Author: Wen naisong
When using Flink to consume Kafka data in real time, it involves the maintenance of offset status. In order to ensure the restart of Flink job or the failure retry of Operator level during running, if you want to achieve "breakpoint continuation", you need the support of Flink Checkpoint. The question is, if you simply turn on Flink's Checkpoint mechanism without additional coding, can you achieve the goal? To answer this question, this paper first studies the Checkpoint processing mechanism of Flink, and then looks at whether Flink supports Kafka state storage. Therefore, this paper is divided into the following four parts:
- Main process of flick checkpoint state snapshot
- The main process of Flink Checkpoint initializeState
- Implementation of flick checkpoint by Kafka Source Operator
- Kafka Source Operator state recovery
For the sake of accurate description, Flink 1.12 X version, Kafka client version 2.4 X as an example.
Main process of flick checkpoint state snapshot
We know that flick checkpoint is periodically initiated by the checkpoint coordinator. It completes the checkpoint by sending trigger messages to related tasks and collecting confirmation messages (acks) from each Task. Omitting the logic analysis initiated by the checkpoint coordinator, go straight to the message acceptor TaskExecutor to see the checkpoint execution process, obtain the Task instance in the TaskExecutor, and trigger the trigger checkpoint barrier:
TaskExecutor.class
@Override
public CompletableFuture<Acknowledge> triggerCheckpoint(
ExecutionAttemptID executionAttemptID,
long checkpointId,
long checkpointTimestamp,
CheckpointOptions checkpointOptions) {
...
final Task task = taskSlotTable.getTask(executionAttemptID);
if (task != null) {
task.triggerCheckpointBarrier(checkpointId, checkpointTimestamp, checkpointOptions);
return CompletableFuture.completedFuture(Acknowledge.get());
...
}
}A Task is a scheduling execution unit in the TaskExecutor, which also responds to Checkpoint requests:
Task.class
public void triggerCheckpointBarrier(
final long checkpointID,
final long checkpointTimestamp,
final CheckpointOptions checkpointOptions) {
...
final CheckpointMetaData checkpointMetaData =
new CheckpointMetaData(checkpointID, checkpointTimestamp);
invokable.triggerCheckpointAsync(checkpointMetaData, checkpointOptions);
...
}The highlight is invokable, which is an object of AbstractInvokable type. It is dynamically instantiated according to the calling class:
// now load and instantiate the task's invokable code
AbstractInvokable invokable =
loadAndInstantiateInvokable(
userCodeClassLoader.asClassLoader(), nameOfInvokableClass, env);The nameOfInvokableClass parameter is passed in during Task initialization to dynamically create an AbstractInvokable instance. For example, take a SourceOperator as an example, and its class name is:
org.apache.flink.streaming.runtime.tasks.SourceOperatorStreamTask
From the definition of SourceOperatorStreamTask class, it is a subclass of StreamTask:
class SourceOperatorStreamTask<T> extends StreamTask<T, SourceOperator<T, ?>>
The triggerCheckpointAsync method calls the triggerCheckpointAsync methods of SourceOperatorStreamTask and StreamTask classes successively. The main logic is in the triggerCheckpointAsync method of StreamTask:
StreamTask.class
@Override
public Future<Boolean> triggerCheckpointAsync(
CheckpointMetaData checkpointMetaData, CheckpointOptions checkpointOptions) {
...
triggerCheckpoint(checkpointMetaData, checkpointOptions)
...
}
private boolean triggerCheckpoint(
CheckpointMetaData checkpointMetaData, CheckpointOptions checkpointOptions)
throws Exception {
// No alignment if we inject a checkpoint
CheckpointMetricsBuilder checkpointMetrics =
new CheckpointMetricsBuilder()
.setAlignmentDurationNanos(0L)
.setBytesProcessedDuringAlignment(0L);
...
boolean success =
performCheckpoint(checkpointMetaData, checkpointOptions, checkpointMetrics);
if (!success) {
declineCheckpoint(checkpointMetaData.getCheckpointId());
}
return success;
}
private boolean performCheckpoint(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
CheckpointMetricsBuilder checkpointMetrics)
throws Exception {
...
subtaskCheckpointCoordinator.checkpointState(
checkpointMetaData,
checkpointOptions,
checkpointMetrics,
operatorChain,
this::isRunning);
...
}subtaskCheckpointCoordinator is an instance of SubtaskCheckpointCoordinatorImpl type, which is responsible for coordinating checkpoint work related to subtasks:
/**
* Coordinates checkpointing-related work for a subtask (i.e. {@link
* org.apache.flink.runtime.taskmanager.Task Task} and {@link StreamTask}). Responsibilities:
*
* <ol>
* <li>build a snapshot (invokable)
* <li>report snapshot to the JobManager
* <li>action upon checkpoint notification
* <li>maintain storage locations
* </ol>
*/
@Internal
public interface SubtaskCheckpointCoordinator extends CloseableThe following is the main logic of the checkpoint state in the subtaskcheckbpointcoordinatorimpl implementation class:
SubtaskCheckpointCoordinatorImpl.class
@Override
public void checkpointState(
CheckpointMetaData metadata,
CheckpointOptions options,
CheckpointMetricsBuilder metrics,
OperatorChain<?, ?> operatorChain,
Supplier<Boolean> isRunning)
throws Exception {
// All of the following steps happen as an atomic step from the perspective of barriers and
// records/watermarks/timers/callbacks.
// We generally try to emit the checkpoint barrier as soon as possible to not affect
// downstream
// checkpoint alignments
if (lastCheckpointId >= metadata.getCheckpointId()) {
LOG.info(
"Out of order checkpoint barrier (aborted previously?): {} >= {}",
lastCheckpointId,
metadata.getCheckpointId());
channelStateWriter.abort(metadata.getCheckpointId(), new CancellationException(), true);
checkAndClearAbortedStatus(metadata.getCheckpointId());
return;
}
lastCheckpointId = metadata.getCheckpointId();
if (checkAndClearAbortedStatus(metadata.getCheckpointId())) {
// broadcast cancel checkpoint marker to avoid downstream back-pressure due to
// checkpoint barrier align.
operatorChain.broadcastEvent(new CancelCheckpointMarker(metadata.getCheckpointId()));
return;
}
// Step (1): Prepare the checkpoint, allow operators to do some pre-barrier work.
