Inverted index
At present, the mainstream index technology of full-text search engine is the way of inverted index. The traditional way to save data is: record → word. The way of storing data in inverted index is: word → record. The inverted index is constructed based on word segmentation technology. When each record saves data, it will not be directly stored in the database. The system will segment the data first, and then save it in an inverted index structure.
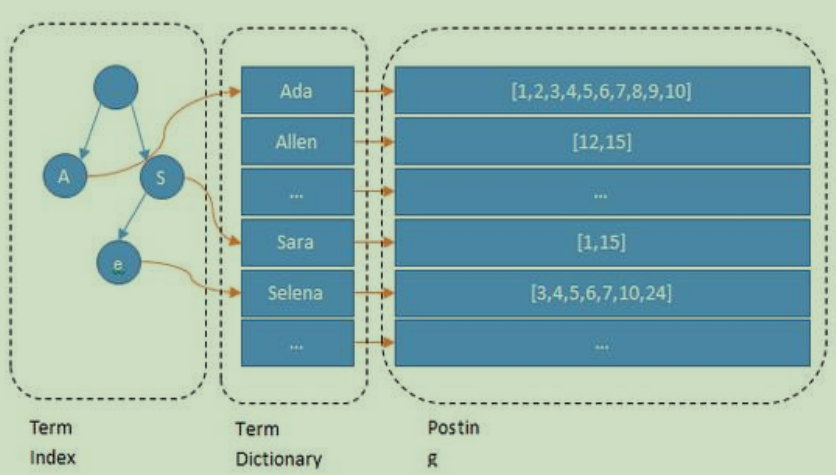
It can be seen that Lucene adds another layer of Term Index structure to the term dictionary part for fast positioning, and the Term Index is cached in memory, but MySQL B+tree is not in memory, so on the whole, ES is faster, but it also consumes more resources (memory and disk)
Cluster operation
- Cluster health status - get/_ cat/health? v
Green – everything is normal (the cluster is fully functional)
Yellow – all data is available, but some replicas have not been allocated (the cluster function is complete)
Red – some data is unavailable (some functions of the cluster)
- View node status - get/_ cat/nodes? v

- Query each index status - get/_ cat/indices? v

Indexes
-
Create index - PUT /film
-
View the fragmentation of an index - get/_ cat/shards/film? v
-
Delete index - DELETE /film
Document operation
- Create document - PUT /film/_doc/1 idempotency
{ "id":100,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]}
- POST /film/_doc / non idempotent
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[ {"id":4,"name":"zhang cuishan111"}]
}
Idempotency is guaranteed according to the primary key
-
Query all documents in an index - GET /film/_search

