Abstract: This paper introduces our practice sharing of building FlinkCDC streaming Hudi Sync Hive based on Dlink. The contents include:
- background information
- Ready to deploy
- data sheet
- debugging
- conclusion
1, Background information
Apache Hudi (pronounced "hoodie") is the next generation streaming data Lake platform. Apache Hudi brings core warehouse and database functions directly into the database. Hudi provides tables, transactions, efficient upgrade / delete, advanced indexing, streaming ingestion services, data clustering / compression optimization and concurrency, while keeping data stored in open source file format. Apache Hudi is not only well suited for streaming workloads, but also allows you to create efficient incremental batch pipelines.
The integration of real-time warehouse, stream and batch has become the general trend.
Why use Hudi?
- At present, the business structure is relatively heavy
- Maintain multiple frames
- The data is updated frequently
2, Background
assembly | edition | remarks |
|---|---|---|
Flink | 1.13.5 | Integrated into CM |
Flink-SQL-CDC | 2.1.1 | |
Hudi | 0.10.0-patch | Patched |
Mysql | 8.0.13 | Alibaba cloud |
Dlink | dlink-0.5.0-SNAPSHOT | |
Scala | 2.12 |
1. Deploy Flink 1.13.5
Integrate flynk into CM
This step is omitted.
2. Integrate Hudi 0.10.0
①. Address: https://github.com/danny0405/hudi/tree/010-patch Patched.
a. Download the compressed package branch 010 patch. Do not download the master upload and decompression.
b. unzip 010-patch.zip .
c. Find the POM under packing -- Hudi Flink bundle XML, change hive version under flick-bundel-shade-hive2 to 2.1.1-chd6 Version 3.2.
vim pom.xml # Modify hive version as: 2.1.1-cdh6 three point two
d. Perform compilation:
mvn clean install -DskipTests -DskipITs -Dcheckstyle.skip=true -Drat.skip=true -Dhadoop.version=3.0.0 -Pflink-bundle-shade-hive2 -Dscala-2.12
Because chd6 3.0 uses hadoop 3.0 0.0, so you should specify the version of hadoop. Hive uses version 2.1.1, and you should also specify the version of hive. Otherwise, when you use sync to hive, you will report a class conflict. The scala version is 2.12.
At the same time, when flink is integrated into cm, it is also scala2 12. Uniform version.
The compilation is completed as shown in the figure below:
②. Put the relevant jar packages in the corresponding directory.
# hudi's bag ln -s /opt/module/hudi-0.10.0/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/jars/ ln -s /opt/module/hudi-0.10.0/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/jars/ ln -s /opt/module/hudi-0.10.0/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/lib/hive/lib # Synchronize sync to hive every node should play cp /opt/module/hudi-0.10.0/hudi-flink-bundle/target/hudi-flink-bundle_2.12-0.10.0.jar /opt/cloudera/parcels/FLINK/lib/flink/lib/ # Put the following three jar s under flink/lib, otherwise an error will be reported when synchronizing data to hive cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/ cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/ cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/ # Execute the following command cd /opt/module/flink-1.13.5/lib/ scp -r ./* cdh5:`pwd` scp -r ./* cdh6:`pwd` scp -r ./* cdh7:`pwd`
3. Install Dlink-0.5.0
a. github address: https://github.com/DataLinkDC/dlink
b. See GitHub readme for deployment steps MD portal: https://github.com/DataLinkDC/dlink/blob/main/README.md
ps: note that you also need to add Hudi Flink bundle_ 2.12-0.10.0. The jar package is placed under dlink plugins.