// The pre-barrier work should be nothing or minimal in the common case.
operatorChain.prepareSnapshotPreBarrier(metadata.getCheckpointId());
// Step (2): Send the checkpoint barrier downstream
operatorChain.broadcastEvent(
new CheckpointBarrier(metadata.getCheckpointId(), metadata.getTimestamp(), options),
options.isUnalignedCheckpoint());
// Step (3): Prepare to spill the in-flight buffers for input and output
if (options.isUnalignedCheckpoint()) {
// output data already written while broadcasting event
channelStateWriter.finishOutput(metadata.getCheckpointId());
}
// Step (4): Take the state snapshot. This should be largely asynchronous, to not impact
// progress of the
// streaming topology
Map<OperatorID, OperatorSnapshotFutures> snapshotFutures =
new HashMap<>(operatorChain.getNumberOfOperators());
if (takeSnapshotSync(snapshotFutures, metadata, metrics, options, operatorChain, isRunning)) {
finishAndReportAsync(snapshotFutures, metadata, metrics, isRunning);
} else {
cleanup(snapshotFutures, metadata, metrics, new Exception("Checkpoint declined"));
}
}See prepareSnapshotPreBarrier in Step (1). Some lightweight preparations have been made before the formal snapshot. The specific operation is implemented in the OperatorChain. Call the prepareSnapshotPreBarrier method of each StreamOperator in the chain in turn:
OperatorChain.class
public void prepareSnapshotPreBarrier(long checkpointId) throws Exception {
// go forward through the operator chain and tell each operator
// to prepare the checkpoint
for (StreamOperatorWrapper<?, ?> operatorWrapper : getAllOperators()) {
if (!operatorWrapper.isClosed()) {
operatorWrapper.getStreamOperator().prepareSnapshotPreBarrier(checkpointId);
}
}
}After a series of snapshot check and verification, pre snapshot preparation, and event broadcast operations to the downstream, it finally settled in the checkpoint streamoperator method of this class:
SubtaskCheckpointCoordinatorImpl.class
private static OperatorSnapshotFutures checkpointStreamOperator(
StreamOperator<?> op,
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
CheckpointStreamFactory storageLocation,
Supplier<Boolean> isRunning)
throws Exception {
try {
return op.snapshotState(
checkpointMetaData.getCheckpointId(),
checkpointMetaData.getTimestamp(),
checkpointOptions,
storageLocation);
} catch (Exception ex) {
if (isRunning.get()) {
LOG.info(ex.getMessage(), ex);
}
throw ex;
}
}This method also calls the snapshotState of AbstractStreamOperator:
AbstractStreamOperator.class
@Override
public final OperatorSnapshotFutures snapshotState(
long checkpointId,
long timestamp,
CheckpointOptions checkpointOptions,
CheckpointStreamFactory factory)
throws Exception {
return stateHandler.snapshotState(
this,
Optional.ofNullable(timeServiceManager),
getOperatorName(),
checkpointId,
timestamp,
checkpointOptions,
factory,
isUsingCustomRawKeyedState());
}The snapshot state in turn delegates the checkpoint logic to the StreamOperatorStateHandler. The logic of StreamOperatorStateHandler is described below. Sort out the above snapshot logic flow, and the visualization is as follows:
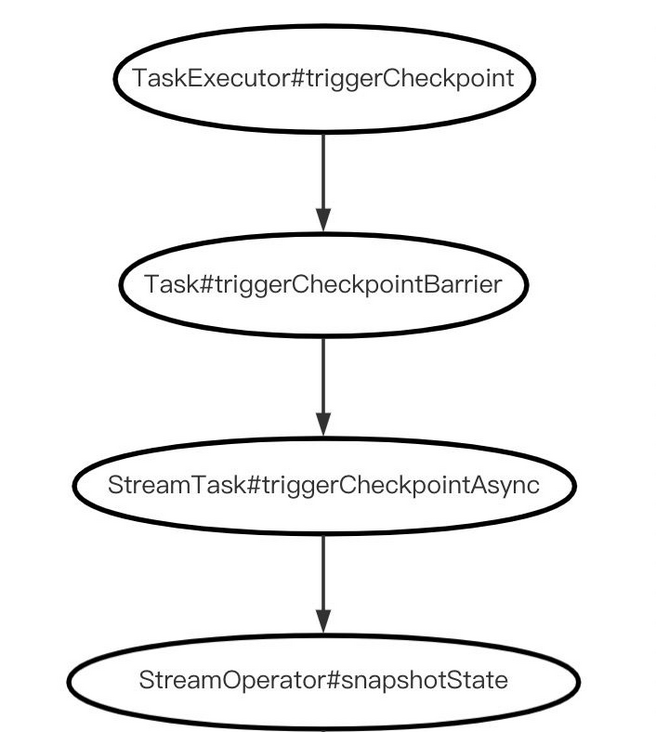
The main process of Flink Checkpoint initializeState
The Task initialization mentioned above will call the invoke method of AbstractInvokable,
// now load and instantiate the task's invokable code
AbstractInvokable invokable =
loadAndInstantiateInvokable(
userCodeClassLoader.asClassLoader(), nameOfInvokableClass, env);
// run the invokable
invokable.invoke();Invoke the invoke method in its parent class StreamTask completes the Template policy actions before calling, running the event loop and after calling:
StreamTask.class
@Override
public final void invoke() throws Exception {
beforeInvoke();
// final check to exit early before starting to run
if (canceled) {
throw new CancelTaskException();
}
// let the task do its work
runMailboxLoop();
// if this left the run() method cleanly despite the fact that this was canceled,
// make sure the "clean shutdown" is not attempted
if (canceled) {
throw new CancelTaskException();
}
afterInvoke();
}In the beforeInvoke method, initialize the state through the initializeStateAndOpenOperators of the operatorChain:
StreamTask.class
protected void beforeInvoke() throws Exception {
operatorChain = new OperatorChain<>(this, recordWriter);
...
operatorChain.initializeStateAndOpenOperators(
createStreamTaskStateInitializer());
...
