DocRED is a large-scale, manual annotation and general domain text level relationship extraction data set released by thunlp in 2019. The data sources are wikipedia and wikidata. paper, code
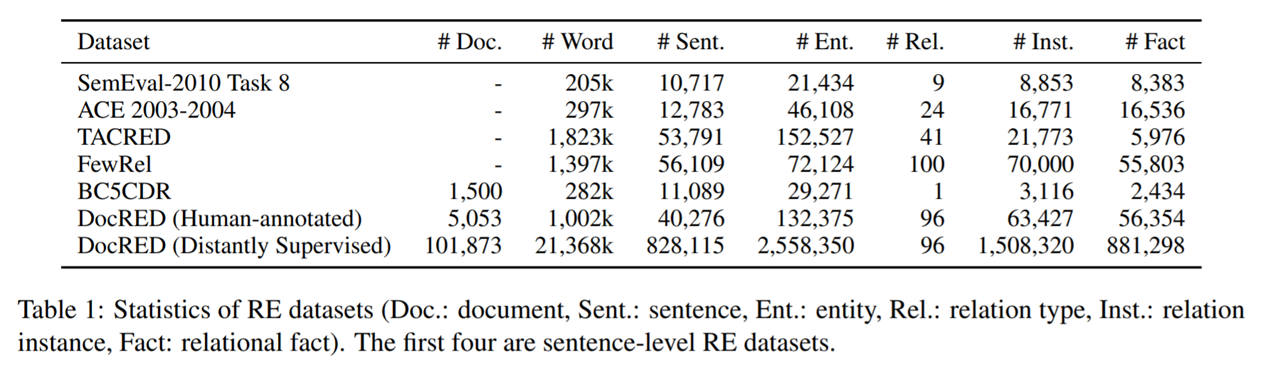
Dataset:
Manually annotated data: from 5053 Wikipedia documents, a total of 13w entities and 5w relationships
Remote monitoring data: from 101873 Wikipedia documents (10w +), a total of 255w entities and 88w relationships
1. Data processing flow:
Stage 1: Distantly Supervised Annotation Generation
For the introduction section of Wikipedia documents, spaCy is used as NER first, and then the entities are linked to wikidata (those with the same KB id are merged). query wikidata obtains the relationship between entities (it seems that the entities not available in wikidata are discarded, and all the entities and relationships obtained in the end are internal to wikidata)
p.s. discard chapters shorter than 128 words and less than 4 entities or relationships. A total of 107050 articles were obtained. 5053 articles with the highest frequency of 96 relationships were randomly selected for manual annotation.
Stage 2: Named Entity and Coreference Annotation
Manually proofread the entities of Stage 1 and perform co referential consolidation.
Stage 3: Entity Linking
Each named entity statement is mapped to a set of candidate wikidata item s (a variety of prediction methods are used here, such as name matching, TagMe recommendation, wikidata hyperlink, etc., to prevent the prediction from missing some relationships).
Stage 4: Relation and Supporting Evidence Collection
Firstly, based on the results of Stage 3, the RE model and remote monitoring prediction relationship are used, and then manually proofread and select the supporting evidence
We recommend 19.9 relation instances per document from entity linking, and 7.8 from RE models for supplement. Finally 57.2% relation instances from entity linking and 48.2% from RE models are reserved.
Stage 5: generate remote supervision data
Except those manually marked, the remaining documents are used as remote supervision data. In order to ensure the consistent distribution with the labeled data, use the labeled data finetune a BERT to predict NER. Link each entity mention to a wikidata item, merge with the same KB id, and then use remote supervision to predict the relationship.
