Original articles are welcome to be reproduced. Reprinted please note: reprinted from IT Story Club Thank you!
Original Link Address: "Doker Actual Chapter" python's docker-tremolo web-side data capture (19)
Why hasn't the trembler grabbed the data? For example, there is an Internet business fresh company, the company's owner wants to put advertisements on some traffic, through increasing the company's product exposure, marketing, in the choice of delivery, he found tremble, tremble has a large amount of data traffic, trying to put advertisements on tremble, to see whether profit and effect are profitable. They analyze the data of tremble, analyze the user portrait of tremble, judge the matching degree between the user group and the company, and need the number of fans, points of praise, number of concerns, nicknames of tremble. Through user preferences, the company's products are integrated into the video to better promote the company's products. Through these data, some public relations companies can find the net red and black horse and carry out marketing packaging. Source code: https://github.com/limingios/dockerpython.git (douyin)
Tremolo Sharing Page
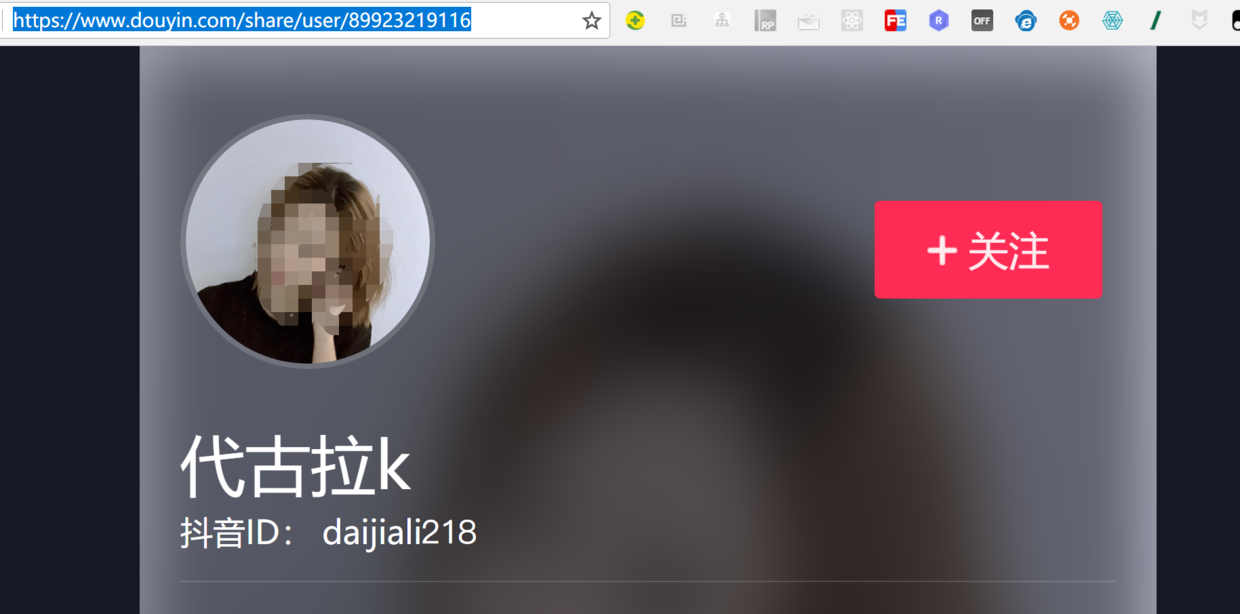
- Install Google xpath helper tool
Getting crx from source code
Google browser input: chrome://extensions/
Drag xpath-helper.crx directly into the interface chrome://extensions/
After successful installation
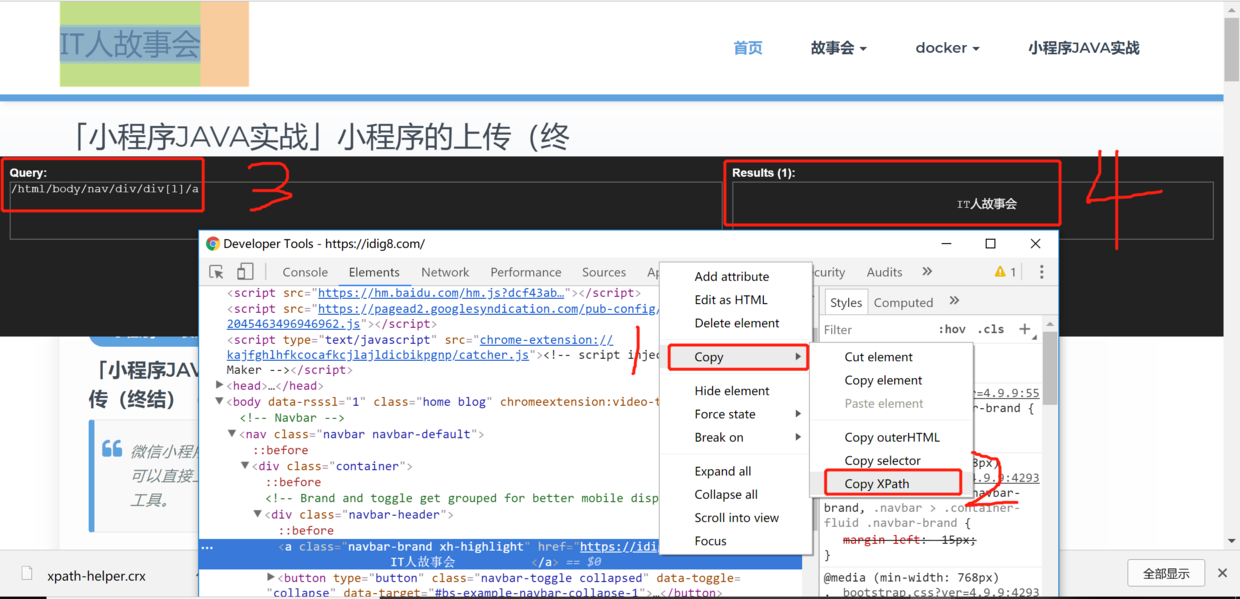
Shortcut keys ctrl+shift+x to start xpath are generally used in conjunction with Google's f12 developer tools.