}Trigger all streamoperators in the current chain in the operatorChain:
OperatorChain.class
protected void initializeStateAndOpenOperators(
StreamTaskStateInitializer streamTaskStateInitializer) throws Exception {
for (StreamOperatorWrapper<?, ?> operatorWrapper : getAllOperators(true)) {
StreamOperator<?> operator = operatorWrapper.getStreamOperator();
operator.initializeState(streamTaskStateInitializer);
operator.open();
}
}Continue to follow up with AbstractStreamOperator calling initializeState:
AbstractStreamOperator.class
@Override
public final void initializeState(StreamTaskStateInitializer streamTaskStateManager)
throws Exception {
final StreamOperatorStateContext context =
streamTaskStateManager.streamOperatorStateContext(
getOperatorID(),
getClass().getSimpleName(),
getProcessingTimeService(),
this,
keySerializer,
streamTaskCloseableRegistry,
metrics,
config.getManagedMemoryFractionOperatorUseCaseOfSlot(
ManagedMemoryUseCase.STATE_BACKEND,
runtimeContext.getTaskManagerRuntimeInfo().getConfiguration(),
runtimeContext.getUserCodeClassLoader()),
isUsingCustomRawKeyedState());
stateHandler =
new StreamOperatorStateHandler(
context, getExecutionConfig(), streamTaskCloseableRegistry);
timeServiceManager = context.internalTimerServiceManager();
stateHandler.initializeOperatorState(this);
}Where statehandler initializeOperatorState delegates initializeOperatorState to the StreamOperatorStateHandler class, where the state initialization of specific StreamOperator subclasses is completed. Sort out the logic of initialization status, which is visualized as follows:
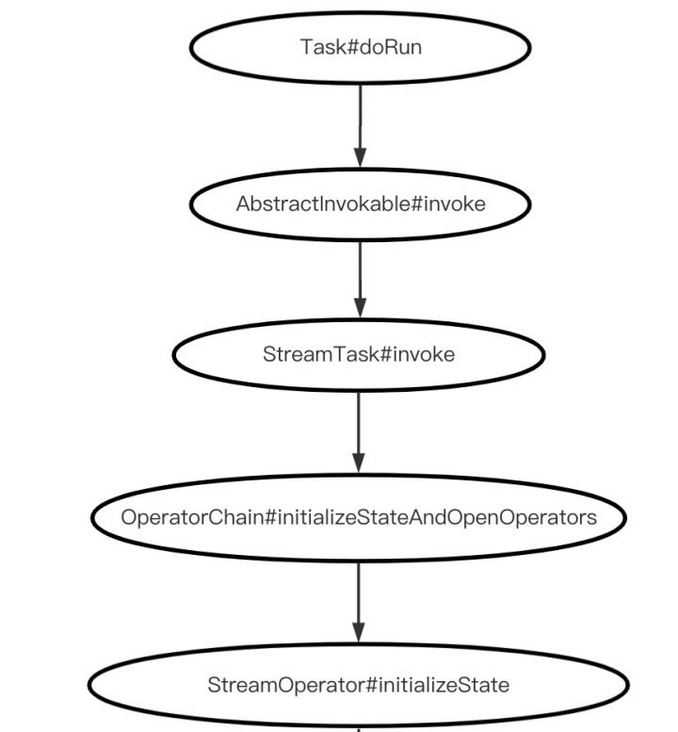
Kafka Source Operator support for flick checkpoint
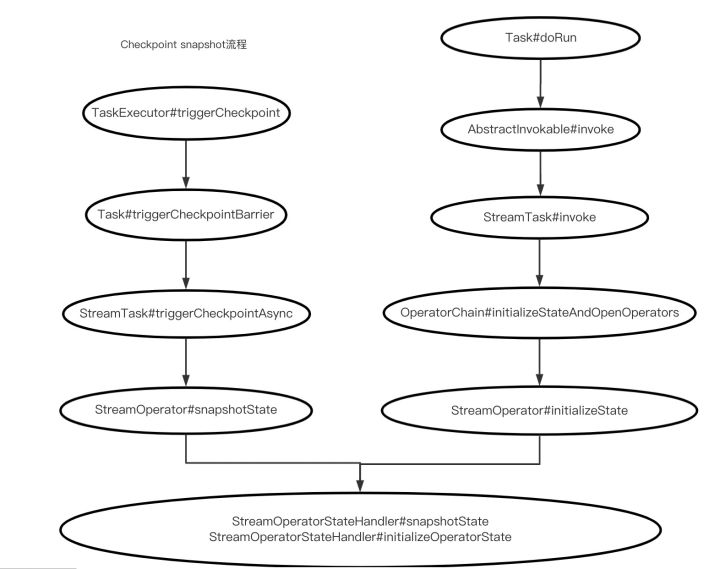
Now draw the state snapshot process and state initialization process of Checkpoint together, and you will see that both are summarized and delegated to StreamOperatorStateHandler for execution:
The initializeoperationstate and snapshotState methods in the StreamOperatorStateHandler class are implemented as follows. They mainly complete the construction of parameters:
StreamOperatorStateHandler.class
public void initializeOperatorState(CheckpointedStreamOperator streamOperator)
throws Exception {
CloseableIterable<KeyGroupStatePartitionStreamProvider> keyedStateInputs =
context.rawKeyedStateInputs();
CloseableIterable<StatePartitionStreamProvider> operatorStateInputs =
context.rawOperatorStateInputs();
StateInitializationContext initializationContext =
new StateInitializationContextImpl(
context.isRestored(), // information whether we restore or start for
// the first time
operatorStateBackend, // access to operator state backend
keyedStateStore, // access to keyed state backend
keyedStateInputs, // access to keyed state stream
operatorStateInputs); // access to operator state stream
streamOperator.initializeState(initializationContext);
}
public OperatorSnapshotFutures snapshotState(
CheckpointedStreamOperator streamOperator,
Optional<InternalTimeServiceManager<?>> timeServiceManager,
String operatorName,
long checkpointId,
long timestamp,
CheckpointOptions checkpointOptions,
CheckpointStreamFactory factory,
boolean isUsingCustomRawKeyedState)
throws CheckpointException {
KeyGroupRange keyGroupRange =
null != keyedStateBackend
? keyedStateBackend.getKeyGroupRange()
: KeyGroupRange.EMPTY_KEY_GROUP_RANGE;
OperatorSnapshotFutures snapshotInProgress = new OperatorSnapshotFutures();
StateSnapshotContextSynchronousImpl snapshotContext =
new StateSnapshotContextSynchronousImpl(
checkpointId, timestamp, factory, keyGroupRange, closeableRegistry);
snapshotState(
streamOperator,
timeServiceManager,
operatorName,
checkpointId,
timestamp,
checkpointOptions,
factory,
snapshotInProgress,
snapshotContext,
isUsingCustomRawKeyedState);
return snapshotInProgress;
}
void snapshotState(
CheckpointedStreamOperator streamOperator,
Optional<InternalTimeServiceManager<?>> timeServiceManager,
String operatorName,
long checkpointId,
long timestamp,
CheckpointOptions checkpointOptions,
CheckpointStreamFactory factory,
OperatorSnapshotFutures snapshotInProgress,
