preface
I believe many students were asked about HashMap during the interview, especially Java/Android programmers. HashMap is almost bound to be mentioned. Because there are too many points to dig. HashMap about Java can be seen everywhere on the Internet. Naturally, with the popularity of fluent, you may also be asked about the HashMap of fluent / dart in the interview. Instead of asking three questions at that time, let's learn about the HashMap of fluent / dart now.
In this article, about Dart's HashMap, I will first list some possible problems encountered in the interview, then make some introduction to the source code, and finally give a superficial answer to these problems. I hope I can help you.
- What is the difference between HashMap and LinkedHashMap?
- This expression final map = Map(); Which of the above two maps is the obtained map?
- What is the underlying data structure of HashMap?
- What is the default size of HashMap?
- How does HashMap handle hash conflicts?
- When will HashMap be expanded? How to expand capacity?
- What is the underlying data structure of LinkedHashMap?
- How does LinkedHashMap handle hash conflicts?
- When will LinkedHashMap be expanded? How to expand capacity?
Let's take a look at the source code with these questions
Using HashMap and LinkedHashMap
Create a HashMap instance:
final map = HashMap();
Create a LinkedHashMap instance
final map = LinkedHashMap();
Create a Map instance
final map = Map();
The map you get here is actually a LinkedHashMap. Its factory constructor is as follows:
@patch
class Map<K, V> {
...
@patch
factory Map() => new LinkedHashMap<K, V>();
...
}
Add / change
map['one'] = 1;
Delete
map.remove('one');
check
final value = map['one'];
The operations of adding, modifying and querying are the same as those of the array. To delete, you need to call remove().
iterator
final it = map.entries.iterator;
while(it.moveNext()) {
print(it.current);
}
A major feature of Dart language is that it is particularly flexible. Here are just some common operations. For other different writing methods, you can refer to API documents.
Next, let's explore the source code.
HashMap
Constructor
@patch
class HashMap<K, V> {
@patch
factory HashMap(
{bool equals(K key1, K key2)?,
int hashCode(K key)?,
bool isValidKey(potentialKey)?}) {
if (isValidKey == null) {
if (hashCode == null) {
if (equals == null) {
return new _HashMap<K, V>();
}
...
}
The HashMap constructor has three optional input parameters, which we don't pass here. In this case, it returns a_ HashMap instance. When there are input parameters, the other two will be returned_ IdentityHashMap and_ One of the customhashmaps, which will not be covered in this article due to space constraints. If you are interested, you can directly look at the source code.
Bottom structure
var _buckets = List<_HashMapEntry<K, V>?>.filled(_INITIAL_CAPACITY, null);
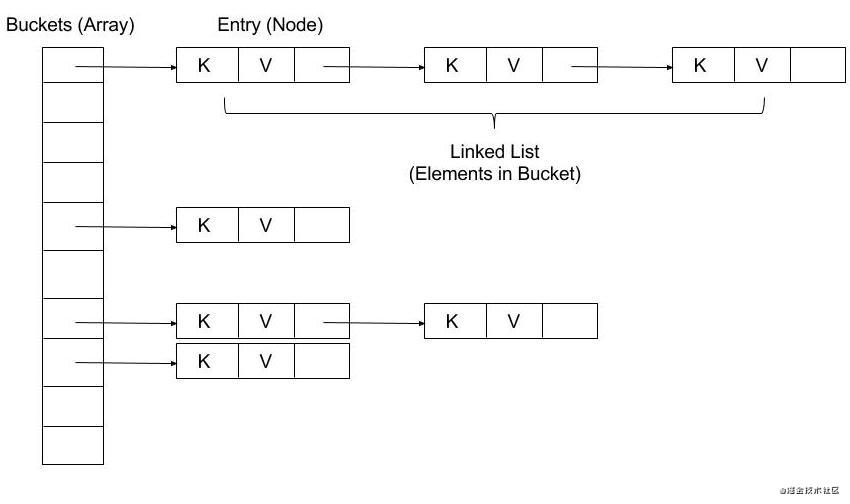
This is the form of array + linked list.
Initialization capacity:
static const int _INITIAL_CAPACITY = 8;
We know that the initialization size of Java's HashMap is 16, and Dart uses 8 Although different, it is also a power of 2. In addition, it seems that Dart does not provide users with the opportunity to customize the initialization size.