-
Query a document by id - GET /film/_doc/3
-
Delete a document according to the document id - DELETE /film/_doc/3
-
Modify document - PUT /film/_doc/3 replaces existing documents (idempotency)
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[ {"id":4,"name":"zhang cuishan"}]
}
- POST /film/_doc/3/_update updates the content of a field in the document
{ "doc": { "yy": "character string" } }
Elasticsearch doesn't actually perform in place updates at the bottom. Instead, it deletes old documents before adding new ones
- Batch create documents
POST /film/_doc/_bulk
{"index":{"_id":66}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"zhang cuishan"}]}
{"index":{"_id":88}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"zhang cuishan"}]}
- Batch updating and deleting documents
POST /film/_doc/_bulk
{"update":{"_id":"66"}}
{"doc": { "name": "wudangshanshang" } }
{"delete":{"_id":"88"}}
query
GET / index name/_ search? Q = & pretty this method is not suitable for complex query scenarios*
- Query specified field - GET /film/_search
{ "_source": ["name", "doubanScore"]}
- Query by word segmentation (word segmentation text type must be used)
GET /film/_search
{
"query": {
"match": {
"actorList.name": "zhang han yu"
}
}}
- Querying by phrase is equivalent to like
GET /film/_search
{
"query": {
"match_phrase": {
"actorList.name": "zhang han yu"
}
}}
- Query by exact matching without word segmentation
GET /film/_search
{
"query": {
"term": {
"actorList.name.keyword":"zhang han yu"
}
}}
- Fault tolerant matching
GET /film/_search
{
"query": {
"fuzzy": {
"name": "radd"
}
}}
- Matching and filtering simultaneously
GET /film/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "red"
}
}],
"filter": {
"term": {
"actorList.id": "3"
}
}
}}}
- Filter the range and query the documents with Douban score of 6 to 9
GET /film/_search
{
"query": {
"range": {
"doubanScore": {
"gte": 6,
"lte": 9
}}
}}
- Sort in descending order according to Douban score
GET /film/_search
{ "query": {
"match": {
"name": "red"
}},
"sort": [ {
"doubanScore": {
"order": "asc"
}
} ]}
- Paging query
GET /film/_search
{"from": 0, "size": 2}
- Highlight search results
GET /film/_search
{
"query": {
"match": {
"name": "red"
}
},
"highlight": {
"fields": {"name":{} },
"pre_tags": "<a>",
"post_tags": "</a>"
}
}
- Aggregation - aggregation provides the ability to group and count data, similar to Group By and SQL aggregation functions in SQL. In ElasticSearch, you can return search results and aggregate calculation results at the same time, which is very powerful and efficient.
GET /film/_search
{
"aggs": {
"groupByName": {
"terms": {
"field": "actorList.name.keyword",
"size": 10,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score": {
"avg": {
"field": "doubanScore"
} }
}}
}}
. keyword is a string field, which is specially used to store the copy of the non participle format. In some scenarios, only the non participle format is allowed, such as filter, aggregation aggs, so the field should be added Suffix of keyword
Chinese word segmentation
-
Comparison of Chinese word segmentation
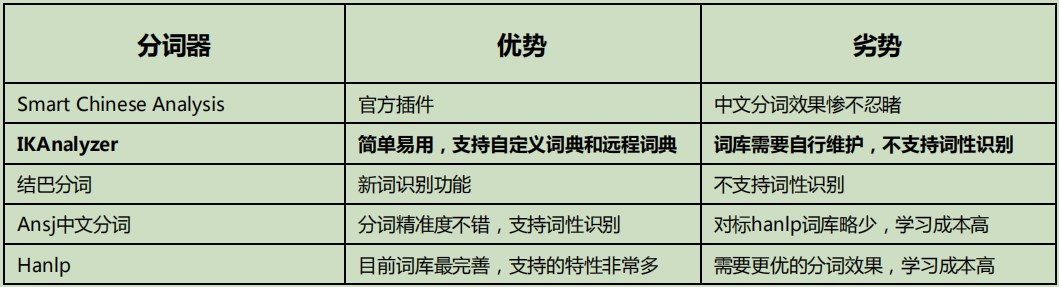
-
GET _analyze
{"analyzer": "ik_smart", "text": "I am Chinese," }
{
"tokens" : [
{
"token" : "I",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "yes",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "Chinese",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
- Custom word segmentation Thesaurus
<comment>IK Analyzer Extended configuration</comment> <!--Users can configure their own extended dictionary here --> <entry key="ext_dict">./myword.txt</entry> <!--Users can configure their own extended stop word dictionary here--> <entry key="ext_stopwords"></entry>
Mapping
- Custom mapping - in fact, the data Type of the field in each Type is defined by mapping. If we do not set mapping when creating the Index, the system will automatically infer the field Type corresponding to a piece of data according to the format of the data, The specific inference types are as follows: true/false → boolean 1020 → long 20.1 → float "2018-02-01" → date "hello world" → text +keyword. By default, only text can be segmented, and keyword is a string without word segmentation. In addition to automatic definition, mapping can also be defined manually, but only the newly added fields without data can be defined. Once the data is available, it cannot be modified.
PUT film01
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "keyword"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
} } }
} }}
copy index data
- Although ElasticSearch is powerful, it cannot dynamically modify mapping. When we need to modify the structure, we sometimes have to recreate the index; ElasticSearch provides us with a reindex command, which is to copy the snapshot data of one index to another index. By default, there are the same indexes_ id will be overwritten (generally, it will not happen unless the data of two indexes are copied into one index)
POST _reindex
{ "source": {
"index": "my_index_name"
},
"dest": {
"index": "my_index_name_new"
}}
Index alias
-
Application scenario - grouping multiple indexes and merging multiple indexes into a group
-
Creating a view for a subset of the Index is equivalent to adding some filter conditions to the Index to narrow the query range
-
Create index and specify alias
PUT flim01
{ "aliases": {
"film_chn_3_aliase": {}
},
- View all aliases
GET /_cat/aliases
- Index addition and deletion
POST /_aliases
{ "actions": [
{ "remove": { "index": "movie_chn_1", "alias": "movie_chn_query" }},
{ "remove": { "index": "movie_chn_2", "alias": "movie_chn_query" }},
{ "add": { "index": "movie_chn_3", "alias": "movie_chn_query" }}
]
}
Index template
-
Application scenario
-
Split index
-
Split index is to divide a business index into multiple indexes according to the time interval. For example, order_info becomes order_info_20200101,order_info_20200102 this has two benefits:
-
Flexibility of structural change
-
Because ES does not allow modification of the data structure. However, in actual use, the structure and configuration of the index will inevitably change, so as long as the index of the next interval is modified, the original index will remain unchanged. In this way, there is a certain degree of flexibility. To achieve this effect, we only need to rebuild the template on the day when the index needs to be changed.
-
Query range optimization
-
Because generally, the data of all time periods will not be queried, the segmentation index can physically reduce the range of scanned data and optimize the performance.
-
Create template
PUT _template/template_film
{"index_patterns": ["film_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"film_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}}
}}}
- Query all templates
GET _cat/templates
- Query template details
GET _template/template_film*