StateSnapshotContextSynchronousImpl snapshotContext,
boolean isUsingCustomRawKeyedState)
throws CheckpointException {
if (timeServiceManager.isPresent()) {
checkState(
keyedStateBackend != null,
"keyedStateBackend should be available with timeServiceManager");
final InternalTimeServiceManager<?> manager = timeServiceManager.get();
if (manager.isUsingLegacyRawKeyedStateSnapshots()) {
checkState(
!isUsingCustomRawKeyedState,
"Attempting to snapshot timers to raw keyed state, but this operator has custom raw keyed state to write.");
manager.snapshotToRawKeyedState(
snapshotContext.getRawKeyedOperatorStateOutput(), operatorName);
}
}
streamOperator.snapshotState(snapshotContext);
snapshotInProgress.setKeyedStateRawFuture(snapshotContext.getKeyedStateStreamFuture());
snapshotInProgress.setOperatorStateRawFuture(
snapshotContext.getOperatorStateStreamFuture());
if (null != operatorStateBackend) {
snapshotInProgress.setOperatorStateManagedFuture(
operatorStateBackend.snapshot(
checkpointId, timestamp, factory, checkpointOptions));
}
if (null != keyedStateBackend) {
snapshotInProgress.setKeyedStateManagedFuture(
keyedStateBackend.snapshot(
checkpointId, timestamp, factory, checkpointOptions));
}
}It is worth mentioning that the StreamOperator parameter in the two methods requires the type of CheckpointedStreamOperator:
public interface CheckpointedStreamOperator {
void initializeState(StateInitializationContext context) throws Exception;
void snapshotState(StateSnapshotContext context) throws Exception;
}Compare the following three methods of StreamOperator related to Checkpoint, which are defined as follows:
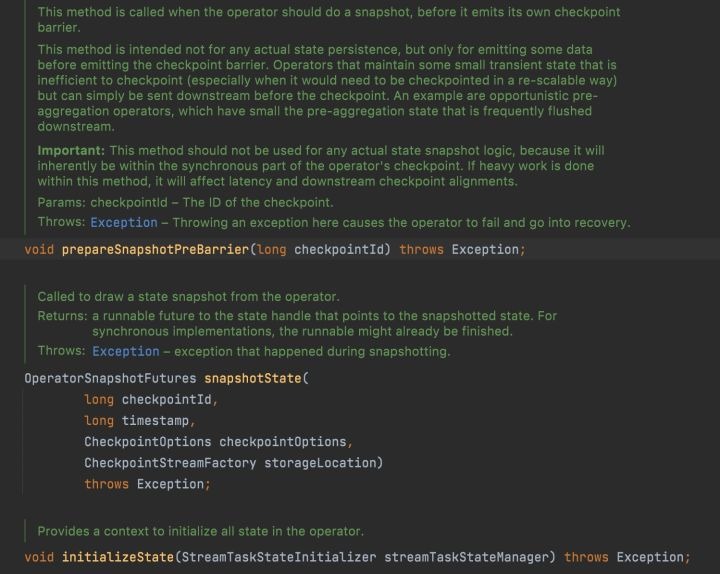
Although the method names are the same and the parameters are different, you don't have to worry about these. You only need to know that the StreamOperator delegates the snapshot related logic to the StreamOperator statehandler, and the real snapshot logic is completed in the CheckpointedStreamOperator. Therefore, to realize the self-defined snapshot logic, you only need to implement the checkpoint edstreamoperato interface, taking the SourceOperator as an example, Class definition:
public class SourceOperator<OUT, SplitT extends SourceSplit> extends AbstractStreamOperator<OUT>
implements OperatorEventHandler, PushingAsyncDataInput<OUT>The class definition of AbstractStreamOperator is:
public abstract class AbstractStreamOperator<OUT>
implements StreamOperator<OUT>,
SetupableStreamOperator<OUT>,
CheckpointedStreamOperator,
SerializableAbstractStreamOperator has helped us implement relevant methods. We only need extend AbstractStreamOperator. We still take SourceOperator as an example to see its implementation:
SourceOperator.class
private ListState<SplitT> readerState;
@Override
public void initializeState(StateInitializationContext context) throws Exception {
super.initializeState(context);
final ListState<byte[]> rawState =
context.getOperatorStateStore().getListState(SPLITS_STATE_DESC);
readerState = new SimpleVersionedListState<>(rawState, splitSerializer);
}
@Override
public void snapshotState(StateSnapshotContext context) throws Exception {
long checkpointId = context.getCheckpointId();
LOG.debug("Taking a snapshot for checkpoint {}", checkpointId);
readerState.update(sourceReader.snapshotState(checkpointId));
}It can be seen that the SourceOperator stores the snapshot state in the SimpleVersionedListState in memory, and the specific operation of the snapshot state is transferred to the SourceReader. See how the KafkaSourceReader provided by Flink Kafka Connector implements the snapshot state:
KafkaSourceReader.class
KafkaSourceReader extends SourceReaderBase implements SourceReader
@Override
public List<KafkaPartitionSplit> snapshotState(long checkpointId) {
List<KafkaPartitionSplit> splits = super.snapshotState(checkpointId);
if (splits.isEmpty() && offsetsOfFinishedSplits.isEmpty()) {
offsetsToCommit.put(checkpointId, Collections.emptyMap());
} else {
Map<TopicPartition, OffsetAndMetadata> offsetsMap =
offsetsToCommit.computeIfAbsent(checkpointId, id -> new HashMap<>());
// Put the offsets of the active splits.