Find operation
V? operator [](Object? key) {
final hashCode = key.hashCode;
final buckets = _buckets;
final index = hashCode & (buckets.length - 1);
var entry = buckets[index];
while (entry != null) {
if (hashCode == entry.hashCode && entry.key == key) {
return entry.value;
}
entry = entry.next;
}
return null;
}
It can be seen that taking the array subscript is to directly sum the hashCode of the key and the array length - 1.
final index = hashCode & (buckets.length - 1);
Then compare the hash values saved by the linked list elements and whether the key s are equal. If they are not equal, find the next linked list element. If they are equal, return the corresponding value. Here we should note that there are no red and black trees. So dart's HashMap implementation is actually the same as jdk1 The implementation before 8 is similar.
Assignment operation
void operator []=(K key, V value) {
final hashCode = key.hashCode;
final buckets = _buckets;
final length = buckets.length;
final index = hashCode & (length - 1);
var entry = buckets[index];
while (entry != null) {
if (hashCode == entry.hashCode && entry.key == key) {
entry.value = value;
return;
}
entry = entry.next;
}
_addEntry(buckets, index, length, key, value, hashCode);
}
In fact, the process is similar to the value taking operation. When the key value pair exists, it will be directly assigned, and when it does not exist, it will be called_ addEntry() does the adding operation.
void _addEntry(List<_HashMapEntry<K, V>?> buckets, int index, int length,
K key, V value, int hashCode) {
final entry = new _HashMapEntry<K, V>(key, value, hashCode, buckets[index]);
buckets[index] = entry;
final newElements = _elementCount + 1;
_elementCount = newElements;
// If we end up with more than 75% non-empty entries, we
// resize the backing store.
if ((newElements << 2) > ((length << 1) + length)) _resize();
_modificationCount = (_modificationCount + 1) & _MODIFICATION_COUNT_MASK;
}
Here, notice the new_ When HashMapEntry, it will pass in the entry of the current array, that is, buckets[index]. Then assign the new entry to buckets[index].
buckets[index] = entry;
Here we can guess that the head insertion method should be used. In addition_ modificationCount is self incremented every time there are operations such as adding and deleting. If there are such operations in the process of traversing HashMap, it will lead to Concurrent modification exception. This is the "fail fast" mechanism
Obviously, the new operation will involve capacity expansion. From the above comments, we can see that when the number of key value pairs exceeds 75% of the array capacity, the capacity will be expanded, that is, its load factor is 0.75. This is the same as Java. This 75% calculation process uses bit operation and addition instead of division in order to improve efficiency, which is equivalent to E4 > L3 - > e / L > 3 / 4 - > e / L > 75%
Capacity expansion operation
void _resize() {
final oldBuckets = _buckets;
final oldLength = oldBuckets.length;
final newLength = oldLength << 1;
final newBuckets = new List<_HashMapEntry<K, V>?>.filled(newLength, null);
for (int i = 0; i < oldLength; i++) {
var entry = oldBuckets[i];
while (entry != null) {
final next = entry.next;
final hashCode = entry.hashCode;
final index = hashCode & (newLength - 1);
entry.next = newBuckets[index];
newBuckets[index] = entry;
entry = next;
}
}
_buckets = newBuckets;
}
The length of the new array after capacity expansion is twice the original length.
final newLength = oldLength << 1;
We know that its initial length is 8. It can be seen that the length of the buckets array will always be a power of 2.
From the process of transferring the entry from the old array to the new array, we can also see that the transfer process also uses header interpolation.
One thing to note about capacity expansion here is that when the number of key value pairs exceeds 75% of the length of the array, capacity expansion will occur, rather than when the array is occupied by more than 75%. This misunderstanding has also appeared in many articles discussing Java HashMap. We need to carefully understand the differences.
Delete operation
void _removeEntry(_HashMapEntry<K, V> entry,
_HashMapEntry<K, V>? previousInBucket, int bucketIndex) {
if (previousInBucket == null) {
_buckets[bucketIndex] = entry.next;
} else {
previousInBucket.next = entry.next;
}
}
Deletion is the normal process of deleting nodes in the linked list.
ergodic
void forEach(void action(K key, V value)) {
final stamp = _modificationCount;
final buckets = _buckets;
final length = buckets.length;
for (int i = 0; i < length; i++) {
var entry = buckets[i];
while (entry != null) {
action(entry.key, entry.value);
if (stamp != _modificationCount) {
throw new ConcurrentModificationError(this);
}
entry = entry.next;
}
}
}
The traversal will start from the first position of the array and access each item of the linked list in turn. It is obvious that the order of traversal is inconsistent with the sequence of key insertion. Here we can also see that the "fail fast" mechanism works. If users add or delete HashMap during traversal, it will lead to stamp and_ The modificationCount is not equal, resulting in the ConcurrentModificationError exception.
