About fault
The causes of faults can be divided into the following categories:
- Network problems: network link problems and broadband congestion.
- Performance problems: slow database, SQL, Java full gc, excessive hard disk IO, high CPU, insufficient memory.
- Security issues: being attacked by networks, such as DDoS.
- Operation and maintenance issues: the system is constantly updated and modified.
- Management problem: key services and service dependencies are not sorted out.
- Hardware problems: hard disk damage, network card failure, computer room power failure.
From another perspective, in terms of flow time sequence, the fault comes from four aspects:
- Sudden increase of upstream flow.
- The system itself has problems, such as power failure, disk full, etc.
- Caused by human changes, such as release and launch.
- The downstream service is abnormal.
Therefore, faults are normal and common, "everything will fail"
Instead of trying to avoid faults, treat the fault handling code as a normal function in the architecture and write it in the code.
Downgrade
The essence of degradation is to solve the problems of insufficient resources and excessive traffic, and temporarily sacrifice some things to ensure the smooth operation of the whole system.
For service callers, service degradation can provide lossy services upward through temporary alternatives when the called service is unavailable to ensure business flexibility and availability;
For service providers, service degradation greatly reduces the pressure on service providers and helps service providers recover quickly.
Current limiting can be considered as a kind of service degradation. Current limiting is to limit the input and output traffic of the system to protect the system. The idea of limited flow is widely used in many places, such as database connection pool, thread pool and limit under Nginx to limit the number of instantaneous concurrent connections_ Conn module, which limits the average rate per second_ Req module.
Limit the number of requests that the interface can pass per second. The excess traffic can be delayed, partially rejected or directly rejected.
Degradation is an idea, and current limiting and fusing are measures.
There are three modes of degradation:
- Forced demotion: in the forced demotion mode, all client calls to a service will be demoted. After demotion, it will be returned according to the configured demotion policy. The forced degradation switch needs to be opened and closed manually by the development director. It is generally used to downgrade all back-end calls in an emergency, and manually close the degradation switch after returning to normal.
- Failure degradation: in the failure degradation mode, the client will always call the back-end service, but the service degradation will be carried out only when the call fails. At this time, it will be returned according to the configured degradation policy.
- Automatic demotion: in the automatic demotion mode, the client will automatically identify whether to demote according to the current service call. If degradation is required, it will be returned according to the configured degradation policy; If degradation is not required, normal service calls are made.
Current limiting strategy
- Denial of service: reject many requests, count which client has the most traffic, and directly reject them. This way can block out some abnormal or malicious high concurrent access. In Pigeon, you can limit the maximum QPS requested by a client application. If the QPS requested by the client exceeds the threshold, the server returns RejectedException; Limit the maximum QPS requested by a service method of the server for a client application, such as The echo method of the EchoService service interface. The maximum stand-alone QPS for applying account service to the client is 200.
- Service degradation: This allows services to have more resources to handle more requests. One way to degrade is to stop some unimportant services and give CPU, memory or data resources to more important functions; The other is not to return the full amount of data, but only part of the data, so as to obtain greater performance throughput at the expense of consistency.
- Privilege request: the resources are not enough. Only limited resources can be allocated to important users, such as VIP users.
- Delay processing: generally, there is a queue to buffer a large number of requests. If the queue is full, users can only be rejected. The buffer queue is only used to relieve pressure and is generally used to deal with short peak spike requests.
Implementation of current limiting
- Counter mode: simple violence. Directly maintain a counter to limit the number of requests that can pass in one second. The implementation idea of the algorithm is to start timing from the first request. In the next 1 second, when a request comes in, the counter count will increase by 1. If the counter is greater than 100, turn on the reject request to protect the system, and all subsequent requests will be rejected. You can use the AtomicLong#incrementAndGet() method to increment the counter by 1 and return the latest value, which can be compared with the threshold. The disadvantage is the "prick phenomenon".
- Queue algorithm: priority queue, which processes high priority queues first, and then low priority queues. In order to avoid starvation of low priority queues, it is generally to allocate different proportions of processing time to different queues, that is, the queue with weight. For example, after processing three requests on the queue with weight 3, process two requests on the queue with weight 2, and finally process one request on the queue with weight 1. If the processing is too slow, it will cause the queue to be full and start triggering flow restriction.
