preface
I believe many of our students often use the concepts of Node and Element. What's the difference between them? I don't know how many people can answer this question?
Today, I'm here to try to explain the difference between Node and Element.
preparation
Before formally introducing the difference between Node and Element, let's prepare the following code:
<div id="parent">
This is parent content.
<div id="child1">This is child1.</div>
<div id="child2">This is child2.</div>
</div>Most of the following phenomena and conclusions will be illustrated with the help of the structure of this code.
What exactly does getElementById get?
document.getElementById() method should be one of the most commonly used interfaces. Is its return value Node or Element?
Let's verify it with the following code:
let parentEle = document.getElementById('parent');
parentEle instanceof Node
// true
parentEle instanceof Element
// true
parentEle instanceof HTMLElement
// trueAs you can see, document The result obtained by getelementbyid() is both a Node and an Element.
What is the relationship between Node, ELement and HTMLElement?
Why should Node, Element and HTMLElement be used for type judgment in the above code? What is the relationship between them?
Look at the code:
let parentEle = document.getElementById('parent');
parentEle.__proto__
// HTMLDivElement {...}
parentEle.__proto__.__proto__
// HTMLElement {...}
parentEle.__proto__.__proto__.__proto__
// Element {...}
parentEle.__proto__.__proto__.__proto__.__proto__
// Node {...}
parentEle.__proto__.__proto__.__proto__.__proto__.__proto__
// EventTarget {...}
parentEle.__proto__.__proto__.__proto__.__proto__.__proto__.__proto__
// {constructor: ƒ, ...}
parentEle.__proto__.__proto__.__proto__.__proto__.__proto__.__proto__.__proto__
// nullFor the above output results, we can use a graph to more intuitively express the relationship between them:
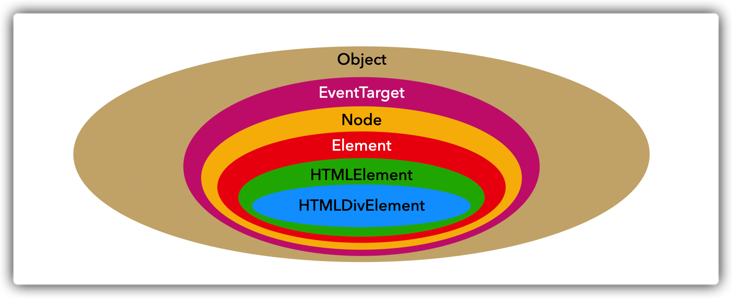
This explains why getElementById obtains both Node and Element, because Element inherits from Node.
Thus, we can also draw a conclusion: Element must be Node, but Node is not necessarily Element.
So: Element can use all methods of Node.
Look more directly at nodes and elements
Although the above conclusion is reached and the relationship between Node and Element is clear, it is only a theory. We need more straightforward results to strengthen our understanding of the theory.
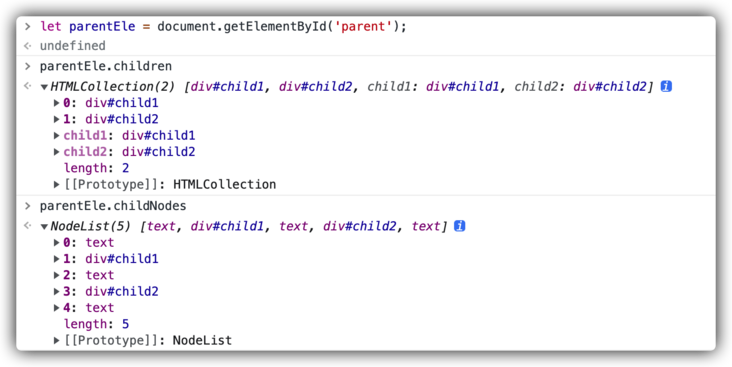
NodeList content:
- [0] "\n This is parent content."
- [2] "\n "
- [4] "\n "
Element.children only get all div s under the parent element point, while element ChildNodes gets all the nodes (including text content and elements) under the parent node.
Where is the boundary of a single Node?
From the NodeList content of the above example, the newline character \ n is treated as a single Node, which raises a new question: where is the boundary generated by a single Node?