Summary
In general, dart's HashMap is relatively simple to implement. On the whole, it is similar to jdk1 Version 7 is similar to HashMap. I believe students who have studied Java implementation will find DART's HashMap easier to understand.
LinkedHashMap
From the API documents, the difference between LinkedHashMap and HashMap is that LinkedHashMap will keep the insertion order of key value pairs during traversal. In jdk, the implementation of LinkedHashMap is to transform the Node into a two-way linked list to preserve the order. dart's LinkedHashMap implementation is different.
Constructor
@patch
class LinkedHashMap<K, V> {
@patch
factory LinkedHashMap(
{bool equals(K key1, K key2)?,
int hashCode(K key)?,
bool isValidKey(potentialKey)?}) {
if (isValidKey == null) {
if (hashCode == null) {
if (equals == null) {
return new _InternalLinkedHashMap<K, V>();
}
...
}
Similarly, the LinkedHashMap constructor has three optional input parameters, which we don't pass here. In this case, it returns a_ InternalLinkedHashMap instance. When there are input parameters, the other two will be returned_ CompactLinkedIdentityHashMap and_ Compactlinked customhashmap is one of them, which will not be covered in this article.
Bottom structure
Let's look directly_ InternalLinkedHashMap.
_ InternalLinkedHashMap constructor:
_InternalLinkedHashMap() {
_index = new Uint32List(_HashBase._INITIAL_INDEX_SIZE);
_hashMask = _HashBase._indexSizeToHashMask(_HashBase._INITIAL_INDEX_SIZE);
_data = new List.filled(_HashBase._INITIAL_INDEX_SIZE, null);
_usedData = 0;
_deletedKeys = 0;
}
Visible_ There are two arrays at the bottom of InternalLinkedHashMap_ Index and_ data. _ The index array records the corresponding key value pairs with the hash code as the index_ Position in the data array_ The data array saves key and value in the order of insertion.
It is shown in the figure as follows:
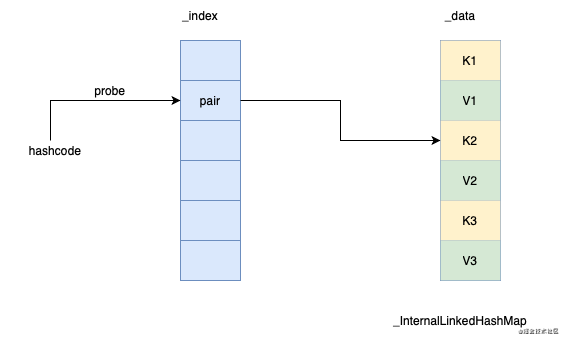
The initialization length of both arrays is_ INITIAL_INDEX_SIZE. As can be seen from the following code, its value is 16_ The data array stores key value pairs. At most, it can only store 8 key value pairs. In other words, the initial capacity of LinkedHashMap is actually 8.
abstract class _HashBase implements _HashVMBase {
...
static const int _INITIAL_INDEX_BITS = 3;
static const int _INITIAL_INDEX_SIZE = 1 << (_INITIAL_INDEX_BITS + 1);
}
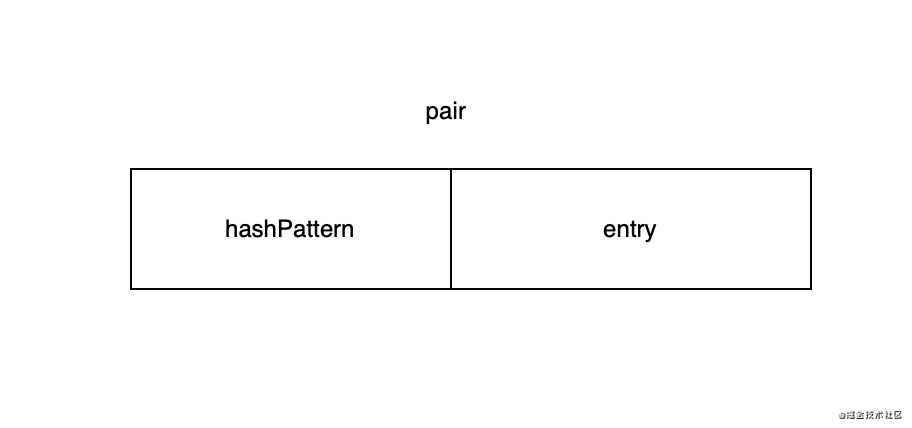
The underlying layer of LinkedHashMap is actually realized by linear detection method. Array_ index stores an integer called pair. It is called pair because it is composed of high and low parts. The high part is called hashPattern and the low part is called entry. Entry point_ The key value pair corresponding to the data array. The key point in the search process from hashcode to real key value pairs is actually this entry.