- Funnel algorithm: a fixed capacity funnel flows out water droplets at a fixed rate. If the inflow water droplets exceed the capacity of the funnel, the inflow water droplets overflow (are discarded).
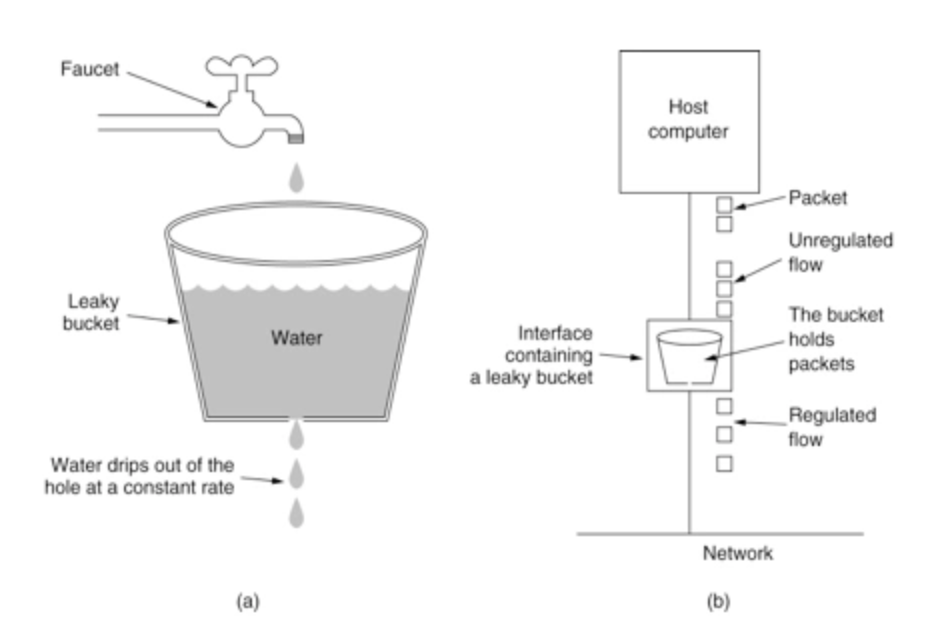
- Token bucket algorithm: for many application scenarios, in addition to limiting the average data transmission rate, it is also required to allow a certain degree of burst traffic. At this time, the funnel algorithm may not be appropriate, and the token bucket algorithm can be used. Put some tokens in a bucket at a certain rate. Only when you get the token can you process the request; The token bucket has a capacity. When the token bucket is full, putting a token into it will be discarded. Save money when the traffic is small, and handle it quickly when the traffic is large.
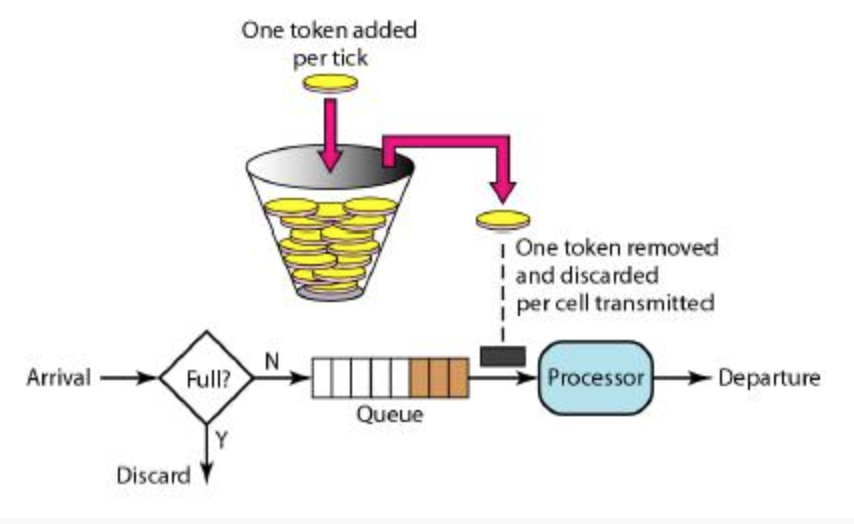
The use scenarios of funnel algorithm and token bucket algorithm are different. It can not be said that token bucket algorithm is better than funnel algorithm.