The packages under plugins are shown in the following figure:
c. Access: http://ip:port/#/user/login Default user: admin Password: admin
d. Create cluster instance:
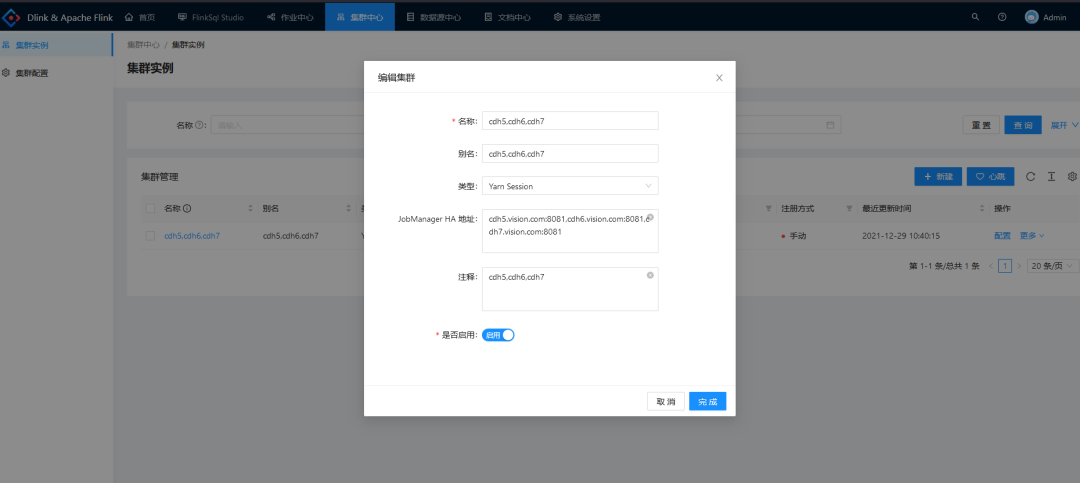
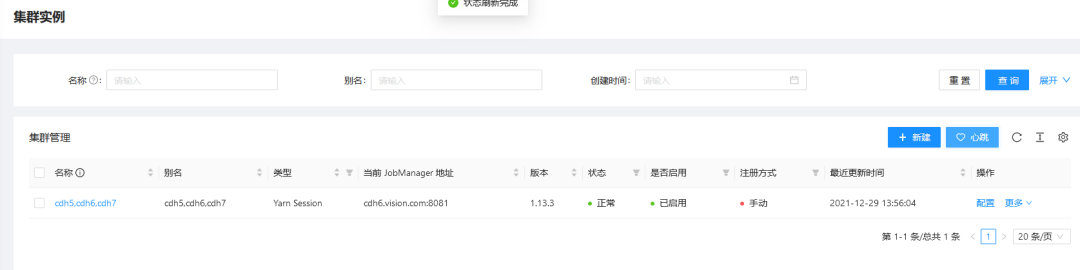
3, Data sheet
1. DDL preparation
(the following ddl is generated by Python program template. Please skip! O(∩ ∩) o)
------------- 'Order form' order_mysql_goods_order -----------------
CREATE TABLE source_order_mysql_goods_order (
`goods_order_id` bigint COMMENT 'Auto increment primary key id'
, `goods_order_uid` string COMMENT 'order uid'
, `customer_uid` string COMMENT 'customer uid'
, `customer_name` string COMMENT 'customer name'
, `student_uid` string COMMENT 'student uid'
, `order_status` bigint COMMENT 'Order status 1:Pending payment 2:Partial payment 3:Payment review 4:Paid 5:Cancelled'
, `is_end` bigint COMMENT 'Order closed 1.Open 2.Closed'
, `discount_deduction` bigint COMMENT 'Total preferential amount (unit: minute)'
, `contract_deduction` bigint COMMENT 'Deduction amount of old contract (unit: points)'
, `wallet_deduction` bigint COMMENT 'Wallet deduction amount (unit: minute)'
, `original_price` bigint COMMENT 'Original order price (unit: minute)'
, `real_price` bigint COMMENT 'Paid in amount (unit: minute)'
, `pay_success_time` timestamp(3) COMMENT 'Full payment time'
, `tags` string COMMENT 'Order label (1 new signing 2 renewal 3 expansion 4 Registration)-Hexin 5 shift-Hexin 6 renewal fee-Hexin 7 audition-Hexin)'
, `status` bigint COMMENT 'Valid (1).Effective 2.Failure 3.Overtime (unpaid)'
, `remark` string COMMENT 'Order remarks'
, `delete_flag` bigint COMMENT 'Delete (1).No, 2.(yes)'
, `test_flag` bigint COMMENT 'Test data (1).No, 2.(yes)'