At the same time, pair is also used to express_ The status of the corresponding position of the index array. 0(_UNUSED_PAIR) indicates that it is not currently used, and 1(_DELETED_PAIR) indicates that the current location is deleted:
abstract class _HashBase implements _HashVMBase {
...
static const int _UNUSED_PAIR = 0;
static const int _DELETED_PAIR = 1;
...
}
Find operation
V? operator [](Object? key) {
var v = _getValueOrData(key);
return identical(_data, v) ? null : internal.unsafeCast<V>(v);
}
The lookup will eventually be called to_ getValueOrData
Object? _getValueOrData(Object? key) {
final int size = _index.length;
final int sizeMask = size - 1;
final int maxEntries = size >> 1;
final int fullHash = _hashCode(key);
final int hashPattern = _HashBase._hashPattern(fullHash, _hashMask, size);
int i = _HashBase._firstProbe(fullHash, sizeMask);
int pair = _index[i];
while (pair != _HashBase._UNUSED_PAIR) {
if (pair != _HashBase._DELETED_PAIR) {
final int entry = hashPattern ^ pair;
if (entry < maxEntries) {
final int d = entry << 1;
if (_equals(key, _data[d])) {
return _data[d + 1];
}
}
}
i = _HashBase._nextProbe(i, sizeMask);
pair = _index[i];
}
return _data;
}
From this function, we can understand the process of linear detection. First, by calling_ HashBase._firstProbe() to get the first address:
static int _firstProbe(int fullHash, int sizeMask) {
final int i = fullHash & sizeMask;
// Light, fast shuffle to mitigate bad hashCode (e.g., sequential).
return ((i << 1) + i) & sizeMask;
}
The first detection is to take the module of hashcode and array length. Note that another step is to take the module after multiplying i by 3. From the annotation point of view, it is to make the hashcode distribution more uniform. You can think about the reasons.
Get the pair after the first detection. If the pair is unoccupied, it indicates that the key value pair does not exist and returns directly as agreed_ Data array. If the status is deleted, then conduct secondary detection. If it is in the normal occupancy state, XOR the pair and hashPattern. As you can see from the previous figure, you get the entry. If the entry does not cross the boundary, multiply it by 2 to get the key_ The position in the data array is. Finally, if the key is equal, it is returned_ The next element of data is value.
The second probe will call_ HashBase._nextProbe()
static int _nextProbe(int i, int sizeMask) => (i + 1) & sizeMask;
The source code is to try the next address one by one.
Assignment operation
void operator []=(K key, V value) {
final int size = _index.length;
final int fullHash = _hashCode(key);
final int hashPattern = _HashBase._hashPattern(fullHash, _hashMask, size);
final int d = _findValueOrInsertPoint(key, fullHash, hashPattern, size);
if (d > 0) {
_data[d] = value;
} else {
final int i = -d;
_insert(key, value, hashPattern, i);
}
}
When assigning a value, it will be called first_ findValueOrInsertPoint() to find existing key value pairs, their logic and functions_ getValueOrData is similar. If a key value pair exists, the corresponding value is returned directly_ data, and then directly assign the value. If it does not exist, it will return a negative number. In fact, this negative number is what is detected after detection_ Available locations in the index array. With this location, you can call_ insert() to do the insertion operation.
void _insert(K key, V value, int hashPattern, int i) {
if (_usedData == _data.length) {
_rehash();
this[key] = value;
} else {
assert(1 <= hashPattern && hashPattern < (1 << 32));
final int index = _usedData >> 1;
assert((index & hashPattern) == 0);
_index[i] = hashPattern | index;
_data[_usedData++] = key;
_data[_usedData++] = value;
}
}
Judge before inserting_ Whether the data array is full. Call when it's full_ rehash() has been expanded. If it is not full, it is a simple assignment operation, and_ After dividing the next empty bit of data by 2, do or operation with hashPattern, and then put it into_ index array, and then put the key and value next to each other_ Data array.