2. Dataset file:
- rel_info.json
There are 96 kinds of relationship information stored. The storage format is: (key is wikidata ID, see the appendix for detailed explanation){"P6": "head of government", "P17": "country", "P19": "place of birth", "P20": "place of death", "P22": "father", "P25": "mother", "P26": "spouse", "P27": "country of citizenship", ...} - train_annotated.json manual annotation training set
(Manual marking (in data) at least 40.7%The data can only be inferred from multiple sentences: According to the statistics on our human-annotated corpus sampled from Wikipedia documents, at least 40.7% relational facts can only be extracted from multiple sentences, which is not negligible
- train_distant.json remote supervision training set
- dev.json validation set
- test.json test set
3. Data format:
Data Format:
{
'title',
'sents': [
[word in sent 0],
[word in sent 1]
]
'vertexSet': [
[
{ 'name': mention_name,
'sent_id': mention in which sentence,
'pos': postion of mention in a sentence,
'type': NER_type}
{anthor mention}
],
[anthoer entity]
]
'labels': [
{
'h': idx of head entity in vertexSet,
't': idx of tail entity in vertexSet,
'r': relation,
'evidence': evidence sentences' id
}
]
}
4. Data analysis
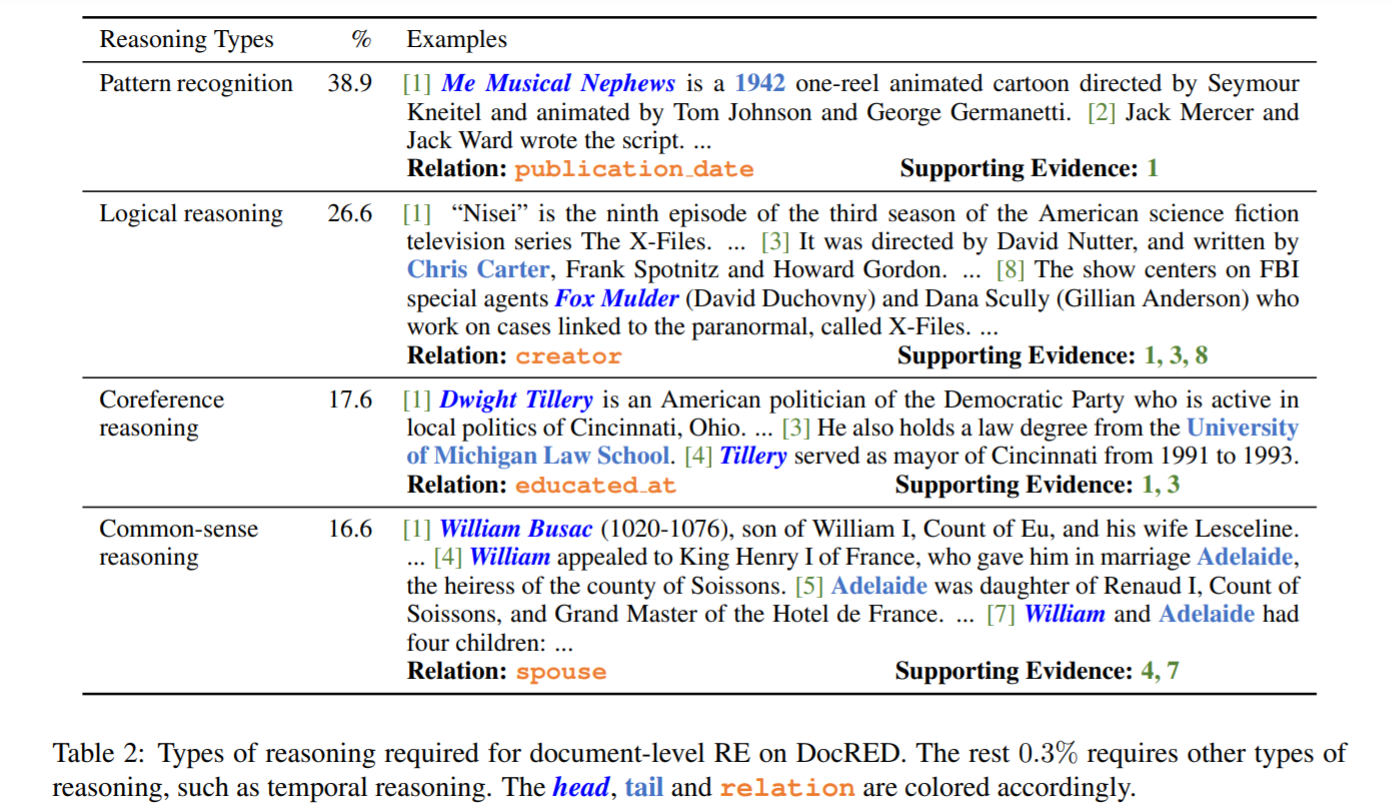
Relationship types: pure template matching, logical reasoning (multi hop), common reference, common sense reasoning
5. baseline used
CNN, LSTM, BiLSTM, Context-aware Attention