, `create_time` timestamp(3) COMMENT 'Creation time'
, `update_time` timestamp(3) COMMENT 'Update time'
, `create_by` string COMMENT 'Founder uid((unique identification)'
, `update_by` string COMMENT 'Update person uid((unique identification)'
,PRIMARY KEY(goods_order_id) NOT ENFORCED
) COMMENT 'Order form'
WITH (
'connector' = 'mysql-cdc'
,'hostname' = 'rm-bp1t34384933232rds.aliyuncs.com'
,'port' = '3306'
,'username' = 'app_kfkdr'
,'password' = 'CV122fff0E40'
,'server-time-zone' = 'UTC'
,'scan.incremental.snapshot.enabled' = 'true'
,'debezium.snapshot.mode'='latest-offset' -- perhaps key yes scan.startup.mode,initial Indicates that you want historical data, latest-offset Indicates that historical data is not required
,'debezium.datetime.format.date'='yyyy-MM-dd'
,'debezium.datetime.format.time'='HH-mm-ss'
,'debezium.datetime.format.datetime'='yyyy-MM-dd HH-mm-ss'
,'debezium.datetime.format.timestamp'='yyyy-MM-dd HH-mm-ss'
,'debezium.datetime.format.timestamp.zone'='UTC+8'
,'database-name' = 'order'
,'table-name' = 'goods_order'
-- ,'server-id' = '2675788754-2675788754'
);
CREATE TABLE sink_order_mysql_goods_order(
`goods_order_id` bigint COMMENT 'Auto increment primary key id'
, `goods_order_uid` string COMMENT 'order uid'
, `customer_uid` string COMMENT 'customer uid'
, `customer_name` string COMMENT 'customer name'
, `student_uid` string COMMENT 'student uid'
, `order_status` bigint COMMENT 'Order status 1:Pending payment 2:Partial payment 3:Payment review 4:Paid 5:Cancelled'
, `is_end` bigint COMMENT 'Order closed 1.Open 2.Closed'
, `discount_deduction` bigint COMMENT 'Total preferential amount (unit: minute)'