The token bucket can be used to protect itself. It is mainly used to limit the current of the caller's frequency in order not to be defeated. Therefore, if you have processing capacity, if the traffic bursts (the actual consumption capacity is stronger than the configured traffic limit), the actual processing rate can exceed the configured limit.
The leaky bucket algorithm is used to protect others, that is, to protect the system he calls. The main scenario is that when the calling third-party system itself has no protection mechanism or has traffic restrictions, our call speed cannot exceed its restrictions. Because we cannot change the third-party system, we can only control it at the main caller. At this time, even if the traffic is sudden, it must be abandoned. Because the consumption power is determined by a third party.
Current limiting strategy
- Single machine current limiting: single machine fixed current limiting is implemented based on the token bucket algorithm, which can deal with sudden traffic. The set number of qps tokens will be saved in the default bucket.
- Cluster current limiting (imprecise): single machine current limiting. By specifying the QPS of the cluster, the single machine QPS will be dynamically calculated according to the number of machines in the business.
- Cluster current limiting (accurate): accurate cluster current limiting is realized based on Redis counting. Each current limiting needs to communicate with Redis, with a performance loss of about 1ms. If Redis hangs up, current limiting will not be carried out.
- Cluster frequency limiting: internally, the access frequency of each uuid is realized through the uuid keyword. For example, there are users a, b, c, d... z and access interface / index. The current requirement is to limit the access frequency of each user twice / 5s. It can be realized through cluster frequency limiting and counting based on redis. The user id + interface name is used as the key, and the expiration time is 5s, which is saved in redis
- Cluster quota: it is consistent with the implementation principle of cluster frequency limiting, but only one current limit can be created for each policy. If the following requirements are met, this policy can be used. For example, the access frequency of each user needs to be limited to 2 times / 5s, and the total number of calls per day should be limited to 2000. For these two requirements, a cluster quota can be created, Limit the total number of calls per user per day
Best practices
TODO configuration
Source code analysis
with
RateLimiter rateLimiter = RateLimiter.create(2);
boolean res = rateLimiter.tryAcquire();
rateLimiter.getRate();
rateLimiter.setRate(100);
rateLimiter.tryAcquire();
@ThreadSafe
@Beta
public abstract class RateLimiter {
public static RateLimiter create(double permitsPerSecond) {
return create(SleepingStopwatch.createFromSystemTimer(), permitsPerSecond);
}
static RateLimiter create(SleepingStopwatch stopwatch, double permitsPerSecond) {
RateLimiter rateLimiter = new SmoothBursty(stopwatch, 1.0 /* maxBurstSeconds */);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}
public static RateLimiter create(double permitsPerSecond, long warmupPeriod, TimeUnit unit) {
checkArgument(warmupPeriod >= 0, "warmupPeriod must not be negative: %s", warmupPeriod);
return create(SleepingStopwatch.createFromSystemTimer(), permitsPerSecond, warmupPeriod, unit);
}
@VisibleForTesting
static RateLimiter create(
SleepingStopwatch stopwatch, double permitsPerSecond, long warmupPeriod, TimeUnit unit) {
RateLimiter rateLimiter = new SmoothWarmingUp(stopwatch, warmupPeriod, unit);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}
/**
* The underlying timer; used both to measure elapsed time and sleep as necessary. A separate
* object to facilitate testing.
*/
private final SleepingStopwatch stopwatch;
// Can't be initialized in the constructor because mocks don't call the constructor.