Begin python crawling for jitter-sharing website data
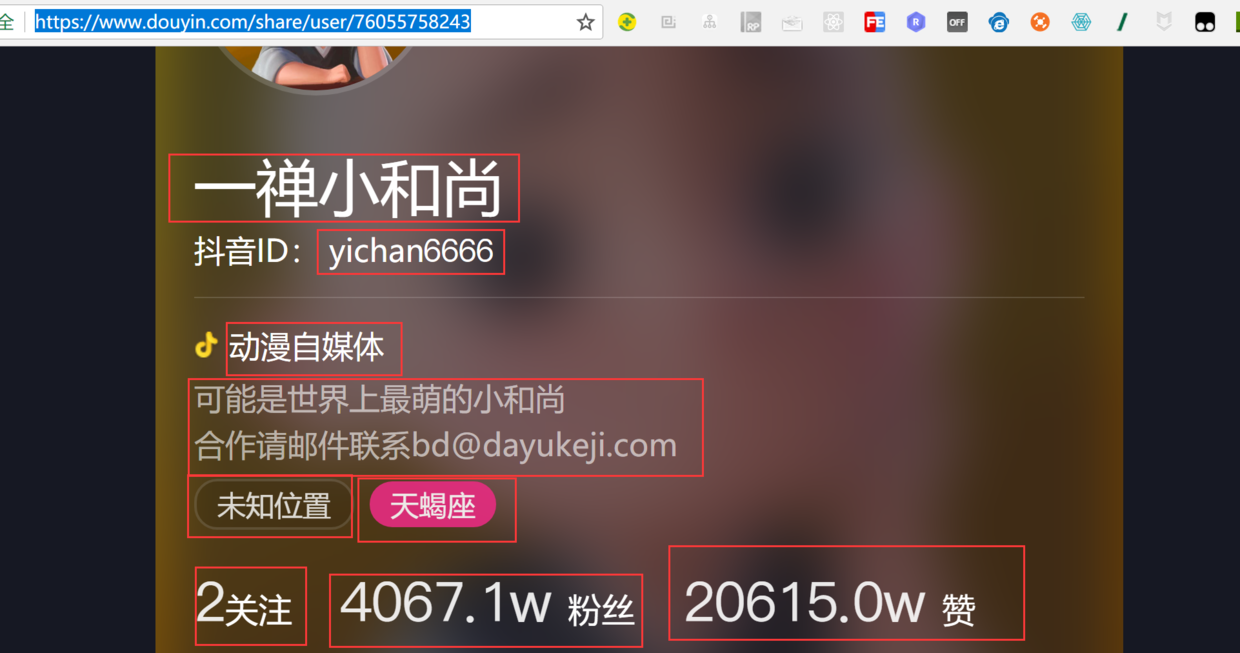
Analytical Sharing Page https://www.douyin.com/share/user/76055758243
1. Tremolo is a villain mechanism. The number in the tremolo ID is changed into a string and replaced.
{'name':['  ','  ','  '],'value':0},
{'name':['  ','  ','  '],'value':1},
{'name':['  ','  ','  '],'value':2},
{'name':['  ','  ','  '],'value':3},
{'name':['  ','  ','  '],'value':4},
{'name':['  ','  ','  '],'value':5},
{'name':['  ','  ','  '],'value':6},
{'name':['  ','  ','  '],'value':7},
{'name':['  ','  ','  '],'value':8},
{'name':['  ','  ','  '],'value':9},
2. Get the xpath of the required node
# Nickname? //div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text() #Jitter ID //div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text() #work //div[@class='personal-card']/div[@class='info2']/div[@class='verify-info']/span[@class='info']/text() #describe //div[@class='personal-card']/div[@class='info2']/p[@class='signature']/text() #address //div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[1]/text() #constellation //div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[2]/text() #Concern number //div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i[@class='icon iconfont follow-num']/text() #Number of fans //div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text() #Zan number //div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()
- Complete code
import re import requests import time from lxml import etree
def handle_decode(input_data,share_web_url,task):
search_douyin_str = re.compile(r'dither ID:')
regex_list = [
{'name':[' ',' ',' '],'value':0},
{'name':[' ',' ',' '],'value':1},
{'name':[' ',' ',' '],'value':2},
{'name':[' ',' ',' '],'value':3},
{'name':[' ',' ',' '],'value':4},
{'name':[' ',' ',' '],'value':5},
{'name':[' ',' ',' '],'value':6},
{'name':[' ',' ',' '],'value':7},
{'name':[' ',' ',' '],'value':8},
{'name':[' ',' ',' '],'value':9},
]
for i1 in regex_list:
for i2 in i1['name']:
input_data = re.sub(i2,str(i1['value']),input_data)
share_web_html = etree.HTML(input_data)
douyin_info = {}
douyin_info['nick_name'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]