for (KafkaPartitionSplit split : splits) {
// If the checkpoint is triggered before the partition starting offsets
// is retrieved, do not commit the offsets for those partitions.
if (split.getStartingOffset() >= 0) {
offsetsMap.put(
split.getTopicPartition(),
new OffsetAndMetadata(split.getStartingOffset()));
}
}
// Put offsets of all the finished splits.
offsetsMap.putAll(offsetsOfFinishedSplits);
}
return splits;
}The above is memory based state storage, and persistence also needs the support of external systems. Continue to explore the snapshot method logic of StreamOperatorStateHandler, including the following paragraph:
if (null != operatorStateBackend) {
snapshotInProgress.setOperatorStateManagedFuture(
operatorStateBackend.snapshot(
checkpointId, timestamp, factory, checkpointOptions));
}Only when the persistent backend storage is configured can the state data be persisted. Take the default OperatorStateBackend as an example:
DefaultOperatorStateBackend.class
@Override
public RunnableFuture<SnapshotResult<OperatorStateHandle>> snapshot(
long checkpointId,
long timestamp,
@Nonnull CheckpointStreamFactory streamFactory,
@Nonnull CheckpointOptions checkpointOptions)
throws Exception {
long syncStartTime = System.currentTimeMillis();
RunnableFuture<SnapshotResult<OperatorStateHandle>> snapshotRunner =
snapshotStrategy.snapshot(
checkpointId, timestamp, streamFactory, checkpointOptions);
return snapshotRunner;
}snapshotStrategy. The snapshot execution logic is implemented in the defaultoperatorstatebackendsnapshot strategy:
DefaultOperatorStateBackendSnapshotStrategy.class
@Override
public RunnableFuture<SnapshotResult<OperatorStateHandle>> snapshot(
final long checkpointId,
final long timestamp,
@Nonnull final CheckpointStreamFactory streamFactory,
@Nonnull final CheckpointOptions checkpointOptions)
throws IOException {
...
for (Map.Entry<String, PartitionableListState<?>> entry :
registeredOperatorStatesDeepCopies.entrySet()) {
operatorMetaInfoSnapshots.add(
entry.getValue().getStateMetaInfo().snapshot());
}
...
// ... write them all in the checkpoint stream ...
DataOutputView dov = new DataOutputViewStreamWrapper(localOut);
OperatorBackendSerializationProxy backendSerializationProxy =
new OperatorBackendSerializationProxy(
operatorMetaInfoSnapshots, broadcastMetaInfoSnapshots);
backendSerializationProxy.write(dov);
...
for (Map.Entry<String, PartitionableListState<?>> entry :
registeredOperatorStatesDeepCopies.entrySet()) {
PartitionableListState<?> value = entry.getValue();
long[] partitionOffsets = value.write(localOut);
}
}The status data includes metadata information and the data of the status itself. The status data is written to the file system through the write method of PartitionableListState:
PartitionableListState.class
public long[] write(FSDataOutputStream out) throws IOException {
long[] partitionOffsets = new long[internalList.size()];
DataOutputView dov = new DataOutputViewStreamWrapper(out);
for (int i = 0; i < internalList.size(); ++i) {
S element = internalList.get(i);
partitionOffsets[i] = out.getPos();
getStateMetaInfo().getPartitionStateSerializer().serialize(element, dov);
}
return partitionOffsets;
}Kafka Source Operator state recovery
The above part introduces Kafka Source Operator's support for flick checkpoint, which also involves snapshot and initialState, but mainly introduces the logic of snapshot. Let's see how SourceOperator initializes the state:
SourceOperator.class
@Override
public void initializeState(StateInitializationContext context) throws Exception {
super.initializeState(context);
final ListState<byte[]> rawState =
context.getOperatorStateStore().getListState(SPLITS_STATE_DESC);
readerState = new SimpleVersionedListState<>(rawState, splitSerializer);
}context.getOperatorStateStore uses the getListState method of DefaultOperatorStateBackend:
DefaultOperatorStateBackend.class
private final Map<String, PartitionableListState<?>> registeredOperatorStates;
@Override
public <S> ListState<S> getListState(ListStateDescriptor<S> stateDescriptor) throws Exception {
return getListState(stateDescriptor, OperatorStateHandle.Mode.SPLIT_DISTRIBUTE);
}
private <S> ListState<S> getListState(
ListStateDescriptor<S> stateDescriptor, OperatorStateHandle.Mode mode)
throws StateMigrationException {
...
