4) Large amount of transmitted data
5) Unreadable.
3. Variant of UUID
1) To solve the problem that UUID is not readable, you can use the method of UUID to Int64.
/// <summary>
///Gets a unique sequence of numbers based on GUID
/// </summary>
public static long GuidToInt64()
{
byte[] bytes = Guid.NewGuid().ToByteArray();
return BitConverter.ToInt64(bytes, 0);
}2) In order to solve the problem of UUID disorder, NHibernate provides Comb algorithm (combined guid/timestamp) in its primary key generation method. 10 bytes of the GUID are reserved, and another 6 bytes are used to represent the GUID generation time (DateTime).
/// <summary>
/// Generate a new <see cref="Guid"/> using the comb algorithm.
/// </summary>
private Guid GenerateComb()
{
byte[] guidArray = Guid.NewGuid().ToByteArray();
DateTime baseDate = new DateTime(1900, 1, 1);
DateTime now = DateTime.Now;
// Get the days and milliseconds which will be used to build
//the byte string
TimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks);
TimeSpan msecs = now.TimeOfDay;
// Convert to a byte array
// Note that SQL Server is accurate to 1/300th of a
// millisecond so we divide by 3.333333
byte[] daysArray = BitConverter.GetBytes(days.Days);
byte[] msecsArray = BitConverter.GetBytes((long)
(msecs.TotalMilliseconds / 3.333333));
// Reverse the bytes to match SQL Servers ordering
Array.Reverse(daysArray);
Array.Reverse(msecsArray);
// Copy the bytes into the guid
Array.Copy(daysArray, daysArray.Length - 2, guidArray,
guidArray.Length - 6, 2);
Array.Copy(msecsArray, msecsArray.Length - 4, guidArray,
guidArray.Length - 4, 4);
return new Guid(guidArray);
}Test the above algorithm and get the following results: for comparison, the first three are the results obtained by using the COMB algorithm, and the last 12 strings are in time order (3 UUID s generated in unified milliseconds). If they are generated again after a period of time, the 12 strings will be larger than those shown in the figure. The last three are directly generated guids.
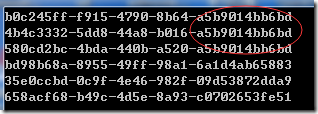
If you want to put the time order first, you can change the position of 12 strings after generation, or you can modify the last two arrays of the algorithm class Copy.
4. Redis generated ID
When the performance of using database to generate ID is not enough, we can try to use redis to generate ID. This mainly depends on that redis is single threaded, so it can also be used to generate globally unique IDs. Redis's atomic operations INCR and INCRBY can be used.
Redis cluster can be used to obtain higher throughput. Suppose there are 5 redis in a cluster. Each redis can be initialized with values of 1, 2, 3, 4 and 5 respectively, and then the step size is 5. The ID s generated by each redis are:
A: 1,6,11,16,21
B: 2,7,12,17,22
C: 3,8,13,18,23
D: 4,9,14,19,24
E: 5,10,15,20,25
Well, it's OK to load to any machine, and it's difficult to make modifications in the future. However, 3-5 servers can basically meet the requirements on the server, and can obtain different ID s. However, the step size and initial value must be required in advance. Redis cluster can also solve the problem of single point of failure.
In addition, Redis is more suitable for generating serial numbers starting from 0 every day. For example, order number = date + self growth number of the current day. A Key can be generated in Redis every day and accumulated using INCR.
advantage:
1) It does not depend on the database, is flexible and convenient, and its performance is better than the database.
2) Digital ID natural sorting is very helpful for paging or sorting results.
Disadvantages:
1) If there is no Redis in the system, new components need to be introduced to increase the complexity of the system.
2) The workload of coding and configuration is relatively large.
5. Twitter's snowflake algorithm
snowflake is Twitter's open source distributed ID generation algorithm, and the result is a long ID. Its core idea is to use 41bit as the number of milliseconds, 10bit as the machine ID (5 bits are the data center and 5 bit machine ID), 12bit as the serial number within milliseconds (meaning that each node can generate 4096 IDS per millisecond), and finally there is a symbol bit, which is always 0. For the specific implementation code, see https://github.com/twitter/snowflake . The TPS supported by snowflake algorithm can reach about 4.19 million (2 ^ 22 * 1000).
Snowflake algorithm has single machine version and distributed version in engineering implementation. The stand-alone version is as follows. For the distributed version, please refer to meituan leaf algorithm: https://github.com/Meituan-Dianping/Leaf
The C# code is as follows:
/// <summary>
/// From: https://github.com/twitter/snowflake
/// An object that generates IDs.