douyin_id = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']/p[@class='shortid']/i/text()"))
douyin_info['douyin_id'] = re.sub(search_douyin_str,'',share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]).strip() + douyin_id
try:
douyin_info['job'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/div[@class='verify-info']/span[@class='info']/text()")[0].strip()
except:
pass
douyin_info['describe'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='signature']/text()")[0].replace('\n',',')
douyin_info['location'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[1]/text()")[0]
douyin_info['xingzuo'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[2]/text()")[0]
douyin_info['follow_count'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i[@class='icon iconfont follow-num']/text()")[0].strip()
fans_value = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['fans'] = str((int(fans_value)/10))+'w'
like = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['like'] = str(int(like)/10)+'w'
douyin_info['from_url'] = share_web_url
print(douyin_info)def handle_douyin_web_share(share_id):
share_web_url = 'https://www.douyin.com/share/user/'+share_id
print(share_web_url)
share_web_header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
share_web_response = requests.get(url=share_web_url,headers=share_web_header)
handle_decode(share_web_response.text,share_web_url,share_id)
if name == 'main':
while True:
share_id = "76055758243"
if share_id == None:
print('current processing task is:% s'%share_id)
break
else:
print('current processing task is:% s'%share_id)
handle_douyin_web_share(share_id)
time.sleep(2)
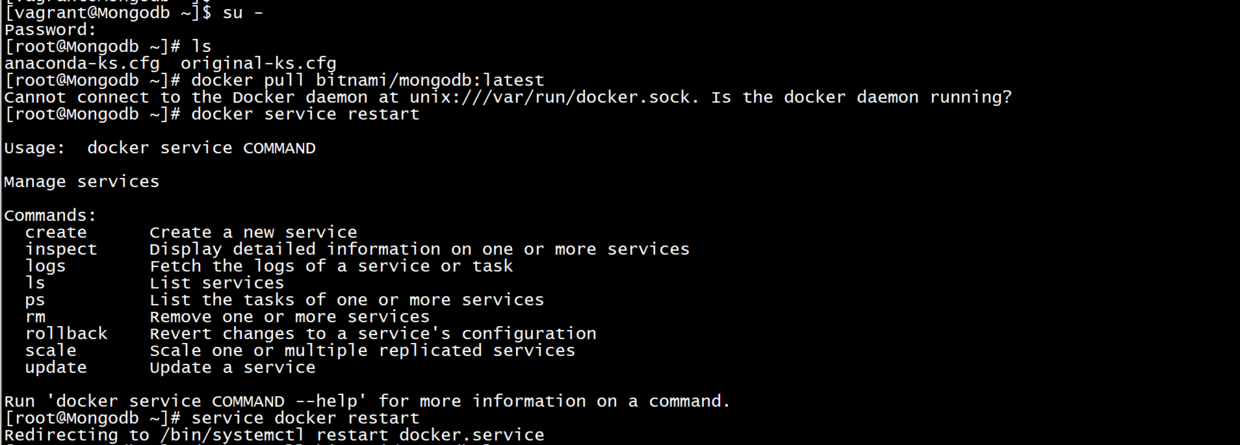
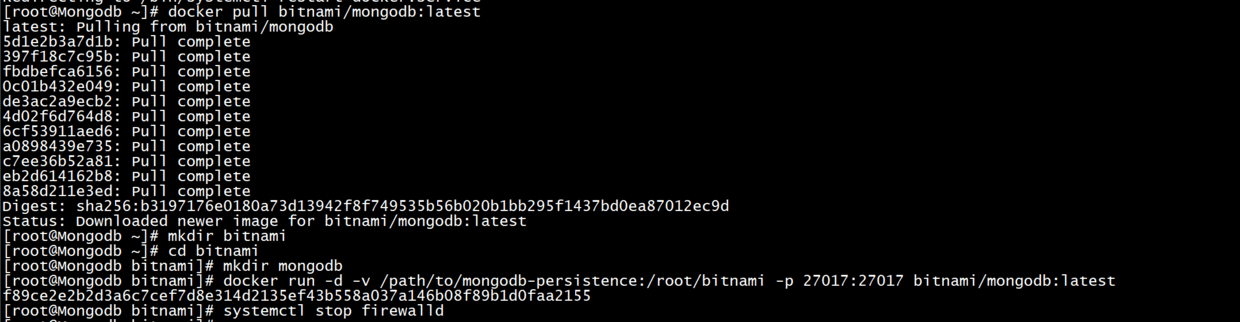
 #### mongodb >adopt vagrant Generating Virtual Machine Creation mongodb,Specific view 「docker DJ Java Decompiler」python Of docker Crawler technology-python Script app Grab (13) ``` bash su - #Password: vagrant docker >https://hub.docker.com/r/bitnami/mongodb >Default port: 27017 ``` bash docker pull bitnami/mongodb:latest mkdir bitnami cd bitnami mkdir mongodb docker run -d -v /path/to/mongodb-persistence:/root/bitnami -p 27017:27017 bitnami/mongodb:latest #Close the firewall systemctl stop firewalld
- Manipulating mongodb