Capacity expansion operation
void _rehash() {
if ((_deletedKeys << 2) > _usedData) {
_init(_index.length, _hashMask, _data, _usedData);
} else {
_init(_index.length << 1, _hashMask >> 1, _data, _usedData);
}
}
Before capacity expansion, check whether more than half of the elements in the array are deleted. If so, the expansion length is the same as that of the original array, otherwise the length of the new array is twice that of the original array. Why do you do this? Let's go on_ ininit() function.
void _init(int size, int hashMask, List? oldData, int oldUsed) {
_index = new Uint32List(size);
_hashMask = hashMask;
_data = new List.filled(size, null);
_usedData = 0;
_deletedKeys = 0;
if (oldData != null) {
for (int i = 0; i < oldUsed; i += 2) {
var key = oldData[i];
if (!_HashBase._isDeleted(oldData, key)) {
this[key] = oldData[i + 1];
}
}
}
}
The new length will be created here_ index and_ data array. If the copied key is in the correct state, it will not be deleted. Therefore, the "capacity expansion" process as long as the original array actually deletes the deleted elements.
Delete operation
V? remove(Object? key) {
final int size = _index.length;
final int sizeMask = size - 1;
final int maxEntries = size >> 1;
final int fullHash = _hashCode(key);
final int hashPattern = _HashBase._hashPattern(fullHash, _hashMask, size);
int i = _HashBase._firstProbe(fullHash, sizeMask);
int pair = _index[i];
while (pair != _HashBase._UNUSED_PAIR) {
if (pair != _HashBase._DELETED_PAIR) {
final int entry = hashPattern ^ pair;
if (entry < maxEntries) {
final int d = entry << 1;
if (_equals(key, _data[d])) {
_index[i] = _HashBase._DELETED_PAIR;
_HashBase._setDeletedAt(_data, d);
V value = _data[d + 1];
_HashBase._setDeletedAt(_data, d + 1);
++_deletedKeys;
return value;
}
}
}
i = _HashBase._nextProbe(i, sizeMask);
pair = _index[i];
}
return null;
}
The deletion process is also a linear detection. If you find it, you can do two things. First, you will_ Set the corresponding position of index array to_ HashBase._DELETED_PAIR. Then_ Set the corresponding position of data array to_ data.
ergodic
As we know, LinkedHashMap will ensure that the traversal order and insertion order are the same. Through the above introduction, we know that the inserted key value pairs are saved in order_ Data array. Then you only need to traverse when traversing_ The data array can naturally traverse the LinkedHashMap in the insertion order.
bool moveNext() {
if (_table._isModifiedSince(_data, _checkSum)) {
throw new ConcurrentModificationError(_table);
}
do {
_offset += _step;
} while (_offset < _len && _HashBase._isDeleted(_data, _data[_offset]));
if (_offset < _len) {
_current = internal.unsafeCast<E>(_data[_offset]);
return true;
} else {
_current = null;
return false;
}
}
If the key value pair is deleted, it will be skipped.
Summary
Dart's LinkedHashMap implementation is different from that of jdk. You may be unfamiliar with it for the first time. You need to carefully study the source code to see the specific implementation, and you can learn something.
summary
In general, the implementation of Dart's HashMap and LinkedHashMap is relatively simple, and there is no detailed optimization work like jdk, which may need the further development of Dart / fluent. But we can also see that no matter what language it is, the design ideas of some basic data structures are interlinked. By mastering the design ideas behind the source code, we can draw inferences from one instance. No matter which new language or new architecture, we can quickly master it. Finally, I put the initial questions together with the shallow answers below:
What is the difference between HashMap and LinkedHashMap?
From the perspective of API, the traversal order of HashMap is not guaranteed to be the same as the insertion order, while the traversal order of LinkedHashMap is guaranteed to be the same as the insertion order.
This expression final map = Map(); Which of the above two maps is the obtained map?
It's LinkedHashMap.
What is the underlying data structure of HashMap?
Array + linked list.
What is the default size of HashMap?
8.
How does HashMap handle hash conflicts?
Chain address method.
When will HashMap be expanded? How to expand capacity?
Capacity expansion occurs when the number of key value pairs exceeds 75% of the length of the array, rather than when the array is occupied by more than 75%. The length of the new array after capacity expansion will be twice that of the original array. The head interpolation method is used in the capacity expansion process.
What is the underlying data structure of LinkedHashMap?
Two arrays:_ Index and_ data, _ The index array records the corresponding key value pairs with the hash code as the index_ Position in the data array_ The data array saves key and value in the order of insertion.
How does LinkedHashMap handle hash conflicts?
Linear detection method.
When will LinkedHashMap be expanded? How to expand capacity?
_ When the data array is full, expand the capacity. Before expanding the capacity, first check whether more than half of the elements in the array are deleted. If so, the expansion length is the same as that of the original array, otherwise the length of the new array is twice the original length.
last
Xiaobian has collected some learning documents, interview questions, Android core notes and other documents related to Android Development on the Internet, hoping to help you learn and improve. If you need learning reference, you can go to me directly GitHub address: https://github.com/733gh/Android-T3 Access.