, `contract_deduction` bigint COMMENT 'Deduction amount of old contract (unit: points)'
, `wallet_deduction` bigint COMMENT 'Wallet deduction amount (unit: minute)'
, `original_price` bigint COMMENT 'Original order price (unit: minute)'
, `real_price` bigint COMMENT 'Paid in amount (unit: minute)'
, `pay_success_time` timestamp(3) COMMENT 'Full payment time'
, `tags` string COMMENT 'Order label (1 new signing 2 renewal 3 expansion 4 Registration)-Hexin 5 shift-Hexin 6 renewal fee-Hexin 7 audition-Hexin)'
, `status` bigint COMMENT 'Valid (1).Effective 2.Failure 3.Overtime (unpaid)'
, `remark` string COMMENT 'Order remarks'
, `delete_flag` bigint COMMENT 'Delete (1).No, 2.(yes)'
, `test_flag` bigint COMMENT 'Test data (1).No, 2.(yes)'
, `create_time` timestamp(3) COMMENT 'Creation time'
, `update_time` timestamp(3) COMMENT 'Update time'
, `create_by` string COMMENT 'Founder uid((unique identification)'
, `update_by` string COMMENT 'Update person uid((unique identification)'
,PRIMARY KEY (goods_order_id) NOT ENFORCED
) COMMENT 'Order form'
WITH (
'connector' = 'hudi'
, 'path' = 'hdfs://cluster1/data/bizdata/cdc/mysql/order/goods_order '-- the path will be created automatically
, 'hoodie.datasource.write.recordkey.field' = 'goods_order_id' -- Primary key
, 'write.precombine.field' = 'update_time' -- When the key value is the same, the maximum value of this field is taken, and the default value is ts field
, 'read.streaming.skip_compaction' = 'true' -- Avoid repeated consumption
, 'write.bucket_assign.tasks' = '2' -- Concurrent write bucekt number
, 'write.tasks' = '2'
, 'compaction.tasks' = '1'
, 'write.operation' = 'upsert' -- UPSERT(Insert update)\INSERT((insert)\BULK_INSERT(Batch insert)( upsert The performance will be lower, which is not suitable for buried point reporting)