Read the txt file to get the userId number.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/1/30 19:35
# @Author : Aries
# @Site :
# @File : handle_mongo.py.py
# @Software: PyCharm
import pymongo
from pymongo.collection import Collection
client = pymongo.MongoClient(host='192.168.66.100',port=27017)
db = client['douyin']
def handle_init_task():
task_id_collections = Collection(db, 'task_id')
with open('douyin_hot_id.txt','r') as f:
f_read = f.readlines()
for i in f_read:
task_info = {}
task_info['share_id'] = i.replace('\n','')
task_id_collections.insert(task_info)
def handle_get_task():
task_id_collections = Collection(db, 'task_id')
# return task_id_collections.find_one({})
return task_id_collections.find_one_and_delete({})
#handle_init_task()
- Modifying python program calls
import re import requests import time from lxml import etree from handle_mongo import handle_get_task from handle_mongo import handle_insert_douyin
def handle_decode(input_data,share_web_url,task):
search_douyin_str = re.compile(r'dither ID:')
regex_list = [
{'name':[' ',' ',' '],'value':0},
{'name':[' ',' ',' '],'value':1},
{'name':[' ',' ',' '],'value':2},
{'name':[' ',' ',' '],'value':3},
{'name':[' ',' ',' '],'value':4},
{'name':[' ',' ',' '],'value':5},
{'name':[' ',' ',' '],'value':6},
{'name':[' ',' ',' '],'value':7},
{'name':[' ',' ',' '],'value':8},
{'name':[' ',' ',' '],'value':9},
]
for i1 in regex_list:
for i2 in i1['name']:
input_data = re.sub(i2,str(i1['value']),input_data)
share_web_html = etree.HTML(input_data)
douyin_info = {}
douyin_info['nick_name'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]
douyin_id = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']/p[@class='shortid']/i/text()"))
douyin_info['douyin_id'] = re.sub(search_douyin_str,'',share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]).strip() + douyin_id
try:
douyin_info['job'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/div[@class='verify-info']/span[@class='info']/text()")[0].strip()
except:
pass
douyin_info['describe'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='signature']/text()")[0].replace('\n',',')
douyin_info['location'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[1]/text()")[0]
douyin_info['xingzuo'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[2]/text()")[0]