/// This is broken into a separate class in case
/// we ever want to support multiple worker threads
/// per process
/// </summary>
public class IdWorker
{
private long workerId;
private long datacenterId;
private long sequence = 0L;
private static long twepoch = 1288834974657L;
private static long workerIdBits = 5L;
private static long datacenterIdBits = 5L;
private static long maxWorkerId = -1L ^ (-1L << (int)workerIdBits);
private static long maxDatacenterId = -1L ^ (-1L << (int)datacenterIdBits);
private static long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << (int)sequenceBits);
private long lastTimestamp = -1L;
private static object syncRoot = new object();
public IdWorker(long workerId, long datacenterId)
{
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0)
{
throw new ArgumentException(string.Format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0)
{
throw new ArgumentException(string.Format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public long nextId()
{
lock (syncRoot)
{
long timestamp = timeGen();
if (timestamp < lastTimestamp)
{
throw new ApplicationException(string.Format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp)
{
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0)
{
timestamp = tilNextMillis(lastTimestamp);
}
}
else
{
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << (int)timestampLeftShift) | (datacenterId << (int)datacenterIdShift) | (workerId << (int)workerIdShift) | sequence;
}
}
protected long tilNextMillis(long lastTimestamp)
{
long timestamp = timeGen();
while (timestamp <= lastTimestamp)
{
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen()
{
return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;
}
}The test code is as follows:
private static void TestIdWorker()
{
HashSet<long> set = new HashSet<long>();
IdWorker idWorker1 = new IdWorker(0, 0);
IdWorker idWorker2 = new IdWorker(1, 0);
Thread t1 = new Thread(() => DoTestIdWoker(idWorker1, set));
Thread t2 = new Thread(() => DoTestIdWoker(idWorker2, set));
t1.IsBackground = true;
t2.IsBackground = true;
t1.Start();
t2.Start();
try
{
Thread.Sleep(30000);
t1.Abort();
t2.Abort();
}
catch (Exception e)
{
}
Console.WriteLine("done");
}
private static void DoTestIdWoker(IdWorker idWorker, HashSet<long> set)
{
while (true)
{
long id = idWorker.nextId();
if (!set.Add(id))
{
Console.WriteLine("duplicate:" + id);
}
Thread.Sleep(1);
}
}The snowflake algorithm can be modified according to the needs of its own project. For example, estimate the number of data centers in the future, the number of machines in each data center and the number of concurrency that can be unified in milliseconds to adjust the number of bit s required in the algorithm.
advantage:
1) It does not depend on the database, is flexible and convenient, and its performance is better than the database.
2) The ID is incremented on the stand-alone machine by time.
Disadvantages:
1) It is incremental on a single machine, but due to the distributed environment, the clock on each machine cannot be fully synchronized. The problem of time callback should be solved in the algorithm.
6. Generate unique ID with zookeeper
zookeeper mainly generates the serial number through its znode data version. It can generate 32-bit and 64 bit data version numbers. The client can use this version number as the unique serial number.
Zookeeper is rarely used to generate unique ID s. This is mainly because you need to rely on zookeeper and call the API in multiple steps. If there is a large competition, you need to consider using distributed locks. Therefore, the performance is not ideal in the highly concurrent distributed environment.
7. ObjectId of mongodb
The ObjectId of MongoDB is similar to the snowflake algorithm. It is designed to be light-weight, and different machines can easily generate it with the same globally unique method. MongoDB was designed as a distributed database from the beginning, and processing multiple nodes is a core requirement. Make it much easier to generate in a sharded environment.
The format is as follows:
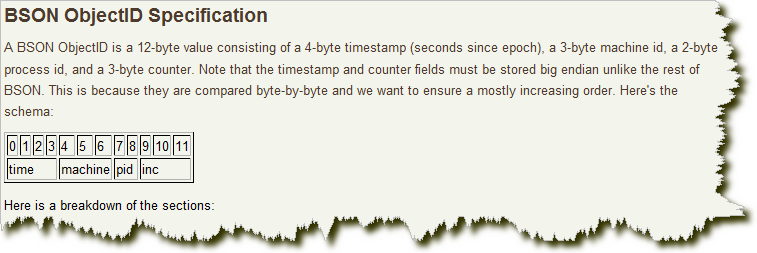
The first four bytes are the timestamp from the standard era, in seconds. The timestamp, combined with the next five bytes, provides second level uniqueness. Because the timestamp comes first, this means that the objectids are roughly in the order of insertion. This is useful for some aspects, such as using it as an index to improve efficiency. These four bytes also imply the time when the document was created. Most client class libraries expose a method to get this information from ObjectId.
The next three bytes are the unique identifier of the host. Usually a hash of the machine hostname. This ensures that different hosts generate different objectids without conflicts.
In order to ensure that the ObjectId generated by multiple concurrent processes on the same machine is unique, the next two bytes are from the process identifier (PID) generating the ObjectId.
The first 9 bytes ensure that the objectids generated by different processes on different machines in the same second are unique. The last three bytes are an automatically incremented counter to ensure that the ObjectId generated by the same process in the same second is also different. A maximum of 2563 (16 777 216) different objectids per process are allowed in the same second.
The source code can be downloaded from the official website of MongoDB.
8. Primary key of tidb
TiDB supports self incrementing primary keys by default. For tables that do not declare primary keys, an implicit primary key is provided_ tidb_rowid, because the primary key is monotonically increasing, there will also be the "tail hot spot" problem we mentioned earlier.
TiDB also provides the UUID function, and in version 4.0, it also provides another solution, AutoRandom. TiDB imitates the AutoIncrement of MySQL and provides the AutoRandom keyword to generate a random ID to fill the specified column.