private volatile Object mutexDoNotUseDirectly;
private Object mutex() {
Object mutex = mutexDoNotUseDirectly;
if (mutex == null) {
synchronized (this) {
mutex = mutexDoNotUseDirectly;
if (mutex == null) {
mutexDoNotUseDirectly = mutex = new Object();
}
}
}
return mutex;
}
RateLimiter(SleepingStopwatch stopwatch) {
this.stopwatch = checkNotNull(stopwatch);
}
public final void setRate(double permitsPerSecond) {
checkArgument(
permitsPerSecond > 0.0 && !Double.isNaN(permitsPerSecond), "rate must be positive");
synchronized (mutex()) {
doSetRate(permitsPerSecond, stopwatch.readMicros());
}
}
abstract void doSetRate(double permitsPerSecond, long nowMicros);
public final double getRate() {
synchronized (mutex()) {
return doGetRate();
}
}
abstract double doGetRate();
public double acquire() {
return acquire(1);
}
public double acquire(int permits) {
long microsToWait = reserve(permits);
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return 1.0 * microsToWait / SECONDS.toMicros(1L);
}
final long reserve(int permits) {
checkPermits(permits);
synchronized (mutex()) {
return reserveAndGetWaitLength(permits, stopwatch.readMicros());
}
}
/**
* Acquires a permit from this {@code RateLimiter} if it can be obtained
* without exceeding the specified {@code timeout}, or returns {@code false}
* immediately (without waiting) if the permit would not have been granted
* before the timeout expired.
*
* <p>This method is equivalent to {@code tryAcquire(1, timeout, unit)}.
*
* @param timeout the maximum time to wait for the permit. Negative values are treated as zero.
* @param unit the time unit of the timeout argument
* @return {@code true} if the permit was acquired, {@code false} otherwise
* @throws IllegalArgumentException if the requested number of permits is negative or zero
*/
public boolean tryAcquire(long timeout, TimeUnit unit) {
return tryAcquire(1, timeout, unit);
}
public boolean tryAcquire(int permits) {
return tryAcquire(permits, 0, MICROSECONDS);
}
public boolean tryAcquire() {
return tryAcquire(1, 0, MICROSECONDS);
}
public boolean tryAcquire(int permits, long timeout, TimeUnit unit) {
long timeoutMicros = max(unit.toMicros(timeout), 0);
checkPermits(permits);
long microsToWait;
synchronized (mutex()) {
long nowMicros = stopwatch.readMicros();
if (!canAcquire(nowMicros, timeoutMicros)) {
return false;
} else {
microsToWait = reserveAndGetWaitLength(permits, nowMicros);
}
}
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return true;
}
private boolean canAcquire(long nowMicros, long timeoutMicros) {
return queryEarliestAvailable(nowMicros) - timeoutMicros <= nowMicros;
}
/**
* Reserves next ticket and returns the wait time that the caller must wait for.
*
* @return the required wait time, never negative
*/
final long reserveAndGetWaitLength(int permits, long nowMicros) {
long momentAvailable = reserveEarliestAvailable(permits, nowMicros);
return max(momentAvailable - nowMicros, 0);
}
/**
* Returns the earliest time that permits are available (with one caveat).
*
* @return the time that permits are available, or, if permits are available immediately, an
* arbitrary past or present time
*/
abstract long queryEarliestAvailable(long nowMicros);
abstract long reserveEarliestAvailable(int permits, long nowMicros);
@Override
public String toString() {
return String.format("RateLimiter[stableRate=%3.1fqps]", getRate());
}
@VisibleForTesting
abstract static class SleepingStopwatch {
abstract long readMicros();
abstract void sleepMicrosUninterruptibly(long micros);
static final SleepingStopwatch createFromSystemTimer() {
return new SleepingStopwatch() {
final Stopwatch stopwatch = Stopwatch.createStarted();
@Override
long readMicros() {
return stopwatch.elapsed(MICROSECONDS);
}
@Override
void sleepMicrosUninterruptibly(long micros) {
if (micros > 0) {
Uninterruptibles.sleepUninterruptibly(micros, MICROSECONDS);
}
}
};
}
}
private static int checkPermits(int permits) {
checkArgument(permits > 0, "Requested permits (%s) must be positive", permits);
return permits;
}
@Override
final long reserveEarliestAvailable(int requiredPermits, long nowMicros) {
resync(nowMicros);
long returnValue = nextFreeTicketMicros;
double storedPermitsToSpend = min(requiredPermits, this.storedPermits);
double freshPermits = requiredPermits - storedPermitsToSpend;
long waitMicros = storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros);
this.nextFreeTicketMicros = nextFreeTicketMicros + waitMicros;
this.storedPermits -= storedPermitsToSpend;
return returnValue;
}