, 'write.rate.limit' = '20000' -- Limit how many entries per second
, 'table.type' = 'COPY_ON_WRITE' -- default COPY_ON_WRITE ,
, 'compaction.async.enabled' = 'true' -- Online compression
, 'compaction.trigger.strategy' = 'num_or_time' -- Compress by times
, 'compaction.delta_commits' = '20' -- The default is 5
, 'compaction.delta_seconds' = '60' -- The default is 1 hour
, 'hive_sync.enable' = 'true' -- Enable hive synchronization
, 'hive_sync.mode' = 'hms' -- Enable hive hms Sync, default jdbc
, 'hive_sync.metastore.uris' = 'thrift://cdh2. vision. COM: 9083 '-- required, the port of Metastore
, 'hive_sync.jdbc_url' = 'jdbc:hive2://cdh1. vision. COM: 10000 '-- required, hiveserver address
, 'hive_sync.table' = 'order_mysql_goods_order' -- required, hive The new table names are automatically synchronized hudi Table structure and data to hive
, 'hive_sync.db' = 'cdc_ods' -- required, hive New database name
, 'hive_sync.username' = 'hive' -- required, HMS user name
, 'hive_sync.password' = '123456' -- required, HMS password
, 'hive_sync.skip_ro_suffix' = 'true' -- remove ro suffix
);
---------- source_order_mysql_goods_order=== TO ==>> sink_order_mysql_goods_order ------------
insert into sink_order_mysql_goods_order select * from source_order_mysql_goods_order;4, Debug
1. Perform syntax verification on the above SQL
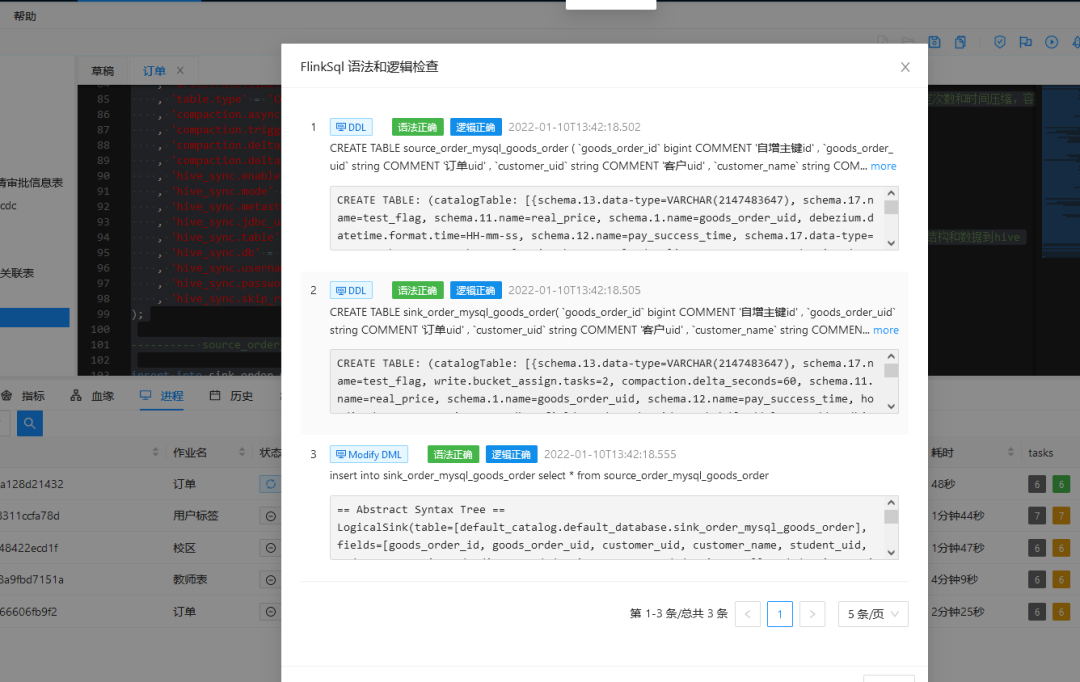
2. Get JobPlan
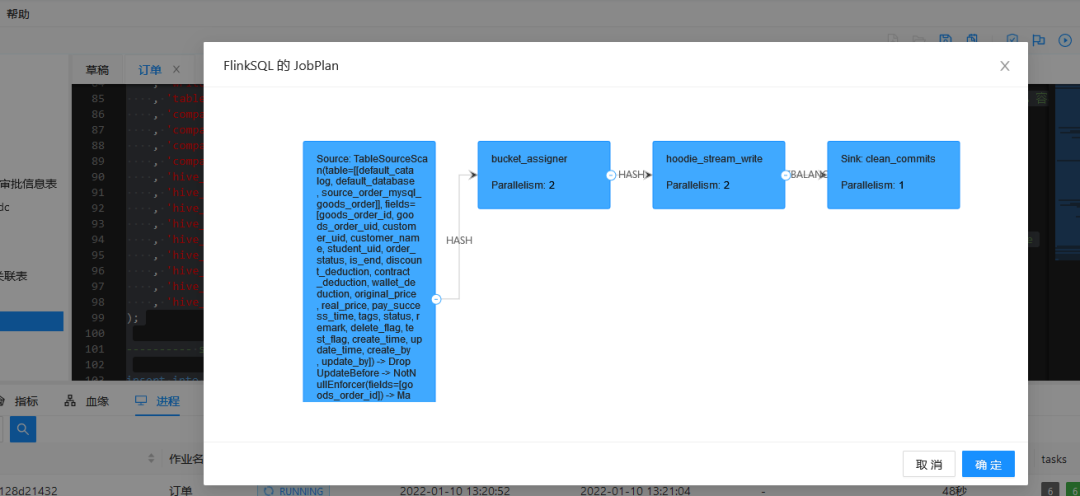
3. Perform tasks
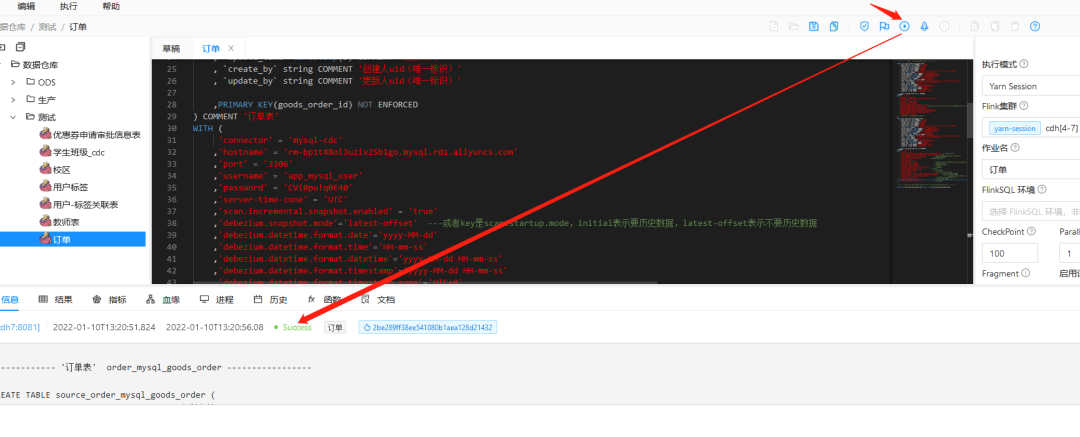
4. View task status
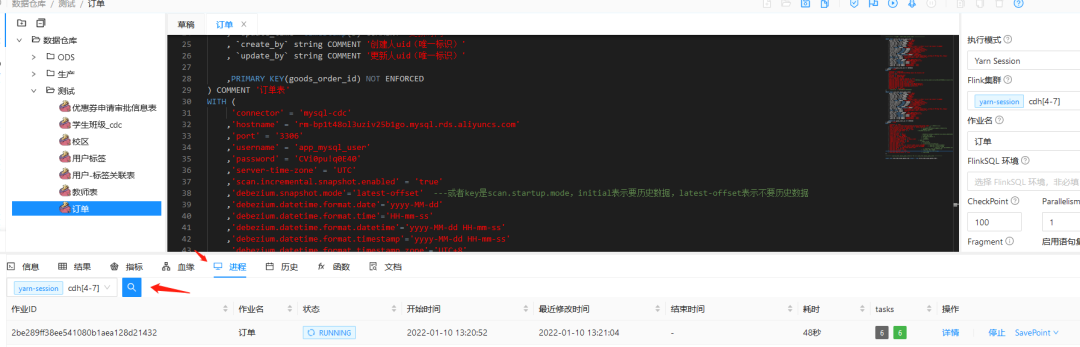
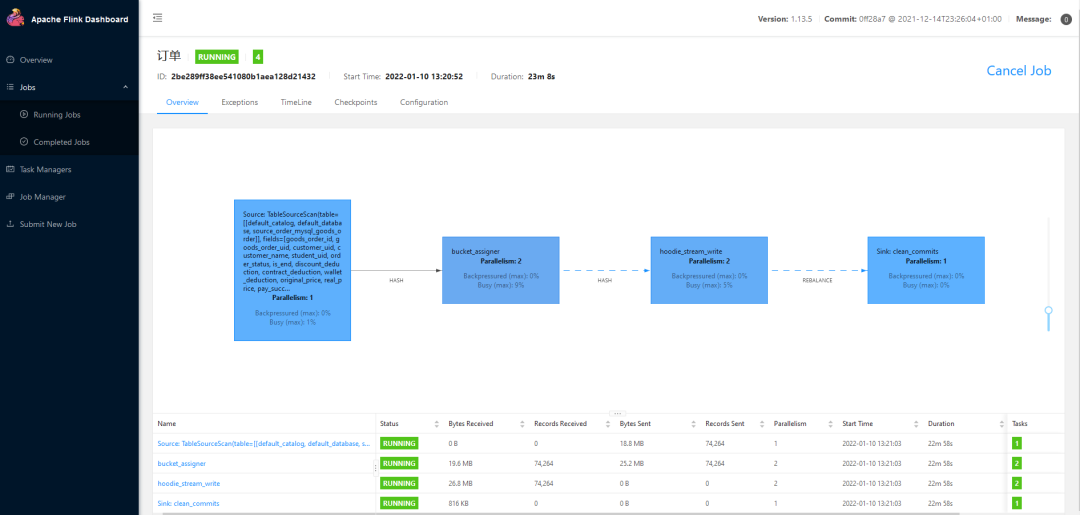
5. View job with Flink webui
6. View the data under the hdfs path