douyin_info['follow_count'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i[@class='icon iconfont follow-num']/text()")[0].strip()
fans_value = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['fans'] = str((int(fans_value)/10))+'w'
like = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['like'] = str(int(like)/10)+'w'
douyin_info['from_url'] = share_web_url
print(douyin_info)
handle_insert_douyin(douyin_info)def handle_douyin_web_share(task):
share_web_url = 'https://www.douyin.com/share/user/'+task["share_id"]
print(share_web_url)
share_web_header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
share_web_response = requests.get(url=share_web_url,headers=share_web_header)
handle_decode(share_web_response.text,share_web_url,task["share_id"])
if name == 'main':
while True:
task=handle_get_task()
handle_douyin_web_share(task)
time.sleep(2)
* mongodb field
>handle_init_task Will be txt Deposit in mongodb in
>handle_get_task Find out one and delete one because txt It does exist, so deletion doesn't matter at all.
``` python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/1/30 19:35
# @Author : Aries
# @Site :
# @File : handle_mongo.py.py
# @Software: PyCharm
import pymongo
from pymongo.collection import Collection
client = pymongo.MongoClient(host='192.168.66.100',port=27017)
db = client['douyin']
def handle_init_task():
task_id_collections = Collection(db, 'task_id')
with open('douyin_hot_id.txt','r') as f:
f_read = f.readlines()
for i in f_read:
task_info = {}
task_info['share_id'] = i.replace('\n','')
task_id_collections.insert(task_info)
def handle_insert_douyin(douyin_info):
task_id_collections = Collection(db, 'douyin_info')
task_id_collections.insert(douyin_info)
def handle_get_task():
task_id_collections = Collection(db, 'task_id')
# return task_id_collections.find_one({})
return task_id_collections.find_one_and_delete({})
handle_init_task()
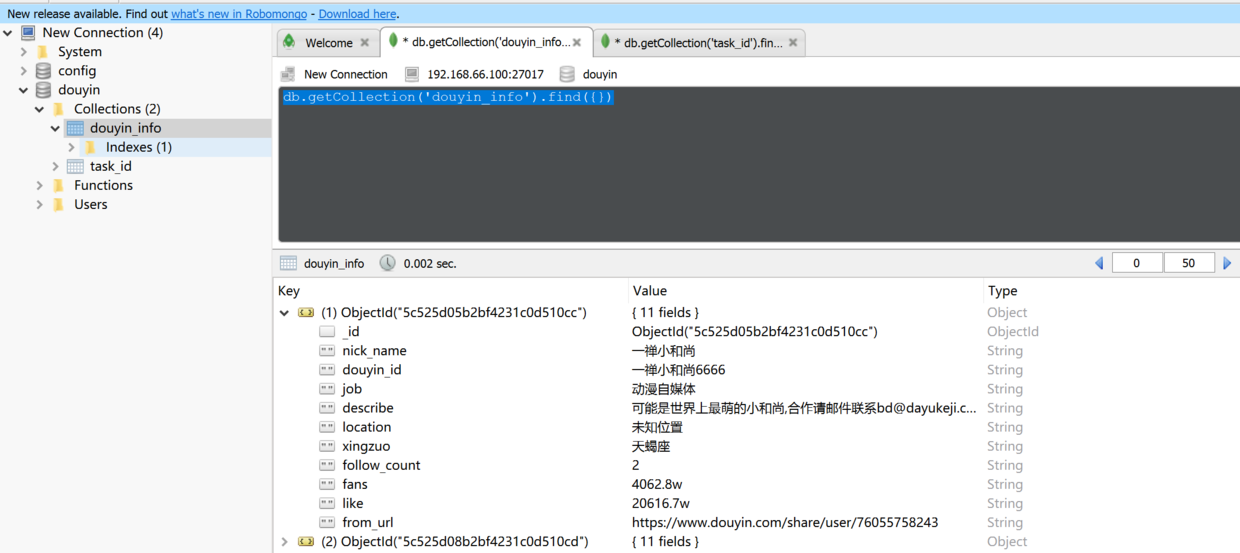
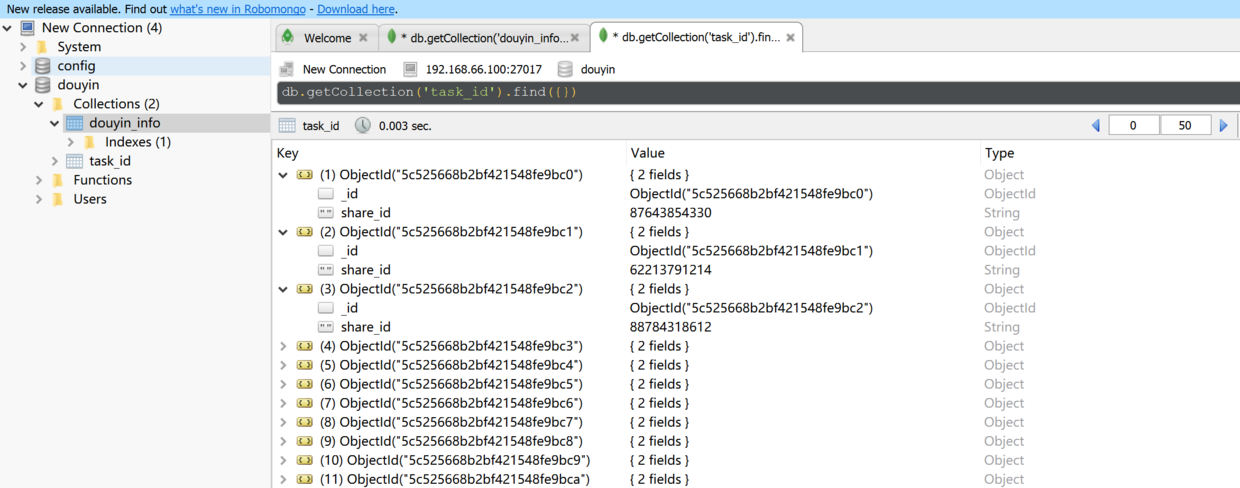
PS: Text text data 1000 is not enough to crawl too little, in fact, app and pc side cooperate to crawl, pc side is responsible for initialization of data, through the user ID to get the list of fans and then in a non-stop cycle to crawl, so you can get a lot of data.