PartitionableListState<S> partitionableListState =
(PartitionableListState<S>) registeredOperatorStates.get(name);
...
return partitionableListState;
}The getListState is only obtained from the map > called registeredoperationstates. The question is, where does registeredoperationstates come from? In order to find the answer, this part uses a Kafka consumption example to demonstrate and explain. First, create a KafkaSource:
KafkaSource<MetaAndValue> kafkaSource =
KafkaSource.<ObjectNode>builder()
.setBootstrapServers(Constants.kafkaServers)
.setGroupId(KafkaSinkIcebergExample.class.getName())
.setTopics(topic)
.setDeserializer(recordDeserializer)
.setStartingOffsets(OffsetsInitializer.earliest())
.setBounded(OffsetsInitializer.latest())
.setProperties(properties)
.build();And set the restart policy: restart once immediately after the StreamOperator fails. Good snapshot interval: once every 100ms:
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(1, Time.seconds(0))); env.getCheckpointConfig().setCheckpointInterval(1 * 100L);
Then, in the case of Kafka inverse sequence, set to parse 100 records and throw an exception:
public static class TestingKafkaRecordDeserializer
implements KafkaRecordDeserializer<MetaAndValue> {
private static final long serialVersionUID = -3765473065594331694L;
private transient Deserializer<String> deserializer = new StringDeserializer();
int parseNum=0;
@Override
public void deserialize(
ConsumerRecord<byte[], byte[]> record, Collector<MetaAndValue> collector) {
if (deserializer == null)
deserializer = new StringDeserializer();
MetaAndValue metaAndValue=new MetaAndValue(
new TopicPartition(record.topic(), record.partition()),
deserializer.deserialize(record.topic(), record.value()), record.offset());
if(parseNum++>100) {
Map<String,Object> metaData=metaAndValue.getMetaData();
throw new RuntimeException("for test");
}
collector.collect(metaAndValue);
}
}When the JobMaster initializes and creates the Scheduler, it initializes the status from the Checkpoint. If the initialization from the Checkpoint fails, it attempts to recover from the Savepoint.
SchedulerBase.class
private ExecutionGraph createAndRestoreExecutionGraph(
JobManagerJobMetricGroup currentJobManagerJobMetricGroup,
ShuffleMaster<?> shuffleMaster,
JobMasterPartitionTracker partitionTracker,
ExecutionDeploymentTracker executionDeploymentTracker,
long initializationTimestamp)
throws Exception {
ExecutionGraph newExecutionGraph =
createExecutionGraph(
currentJobManagerJobMetricGroup,
shuffleMaster,
partitionTracker,
executionDeploymentTracker,
initializationTimestamp);
final CheckpointCoordinator checkpointCoordinator =
newExecutionGraph.getCheckpointCoordinator();
if (checkpointCoordinator != null) {
// check whether we find a valid checkpoint
if (!checkpointCoordinator.restoreInitialCheckpointIfPresent(
new HashSet<>(newExecutionGraph.getAllVertices().values()))) {
// check whether we can restore from a savepoint
tryRestoreExecutionGraphFromSavepoint(
newExecutionGraph, jobGraph.getSavepointRestoreSettings());
}
}
return newExecutionGraph;
}Finally, go back to the familiar Checkpoint coordinator and load the latest snapshot state from the Checkpoint directory in its method restoreLatestCheckpointedStateInternal:
CheckpointCoordinator.class
public boolean restoreInitialCheckpointIfPresent(final Set<ExecutionJobVertex> tasks)
throws Exception {
final OptionalLong restoredCheckpointId =
restoreLatestCheckpointedStateInternal(
tasks,
OperatorCoordinatorRestoreBehavior.RESTORE_IF_CHECKPOINT_PRESENT,
false, // initial checkpoints exist only on JobManager failover. ok if not
// present.
false); // JobManager failover means JobGraphs match exactly.
return restoredCheckpointId.isPresent();
}
private OptionalLong restoreLatestCheckpointedStateInternal(
final Set<ExecutionJobVertex> tasks,
final OperatorCoordinatorRestoreBehavior operatorCoordinatorRestoreBehavior,
final boolean errorIfNoCheckpoint,
final boolean allowNonRestoredState)
throws Exception {
...
// Recover the checkpoints, TODO this could be done only when there is a new leader, not
// on each recovery
completedCheckpointStore.recover();
// Restore from the latest checkpoint
CompletedCheckpoint latest =
completedCheckpointStore.getLatestCheckpoint(isPreferCheckpointForRecovery);
...
// re-assign the task states
final Map<OperatorID, OperatorState> operatorStates = latest.getOperatorStates();
StateAssignmentOperation stateAssignmentOperation =
new StateAssignmentOperation(
latest.getCheckpointID(), tasks, operatorStates, allowNonRestoredState);
stateAssignmentOperation.assignStates();
...
}The above is the state recovery logic of the initial startup of the application. What is the logic of the failed restart of the Operator during the operation of the application? In fact, the JobMaster will listen to the running status of the task and handle it accordingly, such as the following failure handling link logic:
UpdateSchedulerNgOnInternalFailuresListener.class
@Override
public void notifyTaskFailure(
final ExecutionAttemptID attemptId,
final Throwable t,
final boolean cancelTask,
final boolean releasePartitions) {
final TaskExecutionState state =
new TaskExecutionState(jobId, attemptId, ExecutionState.FAILED, t);
schedulerNg.updateTaskExecutionState(
new TaskExecutionStateTransition(state, cancelTask, releasePartitions));
}
SchedulerBase.class
@Override
public final boolean updateTaskExecutionState(
final TaskExecutionStateTransition taskExecutionState) {
final Optional<ExecutionVertexID> executionVertexId =
getExecutionVertexId(taskExecutionState.getID());
boolean updateSuccess = executionGraph.updateState(taskExecutionState);
if (updateSuccess) {
checkState(executionVertexId.isPresent());
if (isNotifiable(executionVertexId.get(), taskExecutionState)) {
updateTaskExecutionStateInternal(executionVertexId.get(), taskExecutionState);
}
return true;
} else {
return false;
}
}
DefaultScheduler.class
@Override
protected void updateTaskExecutionStateInternal(
final ExecutionVertexID executionVertexId,
final TaskExecutionStateTransition taskExecutionState) {
schedulingStrategy.onExecutionStateChange(
executionVertexId, taskExecutionState.getExecutionState());
maybeHandleTaskFailure(taskExecutionState, executionVertexId);
}
private void maybeHandleTaskFailure(
final TaskExecutionStateTransition taskExecutionState,
final ExecutionVertexID executionVertexId) {
if (taskExecutionState.getExecutionState() == ExecutionState.FAILED) {
final Throwable error = taskExecutionState.getError(userCodeLoader);
handleTaskFailure(executionVertexId, error);
}
}
private void handleTaskFailure(
final ExecutionVertexID executionVertexId, @Nullable final Throwable error) {
setGlobalFailureCause(error);
notifyCoordinatorsAboutTaskFailure(executionVertexId, error);
final FailureHandlingResult failureHandlingResult =
executionFailureHandler.getFailureHandlingResult(executionVertexId, error);
maybeRestartTasks(failureHandlingResult);
}
private void maybeRestartTasks(final FailureHandlingResult failureHandlingResult) {
if (failureHandlingResult.canRestart()) {
//Call restartasks
restartTasksWithDelay(failureHandlingResult);
} else {
failJob(failureHandlingResult.getError());
}
}
private Runnable restartTasks(
final Set<ExecutionVertexVersion> executionVertexVersions,
final boolean isGlobalRecovery) {
return () -> {
final Set<ExecutionVertexID> verticesToRestart =
executionVertexVersioner.getUnmodifiedExecutionVertices(
executionVertexVersions);
removeVerticesFromRestartPending(verticesToRestart);
resetForNewExecutions(verticesToRestart);
try {
restoreState(verticesToRestart, isGlobalRecovery);
} catch (Throwable t) {
handleGlobalFailure(t);
return;
}
schedulingStrategy.restartTasks(verticesToRestart);
};
}
SchedulerBase.class
protected void restoreState(
final Set<ExecutionVertexID> vertices, final boolean isGlobalRecovery)
throws Exception {
...