7. Check Hive table


8. Update data operation
UPDATE `order`.`goods_order` SET `remark` = 'cdc_test update' WHERE `goods_order_id` = 73270;
Check hive data again and find that it has been updated.

9. Delete data
(logical deletion is used in internal business instead of physical deletion. This example is only for demonstration / test. Use caution)
delete from `order`.`goods_order` where goods_order_id='73270';
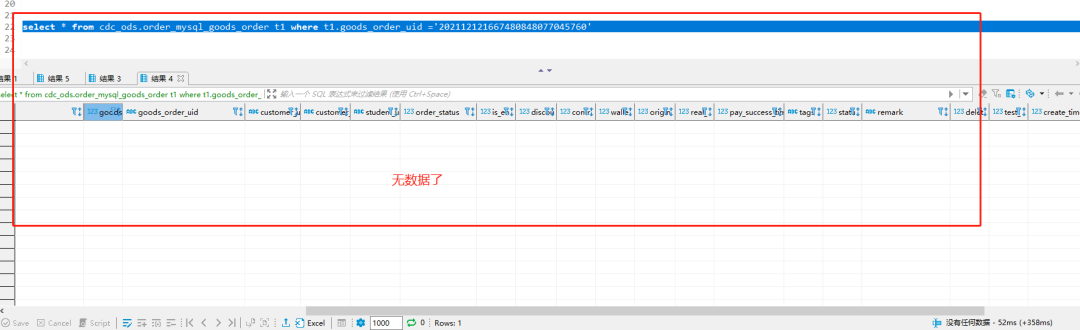
10. Insert this data here
INSERT INTO `order`.`goods_order`(`goods_order_id`, `goods_order_uid`, `customer_uid`, `customer_name`, `student_uid`, `order_status`, `is_end`, `discount_deduction`, `contract_deduction`, `wallet_deduction`, `original_price`, `real_price`, `pay_success_time`, `tags`, `status`, `remark`, `delete_flag`, `test_flag`, `create_time`, `update_time`, `create_by`, `update_by`) VALUES (73270, '202112121667480848077045760', 'VA100002435', 'weweweywu', 'S100002435', 4, 1, 2000000, 0, 0, 2000000, 0, '2021-12-12 18:51:41', '1', 1, '', 1, 1, '2021-12-12 18:51:41', '2022-01-10 13:53:59', 'VA100681', 'VA100681');
Query hive data again and enter normally.

So far, Dlink's Flink SQL CDC to Hudi Sync Hive test is over.
5, Conclusion
Dlink + Flink CDC + Hudi greatly reduces the cost of our streaming into the lake. Flink CDC simplifies the architecture and construction cost of traditional CDC, while Hudi's high-performance reading and writing is more conducive to the storage of frequently changing data. Finally, dlink makes the whole data development process sql platform, making our development, operation and maintenance more professional and comfortable, Look forward to the follow-up development of dlink.