We will remove the formatting and merge the HTML code used into one line, and modify it as follows:
<div id="parent">This is parent content.<div id="child1">This is child1.</div><div id="child2">This is child2.</div></div>
Output result:
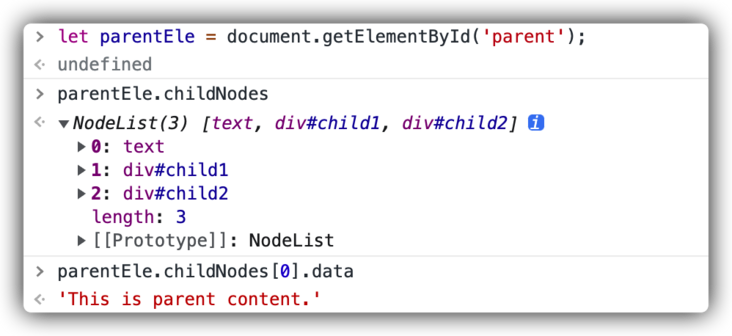
There is no line break in NodeList. In the previous example, the line break in NodeList is caused by the line break between HTML tags and tags, and between content and tags in the original code.
Now you can answer the boundary of a single Node in two aspects:
- A single HTML tag is a single Node;
- For non HTML tags (such as text, space, etc.), start from the starting tag of an HTML tag to the first HTML tag. If there is content (text, space, etc.) in the middle, this part of the content is a Node.
Further
Because the above examples use block level elements, what happens if inline elements are used?
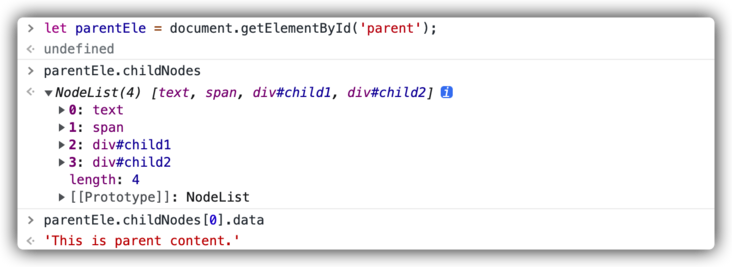
Test 1:
<div id="parent">This is parent content.<span>This is a span.</span><div id="child1">This is child1.</div><div id="child2">This is child2.</div></div>
Test 2:
<body>
<div id="parent">This is parent content\n.
<span>This is a span.</span>
<div id="child1">This is child1.</div><div id="child2">This is child2.</div>
</div>
</body>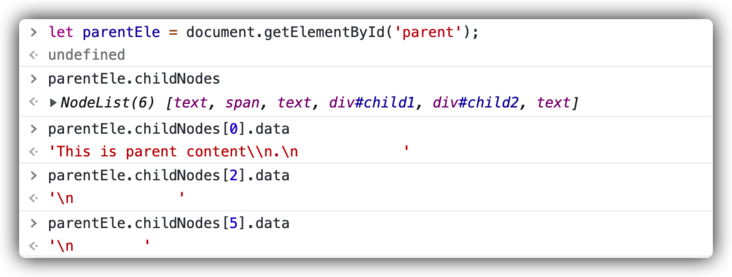
It can be seen that even if the span element is used, the final result is consistent with the conclusion of single Node boundary drawn above.
extend
From the above examples, we can expand and summarize:
- Line breaks in HTML can only use < / BR > tags, and will be directly parsed into strings;
- In HTML code, line breaks between tags and text, and between tags and tags will be truthfully recorded and reflected in the obtained results, which is \ n;
- In HTML code, the spaces between tags, text and text, text and tags are not truthfully recorded;
- node. The number of space characters after \ n in the data content is related to the configured number of formatted spaces in the actual code, which is actually "spaces will be truthfully recorded".
summary
The above examples illustrate the difference between Node and Element. The main conclusions are as follows:
- document. The result obtained by getelementbyid() is both a Node and an Element.
- Element must be a Node, but Node is not necessarily an element. It may also be text, spaces and line breaks.
- The newline character in NodeList is generated by the newline between HTML tags and tags, and between content and tags in the original code.
- A single HTML tag is a single Node.
- For non HTML tags (such as text, space, etc.), start from the starting tag of an HTML tag to the first HTML tag. If the middle is composed of content (text, space, etc.), this part of the content is a Node.
~
~End of this article, thank you for reading!
~
Learn interesting knowledge, make interesting friends and shape interesting souls!
Hello, I'm Programming samadhi Hermit Wang, my official account is " Programming samadhi "Welcome to pay attention and hope you can give us more advice!