if (isGlobalRecovery) {
final Set<ExecutionJobVertex> jobVerticesToRestore =
getInvolvedExecutionJobVertices(vertices);
checkpointCoordinator.restoreLatestCheckpointedStateToAll(jobVerticesToRestore, true);
} else {
final Map<ExecutionJobVertex, IntArrayList> subtasksToRestore =
getInvolvedExecutionJobVerticesAndSubtasks(vertices);
final OptionalLong restoredCheckpointId =
checkpointCoordinator.restoreLatestCheckpointedStateToSubtasks(
subtasksToRestore.keySet());
// Ideally, the Checkpoint Coordinator would call OperatorCoordinator.resetSubtask, but
// the Checkpoint Coordinator is not aware of subtasks in a local failover. It always
// assigns state to all subtasks, and for the subtask execution attempts that are still
// running (or not waiting to be deployed) the state assignment has simply no effect.
// Because of that, we need to do the "subtask restored" notification here.
// Once the Checkpoint Coordinator is properly aware of partial (region) recovery,
// this code should move into the Checkpoint Coordinator.
final long checkpointId =
restoredCheckpointId.orElse(OperatorCoordinator.NO_CHECKPOINT);
notifyCoordinatorsOfSubtaskRestore(subtasksToRestore, checkpointId);
}
...
}The whole link above involves DefaultScheduler and SchedulerBase, which are actually carried out in a running object instance. The relationship between the two is as follows:
public abstract class SchedulerBase implements SchedulerNG public class DefaultScheduler extends SchedulerBase implements SchedulerOperations
Finally, I returned to the familiar checkpoint coordinator:
CheckpointCoordinator.class
public OptionalLong restoreLatestCheckpointedStateToSubtasks(
final Set<ExecutionJobVertex> tasks) throws Exception {
// when restoring subtasks only we accept potentially unmatched state for the
// following reasons
// - the set frequently does not include all Job Vertices (only the ones that are part
// of the restarted region), meaning there will be unmatched state by design.
// - because what we might end up restoring from an original savepoint with unmatched
// state, if there is was no checkpoint yet.
return restoreLatestCheckpointedStateInternal(
tasks,
OperatorCoordinatorRestoreBehavior
.SKIP, // local/regional recovery does not reset coordinators
false, // recovery might come before first successful checkpoint
true); // see explanation above
}In scheduling strategy In restartasks, the assigned status of each Task is encapsulated in jobmanagertaskrestore, which will be distributed to the taskexecutor as an attribute of the TaskDeploymentDescriptor. After the TaskDeploymentDescriptor is submitted to the taskexecutor, the taskexecutor will use the TaskStateManager to manage the status of the current Task. The TaskStateManager object will be created based on the allocated jobmanagertaskrestore and the local status store TaskLocalStateStore:
TaskEXecutor.class
@Override
public CompletableFuture<Acknowledge> submitTask(
TaskDeploymentDescriptor tdd, JobMasterId jobMasterId, Time timeout) {
...
final TaskLocalStateStore localStateStore =
localStateStoresManager.localStateStoreForSubtask(
jobId,
tdd.getAllocationId(),
taskInformation.getJobVertexId(),
tdd.getSubtaskIndex());
final JobManagerTaskRestore taskRestore = tdd.getTaskRestore();
final TaskStateManager taskStateManager =
new TaskStateManagerImpl(
jobId,
tdd.getExecutionAttemptId(),
localStateStore,
taskRestore,
checkpointResponder);
...
//Start Task
}Starting a Task will call the invoke method of StreamTask, and perform the following initialization in beforeInvoke:
StreamTask.class
protected void beforeInvoke() throws Exception {
...
operatorChain.initializeStateAndOpenOperators(
createStreamTaskStateInitializer());
...
}
public StreamTaskStateInitializer createStreamTaskStateInitializer() {
InternalTimeServiceManager.Provider timerServiceProvider =
configuration.getTimerServiceProvider(getUserCodeClassLoader());
return new StreamTaskStateInitializerImpl(
getEnvironment(),
stateBackend,
TtlTimeProvider.DEFAULT,
timerServiceProvider != null
? timerServiceProvider
: InternalTimeServiceManagerImpl::create);
}Return to the initializeStateAndOpenOperators method of operatorChain:
OperatorChain.class
protected void initializeStateAndOpenOperators(
StreamTaskStateInitializer streamTaskStateInitializer) throws Exception {
for (StreamOperatorWrapper<?, ?> operatorWrapper : getAllOperators(true)) {
StreamOperator<?> operator = operatorWrapper.getStreamOperator();
operator.initializeState(streamTaskStateInitializer);
operator.open();
}
}Where the initializeState of StreamOperator calls the initializeState of subclass AbstractStreamOperator and creates StreamOperator statecontext in it:
AbstractStreamOperator.class
@Override
public final void initializeState(StreamTaskStateInitializer streamTaskStateManager)
throws Exception {
final TypeSerializer<?> keySerializer =
config.getStateKeySerializer(getUserCodeClassloader());
final StreamTask<?, ?> containingTask = Preconditions.checkNotNull(getContainingTask());
final CloseableRegistry streamTaskCloseableRegistry =
Preconditions.checkNotNull(containingTask.getCancelables());
final StreamOperatorStateContext context =
streamTaskStateManager.streamOperatorStateContext(
getOperatorID(),
getClass().getSimpleName(),
getProcessingTimeService(),
this,
keySerializer,
streamTaskCloseableRegistry,
metrics,
config.getManagedMemoryFractionOperatorUseCaseOfSlot(
ManagedMemoryUseCase.STATE_BACKEND,
runtimeContext.getTaskManagerRuntimeInfo().getConfiguration(),
runtimeContext.getUserCodeClassLoader()),
isUsingCustomRawKeyedState());
stateHandler =
new StreamOperatorStateHandler(
context, getExecutionConfig(), streamTaskCloseableRegistry);
timeServiceManager = context.internalTimerServiceManager();
stateHandler.initializeOperatorState(this);
runtimeContext.setKeyedStateStore(stateHandler.getKeyedStateStore().orElse(null));
}The actual actions of reading state data from the snapshot and restoring it are hidden in the creation process of streamOperatorStateContext:
StreamTaskStateInitializerImpl.class
@Override
public StreamOperatorStateContext streamOperatorStateContext(
// -------------- Keyed State Backend --------------
keyedStatedBackend =
keyedStatedBackend(
keySerializer,
operatorIdentifierText,
prioritizedOperatorSubtaskStates,
streamTaskCloseableRegistry,
metricGroup,
managedMemoryFraction);
// -------------- Operator State Backend --------------
operatorStateBackend =
operatorStateBackend(
operatorIdentifierText,
prioritizedOperatorSubtaskStates,
streamTaskCloseableRegistry);
// -------------- Raw State Streams --------------
rawKeyedStateInputs =
rawKeyedStateInputs(
prioritizedOperatorSubtaskStates
.getPrioritizedRawKeyedState()
.iterator());
streamTaskCloseableRegistry.registerCloseable(rawKeyedStateInputs);
rawOperatorStateInputs =
rawOperatorStateInputs(
prioritizedOperatorSubtaskStates
.getPrioritizedRawOperatorState()
.iterator());
streamTaskCloseableRegistry.registerCloseable(rawOperatorStateInputs);
// -------------- Internal Timer Service Manager --------------
if (keyedStatedBackend != null) {
// if the operator indicates that it is using custom raw keyed state,
// then whatever was written in the raw keyed state snapshot was NOT written
// by the internal timer services (because there is only ever one user of raw keyed
// state);
// in this case, timers should not attempt to restore timers from the raw keyed
// state.
final Iterable<KeyGroupStatePartitionStreamProvider> restoredRawKeyedStateTimers =
(prioritizedOperatorSubtaskStates.isRestored()
&& !isUsingCustomRawKeyedState)
? rawKeyedStateInputs
: Collections.emptyList();
timeServiceManager =
timeServiceManagerProvider.create(
keyedStatedBackend,
environment.getUserCodeClassLoader().asClassLoader(),
keyContext,
processingTimeService,
restoredRawKeyedStateTimers);
} else {
timeServiceManager = null;
}
// -------------- Preparing return value --------------
return new StreamOperatorStateContextImpl(
prioritizedOperatorSubtaskStates.isRestored(),
operatorStateBackend,
keyedStatedBackend,
timeServiceManager,
rawOperatorStateInputs,
rawKeyedStateInputs);
}So far, we have completed combing the state recovery process of Flink Kafka Source Operator Checkpoint. This logic can be roughly divided into two parts: state initialization based on StateInitializationContext and restoring state from Checkpoint and generating StateInitializationContext. The recovery process of the latter is much more complex than that described in the article. In fact, after the JobMaster listens to the task failure, it will load the state metadata of the latest snapshot from the Checkpoint persistence data, and then reassign the state to each subtask, especially the recovery of application restart level, which also involves the change of operator topology and parallelism, After the JobMaster state is restored, submit the task restart request. On the task manager side, you may also restore the state data from the local snapshot (if enabled). The status recovery on the TaskManager side is marked by the completion of the creation of the StreamOperator statecontext. It wraps the complete data after the snapshot recovery, and then returns to the normal calling process of the InitialState method of the StreamOperator.
summary
From the processing flow of Flink Checkpoint (including snapshot creation and initialization) and Kafka's support for Flink Checkpoint, this paper determines that Flink Checkpoint supports Kafka's data consumption state maintenance from the perspective of Flink's code implementation, but this state is only obtained from the StateInitializationContext object, In order to further verify whether the state of StateInitializationContext is obtained from Checkpoint persistence, the fourth part of this paper combs Flink's state recovery logic from Flink application restart and runtime Operator failure retry, and determines that Flink supports state recovery from Checkpoint or Savepoint.
Finally, according to the above analysis, developers should pay attention to when developing Flink applications: Although Flink can restore the Kafka consumption status to the latest Checkpoint snapshot, it cannot avoid repeated consumption between the two snapshots. A typical scenario is that when the Sink side does not support idempotent, it may cause data duplication. For example, PrintSink cannot recall the data output between snapshots. In addition, when the flick Checkpoint is not opened, you need to rely on the state of Kafka Client's own commit to maintain the state.